
Upload folder using huggingface_hub
Browse files- .gitattributes +3 -0
- README.md +191 -0
- assets/Logs.png +3 -0
- assets/molforge_architecture.png +3 -0
- assets/reward_curve.png +3 -0
- molforge_grpo_official_submission.ipynb +368 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,6 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
assets/Logs.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
assets/molforge_architecture.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
assets/reward_curve.png filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,191 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "MolForge: Verifier-Driven RL for Drug Discovery"
|
| 3 |
+
emoji: 🧬
|
| 4 |
+
colorFrom: indigo
|
| 5 |
+
colorTo: blue
|
| 6 |
+
sdk: static
|
| 7 |
+
pinned: false
|
| 8 |
+
license: mit
|
| 9 |
+
tags:
|
| 10 |
+
- reinforcement-learning
|
| 11 |
+
- drug-discovery
|
| 12 |
+
- chemistry
|
| 13 |
+
- multi-agent
|
| 14 |
+
- oncology
|
| 15 |
+
- molecular-simulation
|
| 16 |
+
- openenv
|
| 17 |
+
---
|
| 18 |
+
|
| 19 |
+
# MolForge: Verifier-Driven RL for Drug Discovery
|
| 20 |
+
|
| 21 |
+
MolForge is a reinforcement learning environment that simulates a **medical oncology discovery lab**. Unlike traditional LLM tasks where the model generates a final answer in one shot, MolForge forces the model to execute the **scientific method** under real-world constraints: budget, toxicity, and synthesis complexity.
|
| 22 |
+
|
| 23 |
+
### The Scientific Method as a Workflow
|
| 24 |
+
|
| 25 |
+
Imagine a biotech team tasked with optimizing a lead candidate for **KRAS G12C** (including a high-difficulty resistance panel). The model doesn't just "write" a molecule; it controls a specialist team that must navigate a resource-constrained laboratory:
|
| 26 |
+
|
| 27 |
+
- **Lead Chemist**: Proposes molecular edits and decides when to submit.
|
| 28 |
+
- **Assay Planner**: Allocates limited budget to run empirical tests.
|
| 29 |
+
- **Toxicologist**: Reviews safety risks and can object to unsafe designs.
|
| 30 |
+
- **Process Chemist**: Evaluates whether the molecule is practical to synthesize.
|
| 31 |
+
|
| 32 |
+
Every action—editing a fragment, running a docking simulation, or ordering a toxicity assay—is a decision that impacts the final outcome. The model must learn to gather enough evidence to justify a submission while keeping the project within budget.
|
| 33 |
+
|
| 34 |
+
> **Core Philosophy:** The LLM is not the judge. The LLM is the scientist being judged by external, verifiable reality.
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
## What Makes MolForge Special?
|
| 38 |
+
|
| 39 |
+
MolForge is built to move beyond simple "molecule generation" into "scientific workflow optimization." Here are the seven core pillars that make it unique:
|
| 40 |
+
|
| 41 |
+
1. [**Verifier-Based Evaluation**](#1-verifier-based-evaluation): The LLM is the scientist, not the judge. It is held accountable by real-world verifiers like **RDKit** and **TDC**.
|
| 42 |
+
2. [**Chemical & Molecular Simulations**](#2-chemical--molecular-simulations): Realistic simulation of potency and existence using heuristic docking, **RDKit**, and **TDC**.
|
| 43 |
+
3. [**Self-Correction & Improvement Loop**](#3-self-correction--improvement-loop): After each edit, agents receive structured feedback from verifiers, allowing them to self-correct.
|
| 44 |
+
4. [**Decomposed Reward Architecture**](#4-decomposed-reward-architecture): Multi-step rewards for every action (research, edits, coordination) provide high observability.
|
| 45 |
+
5. [**Scientific Model Improvement**](#5-scientific-model-improvement): Real verifier feedback (Reviews) guides the model toward scientifically sound designs.
|
| 46 |
+
6. [**Strategic Training Modes**](#6-strategic-training-modes): A dual-mode system using **Curriculum mode** (partial credit) and **Assay-Gated mode** (strict).
|
| 47 |
+
7. [**Multi-Agent Governance**](#7-multi-agent-governance): A specialized team that plans, executes, and shares information to coordinate the next plan of action.
|
| 48 |
+
|
| 49 |
+
---
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
## Architecture
|
| 53 |
+
|
| 54 |
+
The architecture is a closed scientific feedback loop:
|
| 55 |
+
|
| 56 |
+

|
| 57 |
+
|
| 58 |
+
## Scientific Verifier Layers
|
| 59 |
+
|
| 60 |
+
### RDKit: chemical plausibility
|
| 61 |
+
|
| 62 |
+
RDKit checks molecule-like behavior and chemistry descriptors. In MolForge, this layer is used to keep the molecule edits grounded in chemical reality. It supports descriptor-style reasoning such as lipophilicity, polarity, tractability, and drug-likeness.
|
| 63 |
+
|
| 64 |
+
### TDC: biomedical outcome signals
|
| 65 |
+
|
| 66 |
+
Therapeutics Data Commons represents the medical outcome side of the environment. It provides the project with a path toward realistic prediction tasks such as toxicity, synthesis difficulty, and drug-likeness. In the default Docker deployment, RDKit remains active and TDC is optional because it can pull a heavier platform-sensitive ML stack.
|
| 67 |
+
|
| 68 |
+
### Heuristic docking: receptor fit
|
| 69 |
+
|
| 70 |
+
MolForge includes a docking-style surrogate that answers three fast questions:
|
| 71 |
+
|
| 72 |
+
| Check | Question | Why it matters |
|
| 73 |
+
| --- | --- | --- |
|
| 74 |
+
| Pocket matching | Does the hinge fragment fit the receptor pocket? | Better pocket complementarity improves potency. |
|
| 75 |
+
| Lipophilic match | Is LogP near the target pocket's hydrophobic comfort zone around `3.0`? | Too much lipophilicity can increase toxicity; too little can weaken binding. |
|
| 76 |
+
| Polarity match | Is TPSA near a useful range around `85.0`? | Polarity affects binding, permeability, and clash risk. |
|
| 77 |
+
|
| 78 |
+
This gives the environment fast receptor-aware feedback in milliseconds, which is important for RL.
|
| 79 |
+
|
| 80 |
+
## Training Story
|
| 81 |
+
|
| 82 |
+
The training pipeline has two stages:
|
| 83 |
+
|
| 84 |
+
1. **SFT warm start**
|
| 85 |
+
2. **RL with verifier rewards**
|
| 86 |
+
|
| 87 |
+
### Base model
|
| 88 |
+
|
| 89 |
+
The model used for the main run is:
|
| 90 |
+
|
| 91 |
+
```text
|
| 92 |
+
unsloth/Qwen3.5-2B
|
| 93 |
+
```
|
| 94 |
+
|
| 95 |
+
The raw base model was not reliable enough for the environment at first. It often failed to produce the exact structured JSON actions that MolForge expects, and it did not consistently respect the specialist-agent interaction format.
|
| 96 |
+
|
| 97 |
+
So the first step was a small SFT warm start. This stage is not meant to teach the model the optimal chemistry. It teaches the model how to speak the environment's action language:
|
| 98 |
+
|
| 99 |
+
- valid JSON actions
|
| 100 |
+
- correct role/action pairing
|
| 101 |
+
- correct molecule slots and fragments
|
| 102 |
+
- concise rationales
|
| 103 |
+
- evidence fields based only on visible observations
|
| 104 |
+
- expected-effect fields such as potency up/down or toxicity up/down
|
| 105 |
+
- valid specialist messages where needed
|
| 106 |
+
|
| 107 |
+
### Training Results
|
| 108 |
+
After SFT, the policy is trained with GRPO-style RL against MolForge itself. During training, the model explores the 256-combination molecular edit space, receiving rewards for molecule quality, evidence coverage, and budget discipline.
|
| 109 |
+
|
| 110 |
+

|
| 111 |
+

|
| 112 |
+
|
| 113 |
+
As shown in the reward curve and logs, the model successfully learns to navigate the scientific constraints, moving from early exploration to consistent, verifier-backed molecule submissions. For strict evaluation, the environment switches back to `assay_gated` mode.
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
## Example Successful Strategy
|
| 125 |
+
|
| 126 |
+
A strong MolForge policy usually learns to:
|
| 127 |
+
|
| 128 |
+
1. Start with a cheap property assay.
|
| 129 |
+
2. Edit one high-impact molecular slot.
|
| 130 |
+
3. Re-assay after the edit.
|
| 131 |
+
4. Repair toxicity or synthesis issues before chasing more potency.
|
| 132 |
+
5. Save expensive toxicity or MD-style assays for candidates that are worth confirming.
|
| 133 |
+
6. Use specialist review messages before risky submission.
|
| 134 |
+
7. Restart in the hard scenario if the scaffold appears trapped.
|
| 135 |
+
8. Submit only when potency, toxicity, and synthesis evidence are present for the current molecule.
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
## Why This Project Matters
|
| 140 |
+
|
| 141 |
+
MolForge is designed to test a deeper kind of AI capability than simple answer generation. The model must work inside a scientific feedback loop where actions are checked, evidence costs money, unsafe decisions can be blocked, and the final answer only matters if the path to that answer is experimentally justified.
|
| 142 |
+
|
| 143 |
+
The strongest part of the project is that the LLM is not trusted by default. It has to earn trust through verifier-backed decisions.
|
| 144 |
+
|
| 145 |
+
## Deep Dive: What Makes MolForge Special?
|
| 146 |
+
|
| 147 |
+
### 1. Verifier-Based Evaluation
|
| 148 |
+
In many LLM systems, the model itself is used as a judge, reviewer, or evaluator. MolForge flips that pattern. The LLM is the scientist being judged, not the judge. It is held accountable by real-world verifiers like **RDKit**, **TDC**, and molecular simulation engines. This ensures that the model's progress is grounded in chemical and biological reality, not just persuasive language.
|
| 149 |
+
|
| 150 |
+
### 2. Chemical & Molecular Simulations
|
| 151 |
+
MolForge doesn't just predict outcomes; it utilizes multiple simulation layers to ground the model's decisions:
|
| 152 |
+
* **Chemical Plausibility (RDKit):** Decides if the molecule generated by the LLM (via edits) can actually exist in chemical reality. [Visit RDKit](https://www.rdkit.org)
|
| 153 |
+
* **Medical Outcomes (TDC):** Predicts the most probable medical outcomes and properties using the [Therapeutics Data Commons](https://tdcommons.ai).
|
| 154 |
+
* **Heuristic Docking Score:** A fast, physics-inspired simulation that updates **potency** in milliseconds based on three rules:
|
| 155 |
+
1. **Pocket Matching:** Does the fragment structurally fit the target receptor pocket (e.g., KRAS G12C)?
|
| 156 |
+
2. **Lipophilic Match:** Is the LogP near the ideal **3.0** to sit comfortably in the hydrophobic pocket?
|
| 157 |
+
3. **Polarity Match:** Is the TPSA near the ideal **85.0** to avoid repulsive polar clashes?
|
| 158 |
+
|
| 159 |
+
### 3. Self-Correction & Improvement Loop
|
| 160 |
+
MolForge is an iterative environment. After each proposed molecular modification, the model receives a structured review from the verifiers. This feedback allows the agent to recognize liabilities (like toxicity or low potency) and correct them in the next step. This creates a genuine **self-improvement loop** within each episode.
|
| 161 |
+
|
| 162 |
+
### 4. Decomposed Reward Architecture
|
| 163 |
+
The reward function is not a single "black box" scalar. We use a multi-step reward system where small-scale rewards are designed for every individual action—research, molecular edits, and inter-agent coordination. While we may output a single total reward for training simplicity (especially for the hackathon), the decomposed components allow for massive observability into which sections of the workflow are lacking.
|
| 164 |
+
|
| 165 |
+
### 5. Scientific Model Improvement
|
| 166 |
+
We use real verifier feedback to drive model improvement. By providing constant, verifiable reviews, we train the model to improve its designs based on evidence. This moves the model away from simple pattern matching and toward a more rigorous, evidence-based design process.
|
| 167 |
+
|
| 168 |
+
### 6. Strategic Training Modes: Curriculum vs. Assay-Gated
|
| 169 |
+
To solve the "sparse reward" problem common in RL, MolForge uses two distinct modes:
|
| 170 |
+
* **Curriculum Mode (Training):** If a model fails to submit but showed good scientific behavior, it receives "Partial Credit" (up to +0.75). It gets points for gathering evidence and designing promising molecules. These "breadcrumbs" teach the model how to explore before it discovers the terminal submission bonus.
|
| 171 |
+
* **Assay-Gated Mode (Evaluation):** This is the strict, official mode used for hackathon grading. There is **zero partial credit**. If the model fails to explicitly `submit` a high-potency, safe molecule before the budget runs out, its score is exactly `0.0`.
|
| 172 |
+
|
| 173 |
+
### 7. Multi-Agent Governance
|
| 174 |
+
Drug discovery is a team effort. MolForge implements a multi-agent system where specialized roles (Lead Chemist, Toxicologist, Assay Planner) review each other's moves, plans, and executions. Crucially, these agents **share information and coordinate** between themselves to decide the next plan of action, ensuring that every decision undergoes a rigorous "peer review" process before execution.
|
| 175 |
+
|
| 176 |
+
---
|
| 177 |
+
|
| 178 |
+
## Final Takeaway
|
| 179 |
+
|
| 180 |
+
MolForge is special because it treats the LLM as a trainable research agent inside a controlled scientific environment, not as an oracle. The model is judged by chemistry and biomedical verifiers, corrected by specialist feedback, constrained by assay budget, and scored by a reward system that can explain where the policy succeeded or failed.
|
| 181 |
+
|
| 182 |
+
The important pieces work together:
|
| 183 |
+
|
| 184 |
+
- **Verifier-first evaluation:** RDKit, TDC-style signals, and docking-style simulation judge the model's actions.
|
| 185 |
+
- **Multi-agent review:** specialist roles create checks and balances around each decision.
|
| 186 |
+
- **Self-improvement loop:** every action produces feedback that the next action can respond to.
|
| 187 |
+
- **Decomposed rewards:** the environment tracks molecule quality, evidence, budget, coordination, and safety separately.
|
| 188 |
+
- **Curriculum to strict evaluation:** training can use partial-credit breadcrumbs, while final evaluation remains unforgiving.
|
| 189 |
+
- **Dynamic molecular search:** the model explores 256 fragment combinations across three starting scientific scenarios instead of memorizing one answer.
|
| 190 |
+
|
| 191 |
+
That is the project thesis: useful scientific agents should not merely generate plausible ideas. They should operate in a loop where the world pushes back.
|
assets/Logs.png
ADDED
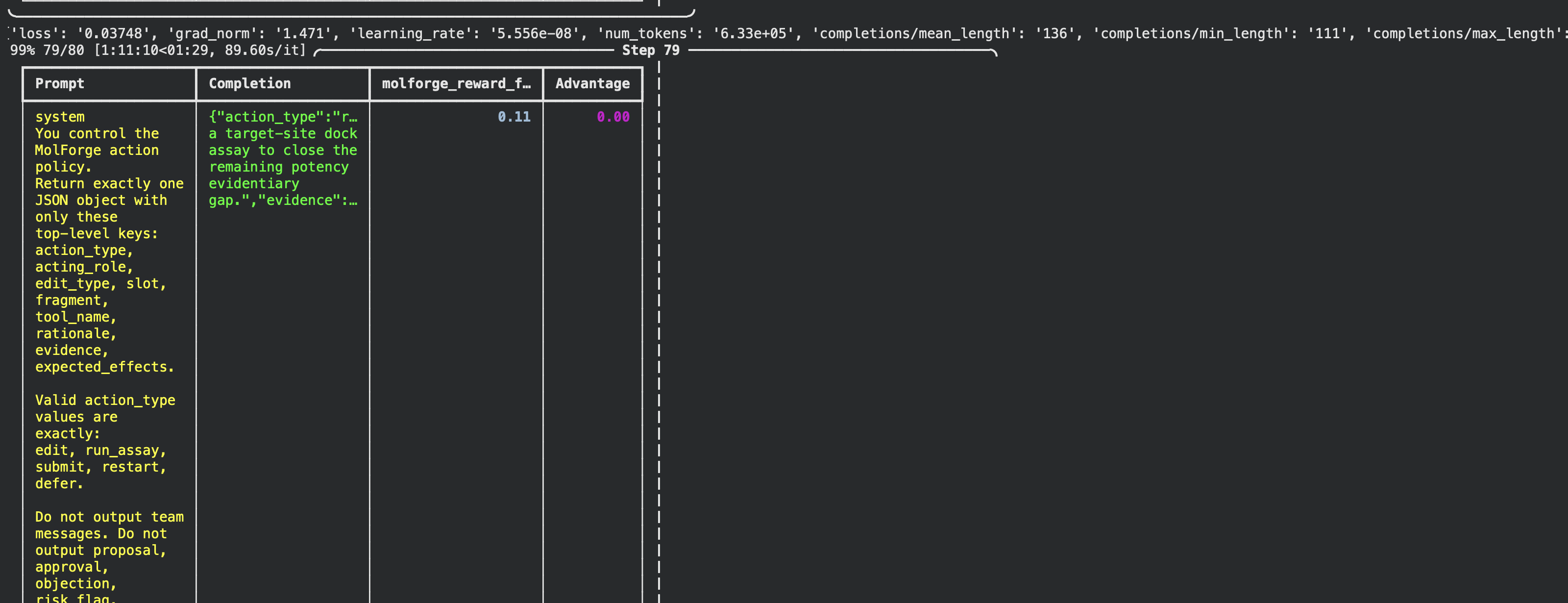
|
Git LFS Details
|
assets/molforge_architecture.png
ADDED
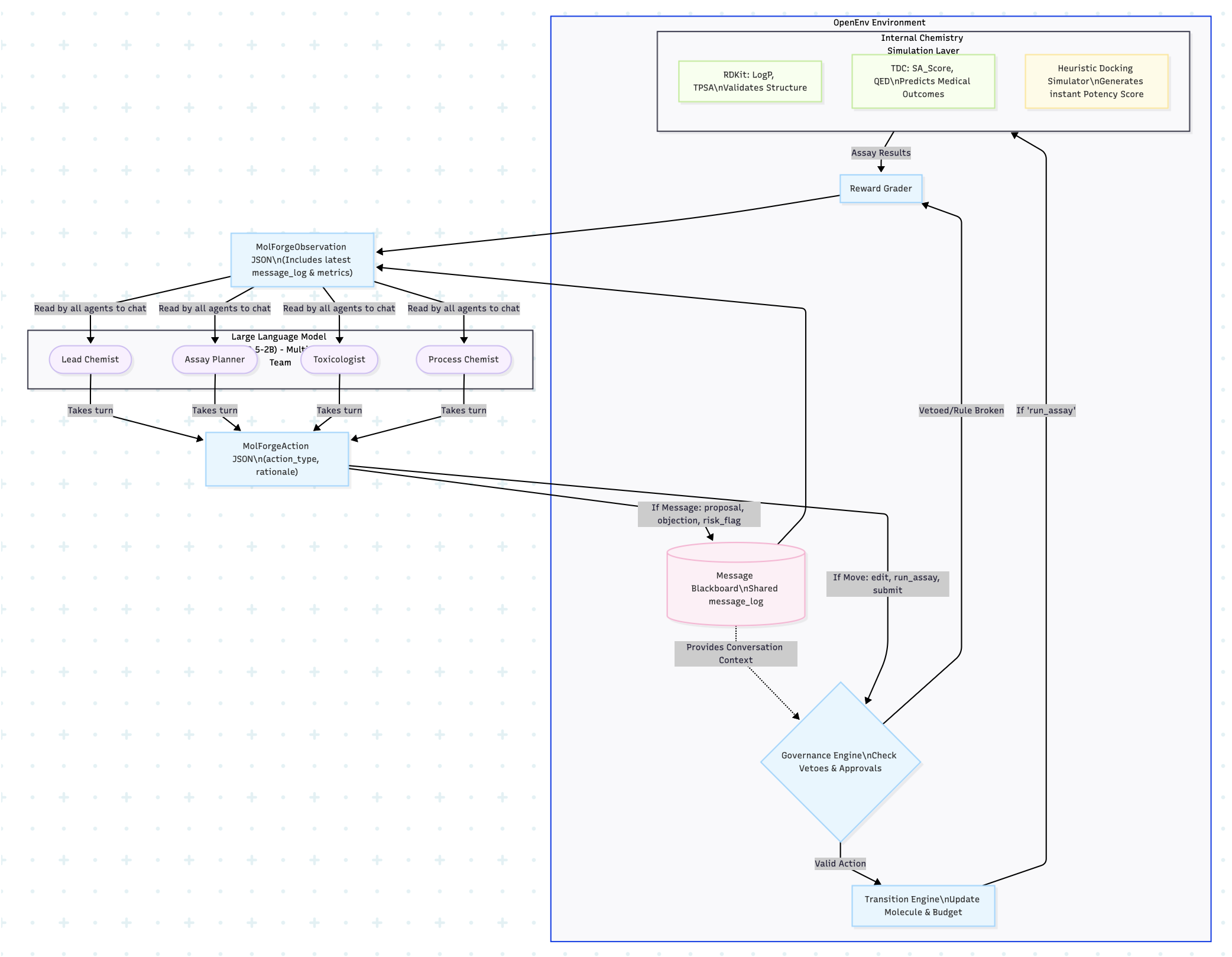
|
Git LFS Details
|
assets/reward_curve.png
ADDED

|
Git LFS Details
|
molforge_grpo_official_submission.ipynb
ADDED
|
@@ -0,0 +1,368 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"cell_type": "markdown",
|
| 5 |
+
"metadata": {},
|
| 6 |
+
"source": [
|
| 7 |
+
"# MolForge GRPO Training Pipeline\n",
|
| 8 |
+
"This notebook implements the Reinforcement Learning (GRPO) training pipeline for the MolForge environment.\n",
|
| 9 |
+
"We train the model using a **Proposer-Critic-Selector** architecture and targeted **reward shaping** to overcome local minima."
|
| 10 |
+
]
|
| 11 |
+
},
|
| 12 |
+
{
|
| 13 |
+
"cell_type": "code",
|
| 14 |
+
"execution_count": null,
|
| 15 |
+
"metadata": {},
|
| 16 |
+
"outputs": [],
|
| 17 |
+
"source": [
|
| 18 |
+
"!pip install -U \"unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git\"\n",
|
| 19 |
+
"!pip install -U \"trl>=0.21.0\" peft accelerate bitsandbytes datasets matplotlib pandas huggingface_hub \"openenv-core[core]>=0.2.3\" rdkit jmespath xformers"
|
| 20 |
+
]
|
| 21 |
+
},
|
| 22 |
+
{
|
| 23 |
+
"cell_type": "code",
|
| 24 |
+
"execution_count": null,
|
| 25 |
+
"metadata": {},
|
| 26 |
+
"outputs": [],
|
| 27 |
+
"source": [
|
| 28 |
+
"import os\n",
|
| 29 |
+
"import sys\n",
|
| 30 |
+
"from pathlib import Path\n",
|
| 31 |
+
"\n",
|
| 32 |
+
"# Clone the repository\n",
|
| 33 |
+
"if not Path(\"/content/molt_lab\").exists():\n",
|
| 34 |
+
" !git clone https://github.com/Adhitya-Vardhan/molt_lab.git /content/molt_lab\n",
|
| 35 |
+
"\n",
|
| 36 |
+
"# Add project root to path\n",
|
| 37 |
+
"if \"/content/molt_lab\" not in sys.path:\n",
|
| 38 |
+
" sys.path.insert(0, \"/content/molt_lab\")\n",
|
| 39 |
+
" \n",
|
| 40 |
+
"# Change working directory\n",
|
| 41 |
+
"os.chdir(\"/content/molt_lab\")"
|
| 42 |
+
]
|
| 43 |
+
},
|
| 44 |
+
{
|
| 45 |
+
"cell_type": "code",
|
| 46 |
+
"execution_count": null,
|
| 47 |
+
"metadata": {},
|
| 48 |
+
"outputs": [],
|
| 49 |
+
"source": [
|
| 50 |
+
"import time\n",
|
| 51 |
+
"import os\n",
|
| 52 |
+
"\n",
|
| 53 |
+
"# Training Configuration\n",
|
| 54 |
+
"os.environ[\"MOLFORGE_REWARD_MODE\"] = \"curriculum\"\n",
|
| 55 |
+
"os.environ[\"MOLFORGE_TRAINING_RANDOMIZATION\"] = \"1\"\n",
|
| 56 |
+
"\n",
|
| 57 |
+
"RL_MAX_STEPS = 300\n",
|
| 58 |
+
"NUM_GENERATIONS = 2\n",
|
| 59 |
+
"PER_DEVICE_BATCH = 2\n",
|
| 60 |
+
"GRAD_ACCUM = 4\n",
|
| 61 |
+
"LEARNING_RATE = 2e-6\n",
|
| 62 |
+
"MAX_SEQ_LENGTH = 2048\n",
|
| 63 |
+
"MAX_PROMPT_LENGTH = 1536\n",
|
| 64 |
+
"MAX_COMPLETION_LENGTH = 384\n",
|
| 65 |
+
"\n",
|
| 66 |
+
"RUN_NAME = time.strftime(\"molforge_grpo_%Y%m%d_%H%M%S\")\n",
|
| 67 |
+
"OUTPUT_DIR = Path(f\"/content/molforge_rl_runs/{RUN_NAME}\")\n",
|
| 68 |
+
"ADAPTER_SAVE_DIR = OUTPUT_DIR / \"adapters\"\n",
|
| 69 |
+
"PLOT_DIR = OUTPUT_DIR / \"plots\"\n",
|
| 70 |
+
"\n",
|
| 71 |
+
"OUTPUT_DIR.mkdir(parents=True, exist_ok=True)\n",
|
| 72 |
+
"PLOT_DIR.mkdir(parents=True, exist_ok=True)"
|
| 73 |
+
]
|
| 74 |
+
},
|
| 75 |
+
{
|
| 76 |
+
"cell_type": "markdown",
|
| 77 |
+
"metadata": {},
|
| 78 |
+
"source": [
|
| 79 |
+
"### Reward Function & OpenEnv Integration\n",
|
| 80 |
+
"We implement a custom reward function that wraps the native `MolForgeEnvironment`. \n",
|
| 81 |
+
"To prevent \"reward hacking\" (where the model endlessly farms `run_assay` for safe points), we apply targeted reward shaping."
|
| 82 |
+
]
|
| 83 |
+
},
|
| 84 |
+
{
|
| 85 |
+
"cell_type": "code",
|
| 86 |
+
"execution_count": null,
|
| 87 |
+
"metadata": {},
|
| 88 |
+
"outputs": [],
|
| 89 |
+
"source": [
|
| 90 |
+
"import json\n",
|
| 91 |
+
"from typing import Any, Dict, Tuple\n",
|
| 92 |
+
"from inference_common import (\n",
|
| 93 |
+
" MolForgeAction,\n",
|
| 94 |
+
" attach_reasoning_fields,\n",
|
| 95 |
+
" attach_team_messages,\n",
|
| 96 |
+
" extract_json,\n",
|
| 97 |
+
")\n",
|
| 98 |
+
"from server.molforge_environment import MolForgeEnvironment\n",
|
| 99 |
+
"from models import MolForgeState\n",
|
| 100 |
+
"\n",
|
| 101 |
+
"def replay_to_state(record: dict[str, Any]) -> MolForgeEnvironment:\n",
|
| 102 |
+
" \"\"\"Replays actions to reach a specific state.\"\"\"\n",
|
| 103 |
+
" env = MolForgeEnvironment()\n",
|
| 104 |
+
" # Set randomization and seed if provided\n",
|
| 105 |
+
" if record.get(\"randomized\"):\n",
|
| 106 |
+
" os.environ[\"MOLFORGE_TRAINING_RANDOMIZATION\"] = \"1\"\n",
|
| 107 |
+
" os.environ[\"MOLFORGE_RAND_SEED\"] = str(record.get(\"random_seed\", \"rl\"))\n",
|
| 108 |
+
" \n",
|
| 109 |
+
" observation = env.reset()\n",
|
| 110 |
+
" for action_payload in record.get(\"pre_actions\", []):\n",
|
| 111 |
+
" action = MolForgeAction(**action_payload)\n",
|
| 112 |
+
" observation = env.step(attach_team_messages(observation, attach_reasoning_fields(observation, action)))\n",
|
| 113 |
+
" if observation.done:\n",
|
| 114 |
+
" break\n",
|
| 115 |
+
" return env\n",
|
| 116 |
+
"\n",
|
| 117 |
+
"def evaluate_completion(prompt_str: str, completion_str: str, record: dict[str, Any]) -> Tuple[float, dict]:\n",
|
| 118 |
+
" diagnostics = {\"valid_json\": False}\n",
|
| 119 |
+
" try:\n",
|
| 120 |
+
" action_dict = extract_json(completion_str)\n",
|
| 121 |
+
" action = MolForgeAction(**action_dict)\n",
|
| 122 |
+
" except Exception:\n",
|
| 123 |
+
" return -1.2, diagnostics\n",
|
| 124 |
+
"\n",
|
| 125 |
+
" diagnostics[\"valid_json\"] = True\n",
|
| 126 |
+
" env = replay_to_state(record)\n",
|
| 127 |
+
" \n",
|
| 128 |
+
" # Step the OpenEnv environment\n",
|
| 129 |
+
" observation = env._build_observation(reward=0.0, done=False, reward_components=[])\n",
|
| 130 |
+
" action = attach_team_messages(observation, attach_reasoning_fields(observation, action))\n",
|
| 131 |
+
" next_observation = env.step(action)\n",
|
| 132 |
+
" \n",
|
| 133 |
+
" reward = float(next_observation.reward)\n",
|
| 134 |
+
" grader_scores = next_observation.metadata.get(\"terminal_grader_scores\", {})\n",
|
| 135 |
+
" \n",
|
| 136 |
+
" # Reward Shaping\n",
|
| 137 |
+
" if action.action_type == \"run_assay\" and reward > 0:\n",
|
| 138 |
+
" reward *= 0.25\n",
|
| 139 |
+
" elif action.action_type == \"submit\":\n",
|
| 140 |
+
" sub_score = float(grader_scores.get(\"submission_score\", 0.0))\n",
|
| 141 |
+
" if sub_score > 0.0: reward += sub_score * 3.0\n",
|
| 142 |
+
" elif action.action_type == \"edit\" and reward > 0:\n",
|
| 143 |
+
" reward *= 1.5\n",
|
| 144 |
+
"\n",
|
| 145 |
+
" diagnostics.update({\"action_type\": action.action_type, \"reward\": reward, \"done\": next_observation.done})\n",
|
| 146 |
+
" return reward, diagnostics\n",
|
| 147 |
+
"\n",
|
| 148 |
+
"def molforge_reward_func(prompts, completions, **kwargs) -> list[float]:\n",
|
| 149 |
+
" rewards = []\n",
|
| 150 |
+
" # When using dynamic dataset, columns like scenario_id, pre_actions etc are in kwargs\n",
|
| 151 |
+
" for i in range(len(completions)):\n",
|
| 152 |
+
" # Reconstruct the record from kwargs\n",
|
| 153 |
+
" record = {\n",
|
| 154 |
+
" \"pre_actions\": kwargs[\"record\"][i][\"pre_actions\"] if \"record\" in kwargs else [],\n",
|
| 155 |
+
" \"randomized\": True,\n",
|
| 156 |
+
" \"random_seed\": \"dynamic-rl\"\n",
|
| 157 |
+
" }\n",
|
| 158 |
+
" prompt_str = prompts[i][-1][\"content\"] if isinstance(prompts[i], list) else str(prompts[i])\n",
|
| 159 |
+
" completion_str = completions[i][0][\"content\"] if isinstance(completions[i], list) else str(completions[i])\n",
|
| 160 |
+
" reward, _ = evaluate_completion(prompt_str, completion_str, record)\n",
|
| 161 |
+
" rewards.append(reward)\n",
|
| 162 |
+
" return rewards\n"
|
| 163 |
+
]
|
| 164 |
+
},
|
| 165 |
+
{
|
| 166 |
+
"cell_type": "markdown",
|
| 167 |
+
"metadata": {},
|
| 168 |
+
"source": [
|
| 169 |
+
"### Model & Tokenizer Loading"
|
| 170 |
+
]
|
| 171 |
+
},
|
| 172 |
+
{
|
| 173 |
+
"cell_type": "code",
|
| 174 |
+
"execution_count": null,
|
| 175 |
+
"metadata": {},
|
| 176 |
+
"outputs": [],
|
| 177 |
+
"source": [
|
| 178 |
+
"from unsloth import FastLanguageModel\n",
|
| 179 |
+
"\n",
|
| 180 |
+
"# Set this to your SFT checkpoint Deployed to hugging face space \n",
|
| 181 |
+
"# SFT trained on only to mimic the response behavioiur of the model (structured responses visit the hf blog for more detailed explanation )\n",
|
| 182 |
+
"SFT_ADAPTER_PATH = \"Adhitya122/qwen3_5_2b_molforge_sft_v4\"\n",
|
| 183 |
+
"\n",
|
| 184 |
+
"print(\"Loading model and applying Unsloth optimizations...\")\n",
|
| 185 |
+
"model, tokenizer = FastLanguageModel.from_pretrained(\n",
|
| 186 |
+
" model_name=SFT_ADAPTER_PATH,\n",
|
| 187 |
+
" max_seq_length=MAX_SEQ_LENGTH,\n",
|
| 188 |
+
" dtype=None,\n",
|
| 189 |
+
" load_in_4bit=True,\n",
|
| 190 |
+
")\n",
|
| 191 |
+
"\n",
|
| 192 |
+
"# Enable fast training paths\n",
|
| 193 |
+
"FastLanguageModel.for_training(model)\n",
|
| 194 |
+
"\n",
|
| 195 |
+
"# Extract underlying tokenizer if it is wrapped in a vision processor\n",
|
| 196 |
+
"if hasattr(tokenizer, \"tokenizer\"):\n",
|
| 197 |
+
" tokenizer = tokenizer.tokenizer"
|
| 198 |
+
]
|
| 199 |
+
},
|
| 200 |
+
{
|
| 201 |
+
"cell_type": "markdown",
|
| 202 |
+
"metadata": {},
|
| 203 |
+
"source": [
|
| 204 |
+
"### GRPO Training Loop"
|
| 205 |
+
]
|
| 206 |
+
},
|
| 207 |
+
{
|
| 208 |
+
"cell_type": "code",
|
| 209 |
+
"execution_count": null,
|
| 210 |
+
"metadata": {},
|
| 211 |
+
"outputs": [],
|
| 212 |
+
"source": [
|
| 213 |
+
"from datasets import Dataset\n",
|
| 214 |
+
"from scripts.generate_sft_compact_policy_v4_dataset import compact_action_payload, COMPACT_ACTION_SYSTEM_PROMPT\n",
|
| 215 |
+
"from inference_common import heuristic_team_action\n",
|
| 216 |
+
"import random\n",
|
| 217 |
+
"\n",
|
| 218 |
+
"def build_dynamic_prompts(episodes=50, max_turns=5) -> Dataset:\n",
|
| 219 |
+
" \"\"\"Generates training prompts by playing the environment with a heuristic expert.\"\"\"\n",
|
| 220 |
+
" print(f\"Generating {episodes} episodes of dynamic prompts...\")\n",
|
| 221 |
+
" records = []\n",
|
| 222 |
+
" env = MolForgeEnvironment()\n",
|
| 223 |
+
" \n",
|
| 224 |
+
" for _ in range(episodes):\n",
|
| 225 |
+
" observation = env.reset()\n",
|
| 226 |
+
" pre_actions = []\n",
|
| 227 |
+
" \n",
|
| 228 |
+
" for _ in range(max_turns):\n",
|
| 229 |
+
" if observation.done:\n",
|
| 230 |
+
" break\n",
|
| 231 |
+
" \n",
|
| 232 |
+
" # Capture the current state as a prompt\n",
|
| 233 |
+
" prompt_payload = compact_action_payload(observation)\n",
|
| 234 |
+
" records.append({\n",
|
| 235 |
+
" \"prompt\": [\n",
|
| 236 |
+
" {\"role\": \"system\", \"content\": COMPACT_ACTION_SYSTEM_PROMPT},\n",
|
| 237 |
+
" {\"role\": \"user\", \"content\": json.dumps(prompt_payload)}\n",
|
| 238 |
+
" ],\n",
|
| 239 |
+
" \"record\": {\n",
|
| 240 |
+
" \"scenario_id\": observation.scenario_id,\n",
|
| 241 |
+
" \"difficulty\": observation.difficulty,\n",
|
| 242 |
+
" \"step_index\": observation.step_index,\n",
|
| 243 |
+
" \"pre_actions\": list(pre_actions),\n",
|
| 244 |
+
" \"randomized\": True,\n",
|
| 245 |
+
" \"random_seed\": \"dynamic-rl\"\n",
|
| 246 |
+
" }\n",
|
| 247 |
+
" })\n",
|
| 248 |
+
" \n",
|
| 249 |
+
" # Use expert to move to the next state\n",
|
| 250 |
+
" action = heuristic_team_action(observation)\n",
|
| 251 |
+
" observation = env.step(action)\n",
|
| 252 |
+
" pre_actions.append({\"action_type\": action.action_type, \"acting_role\": action.acting_role})\n",
|
| 253 |
+
" \n",
|
| 254 |
+
" random.shuffle(records)\n",
|
| 255 |
+
" return Dataset.from_list(records)\n",
|
| 256 |
+
"\n",
|
| 257 |
+
"# Generate the dataset dynamically (no .jsonl needed!)\n",
|
| 258 |
+
"dataset = build_dynamic_prompts(episodes=20, max_turns=6)\n",
|
| 259 |
+
"print(f\"Dynamic dataset created with {len(dataset)} prompt states.\")\n"
|
| 260 |
+
]
|
| 261 |
+
},
|
| 262 |
+
{
|
| 263 |
+
"cell_type": "code",
|
| 264 |
+
"execution_count": null,
|
| 265 |
+
"metadata": {},
|
| 266 |
+
"outputs": [],
|
| 267 |
+
"source": [
|
| 268 |
+
"from trl import GRPOConfig, GRPOTrainer\n",
|
| 269 |
+
"import inspect\n",
|
| 270 |
+
"\n",
|
| 271 |
+
"# Safe GRPO Configuration (detects supported arguments automatically)\n",
|
| 272 |
+
"config_kwargs = {\n",
|
| 273 |
+
" \"output_dir\": str(OUTPUT_DIR),\n",
|
| 274 |
+
" \"learning_rate\": LEARNING_RATE,\n",
|
| 275 |
+
" \"per_device_train_batch_size\": PER_DEVICE_BATCH,\n",
|
| 276 |
+
" \"gradient_accumulation_steps\": GRAD_ACCUM,\n",
|
| 277 |
+
" \"max_prompt_length\": MAX_PROMPT_LENGTH,\n",
|
| 278 |
+
" \"max_completion_length\": MAX_COMPLETION_LENGTH,\n",
|
| 279 |
+
" \"num_generations\": NUM_GENERATIONS,\n",
|
| 280 |
+
" \"max_steps\": RL_MAX_STEPS,\n",
|
| 281 |
+
" \"logging_steps\": 1,\n",
|
| 282 |
+
" \"save_steps\": 25,\n",
|
| 283 |
+
" \"bf16\": True,\n",
|
| 284 |
+
" \"report_to\": \"none\",\n",
|
| 285 |
+
" \"log_completions\": True,\n",
|
| 286 |
+
"}\n",
|
| 287 |
+
"\n",
|
| 288 |
+
"# Filter arguments to only pass what the current library version supports\n",
|
| 289 |
+
"supported_params = inspect.signature(GRPOConfig.__init__).parameters\n",
|
| 290 |
+
"filtered_kwargs = {k: v for k, v in config_kwargs.items() if k in supported_params}\n",
|
| 291 |
+
"\n",
|
| 292 |
+
"training_args = GRPOConfig(**filtered_kwargs)\n",
|
| 293 |
+
"\n",
|
| 294 |
+
"# Initialize Trainer\n",
|
| 295 |
+
"trainer = GRPOTrainer(\n",
|
| 296 |
+
" model=model,\n",
|
| 297 |
+
" reward_funcs=molforge_reward_func,\n",
|
| 298 |
+
" args=training_args,\n",
|
| 299 |
+
" train_dataset=dataset,\n",
|
| 300 |
+
" processing_class=tokenizer,\n",
|
| 301 |
+
")\n",
|
| 302 |
+
"\n",
|
| 303 |
+
"print(\"Starting GRPO Training...\")\n",
|
| 304 |
+
"trainer.train()\n",
|
| 305 |
+
"\n",
|
| 306 |
+
"print(f\"Training complete. Saving adapters to {ADAPTER_SAVE_DIR}\")\n",
|
| 307 |
+
"trainer.save_model(str(ADAPTER_SAVE_DIR))\n",
|
| 308 |
+
"tokenizer.save_pretrained(str(ADAPTER_SAVE_DIR))\n"
|
| 309 |
+
]
|
| 310 |
+
},
|
| 311 |
+
{
|
| 312 |
+
"cell_type": "code",
|
| 313 |
+
"execution_count": null,
|
| 314 |
+
"metadata": {},
|
| 315 |
+
"outputs": [],
|
| 316 |
+
"source": [
|
| 317 |
+
"import matplotlib.pyplot as plt\n",
|
| 318 |
+
"import pandas as pd\n",
|
| 319 |
+
"\n",
|
| 320 |
+
"# Extract metrics from trainer log history\n",
|
| 321 |
+
"log_history = trainer.state.log_history\n",
|
| 322 |
+
"df = pd.DataFrame(log_history)\n",
|
| 323 |
+
"\n",
|
| 324 |
+
"print(\"Generating plots...\")\n",
|
| 325 |
+
"\n",
|
| 326 |
+
"if \"loss\" in df.columns:\n",
|
| 327 |
+
" plt.figure(figsize=(10, 5))\n",
|
| 328 |
+
" df_loss = df.dropna(subset=[\"loss\"])\n",
|
| 329 |
+
" plt.plot(df_loss[\"step\"], df_loss[\"loss\"], label=\"Loss\", color=\"blue\")\n",
|
| 330 |
+
" plt.title(\"Training Loss\")\n",
|
| 331 |
+
" plt.grid(True)\n",
|
| 332 |
+
" plt.show()\n",
|
| 333 |
+
"\n",
|
| 334 |
+
"if \"reward\" in df.columns:\n",
|
| 335 |
+
" plt.figure(figsize=(10, 5))\n",
|
| 336 |
+
" df_reward = df.dropna(subset=[\"reward\"])\n",
|
| 337 |
+
" plt.plot(df_reward[\"step\"], df_reward[\"reward\"], label=\"Reward\", color=\"green\")\n",
|
| 338 |
+
" plt.title(\"Reward Curve\")\n",
|
| 339 |
+
" plt.grid(True)\n",
|
| 340 |
+
" plt.show()\n",
|
| 341 |
+
"\n",
|
| 342 |
+
"import shutil\n",
|
| 343 |
+
"from google.colab import files\n",
|
| 344 |
+
"\n",
|
| 345 |
+
"print(f\"Zipping results from {OUTPUT_DIR}...\")\n",
|
| 346 |
+
"zip_filename = f\"{RUN_NAME}_results\"\n",
|
| 347 |
+
"shutil.make_archive(zip_filename, \"zip\", OUTPUT_DIR)\n",
|
| 348 |
+
"\n",
|
| 349 |
+
"print(f\"Downloading {zip_filename}.zip...\")\n",
|
| 350 |
+
"files.download(f\"{zip_filename}.zip\")\n"
|
| 351 |
+
]
|
| 352 |
+
}
|
| 353 |
+
],
|
| 354 |
+
"metadata": {
|
| 355 |
+
"colab": {
|
| 356 |
+
"provenance": []
|
| 357 |
+
},
|
| 358 |
+
"kernelspec": {
|
| 359 |
+
"display_name": "Python 3",
|
| 360 |
+
"name": "python3"
|
| 361 |
+
},
|
| 362 |
+
"language_info": {
|
| 363 |
+
"name": "python"
|
| 364 |
+
}
|
| 365 |
+
},
|
| 366 |
+
"nbformat": 4,
|
| 367 |
+
"nbformat_minor": 0
|
| 368 |
+
}
|