
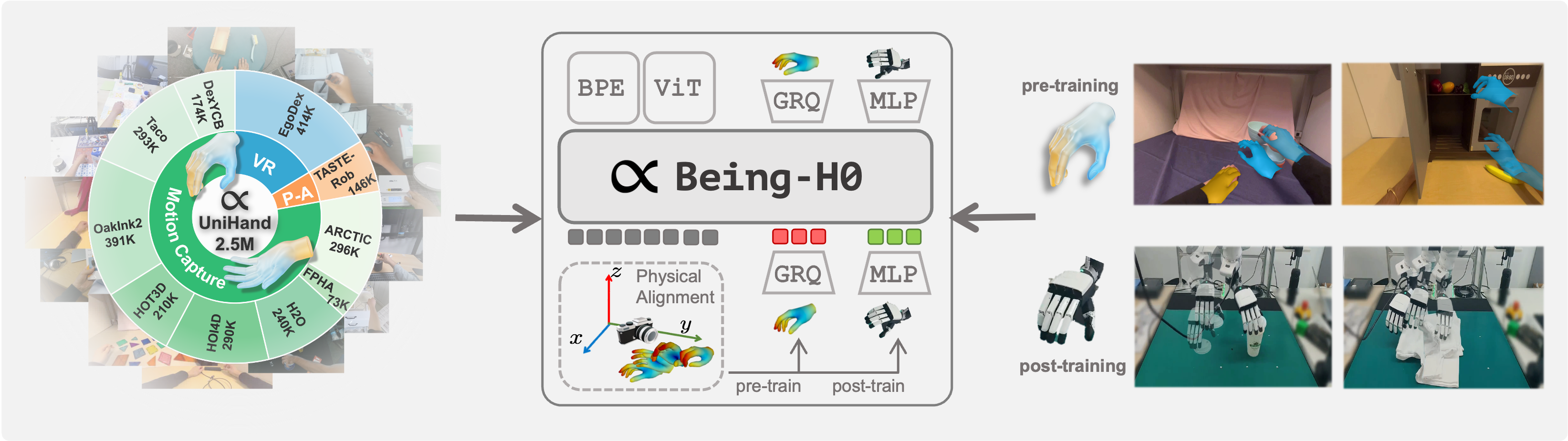
We introduce **Being-H0**, the first dexterous Vision-Language-Action model pretrained from large-scale human videos via explicit hand motion modeling. ## News - **[2025-07-21]**: We publish **Being-H0**! Check our paper [here](https://arxiv.org/abs/2507.15597). ## Code & Model We will release the code and model weights soon! ## Citation If you find our work useful, please consider citing us and give a star to our repository! 🌟🌟🌟 **Being-H0** ```bibtex @article{beingbeyond2025beingh0, title={Being-H0: Vision-Language-Action Pretraining from Large-Scale Human Videos}, author={Luo, Hao and Feng, Yicheng and Zhang, Wanpeng and Zheng, Sipeng and Wang, Ye and Yuan, Haoqi and Liu, Jiazheng and Xu, Chaoyi and Jin, Qin and Lu, Zongqing}, journal={arXiv preprint arXiv:2507.15597}, year={2025} } ```