
Add files using upload-large-folder tool
Browse filesThis view is limited to 50 files because it contains too many changes. See raw diff
- .github/workflows/cpu_unit_tests.yml +90 -0
- .github/workflows/e2e_fully_async_policy.yml +177 -0
- .github/workflows/sanity.yml +109 -0
- docs/README_vllm0.7.md +73 -0
- docs/advance/fully_async.md +525 -0
- docs/algo/dapo.md +187 -0
- docs/ascend_tutorial/ascend_sglang_quick_start.rst +113 -0
- docs/examples/multi_modal_example.rst +45 -0
- docs/hybrid_flow.rst +266 -0
- docs/index.rst +206 -0
- docs/perf/verl_profiler_system.md +36 -0
- docs/sglang_multiturn/search_tool_example.rst +264 -0
- docs/start/more_resources.rst +7 -0
- docs/start/multinode.rst +821 -0
- docs/start/ray_debug_tutorial.rst +96 -0
- docs/workers/model_engine.rst +125 -0
- docs/workers/ray_trainer.rst +241 -0
- docs/workers/sglang_worker.rst +237 -0
- examples/data_preprocess/preprocess_search_r1_dataset.py +178 -0
- examples/grpo_trainer/outputs/2026-01-24/22-29-52/.hydra/config.yaml +610 -0
- examples/grpo_trainer/outputs/2026-01-24/22-48-33/.hydra/hydra.yaml +212 -0
- examples/grpo_trainer/outputs/2026-01-24/22-51-12/.hydra/config.yaml +610 -0
- examples/grpo_trainer/outputs/2026-01-24/22-51-12/.hydra/overrides.yaml +44 -0
- examples/grpo_trainer/outputs/2026-01-24/22-52-15/.hydra/overrides.yaml +44 -0
- examples/grpo_trainer/outputs/2026-01-24/22-53-56/.hydra/hydra.yaml +212 -0
- examples/grpo_trainer/outputs/2026-01-24/22-53-56/.hydra/overrides.yaml +45 -0
- examples/grpo_trainer/outputs/2026-01-24/22-56-04/.hydra/config.yaml +610 -0
- examples/grpo_trainer/outputs/2026-01-24/22-56-04/.hydra/hydra.yaml +212 -0
- examples/grpo_trainer/outputs/2026-01-24/22-59-57/.hydra/config.yaml +610 -0
- examples/grpo_trainer/outputs/2026-01-24/22-59-57/.hydra/overrides.yaml +45 -0
- examples/grpo_trainer/outputs/2026-01-24/23-39-12/.hydra/hydra.yaml +213 -0
- examples/grpo_trainer/outputs/2026-01-24/23-39-12/main_ppo.log +0 -0
- examples/grpo_trainer/outputs/2026-01-24/23-57-09/main_ppo.log +0 -0
- examples/grpo_trainer/outputs/2026-01-24/23-59-39/main_ppo.log +0 -0
- examples/grpo_trainer/outputs/2026-01-25/12-11-49/.hydra/overrides.yaml +47 -0
- examples/grpo_trainer/outputs/2026-01-25/12-26-13/.hydra/config.yaml +610 -0
- examples/grpo_trainer/outputs/2026-01-25/12-30-14/.hydra/overrides.yaml +41 -0
- examples/grpo_trainer/outputs/2026-01-25/12-31-47/.hydra/hydra.yaml +208 -0
- examples/grpo_trainer/outputs/2026-01-25/12-35-51/.hydra/hydra.yaml +213 -0
- examples/grpo_trainer/outputs/2026-01-25/12-36-58/.hydra/hydra.yaml +212 -0
- examples/grpo_trainer/outputs/2026-01-25/12-38-17/.hydra/overrides.yaml +45 -0
- examples/grpo_trainer/outputs/2026-01-25/12-39-19/.hydra/config.yaml +610 -0
- examples/grpo_trainer/outputs/2026-01-26/16-49-41/.hydra/config.yaml +610 -0
- examples/grpo_trainer/outputs/2026-01-26/16-49-41/.hydra/overrides.yaml +45 -0
- examples/grpo_trainer/outputs/2026-01-26/17-05-09/.hydra/config.yaml +610 -0
- examples/grpo_trainer/outputs/2026-01-26/17-05-09/.hydra/overrides.yaml +45 -0
- examples/grpo_trainer/outputs/2026-01-26/17-07-54/.hydra/config.yaml +610 -0
- examples/grpo_trainer/outputs/2026-01-26/17-07-54/.hydra/overrides.yaml +45 -0
- examples/grpo_trainer/outputs/2026-01-26/17-28-29/.hydra/config.yaml +610 -0
- examples/grpo_trainer/outputs/2026-01-26/17-28-29/.hydra/overrides.yaml +45 -0
.github/workflows/cpu_unit_tests.yml
ADDED
|
@@ -0,0 +1,90 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# # Tests layout
|
| 2 |
+
|
| 3 |
+
# Each folder under tests/ corresponds to a test category for a sub-namespace in verl. For instance:
|
| 4 |
+
# - `tests/trainer` for testing functionality related to `verl/trainer`
|
| 5 |
+
# - `tests/models` for testing functionality related to `verl/models`
|
| 6 |
+
# - ...
|
| 7 |
+
|
| 8 |
+
# There are a few folders with `special_` prefix, created for special purposes:
|
| 9 |
+
# - `special_distributed`: unit tests that must run with multiple GPUs
|
| 10 |
+
# - `special_e2e`: end-to-end tests with training/generation scripts
|
| 11 |
+
# - `special_npu`: tests for NPUs
|
| 12 |
+
# - `special_sanity`: a suite of quick sanity tests
|
| 13 |
+
# - `special_standalone`: a set of test that are designed to run in dedicated environments
|
| 14 |
+
|
| 15 |
+
# Accelerators for tests
|
| 16 |
+
# - By default tests are run with GPU available, except for the ones under `special_npu`, and any test script whose name ends with `on_cpu.py`.
|
| 17 |
+
# - For test scripts with `on_cpu.py` name suffix would be tested on CPU resources in linux environment.
|
| 18 |
+
|
| 19 |
+
# # Workflow layout
|
| 20 |
+
|
| 21 |
+
# All CI tests are configured by yaml files in `.github/workflows/`. Here's an overview of all test configs:
|
| 22 |
+
# 1. A list of always triggered CPU sanity tests: `check-pr-title.yml`, `secrets_scan.yml`, `check-pr-title,yml`, `pre-commit.yml`, `doc.yml`
|
| 23 |
+
# 2. Some heavy multi-GPU unit tests, such as `model.yml`, `vllm.yml`, `sgl.yml`
|
| 24 |
+
# 3. End-to-end tests: `e2e_*.yml`
|
| 25 |
+
# 4. Unit tests
|
| 26 |
+
# - `cpu_unit_tests.yml`, run pytest on all scripts with file name pattern `tests/**/test_*_on_cpu.py`
|
| 27 |
+
# - `gpu_unit_tests.yml`, run pytest on all scripts with file without the `on_cpu.py` suffix.
|
| 28 |
+
# - Since cpu/gpu unit tests by default runs all tests under `tests`, please make sure tests are manually excluded in them when
|
| 29 |
+
# - new workflow yaml is added to `.github/workflows`
|
| 30 |
+
# - new tests are added to workflow mentioned in 2.
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
name: cpu_unit_tests
|
| 34 |
+
|
| 35 |
+
on:
|
| 36 |
+
# Trigger the workflow on push or pull request,
|
| 37 |
+
# but only for the main branch
|
| 38 |
+
push:
|
| 39 |
+
branches:
|
| 40 |
+
- main
|
| 41 |
+
- v0.*
|
| 42 |
+
pull_request:
|
| 43 |
+
branches:
|
| 44 |
+
- main
|
| 45 |
+
- v0.*
|
| 46 |
+
paths:
|
| 47 |
+
- "**/*.py"
|
| 48 |
+
- .github/workflows/cpu_unit_tests.yml
|
| 49 |
+
- "!recipe/**/*.py"
|
| 50 |
+
|
| 51 |
+
# Cancel jobs on the same ref if a new one is triggered
|
| 52 |
+
concurrency:
|
| 53 |
+
group: ${{ github.workflow }}-${{ github.ref }}
|
| 54 |
+
cancel-in-progress: ${{ github.ref != 'refs/heads/main' }}
|
| 55 |
+
|
| 56 |
+
# Declare permissions just read content.
|
| 57 |
+
permissions:
|
| 58 |
+
contents: read
|
| 59 |
+
|
| 60 |
+
jobs:
|
| 61 |
+
cpu_unit_tests:
|
| 62 |
+
if: github.repository_owner == 'volcengine'
|
| 63 |
+
runs-on: [L20x8]
|
| 64 |
+
timeout-minutes: 20 # Increase this timeout value as needed
|
| 65 |
+
env:
|
| 66 |
+
HTTP_PROXY: ${{ secrets.PROXY_HTTP }}
|
| 67 |
+
HTTPS_PROXY: ${{ secrets.PROXY_HTTPS }}
|
| 68 |
+
NO_PROXY: "localhost,127.0.0.1,hf-mirror.com"
|
| 69 |
+
HF_ENDPOINT: "https://hf-mirror.com"
|
| 70 |
+
HF_HUB_ENABLE_HF_TRANSFER: "0" # This is more stable
|
| 71 |
+
TORCH_COMPILE_DISABLE: 1
|
| 72 |
+
TORCHINDUCTOR_DISABLE: 1
|
| 73 |
+
container:
|
| 74 |
+
image: verl-ci-cn-beijing.cr.volces.com/verlai/verl:vllm011.dev7
|
| 75 |
+
steps:
|
| 76 |
+
- uses: actions/checkout@11bd71901bbe5b1630ceea73d27597364c9af683 # v4.2.2
|
| 77 |
+
with:
|
| 78 |
+
fetch-depth: 0
|
| 79 |
+
- name: Install the current repository
|
| 80 |
+
run: |
|
| 81 |
+
pip install -e .[test,geo]
|
| 82 |
+
- name: Download datasets
|
| 83 |
+
run: |
|
| 84 |
+
huggingface-cli download verl-team/gsm8k-v0.4.1 --repo-type dataset --local-dir ~/verl-data/gsm8k
|
| 85 |
+
python3 examples/data_preprocess/geo3k.py
|
| 86 |
+
- name: Running CPU unit tests
|
| 87 |
+
run: |
|
| 88 |
+
echo '[pytest]' > pytest.ini
|
| 89 |
+
echo 'python_files = *_on_cpu.py' >> pytest.ini
|
| 90 |
+
pytest -s -x --asyncio-mode=auto tests/
|
.github/workflows/e2e_fully_async_policy.yml
ADDED
|
@@ -0,0 +1,177 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# # Tests layout
|
| 2 |
+
|
| 3 |
+
# Each folder under tests/ corresponds to a test category for a sub-namespace in verl. For instance:
|
| 4 |
+
# - `tests/trainer` for testing functionality related to `verl/trainer`
|
| 5 |
+
# - `tests/models` for testing functionality related to `verl/models`
|
| 6 |
+
# - ...
|
| 7 |
+
|
| 8 |
+
# There are a few folders with `special_` prefix, created for special purposes:
|
| 9 |
+
# - `special_distributed`: unit tests that must run with multiple GPUs
|
| 10 |
+
# - `special_e2e`: end-to-end tests with training/generation scripts
|
| 11 |
+
# - `special_npu`: tests for NPUs
|
| 12 |
+
# - `special_sanity`: a suite of quick sanity tests
|
| 13 |
+
# - `special_standalone`: a set of test that are designed to run in dedicated environments
|
| 14 |
+
|
| 15 |
+
# Accelerators for tests
|
| 16 |
+
# - By default tests are run with GPU available, except for the ones under `special_npu`, and any test script whose name ends with `on_cpu.py`.
|
| 17 |
+
# - For test scripts with `on_cpu.py` name suffix would be tested on CPU resources in linux environment.
|
| 18 |
+
|
| 19 |
+
# # Workflow layout
|
| 20 |
+
|
| 21 |
+
# All CI tests are configured by yaml files in `.github/workflows/`. Here's an overview of all test configs:
|
| 22 |
+
# 1. A list of always triggered CPU sanity tests: `check-pr-title.yml`, `secrets_scan.yml`, `check-pr-title,yml`, `pre-commit.yml`, `doc.yml`
|
| 23 |
+
# 2. Some heavy multi-GPU unit tests, such as `model.yml`, `vllm.yml`, `sgl.yml`
|
| 24 |
+
# 3. End-to-end tests: `e2e_*.yml`
|
| 25 |
+
# 4. Unit tests
|
| 26 |
+
# - `cpu_unit_tests.yml`, run pytest on all scripts with file name pattern `tests/**/test_*_on_cpu.py`
|
| 27 |
+
# - `gpu_unit_tests.yml`, run pytest on all scripts with file without the `on_cpu.py` suffix.
|
| 28 |
+
# - Since cpu/gpu unit tests by default runs all tests under `tests`, please make sure tests are manually excluded in them when
|
| 29 |
+
# - new workflow yaml is added to `.github/workflows`
|
| 30 |
+
# - new tests are added to workflow mentioned in 2.
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
name: e2e_fully_async_policy
|
| 34 |
+
|
| 35 |
+
on:
|
| 36 |
+
# Trigger the workflow on push or pull request,
|
| 37 |
+
# but only for the main branch
|
| 38 |
+
# For push, for now only anti-patterns are specified so it is more conservative
|
| 39 |
+
# and achieves higher coverage.
|
| 40 |
+
push:
|
| 41 |
+
branches:
|
| 42 |
+
- main
|
| 43 |
+
- v0.*
|
| 44 |
+
paths:
|
| 45 |
+
- "**/*.py"
|
| 46 |
+
- "!**/*.md"
|
| 47 |
+
- "!**/*.sh"
|
| 48 |
+
# Other entrypoints
|
| 49 |
+
- "!examples/*trainer*"
|
| 50 |
+
- "!tests/**"
|
| 51 |
+
- "!verl/trainer/main_*.py"
|
| 52 |
+
- "!verl/trainer/fsdp_sft_trainer.py"
|
| 53 |
+
- "!recipe/**"
|
| 54 |
+
- "recipe/fully_async_policy/**"
|
| 55 |
+
pull_request:
|
| 56 |
+
branches:
|
| 57 |
+
- main
|
| 58 |
+
- v0.*
|
| 59 |
+
paths:
|
| 60 |
+
- "**/*.py"
|
| 61 |
+
- "!**/*.md"
|
| 62 |
+
- "!**/*.sh"
|
| 63 |
+
# Other entrypoints
|
| 64 |
+
- "!examples/**"
|
| 65 |
+
- "!tests/**"
|
| 66 |
+
- "!verl/trainer/main_*.py"
|
| 67 |
+
- "!verl/trainer/fsdp_sft_trainer.py"
|
| 68 |
+
# Other recipes
|
| 69 |
+
- "!recipe/**"
|
| 70 |
+
# Home
|
| 71 |
+
- "recipe/fully_async_policy"
|
| 72 |
+
# Entrypoints
|
| 73 |
+
- ".github/workflows/e2e_fully_async_policy.yml"
|
| 74 |
+
- "examples/data_preprocess/gsm8k.py"
|
| 75 |
+
- "tests/special_e2e/run_fully_async_policy.sh"
|
| 76 |
+
|
| 77 |
+
# Cancel jobs on the same ref if a new one is triggered
|
| 78 |
+
concurrency:
|
| 79 |
+
group: ${{ github.workflow }}-${{ github.ref }}
|
| 80 |
+
cancel-in-progress: ${{ github.ref != 'refs/heads/main' }}
|
| 81 |
+
|
| 82 |
+
# Declare permissions just read content.
|
| 83 |
+
permissions:
|
| 84 |
+
contents: read
|
| 85 |
+
|
| 86 |
+
env:
|
| 87 |
+
IMAGE: "verl-ci-cn-beijing.cr.volces.com/verlai/verl:vllm011.dev7"
|
| 88 |
+
DYNAMIC_RUNNER_ENDPOINT: "https://sd10g3clalm04ug7alq90.apigateway-cn-beijing.volceapi.com/runner"
|
| 89 |
+
TRANSFORMERS_VERSION: "4.56.2"
|
| 90 |
+
|
| 91 |
+
jobs:
|
| 92 |
+
setup:
|
| 93 |
+
if: github.repository_owner == 'volcengine'
|
| 94 |
+
runs-on: ubuntu-latest
|
| 95 |
+
outputs:
|
| 96 |
+
runner-label: ${{ steps.create-runner.outputs.runner-label }}
|
| 97 |
+
mlp-task-id: ${{ steps.create-runner.outputs.mlp-task-id }}
|
| 98 |
+
steps:
|
| 99 |
+
- uses: actions/checkout@v4
|
| 100 |
+
- id: create-runner
|
| 101 |
+
uses: volcengine/vemlp-github-runner@v1
|
| 102 |
+
with:
|
| 103 |
+
mode: "create"
|
| 104 |
+
faas-url: "${{ env.DYNAMIC_RUNNER_ENDPOINT }}"
|
| 105 |
+
mlp-image: "${{ env.IMAGE }}"
|
| 106 |
+
|
| 107 |
+
# Test FSDP2 strategy
|
| 108 |
+
e2e_fully_async_policy_fsdp2:
|
| 109 |
+
needs: setup
|
| 110 |
+
runs-on: [ "${{ needs.setup.outputs.runner-label || 'L20x8' }}" ]
|
| 111 |
+
timeout-minutes: 10 # Increase timeout for async training
|
| 112 |
+
env:
|
| 113 |
+
HTTP_PROXY: ${{ secrets.PROXY_HTTP }}
|
| 114 |
+
HTTPS_PROXY: ${{ secrets.PROXY_HTTPS }}
|
| 115 |
+
NO_PROXY: "localhost,127.0.0.1,hf-mirror.com"
|
| 116 |
+
HF_ENDPOINT: "https://hf-mirror.com"
|
| 117 |
+
HF_HUB_ENABLE_HF_TRANSFER: "0" # This is more stable
|
| 118 |
+
ACTOR_STRATEGY: "fsdp2"
|
| 119 |
+
steps:
|
| 120 |
+
- uses: actions/checkout@11bd71901bbe5b1630ceea73d27597364c9af683 # v4.2.2
|
| 121 |
+
with:
|
| 122 |
+
fetch-depth: 0
|
| 123 |
+
- name: Install the current repository
|
| 124 |
+
run: |
|
| 125 |
+
pip3 install --no-deps -e .[test,gpu]
|
| 126 |
+
pip3 install transformers==$TRANSFORMERS_VERSION
|
| 127 |
+
- name: Prepare GSM8K dataset
|
| 128 |
+
run: |
|
| 129 |
+
python3 examples/data_preprocess/gsm8k.py --local_dataset_path ${HOME}/models/hf_data/gsm8k
|
| 130 |
+
- name: Running the E2E test with fully_async_policy algorithm (FSDP2)
|
| 131 |
+
run: |
|
| 132 |
+
ray stop --force
|
| 133 |
+
bash tests/special_e2e/run_fully_async_policy.sh
|
| 134 |
+
|
| 135 |
+
# Test Megatron strategy
|
| 136 |
+
e2e_fully_async_policy_megatron:
|
| 137 |
+
needs: setup
|
| 138 |
+
runs-on: [ "${{ needs.setup.outputs.runner-label || 'L20x8' }}" ]
|
| 139 |
+
timeout-minutes: 10 # Increase timeout for async training
|
| 140 |
+
env:
|
| 141 |
+
HTTP_PROXY: ${{ secrets.PROXY_HTTP }}
|
| 142 |
+
HTTPS_PROXY: ${{ secrets.PROXY_HTTPS }}
|
| 143 |
+
NO_PROXY: "localhost,127.0.0.1,hf-mirror.com"
|
| 144 |
+
HF_ENDPOINT: "https://hf-mirror.com"
|
| 145 |
+
HF_HUB_ENABLE_HF_TRANSFER: "0" # This is more stable
|
| 146 |
+
ACTOR_STRATEGY: "megatron"
|
| 147 |
+
steps:
|
| 148 |
+
- uses: actions/checkout@11bd71901bbe5b1630ceea73d27597364c9af683 # v4.2.2
|
| 149 |
+
with:
|
| 150 |
+
fetch-depth: 0
|
| 151 |
+
- name: Install the current repository
|
| 152 |
+
run: |
|
| 153 |
+
pip3 install --no-deps -e .[test,gpu]
|
| 154 |
+
pip3 install transformers==$TRANSFORMERS_VERSION
|
| 155 |
+
- name: Prepare GSM8K dataset
|
| 156 |
+
run: |
|
| 157 |
+
python3 examples/data_preprocess/gsm8k.py --local_dataset_path ${HOME}/models/hf_data/gsm8k
|
| 158 |
+
- name: Running the E2E test with fully_async_policy algorithm (Megatron)
|
| 159 |
+
run: |
|
| 160 |
+
ray stop --force
|
| 161 |
+
bash tests/special_e2e/run_fully_async_policy.sh
|
| 162 |
+
|
| 163 |
+
cleanup:
|
| 164 |
+
runs-on: ubuntu-latest
|
| 165 |
+
needs:
|
| 166 |
+
[
|
| 167 |
+
setup,
|
| 168 |
+
e2e_fully_async_policy_fsdp2
|
| 169 |
+
]
|
| 170 |
+
if: always()
|
| 171 |
+
steps:
|
| 172 |
+
- id: destroy-runner
|
| 173 |
+
uses: volcengine/vemlp-github-runner@v1
|
| 174 |
+
with:
|
| 175 |
+
mode: "destroy"
|
| 176 |
+
faas-url: "${{ env.DYNAMIC_RUNNER_ENDPOINT }}"
|
| 177 |
+
mlp-task-id: "${{ needs.setup.outputs.mlp-task-id }}"
|
.github/workflows/sanity.yml
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# # Tests layout
|
| 2 |
+
|
| 3 |
+
# Each folder under tests/ corresponds to a test category for a sub-namespace in verl. For instance:
|
| 4 |
+
# - `tests/trainer` for testing functionality related to `verl/trainer`
|
| 5 |
+
# - `tests/models` for testing functionality related to `verl/models`
|
| 6 |
+
# - ...
|
| 7 |
+
|
| 8 |
+
# There are a few folders with `special_` prefix, created for special purposes:
|
| 9 |
+
# - `special_distributed`: unit tests that must run with multiple GPUs
|
| 10 |
+
# - `special_e2e`: end-to-end tests with training/generation scripts
|
| 11 |
+
# - `special_npu`: tests for NPUs
|
| 12 |
+
# - `special_sanity`: a suite of quick sanity tests
|
| 13 |
+
# - `special_standalone`: a set of test that are designed to run in dedicated environments
|
| 14 |
+
|
| 15 |
+
# Accelerators for tests
|
| 16 |
+
# - By default tests are run with GPU available, except for the ones under `special_npu`, and any test script whose name ends with `on_cpu.py`.
|
| 17 |
+
# - For test scripts with `on_cpu.py` name suffix would be tested on CPU resources in linux environment.
|
| 18 |
+
|
| 19 |
+
# # Workflow layout
|
| 20 |
+
|
| 21 |
+
# All CI tests are configured by yaml files in `.github/workflows/`. Here's an overview of all test configs:
|
| 22 |
+
# 1. A list of always triggered CPU sanity tests: `check-pr-title.yml`, `secrets_scan.yml`, `check-pr-title,yml`, `pre-commit.yml`, `doc.yml`
|
| 23 |
+
# 2. Some heavy multi-GPU unit tests, such as `model.yml`, `vllm.yml`, `sgl.yml`
|
| 24 |
+
# 3. End-to-end tests: `e2e_*.yml`
|
| 25 |
+
# 4. Unit tests
|
| 26 |
+
# - `cpu_unit_tests.yml`, run pytest on all scripts with file name pattern `tests/**/test_*_on_cpu.py`
|
| 27 |
+
# - `gpu_unit_tests.yml`, run pytest on all scripts with file without the `on_cpu.py` suffix.
|
| 28 |
+
# - Since cpu/gpu unit tests by default runs all tests under `tests`, please make sure tests are manually excluded in them when
|
| 29 |
+
# - new workflow yaml is added to `.github/workflows`
|
| 30 |
+
# - new tests are added to workflow mentioned in 2.
|
| 31 |
+
# name: Check PR Title
|
| 32 |
+
|
| 33 |
+
name: sanity
|
| 34 |
+
|
| 35 |
+
on:
|
| 36 |
+
# Trigger the workflow on push or pull request,
|
| 37 |
+
# but only for the main branch
|
| 38 |
+
push:
|
| 39 |
+
branches:
|
| 40 |
+
- main
|
| 41 |
+
- v0.*
|
| 42 |
+
pull_request:
|
| 43 |
+
branches:
|
| 44 |
+
- main
|
| 45 |
+
- v0.*
|
| 46 |
+
paths:
|
| 47 |
+
- "**/*.py"
|
| 48 |
+
- .github/workflows/sanity.yml
|
| 49 |
+
- "tests/special_sanity/**"
|
| 50 |
+
|
| 51 |
+
# Cancel jobs on the same ref if a new one is triggered
|
| 52 |
+
concurrency:
|
| 53 |
+
group: ${{ github.workflow }}-${{ github.ref }}
|
| 54 |
+
cancel-in-progress: ${{ github.ref != 'refs/heads/main' }}
|
| 55 |
+
|
| 56 |
+
# Declare permissions just read content.
|
| 57 |
+
permissions:
|
| 58 |
+
contents: read
|
| 59 |
+
|
| 60 |
+
jobs:
|
| 61 |
+
sanity:
|
| 62 |
+
runs-on: ubuntu-latest
|
| 63 |
+
timeout-minutes: 5 # Increase this timeout value as needed
|
| 64 |
+
strategy:
|
| 65 |
+
matrix:
|
| 66 |
+
python-version: ["3.10"]
|
| 67 |
+
steps:
|
| 68 |
+
- uses: actions/checkout@11bd71901bbe5b1630ceea73d27597364c9af683 # v4.2.2
|
| 69 |
+
- name: Set up Python ${{ matrix.python-version }}
|
| 70 |
+
uses: actions/setup-python@0b93645e9fea7318ecaed2b359559ac225c90a2b # v5.3.0
|
| 71 |
+
with:
|
| 72 |
+
python-version: ${{ matrix.python-version }}
|
| 73 |
+
- name: Install the current repository
|
| 74 |
+
run: |
|
| 75 |
+
pip3 install torch torchvision --index-url https://download.pytorch.org/whl/cpu
|
| 76 |
+
pip3 install -r requirements.txt
|
| 77 |
+
pip install -e .[test]
|
| 78 |
+
- name: Run sanity test
|
| 79 |
+
run: |
|
| 80 |
+
pytest -s -x tests/special_sanity
|
| 81 |
+
- name: Run license test
|
| 82 |
+
run: |
|
| 83 |
+
python3 tests/special_sanity/check_license.py --directories .
|
| 84 |
+
- name: Assert naming convention
|
| 85 |
+
run: |
|
| 86 |
+
if grep -rIn --exclude-dir=.git --exclude-dir=.github --exclude-dir=venv --exclude-dir=__pycache__ 'veRL' .; then
|
| 87 |
+
echo "Please use verl instead of veRL in the codebase"
|
| 88 |
+
exit 1
|
| 89 |
+
fi
|
| 90 |
+
- name: Assert SGLang naming convention
|
| 91 |
+
run: |
|
| 92 |
+
if grep -rIn --exclude-dir=.git --exclude-dir=.github --exclude-dir=venv --exclude-dir=__pycache__ -E 'Sglang|sgLang|sglAng|sglaNg|sglanG' .; then
|
| 93 |
+
echo "Please use SGLang or sglang as the formal name of SGLang rollout engine"
|
| 94 |
+
exit 1
|
| 95 |
+
fi
|
| 96 |
+
- name: Validate test folder structure
|
| 97 |
+
run: python3 tests/special_sanity/validate_structure.py
|
| 98 |
+
- name: Assert documentation requirement for functions
|
| 99 |
+
run: python3 tests/special_sanity/validate_imported_docs.py
|
| 100 |
+
- name: Assert device api usage in verl/recipe
|
| 101 |
+
run: python3 tests/special_sanity/check_device_api_usage.py --directory ./recipe
|
| 102 |
+
- name: Assert device api usage in verl/verl
|
| 103 |
+
run: python3 tests/special_sanity/check_device_api_usage.py --directory ./verl
|
| 104 |
+
- name: Assert documentation time info
|
| 105 |
+
run: python3 tests/special_sanity/check_docs_time_info.py
|
| 106 |
+
- name: Check docstrings for specified files
|
| 107 |
+
run: python3 tests/special_sanity/check_docstrings.py
|
| 108 |
+
- name: Check DataProto for specified folders
|
| 109 |
+
run: python3 tests/special_sanity/check_dataproto_usage.py -d ./verl/workers/engine
|
docs/README_vllm0.7.md
ADDED
|
@@ -0,0 +1,73 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Upgrading to vllm >= 0.7
|
| 2 |
+
|
| 3 |
+
Note: verl+vllm 0.8.3 is now stable. Please see ``docs/README_vllm0.8.md`` for upgrade guide.
|
| 4 |
+
|
| 5 |
+
## Installation
|
| 6 |
+
|
| 7 |
+
Note: At time of writing, verl+vllm 0.7.x supports **FSDP** for training and **vLLM** for rollout.
|
| 8 |
+
|
| 9 |
+
```
|
| 10 |
+
# Create the conda environment
|
| 11 |
+
conda create -n verl python==3.10
|
| 12 |
+
conda activate verl
|
| 13 |
+
|
| 14 |
+
# Install verl
|
| 15 |
+
git clone https://github.com/volcengine/verl.git
|
| 16 |
+
cd verl
|
| 17 |
+
pip3 install -e .
|
| 18 |
+
|
| 19 |
+
# Install the latest stable version of vLLM
|
| 20 |
+
pip3 install vllm==0.7.3
|
| 21 |
+
|
| 22 |
+
# Install flash-attn
|
| 23 |
+
pip3 install flash-attn --no-build-isolation
|
| 24 |
+
|
| 25 |
+
```
|
| 26 |
+
|
| 27 |
+
Note that if you are installing lower versions of vLLM (0.7.0, 0.7.1, 0.7.2), you need to make some tiny patches manually on vllm (/path/to/site-packages/vllm after installation) after the above steps:
|
| 28 |
+
|
| 29 |
+
- vllm/distributed/parallel_state.py: Remove the assertion below:
|
| 30 |
+
|
| 31 |
+
```
|
| 32 |
+
if (world_size
|
| 33 |
+
!= tensor_model_parallel_size * pipeline_model_parallel_size):
|
| 34 |
+
raise RuntimeError(
|
| 35 |
+
f"world_size ({world_size}) is not equal to "
|
| 36 |
+
f"tensor_model_parallel_size ({tensor_model_parallel_size}) x "
|
| 37 |
+
f"pipeline_model_parallel_size ({pipeline_model_parallel_size})")
|
| 38 |
+
|
| 39 |
+
```
|
| 40 |
+
|
| 41 |
+
- vllm/executor/uniproc_executor.py: change `local_rank = rank` to `local_rank = int(os.environ["LOCAL_RANK"])`
|
| 42 |
+
- vllm/model_executor/model_loader/weight_utils.py: remove the `torch.cuda.empty_cache()` in `pt_weights_iterator`
|
| 43 |
+
|
| 44 |
+
## Features
|
| 45 |
+
|
| 46 |
+
### Use cuda graph
|
| 47 |
+
|
| 48 |
+
After installation, examples using FSDP as training backends can be used. By default, the `enforce_eager` is set to True, which disables the cuda graph. To enjoy cuda graphs and the sleep mode of vLLM>=0.7, add the following lines to the bash script:
|
| 49 |
+
|
| 50 |
+
```
|
| 51 |
+
actor_rollout_ref.rollout.enforce_eager=False \
|
| 52 |
+
actor_rollout_ref.rollout.free_cache_engine=True \
|
| 53 |
+
|
| 54 |
+
```
|
| 55 |
+
|
| 56 |
+
For a typical job like examples/ppo_trainer/run_qwen2-7b_seq_balance.sh, the rollout generation time is 85 seconds with vLLM0.7.0. By enabling the cudagraph, the generation duration is further reduced to 62 seconds.
|
| 57 |
+
|
| 58 |
+
**Note:** Currently, if the `n` is greater than 1 in `SamplingParams` in vLLM>=0.7, there is a potential performance issue on the stability of rollout generation time (Some iterations would see generation time bursts) using vLLM's V0 Engine.
|
| 59 |
+
|
| 60 |
+
### Use vLLM V1 Engine
|
| 61 |
+
|
| 62 |
+
Using the vLLM V1 engine can avoid instability issues and achieve additional performance improvements. To use the V1 engine, you can first uninstall the previously installed vLLM and then follow the steps below to install the newer version.
|
| 63 |
+
|
| 64 |
+
```
|
| 65 |
+
git clone https://github.com/vllm-project/vllm.git
|
| 66 |
+
cd vllm
|
| 67 |
+
git checkout 2275784
|
| 68 |
+
sed -i "903a\ data_parallel_size = world_size // pipeline_model_parallel_size // tensor_model_parallel_size" ./vllm/distributed/parallel_state.py
|
| 69 |
+
VLLM_USE_PRECOMPILED=1 pip install --editable .
|
| 70 |
+
```
|
| 71 |
+
|
| 72 |
+
Then you can enable the V1 engine by setting `export VLLM_USE_V1=1`. In some benchmark tests, the V1 engine demonstrates a 1.5x speed improvement over the vLLM V0 engine.
|
| 73 |
+
The stable support of the vLLM V1 engine is available on verl main.
|
docs/advance/fully_async.md
ADDED
|
@@ -0,0 +1,525 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Recipe: Fully Async Policy Trainer
|
| 2 |
+
|
| 3 |
+
**Author:** `https://github.com/meituan-search`
|
| 4 |
+
|
| 5 |
+
Last updated: 10/18/2025.
|
| 6 |
+
|
| 7 |
+
This document introduces a fully asynchronous PPO training system that completely decouples the Trainer and Rollouter,
|
| 8 |
+
supporting asynchronous sample generation and training.
|
| 9 |
+
Under this system, we achieved a 2.35x-2.67x performance improvement when training the Qwen2.5-7B model with 128 GPUs,
|
| 10 |
+
without significantly affecting the results.
|
| 11 |
+
|
| 12 |
+
## Introduction
|
| 13 |
+
|
| 14 |
+
### Background
|
| 15 |
+
|
| 16 |
+
The separated rollout and train architecture, compared to the colocate architecture, can allocate resources more
|
| 17 |
+
flexibly and design more flexible training logic, thereby addressing issues such as low GPU utilization and training
|
| 18 |
+
efficiency caused by long-tail problems.
|
| 19 |
+
The one_step_off_policy alleviates the problem of long rollout times and achieves some gains in training efficiency by
|
| 20 |
+
designing a separated architecture and performing asynchronous training between rollout and train for one round.
|
| 21 |
+
However, it forcibly uses data from one round of asynchronous training, which is not flexible enough and cannot
|
| 22 |
+
completely eliminate the impact of long-tail on training efficiency.
|
| 23 |
+
In other frameworks such as AReaL, Magistral, StreamRL, and AsyncFlow, asynchronous training and streaming training have
|
| 24 |
+
been implemented based on the separated architecture and have achieved gains.
|
| 25 |
+
We borrow from their methods and implemented them in VERL. The fully_async_policy supports asynchronous, streaming, and
|
| 26 |
+
partial
|
| 27 |
+
rollout training.
|
| 28 |
+
By reasonably setting parameters such as resource allocation and parameter synchronization frequency, fully_async_policy
|
| 29 |
+
can significantly improve training efficiency.
|
| 30 |
+
|
| 31 |
+
> Magistral https://arxiv.org/abs/2506.10910
|
| 32 |
+
>
|
| 33 |
+
> AReaL: A Large-Scale Asynchronous Reinforcement Learning System for Language
|
| 34 |
+
> Reasoning https://arxiv.org/abs/2505.24298
|
| 35 |
+
>
|
| 36 |
+
> StreamRL: Scalable, Heterogeneous, and Elastic RL for LLMs with Disaggregated Stream
|
| 37 |
+
> Generation https://arxiv.org/abs/2504.15930
|
| 38 |
+
>
|
| 39 |
+
> AsyncFlow: An Asynchronous Streaming RL Framework for Efficient LLM Post-Training https://arxiv.org/abs/2507.01663
|
| 40 |
+
>
|
| 41 |
+
|
| 42 |
+
### Core Contributions
|
| 43 |
+
|
| 44 |
+
* **Resource Isolation**: Unlike using hybrid_engine, Rollouter and Trainer use separate computing resources and need to
|
| 45 |
+
specify the resources they occupy separately.
|
| 46 |
+
* **Parallel Generation and Training**: While the Trainer is training, the Rollouter is generating new samples.
|
| 47 |
+
* **Multi-step Asynchronous**: Compared to one step off policy, it supports asynchronous settings from 0.x steps to
|
| 48 |
+
multiple steps, making the asynchronous solution more flexible.
|
| 49 |
+
* **NCCL Parameter Synchronization**: Uses NCCL communication primitives for parameter communication between Rollouter
|
| 50 |
+
and Trainer.
|
| 51 |
+
* **Stream Inference and Training**: Rollouter generates data sample by sample, and data transmission uses a single
|
| 52 |
+
sample as the minimum transmission unit.
|
| 53 |
+
* **Asynchronous Training and Freshness Control**: By setting the parameter async_training.staleness_threshold, it
|
| 54 |
+
supports training with samples generated by old parameters.
|
| 55 |
+
* **PartialRollout**: The Rollouter's inference process supports partial rollout logic. During parameter
|
| 56 |
+
synchronization, by adding `sleep() and resume()` logic, it
|
| 57 |
+
saves samples from ongoing rollouts and continues using them in the next rollout, reducing the time spent waiting for
|
| 58 |
+
ongoing tasks to finish during parameter synchronization.
|
| 59 |
+
|
| 60 |
+
Currently, the supported usage mode is megatron/fsdp+vllm. vllm must use the server mode based on AgentLoop.
|
| 61 |
+
|
| 62 |
+
## Design
|
| 63 |
+
|
| 64 |
+
The overall architecture of fully_async_policy is shown in the figure below. fully_async_policy mainly consists of four
|
| 65 |
+
parts: Rollouter, MessageQueue, Trainer, and ParameterSynchronizer.
|
| 66 |
+
|
| 67 |
+

|
| 69 |
+
|
| 70 |
+
1. Rollouter generates sequences sample by sample and puts the generated samples into the MessageQueue, with the
|
| 71 |
+
production speed controlled by freshness.
|
| 72 |
+
2. MessageQueue is used to temporarily store samples generated by Rollouter.
|
| 73 |
+
3. Trainer fetches samples from MessageQueue sample by sample. After fetching `require_batches*ppo_mini_batch_size`
|
| 74 |
+
samples, it will perform training. After training for async_training.trigger_parameter_sync_step rounds, it triggers
|
| 75 |
+
a parameter synchronization with Rollouter.
|
| 76 |
+
4. ParameterSynchronizer implements the NCCL synchronous parameter synchronization capability.
|
| 77 |
+
|
| 78 |
+
The source of benefits compared to the base scheme lies in the fact that in the colocate case, using more resources for
|
| 79 |
+
rollout cannot solve the idleness caused by long-tail samples.
|
| 80 |
+
After we perform resource isolation, the time for rollout and train may be longer than before (because fewer resources
|
| 81 |
+
are used),
|
| 82 |
+
but the overlap in their time consumption reduces the end-to-end time consumption.
|
| 83 |
+
|
| 84 |
+

|
| 86 |
+
|
| 87 |
+
## Usage
|
| 88 |
+
|
| 89 |
+
### Parameter Description
|
| 90 |
+
|
| 91 |
+
| super params | implication |
|
| 92 |
+
|-----------------------------------------------|------------------------------------------------------------------------------------------------|
|
| 93 |
+
| `trainer.nnodes` | Number of nodes for Trainer |
|
| 94 |
+
| `trainer.n_gpus_per_node` | Number of GPUs per node for Trainer |
|
| 95 |
+
| `rollout.nnodes` | Number of nodes for Rollouter |
|
| 96 |
+
| `rollout.n_gpus_per_node` | Number of GPUs per node for Rollouter |
|
| 97 |
+
| `data.train_batch_size` | In the fully async strategy, this value is not effective (default is 0) |
|
| 98 |
+
| `data.gen_batch_size` | In the fully async strategy, uses streaming sample production logic (default is 1) |
|
| 99 |
+
| `rollout.total_rollout_steps` | Total number of rollout samples |
|
| 100 |
+
| `rollout.test_freq` | How many times Rollouter updates parameters before performing a validation |
|
| 101 |
+
| `actor_rollout_ref.actor.ppo_mini_batch_size` | The ppo_mini_batch_size is a global num across all workers/gpus |
|
| 102 |
+
| `async_training.require_batches` | Number of ppo_mini_batch_size that FullyAsyncTrainer fetches at once |
|
| 103 |
+
| `async_training.trigger_parameter_sync_step` | Indicates how many local updates FullyAsyncTrainer performs before a parameter synchronization |
|
| 104 |
+
| `async_training.staleness_threshold` | Freshness control |
|
| 105 |
+
| `async_training.partial_rollout` | Whether to perform partial_rollout |
|
| 106 |
+
| `async_training.use_rollout_log_probs` | Use log_probs generated by rollout |
|
| 107 |
+
| `async_training.compute_prox_log_prob` | Whether to compute log_prob using the training model's parameters during the training phase. | |
|
| 108 |
+
|
| 109 |
+
**Further Explanation:**
|
| 110 |
+
|
| 111 |
+
* `rollout.total_rollout_steps`
|
| 112 |
+
|
| 113 |
+
Compared to colocate, the quantity can be aligned by multiplying train_batch_size and step:
|
| 114 |
+
`rollout.total_rollout_steps = data.train_batch_size * step`.
|
| 115 |
+
|
| 116 |
+
* `async_training.trigger_parameter_sync_step`
|
| 117 |
+
|
| 118 |
+
In the fully async strategy, it indicates how many local updates the Trainer performs (i.e., how many times it fetches
|
| 119 |
+
`require_batches * ppo_mini_batch_size` samples) before a parameter synchronization with Rollouter.
|
| 120 |
+
Between every two parameter synchronizations between Rollouter and Trainer, the Trainer will process
|
| 121 |
+
`trigger_parameter_sync_step* require_batches*ppo_mini_batch_size` samples.
|
| 122 |
+
To fairly compare speed with colocate, trigger_parameter_sync_step should be set to
|
| 123 |
+
`data.train_batch_size / (require_batches * ppo_mini_batch_size)`.
|
| 124 |
+
|
| 125 |
+
* `async_training.staleness_threshold`
|
| 126 |
+
|
| 127 |
+
In the fully async strategy, it indicates the maximum proportion of stale samples allowed to be used.
|
| 128 |
+
|
| 129 |
+
* staleness_threshold=0, indicates synchronous training.
|
| 130 |
+
Rollouter will generate a fixed number of samples between two parameter updates, the sample count is:
|
| 131 |
+
$$rollout\_num = (trigger\_parameter\_sync\_step*require\_batches*ppo\_mini\_batch\_size)$$
|
| 132 |
+
* staleness_threshold>0, indicates asynchronous training, can be set to a decimal for more flexible asynchronous
|
| 133 |
+
calls.
|
| 134 |
+
Rollouter will generate at most the following number of samples between two parameter updates:
|
| 135 |
+
$$rollout\_num = (1+staleness\_threshold)*(trigger\_parameter\_sync\_step*require\_batches*ppo\_mini\_batch\_size) - num\_staleness\_sample $$
|
| 136 |
+
|
| 137 |
+
num_staleness_sample represents the number of stale samples generated in excess during the last rollout.
|
| 138 |
+
|
| 139 |
+
Since it's a streaming system, rollout continues to generate and trainer continues to consume. If rollouter is slower,
|
| 140 |
+
trainer will trigger parameter synchronization earlier, and rollouter will not actually produce rollout_num samples.
|
| 141 |
+
When rollout is fast enough, setting staleness_threshold to 1 is basically equivalent to one_step_off policy.
|
| 142 |
+
To avoid too many expired samples affecting training accuracy, it is recommended to set this value to less than 1.
|
| 143 |
+
|
| 144 |
+
* `async_training.partial_rollout`
|
| 145 |
+
|
| 146 |
+
partial_rollout only actually takes effect when staleness_threshold>0.
|
| 147 |
+
|
| 148 |
+
* `async_training.use_rollout_log_probs`
|
| 149 |
+
|
| 150 |
+
In reinforcement learning algorithms, log_probs have implicit correlations with parameter versions and tokens. Due to
|
| 151 |
+
the settings of algorithms like PPO/GRPO/DAPO, when calculating importance sampling,
|
| 152 |
+
old_log_prob must use the log_probs corresponding to the rollout parameters and tokens to ensure algorithm
|
| 153 |
+
correctness. In the fully
|
| 154 |
+
async strategy, we default to old_log_prob being calculated by rollout rather than by trainer.
|
| 155 |
+
|
| 156 |
+
* `async_training.require_batches`
|
| 157 |
+
|
| 158 |
+
In streaming training, require_batches should be set to 1, indicating that training is performed after producing
|
| 159 |
+
enough ppo_mini_batch_size samples.
|
| 160 |
+
In actual testing, we found that if fewer samples are issued at once, due to the order of data distribution, it can
|
| 161 |
+
cause training instability and longer response lengths.
|
| 162 |
+
Here, we additionally provide require_batches for streaming distribution and control the number of samples
|
| 163 |
+
participating in training at once.
|
| 164 |
+
|
| 165 |
+
* `async_training.compute_prox_log_prob` (experimental)
|
| 166 |
+
|
| 167 |
+
During the training process, we observed that metrics and response lengths may become unstable in the later
|
| 168 |
+
stages of training. To mitigate this issue, we can use
|
| 169 |
+
the [Rollout Importance Sampling](https://verl.readthedocs.io/en/latest/advance/rollout_is.html)
|
| 170 |
+
technique for importance sampling. To utilize Rollout Importance Sampling, we need to compute log_prob using
|
| 171 |
+
the training engine, which requires enabling this switch.
|
| 172 |
+
Additionally, when compute_prox_log_prob and Rollout Importance Sampling are enabled under mode d
|
| 173 |
+
(async stream pipeline with partial rollout), our implementation approximates `Areal's Decoupled PPO`.
|
| 174 |
+
|
| 175 |
+
### Supported Modes
|
| 176 |
+
|
| 177 |
+
1. on policy pipeline:
|
| 178 |
+
1. **trigger_parameter_sync_step=1, staleness_threshold=0**
|
| 179 |
+
2. Rollouter produces `require_batches*ppo_mini_batch_size` samples at once, Trainer fetches these samples for
|
| 180 |
+
training, and after training completes, Trainer and Rollouter perform a parameter synchronization;
|
| 181 |
+
3. During the rollout phase, if there are long-tail samples but few rollout samples, shorter samples cannot fill
|
| 182 |
+
idle resources, causing some resource waste.
|
| 183 |
+
4. As shown in figure a;
|
| 184 |
+
|
| 185 |
+
2. stream off policy pipeline:
|
| 186 |
+
1. **trigger_parameter_sync_step>1, staleness_threshold=0**
|
| 187 |
+
2. Synchronous streaming training will be performed. Rollouter produces
|
| 188 |
+
`require_batches*ppo_mini_batch_size*trigger_parameter_sync_step` samples at once, Trainer performs a local
|
| 189 |
+
training every time it fetches `require_batches*ppo_mini_batch_size` samples, and after training
|
| 190 |
+
trigger_parameter_sync_step times, Trainer and Rollouter perform a parameter synchronization;
|
| 191 |
+
3. Compared to a, since more samples are generated at once, resource idleness will be lower.
|
| 192 |
+
4. In one step training, there will be two periods of resource idleness: when fetching the first batch of samples,
|
| 193 |
+
train waits for `require_batches*ppo_mini_batch_size` samples to be produced, and during the last parameter
|
| 194 |
+
update, rollout waits for training to complete.
|
| 195 |
+
5. As shown in figure b;
|
| 196 |
+
|
| 197 |
+
3. async stream pipeline with stale samples:
|
| 198 |
+
1. **trigger_parameter_sync_step>=1, staleness_threshold>0, partial_rollout=False**
|
| 199 |
+
2. After each parameter update, Rollouter will plan to produce at most rollout_num samples (in practice, the number
|
| 200 |
+
of samples generated may be less than this value depending on rollout speed).
|
| 201 |
+
3. If the rollout process is relatively fast, Rollouter will generate some additional samples num_stale_samples
|
| 202 |
+
before parameter synchronization for immediate use by Trainer after synchronization.
|
| 203 |
+
When triggering parameter synchronization, if Rollouter has ongoing tasks, it will wait for the tasks to complete
|
| 204 |
+
and not add new tasks;
|
| 205 |
+
4. Compared to b, except for the first step training, subsequent training will not have the time to wait for the
|
| 206 |
+
first batch rollout to finish, but will have the time to wait for active tasks to finish.
|
| 207 |
+
5. As shown in figure c;
|
| 208 |
+
|
| 209 |
+
4. async stream pipeline with partial rollout:
|
| 210 |
+
1. **trigger_parameter_sync_step>=1, staleness_threshold>0, partial_rollout=True**
|
| 211 |
+
2. Compared to c, when triggering parameter synchronization, if Rollouter has samples being produced, it will
|
| 212 |
+
interrupt the rollout process and perform parameter synchronization. The interrupted samples will continue to be
|
| 213 |
+
generated after synchronization. This reduces the time to wait for active tasks to finish.
|
| 214 |
+
3. As shown in figure d;
|
| 215 |
+
|
| 216 |
+

|
| 218 |
+
|
| 219 |
+
### Key Metrics
|
| 220 |
+
|
| 221 |
+
| metrics | implication |
|
| 222 |
+
|------------------------------------------------|--------------------------------------------------------------------------------------------------------|
|
| 223 |
+
| `trainer/idle_ratio` | Trainer idle rate |
|
| 224 |
+
| `rollouter/idle_ratio` | Rollouter idle rate |
|
| 225 |
+
| `fully_async/count/stale_samples_processed` | Total number of old samples used in training |
|
| 226 |
+
| `fully_async/count/stale_trajectory_processed` | Total number of old trajectories used in training (one sample produces rollout.n trajectories) |
|
| 227 |
+
| `fully_async/partial/total_partial_num` | Number of partial samples processed by Trainer between two trigger_parameter_sync_step |
|
| 228 |
+
| `fully_async/partial/partial_ratio` | Ratio of partial samples processed by Trainer between two trigger_parameter_sync_step |
|
| 229 |
+
| `fully_async/partial/max_partial_span` | Maximum parameter span of partial samples processed by Trainer between two trigger_parameter_sync_step |
|
| 230 |
+
|
| 231 |
+
### Parameter Tuning Recommendations
|
| 232 |
+
|
| 233 |
+
* Resource Allocation and Adjustment:
|
| 234 |
+
* Reasonable resource allocation is the prerequisite for achieving good training efficiency. The ideal resource
|
| 235 |
+
allocation should make the rollout time and train time close, thereby minimizing pipeline bubbles in the entire
|
| 236 |
+
training process,
|
| 237 |
+
avoiding resource idleness, and ensuring Trainer does not use old samples. In real training scenarios, resource
|
| 238 |
+
allocation can be adjusted based on the idle time of rollout and train during actual training,
|
| 239 |
+
which can be obtained from rollouter/idle_ratio and trainer/idle_ratio. If rollouter/idle_ratio is high and
|
| 240 |
+
trainer/idle_ratio is low,
|
| 241 |
+
Trainer resources should be increased and Rollouter resources should be reduced, and vice versa.
|
| 242 |
+
|
| 243 |
+
* Key Parameters:
|
| 244 |
+
* staleness_threshold: Setting it too high will cause more old samples to be used, affecting model performance. It
|
| 245 |
+
is recommended to set it to less than 1.
|
| 246 |
+
* require_batches: The closer to 1, the closer to a pure streaming process, the smaller the training bubbles, and
|
| 247 |
+
the faster the acceleration effect that can be achieved in terms of speed, but it will affect the order of sample
|
| 248 |
+
processing;
|
| 249 |
+
* trigger_parameter_sync_step: The smaller the setting, the closer to on policy, but it will cause frequent
|
| 250 |
+
parameter synchronization. Long-tail samples waste resources that cannot be filled by short samples, resulting in
|
| 251 |
+
low resource utilization.
|
| 252 |
+
The larger the setting, the higher the computational efficiency, but the accuracy will be affected by off policy.
|
| 253 |
+
* rollout.test_freq: It will occupy Rollouter resources and is not recommended to be set too small.
|
| 254 |
+
|
| 255 |
+
* Mode Selection: By adjusting different parameters, the Fully Async architecture supports optimization acceleration at
|
| 256 |
+
different levels, suitable for tasks in different scenarios.
|
| 257 |
+
* For small-scale tasks that need to ensure training stability and on-policy nature, and have low speed
|
| 258 |
+
requirements, the on policy pipeline mode (Mode 1) can be tried.
|
| 259 |
+
* For scenarios that need to improve training throughput but are sensitive to staleness, the stream off policy
|
| 260 |
+
pipeline mode can be tried. That is, by
|
| 261 |
+
setting trigger_parameter_sync_step>1 to improve training efficiency, but still maintaining the synchronization
|
| 262 |
+
mechanism (staleness_threshold=0) (Mode 2).
|
| 263 |
+
* For large-scale tasks with high training speed requirements and can tolerate a certain degree of off-policy and
|
| 264 |
+
staleness, setting staleness_threshold>
|
| 265 |
+
0 and partial_rollout=True can improve training efficiency, using the async stream pipeline mode (Mode 3 or 4).
|
| 266 |
+
|
| 267 |
+
### Quick Start
|
| 268 |
+
|
| 269 |
+
```shell
|
| 270 |
+
rollout_mode="async"
|
| 271 |
+
rollout_name="vllm" # sglang or vllm
|
| 272 |
+
if [ "$rollout_mode" = "async" ]; then
|
| 273 |
+
export VLLM_USE_V1=1
|
| 274 |
+
return_raw_chat="True"
|
| 275 |
+
fi
|
| 276 |
+
|
| 277 |
+
train_prompt_bsz=0
|
| 278 |
+
gen_prompt_bsz=1
|
| 279 |
+
n_resp_per_prompt=16
|
| 280 |
+
train_prompt_mini_bsz=32
|
| 281 |
+
total_rollout_steps=$(((512*400)))
|
| 282 |
+
test_freq=10
|
| 283 |
+
staleness_threshold=0
|
| 284 |
+
trigger_parameter_sync_step=16
|
| 285 |
+
partial_rollout=False
|
| 286 |
+
|
| 287 |
+
|
| 288 |
+
python -m recipe.fully_async_policy.fully_async_main \
|
| 289 |
+
train_batch_size=${train_prompt_bsz} \
|
| 290 |
+
data.gen_batch_size=${gen_prompt_bsz} \
|
| 291 |
+
data.return_raw_chat=${return_raw_chat} \
|
| 292 |
+
actor_rollout_ref.rollout.n=${n_resp_per_prompt} \
|
| 293 |
+
actor_rollout_ref.actor.strategy=fsdp2 \
|
| 294 |
+
critic.strategy=fsdp2 \
|
| 295 |
+
actor_rollout_ref.hybrid_engine=False \
|
| 296 |
+
actor_rollout_ref.actor.use_dynamic_bsz=${use_dynamic_bsz} \
|
| 297 |
+
actor_rollout_ref.ref.log_prob_use_dynamic_bsz=${use_dynamic_bsz} \
|
| 298 |
+
actor_rollout_ref.rollout.log_prob_use_dynamic_bsz=${use_dynamic_bsz} \
|
| 299 |
+
actor_rollout_ref.rollout.name=${rollout_name} \
|
| 300 |
+
actor_rollout_ref.rollout.mode=${rollout_mode} \
|
| 301 |
+
actor_rollout_ref.rollout.calculate_log_probs=True \
|
| 302 |
+
trainer.nnodes="${NNODES_TRAIN}" \
|
| 303 |
+
trainer.n_gpus_per_node="${NGPUS_PER_NODE}" \
|
| 304 |
+
rollout.nnodes="${NNODES_ROLLOUT}" \
|
| 305 |
+
rollout.n_gpus_per_node="${NGPUS_PER_NODE}" \
|
| 306 |
+
rollout.total_rollout_steps="${total_rollout_steps}" \
|
| 307 |
+
rollout.test_freq="${test_freq}" \
|
| 308 |
+
async_training.staleness_threshold="${staleness_threshold}" \
|
| 309 |
+
async_training.trigger_parameter_sync_step="${trigger_parameter_sync_step}" \
|
| 310 |
+
async_training.partial_rollout="${partial_rollout}"
|
| 311 |
+
```
|
| 312 |
+
|
| 313 |
+
## Experiments
|
| 314 |
+
|
| 315 |
+
### Asynchronous Training on 7B Model
|
| 316 |
+
|
| 317 |
+
We used Qwen2.5-Math-7B to verify the benefits of the fully async strategy under long candidates and multiple resources.
|
| 318 |
+
Using the `async stream pipeline with stale samples` strategy, we achieved about 2x performance improvement on 32 cards,
|
| 319 |
+
64 cards, and 128 cards without significantly affecting experimental results.
|
| 320 |
+
|
| 321 |
+
* Machine: H20
|
| 322 |
+
* Model: Qwen2.5-Math-7B
|
| 323 |
+
* Rollout length: max_response_length FSDP2: 28K tokens;
|
| 324 |
+
* Algorithm: DAPO
|
| 325 |
+
* Dataset: TRAIN_FILE: dapo-math-17k.parquet TEST_FILE: aime-2024.parquet
|
| 326 |
+
* Engine: vllm+FSDP2
|
| 327 |
+
* rollout.n: 16
|
| 328 |
+
* ppo_mini_batch_size: 32
|
| 329 |
+
* test_freq: 20
|
| 330 |
+
|
| 331 |
+
* colocate sync:
|
| 332 |
+
* step: 400
|
| 333 |
+
* train_batch_size: 512
|
| 334 |
+
|
| 335 |
+
* fully_async_policy
|
| 336 |
+
* total_rollout_steps: 512*400
|
| 337 |
+
* require_batches: 4
|
| 338 |
+
* trigger_parameter_sync_step: 4
|
| 339 |
+
* staleness_threshold: 0.5
|
| 340 |
+
* partial_rollout: True
|
| 341 |
+
|
| 342 |
+
| training mode | resource allocation | step | gen | old_log_prob | update_actor | total time<br>100 step | total time<br>200 step | total time<br>300 step | total time<br>400 step | acc/mean@1 |
|
| 343 |
+
|:--------------------:|:---------------------:|:--------:|:--------:|:--------------:|:---------------:|:------------------------:|:------------------------:|:------------------------:|:------------------------:|:-------------------------------:|
|
| 344 |
+
| colocate sync | 32 | 790.10 | 357.41 | 107.71 | 269.80 | 13h 44m | 1d 3h 43m | 2d 9h 22m | 3d 17h 5m | max: 0.3313<br>last: 0.2448 |
|
| 345 |
+
| fully_async_policy | 16:16 | 294.77 | 21.26 | \ | 313.81 | 7h 58m<br>(1.72x) | 16h 21m<br>(1.70x) | 1d 0h 53m<br>(2.31x) | 1d 9h 26m<br>(2.66x) | max: 0.3302<br>last: 0.2333 |
|
| 346 |
+
| colocate sync | 64 | 365.28 | 150.72 | 70.26 | 133.41 | 10h 22m | 20h 45m | 1d 7h 6m | 1d 17h 32m | max: 0.3365<br>last: 0.2333 |
|
| 347 |
+
| fully_async_policy | 32:32 | 189.26 | 28.46 | \ | 156.98 | 4h 57m<br>(2.09x) | 10h 14m<br>(2.03x) | 16h 58m<br>(1.83x) | 21h 40m<br>(1.92x) | max: 0.3677<br>last: 0.3406 |
|
| 348 |
+
| colocate sync | 128 | 356.30 | 177.85 | 53.92 | 113.81 | 8h 36m | 17h 56m | 1d 5h 6m | 1d 16h 48m | max: 0.3573<br>last: 0.2958 |
|
| 349 |
+
| fully_async_policy | 64:64 | 150.63 | 33.14 | \ | 113.16 | 3h 13m<br>(2.67x) | 6h 46m<br>(2.65x) | 10h 53m<br>(2.67x) | 17h 22m<br>(2.35x) | max: 0.3521<br>last: 0.3094 |
|
| 350 |
+
|
| 351 |
+
> source data: https://wandb.ai/hou-zg-meituan/fully-async-policy-colocate_async?nw=nwuserhouzg
|
| 352 |
+
|
| 353 |
+
### 128-card 7B Asynchronous Mode Experiment
|
| 354 |
+
|
| 355 |
+
We used Qwen2.5-Math-7B to verify the effects of various modes supported by fully async.
|
| 356 |
+
We can see that the benefit brought by streaming is approximately 1.6x, and after combining staleness and
|
| 357 |
+
partial_rollout, the benefit reaches 2.35x.
|
| 358 |
+
|
| 359 |
+
| mode | step | gen | old_log_prob | update_actor | total time<br>100 step | total time<br>200 step | total time<br>300 step | total time<br>400 step | acc/mean@1 |
|
| 360 |
+
|:-------------------------------------------------------------------------------------------------------:|:--------:|:--------:|:--------------:|:--------------:|:------------------------:|:------------------------:|:------------------------:|:------------------------:|:------------------------------:|
|
| 361 |
+
| colocate sync | 356.30 | 177.85 | 53.92 | 113.81 | 8h 36m | 17h 56m | 1d 5h 6m | 1d 16h 48m | max: 0.3573<br>last: 0.2958 |
|
| 362 |
+
| `stream off policy pipeline`<br>(+fully async: trigger_parameter_sync_step= 4,<br>require_batches= 4) | 231.34 | 128.47 | \ | 98.77 | 4h 25m | 9h 41m | 15h 2m | 1d 1h 53m | max: 0.2844<br>last: 0.2604 |
|
| 363 |
+
| `async stream pipeline with stale samples`<br>(+staleness_threshold=0.5) | | | | | | | | | |
|
| 364 |
+
| `async stream pipeline with partial rollout`<br>(+partial_rollout=True) | 150.63 | 33.14 | \ | 113.16 | 3h 13m | 6h 46m | 10h 53m | 17h 22m | max: 0.3521<br>last: 0.3094 |
|
| 365 |
+
|
| 366 |
+
> source data: https://wandb.ai/hou-zg-meituan/fully-async-policy-stream_stale_partial?nw=nwuserhouzg
|
| 367 |
+
|
| 368 |
+
### 128-card Stale Ablation Experiment
|
| 369 |
+
|
| 370 |
+
Under the `async stream pipeline with partial rollout` mode, we verified the impact of staleness settings on training
|
| 371 |
+
efficiency.
|
| 372 |
+
We found that the larger the staleness, the more obvious the final gains.
|
| 373 |
+
We also noticed that the times for staleness values of 0.3 and 0.5 are quite close, because as the training steps
|
| 374 |
+
increase, the response length changes significantly, causing training instability.
|
| 375 |
+
Further analysis and optimization are needed for this issue.
|
| 376 |
+
|
| 377 |
+
| staleness_threshold | step | gen | old_log_prob | update_actor | total time<br>100 step | total time<br>200 step | total time<br>300 step | total time<br>400 step | acc/mean@1 |
|
| 378 |
+
|:---------------------:|:--------:|:--------:|:--------------:|:--------------:|:------------------------:|:------------------------:|:------------------------:|:------------------------:|:-----------------------------:|
|
| 379 |
+
| 0 | 231.34 | 128.47 | \ | 98.77 | 4h 25m | 9h 41m | 15h 2m | 1d 1h 53m | max: 0.2844<br>last: 0.2604 |
|
| 380 |
+
| 0.1 | 171.30 | 58.17 | \ | 109.12 | 3h 53m | 8h 37m | 14h 25m | 19h 59m | max: 0.3542<br>last: 0.2979 |
|
| 381 |
+
| 0.3 | 146.11 | 38.88 | \ | 103.22 | 3h 18m | 6h 49m | 11h 40m | 17h 20m | max: 0.3469<br>last: 0.2865 |
|
| 382 |
+
| 0.5 | 150.63 | 33.14 | \ | 113.16 | 3h 13m | 6h 46m | 10h 53m | 17h 22m | max: 0.3521<br>last: 0.3094 |
|
| 383 |
+
|
| 384 |
+
> source data: https://wandb.ai/hou-zg-meituan/fully-async-policy-stream_stale_partial?nw=nwuserhouzg
|
| 385 |
+
|
| 386 |
+
### 128-card 7B require_batches Ablation Experiment
|
| 387 |
+
|
| 388 |
+
In multiple tests, we found that the number of samples issued each time in streaming affects the response length during
|
| 389 |
+
training, which in turn affects training time. We verified the impact on results by modifying
|
| 390 |
+
`async_training.require_batches`.
|
| 391 |
+
|
| 392 |
+
| require_batches | step | gen | old_log_prob | update_actor | total time<br>100 step | total time<br>200 step | total time<br>300 step | acc/mean@1 |
|
| 393 |
+
|:-----------------:|:--------:|:-------:|:--------------:|:--------------:|:------------------------:|:------------------------:|:------------------------:|:-----------------------------:|
|
| 394 |
+
| 1 | 203.47 | 30.88 | \ | 181.08 | 3h 31m | 8h 29m | 17h 36m | max: 0.349<br>last: 0.326 |
|
| 395 |
+
| 2 | 158.72 | 26.32 | \ | 128.08 | 3h 35m | 7h 38m | 13h 57m | max: 0.351<br>last: 0.3406 |
|
| 396 |
+
| 4 | 124.64 | 25.62 | \ | 95.06 | 3h 13m | 6h 46m | 10h 53m | max: 0.3521<br>last: 0.3521 |
|
| 397 |
+
|
| 398 |
+
> source data: https://wandb.ai/hou-zg-meituan/fully-async-policy-ablation_require_batches?nw=nwuserhouzg
|
| 399 |
+
|
| 400 |
+
### 30B Model Mode Experiment
|
| 401 |
+
|
| 402 |
+
We achieved a 1.7x performance improvement with `async stream pipeline with staleness samples` strategy on the
|
| 403 |
+
Qwen3-30B-A3B-Base model compared to the colocate setup. It is worth noting that this is far from the upper limit of
|
| 404 |
+
performance gains achievable through asynchrony. Firstly, the comparative experiments used a maximum response length of
|
| 405 |
+
only 8k, which is much shorter than the 20k sequence length in previous experiments, resulting in a less pronounced
|
| 406 |
+
rollout tail effect. Secondly, we adopted a highly skewed resource allocation, with rollout using 96 GPUs and trainer
|
| 407 |
+
using 32 GPUs, which is not an optimal configuration. During the experiments, we observed that the current verl
|
| 408 |
+
implementation imposes certain constraints, such as requiring data to be evenly divisible by the number of GPUs, making
|
| 409 |
+
resource adjustment less flexible. Additionally, as asynchronous training and deployment accelerate, the performance gap
|
| 410 |
+
is gradually narrowing. Therefore, enabling more flexible resource allocation and dynamic resource adjustment in the
|
| 411 |
+
future will be our next focus.
|
| 412 |
+
|
| 413 |
+
* Machine: H20
|
| 414 |
+
* Model: Qwen3-30B-A3B-Base
|
| 415 |
+
* Rollout length: max_response_length : 8K tokens;
|
| 416 |
+
* Algorithm: GRPO
|
| 417 |
+
* Dataset: TRAIN_FILE: dapo-math-17k.parquet TEST_FILE: aime-2024.parquet
|
| 418 |
+
* Engine: vllm+Megatron
|
| 419 |
+
* rollout.n: 16
|
| 420 |
+
* ppo_mini_batch_size: 128
|
| 421 |
+
* test_freq: 20
|
| 422 |
+
|
| 423 |
+
* colocate sync:
|
| 424 |
+
* step:400
|
| 425 |
+
* train_batch_size: 512
|
| 426 |
+
|
| 427 |
+
* fully_async_policy
|
| 428 |
+
* total_rollout_steps: 512*400
|
| 429 |
+
* trigger_parameter_sync_step: 512/128 = 4
|
| 430 |
+
* staleness_threshold: 0.5
|
| 431 |
+
* partial_rollout: True
|
| 432 |
+
|
| 433 |
+
| Training Mode | Resource Allocation | Step | Gen | Old Log Prob | Ref | Update Actor | Total Time 100 Step | Total Time 200 Step | Total Time 300 Step | Total Time 400 Step | Acc/Mean@1 |
|
| 434 |
+
|--------------------|---------------------|--------|--------|--------------|-------|--------------|---------------------|---------------------|---------------------|---------------------|-----------------------------|
|
| 435 |
+
| Colocate Sync | 128 | 497.89 | 348.05 | 28.73 | 20.86 | 86.27 | 13h 36m | 1d 3h 48m | 1d 19h 4m | 2d 11h 39m | max: 0.3500<br>last: 0.3208 |
|
| 436 |
+
| Fully Async Policy | 96:32 | 282.75 | 22.06 | \ | 50.05 | 206.63 | 6h 45m (2.01x) | 14h 48m (1.88x) | 1d 0h 9m (1.78x) | 1d 10h 41m (1.72x) | max: 0.3813<br>last: 0.3448 |
|
| 437 |
+
|
| 438 |
+
> source data: https://wandb.ai/hou-zg-meituan/fully-async-policy-30B?nw=nwuserhouzg | | |
|
| 439 |
+
|
| 440 |
+
## Multi-Turn Tool Calling
|
| 441 |
+
|
| 442 |
+
Referencing **recipe/retool** and **ToolAgentLoop**, we implemented **AsyncPartialToolAgentLoop**, a multi-turn
|
| 443 |
+
tool-calling loop that supports partial_rollout for **fully_async_policy**.
|
| 444 |
+
|
| 445 |
+
### Core Design
|
| 446 |
+
|
| 447 |
+
`AsyncPartialToolAgentLoop` inherits from `ToolAgentLoop` and is adapted for the asynchronous training mode of
|
| 448 |
+
`fully_async_policy`. When `partial_rollout=True`, the Rollouter interrupts ongoing generation tasks before
|
| 449 |
+
synchronizing parameters with the Trainer. `AsyncPartialToolAgentLoop` is capable of:
|
| 450 |
+
|
| 451 |
+
1. **Interrupting Tasks**: Responding to an interrupt signal to save the current state. Currently, interruptions occur
|
| 452 |
+
during the `GENERATING` process or after other states have completed.
|
| 453 |
+
2. **Resuming Tasks**: Resuming execution from the saved state after parameter synchronization is complete, rather than
|
| 454 |
+
starting over.
|
| 455 |
+
|
| 456 |
+
### How to Use
|
| 457 |
+
|
| 458 |
+
RL training with multi-turn tool calling in `fully_async_policy` is similar to `recipe/retool`. It is enabled by
|
| 459 |
+
specifying `multi_turn` configurations in the config file.
|
| 460 |
+
|
| 461 |
+
1. **SFT Stage**: First, the model should undergo SFT to learn how to follow tool-calling format instructions.
|
| 462 |
+
2. **Multi-turn Configuration**: In the `fully_async_policy` training configuration, set the following parameters:
|
| 463 |
+
```yaml
|
| 464 |
+
actor_rollout_ref:
|
| 465 |
+
rollout:
|
| 466 |
+
multi_turn:
|
| 467 |
+
enable: True # AsyncPartialToolAgentLoop will be used by default in fully_async_policy mode
|
| 468 |
+
# Other multi_turn related configurations
|
| 469 |
+
```
|
| 470 |
+
3. **Async Parameters**: To improve efficiency, enable `partial_rollout` and `staleness_threshold` when using multi-turn
|
| 471 |
+
tool calling:
|
| 472 |
+
```yaml
|
| 473 |
+
async_training:
|
| 474 |
+
partial_rollout: True
|
| 475 |
+
staleness_threshold: 0.5
|
| 476 |
+
# Other async parameters
|
| 477 |
+
```
|
| 478 |
+
4. **Example**: See `recipe/fully_async_policy/shell/dapo_7b_async_retool.sh`.
|
| 479 |
+
|
| 480 |
+
### Experimental Results
|
| 481 |
+
|
| 482 |
+
To validate the performance of `fully_async_policy` on multi-turn tool-calling tasks, we compared it with the standard
|
| 483 |
+
`colocate` synchronous mode. Key parameter settings are as follows.
|
| 484 |
+
|
| 485 |
+
* **SFT Model**: Based on `Qwen2.5-7B-Instruct`, trained for 6 epochs on the `ReTool-SFT` dataset
|
| 486 |
+
* **RL Algorithm**: DAPO
|
| 487 |
+
* **Dataset**:
|
| 488 |
+
* Train: `DAPO-Math-17k`
|
| 489 |
+
* Test: `aime_2025`
|
| 490 |
+
* **Resource and Mode Comparison**:
|
| 491 |
+
* `colocate sync`: 32 H20 gpus
|
| 492 |
+
* `fully_async_policy`: 16 gpus for Trainer + 16 gpus for Rollouter
|
| 493 |
+
* **Key Configurations**:
|
| 494 |
+
1. **Tool Calling Configuration**:
|
| 495 |
+
* `multi_turn.enable: True`
|
| 496 |
+
* `multi_turn.max_user_turns: 16`
|
| 497 |
+
* `multi_turn.max_assistant_turns: 16`
|
| 498 |
+
* `multi_turn.tool_config_path: recipe/retool/sandbox_fusion_tool_config.yaml`
|
| 499 |
+
2. **`colocate sync` Configuration**:
|
| 500 |
+
* `ppo_mini_batch_size: 16`
|
| 501 |
+
* `train_batch_size: 64`
|
| 502 |
+
3. **`fully_async_policy` Configuration**:
|
| 503 |
+
* `ppo_mini_batch_size: 16`
|
| 504 |
+
* `trigger_parameter_sync_step: 4`
|
| 505 |
+
* `require_batches: 1`
|
| 506 |
+
* `staleness_threshold: 1`
|
| 507 |
+
* `partial_rollout: True`
|
| 508 |
+
|
| 509 |
+
| training mode | Resource allocation | step | gen | old_log_prob | update_actor | total time<br>100 step | total time<br>200 step | aime_2025<br>acc/mean@30 |
|
| 510 |
+
|:--------------------:|:---------------------:|:---------:|:---------:|:--------------:|:--------------:|:------------------------:|:------------------------:|:-------------------------------:|
|
| 511 |
+
| colocate | 32 | 375.47 | 228.03 | 35.19 | 111.84 | 9h 46m | 22h 28m | start:0.1078<br>last:0.2056 |
|
| 512 |
+
| fully_async_policy | 16: 16 | 221.36 | 40.59 | \ | 179.58 | 6h 19m<br>(1.55x) | 14h 4m<br>(1.60x) | start:0.11<br>last:0.2044 |
|
| 513 |
+
|
| 514 |
+
> source data: https://wandb.ai/hou-zg-meituan/fully-async-policy-multiturn-tool?nw=nwuserhouzg
|
| 515 |
+
|
| 516 |
+
## Future Plans
|
| 517 |
+
|
| 518 |
+
* GRPO experiments
|
| 519 |
+
* Megatron adaptation
|
| 520 |
+
* SGLang integration
|
| 521 |
+
* Transfer queue integration
|
| 522 |
+
* Asynchronous parameter synchronization
|
| 523 |
+
* AReaL asynchronous algorithm implementation
|
| 524 |
+
* TPPO algorithm implementation
|
| 525 |
+
* Multi-turn and Tool support
|
docs/algo/dapo.md
ADDED
|
@@ -0,0 +1,187 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Recipe: Decoupled Clip and Dynamic Sampling Policy Optimization (DAPO)
|
| 2 |
+
|
| 3 |
+
Last updated: 06/19/2025.
|
| 4 |
+
|
| 5 |
+
> Open-Source Algorithm Implementation & Expriement Running: [Yuxuan Tong](https://tongyx361.github.io/), [Guangming Sheng](https://hk.linkedin.com/in/guangming-sheng-b50640211)
|
| 6 |
+
|
| 7 |
+
🏠 [Homepage](https://dapo-sia.github.io/) | 📝 [Paper@arXiv](https://arxiv.org/abs/2503.14476) | 🤗 [Datasets&Models@HF](https://huggingface.co/collections/BytedTsinghua-SIA/dapo-67d7f1517ee33c8aed059da0) | 🐱 [Code@GitHub](https://github.com/volcengine/verl/tree/recipe/dapo/recipe/dapo) | 🐱 [Repo@GitHub](https://github.com/BytedTsinghua-SIA/DAPO)
|
| 8 |
+
|
| 9 |
+
> We propose the **D**ecoupled Clip and Dynamic s**A**mpling **P**olicy **O**ptimization (DAPO) algorithm. By making our work publicly available, we provide the broader research community and society with practical access to scalable reinforcement learning, enabling all to benefit from these advancements. Our system is based on the awesome [verl](https://github.com/volcengine/verl) framework. Thanks for their great work! Applying DAPO training to Qwen2.5-32B base model proves to outperform the previous state-of-the-art DeepSeek-R1-Zero-Qwen-32B on AIME 2024, achieving **50%** accuracy with **50%** less training steps.
|
| 10 |
+
>
|
| 11 |
+
> 
|
| 12 |
+
|
| 13 |
+
## Quickstart
|
| 14 |
+
|
| 15 |
+
1. Prepare the datasets **on the Ray cluster**:
|
| 16 |
+
|
| 17 |
+
```bash
|
| 18 |
+
bash prepare_dapo_data.sh # This downloads the datasets to ${HOME}/verl/data by default
|
| 19 |
+
```
|
| 20 |
+
|
| 21 |
+
2. Submit the job to the Ray cluster **from any machine**:
|
| 22 |
+
|
| 23 |
+
```bash
|
| 24 |
+
cd verl # Repo root
|
| 25 |
+
export RAY_ADDRESS="http://${RAY_IP:-localhost}:8265" # The Ray cluster address to connect to
|
| 26 |
+
export WORKING_DIR="${PWD}" # The local directory to package to the Ray cluster
|
| 27 |
+
# Set the runtime environment like env vars and pip packages for the Ray cluster in yaml
|
| 28 |
+
export RUNTIME_ENV="./recipe/dapo/runtime_env.yaml" # This sets environment variables for the Ray cluster
|
| 29 |
+
bash recipe/dapo/run_dapo_qwen2.5_32b.sh # or other scripts
|
| 30 |
+
```
|
| 31 |
+
|
| 32 |
+
## Reproduction Runs
|
| 33 |
+
|
| 34 |
+
| Setup | AIME 2024 Acc. | Hardware | Image | Commit | Environment Variables | Training Script | Training Record |
|
| 35 |
+
| -------------------------------------------- | -------------- | --------- | -------------------------------------------------------------------- | -------------------------------------------------------------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------- |
|
| 36 |
+
| DAPO | 52% | 16x8xH800 | `hiyouga/verl:ngc-th2.6.0-cu126-vllm0.8.3-flashinfer0.2.2-cxx11abi0` | [`4f80e4`](https://github.com/volcengine/verl/tree/4f80e465c2ec79ab9c3c30ec74b9745de61d0490) | [runtime_env.yaml](https://github.com/volcengine/verl/blob/4f80e465c2ec79ab9c3c30ec74b9745de61d0490/recipe/dapo/runtime_env.yaml) | [run_dapo_qwen2.5_32b.sh](https://github.com/volcengine/verl/blob/4f80e465c2ec79ab9c3c30ec74b9745de61d0490/recipe/dapo/run_dapo_qwen2.5_32b.sh) | [W&B](https://wandb.ai/verl-org/DAPO%20Reproduction%20on%20verl/workspace?nw=wmb4qxfht0n) |
|
| 37 |
+
| DAPO w/o Dynamic Sampling | 50% | 16x8xH800 | `hiyouga/verl:ngc-th2.6.0-cu126-vllm0.8.3-flashinfer0.2.2-cxx11abi0` | [`4f80e4`](https://github.com/volcengine/verl/tree/4f80e465c2ec79ab9c3c30ec74b9745de61d0490) | [runtime_env.yaml](https://github.com/volcengine/verl/blob/4f80e465c2ec79ab9c3c30ec74b9745de61d0490/recipe/dapo/runtime_env.yaml) | [run_dapo_wo_ds_qwen2.5_32b.sh](https://github.com/volcengine/verl/blob/4f80e465c2ec79ab9c3c30ec74b9745de61d0490/recipe/dapo/run_dapo_wo_ds_qwen2.5_32b.sh) | [W&B](https://wandb.ai/verl-org/DAPO%20Reproduction%20on%20verl/workspace?nw=wmb4qxfht0n) |
|
| 38 |
+
| DAPO w/o Token-level Loss & Dynamic Sampling | 44% | 16x8xH20 | `hiyouga/verl:ngc-th2.5.1-cu120-vllm0.7.4-hotfix` | [`4f80e4`](https://github.com/volcengine/verl/tree/4f80e465c2ec79ab9c3c30ec74b9745de61d0490) | [runtime_env.yaml](https://github.com/volcengine/verl/blob/4f80e465c2ec79ab9c3c30ec74b9745de61d0490/recipe/dapo/runtime_env.yaml) | [run_dapo_early_qwen2.5_32b.sh](https://github.com/volcengine/verl/blob/4f80e465c2ec79ab9c3c30ec74b9745de61d0490/recipe/dapo/run_dapo_early_qwen2.5_32b.sh) | [W&B](https://wandb.ai/verl-org/DAPO%20Reproduction%20on%20verl/workspace?nw=wmb4qxfht0n) |
|
| 39 |
+
|
| 40 |
+
> [!IMPORTANT]
|
| 41 |
+
>
|
| 42 |
+
> **📢 Call for Contribution!**
|
| 43 |
+
>
|
| 44 |
+
> Welcome to submit your reproduction runs and setups!
|
| 45 |
+
|
| 46 |
+
## Configuration
|
| 47 |
+
|
| 48 |
+
### Separated Clip Epsilons (-> Clip-Higher)
|
| 49 |
+
|
| 50 |
+
An example configuration:
|
| 51 |
+
|
| 52 |
+
```yaml
|
| 53 |
+
actor_rollout_ref:
|
| 54 |
+
actor:
|
| 55 |
+
clip_ratio_low: 0.2
|
| 56 |
+
clip_ratio_high: 0.28
|
| 57 |
+
```
|
| 58 |
+
|
| 59 |
+
`clip_ratio_low` and `clip_ratio_high` specify the $\varepsilon_{\text {low }}$ and $\varepsilon_{\text {high }}$ in the DAPO objective.
|
| 60 |
+
|
| 61 |
+
Core relevant code:
|
| 62 |
+
|
| 63 |
+
```python
|
| 64 |
+
pg_losses1 = -advantages * ratio
|
| 65 |
+
pg_losses2 = -advantages * torch.clamp(ratio, 1 - cliprange_low, 1 + cliprange_high)
|
| 66 |
+
pg_losses = torch.maximum(pg_losses1, pg_losses2)
|
| 67 |
+
```
|
| 68 |
+
|
| 69 |
+
### Dynamic Sampling (with Group Filtering)
|
| 70 |
+
|
| 71 |
+
An example configuration:
|
| 72 |
+
|
| 73 |
+
```yaml
|
| 74 |
+
data:
|
| 75 |
+
gen_batch_size: 1536
|
| 76 |
+
train_batch_size: 512
|
| 77 |
+
algorithm:
|
| 78 |
+
filter_groups:
|
| 79 |
+
enable: True
|
| 80 |
+
metric: acc # score / seq_reward / seq_final_reward / ...
|
| 81 |
+
max_num_gen_batches: 10 # Non-positive values mean no upper limit
|
| 82 |
+
```
|
| 83 |
+
|
| 84 |
+
Setting `filter_groups.enable` to `True` will filter out groups whose outputs' `metric` are all the same, e.g., for `acc`, groups whose outputs' accuracies are all 1 or 0.
|
| 85 |
+
|
| 86 |
+
The trainer will repeat sampling with `gen_batch_size` until there are enough qualified groups for `train_batch_size` or reaching the upper limit specified by `max_num_gen_batches`.
|
| 87 |
+
|
| 88 |
+
Core relevant code:
|
| 89 |
+
|
| 90 |
+
```python
|
| 91 |
+
prompt_bsz = self.config.data.train_batch_size
|
| 92 |
+
if num_prompt_in_batch < prompt_bsz:
|
| 93 |
+
print(f'{num_prompt_in_batch=} < {prompt_bsz=}')
|
| 94 |
+
num_gen_batches += 1
|
| 95 |
+
max_num_gen_batches = self.config.algorithm.filter_groups.max_num_gen_batches
|
| 96 |
+
if max_num_gen_batches <= 0 or num_gen_batches < max_num_gen_batches:
|
| 97 |
+
print(f'{num_gen_batches=} < {max_num_gen_batches=}. Keep generating...')
|
| 98 |
+
continue
|
| 99 |
+
else:
|
| 100 |
+
raise ValueError(
|
| 101 |
+
f'{num_gen_batches=} >= {max_num_gen_batches=}. Generated too many. Please check your data.'
|
| 102 |
+
)
|
| 103 |
+
else:
|
| 104 |
+
# Align the batch
|
| 105 |
+
traj_bsz = self.config.data.train_batch_size * self.config.actor_rollout_ref.rollout.n
|
| 106 |
+
batch = batch[:traj_bsz]
|
| 107 |
+
```
|
| 108 |
+
|
| 109 |
+
### Flexible Loss Aggregation Mode (-> Token-level Loss)
|
| 110 |
+
|
| 111 |
+
An example configuration:
|
| 112 |
+
|
| 113 |
+
```yaml
|
| 114 |
+
actor_rollout_ref:
|
| 115 |
+
actor:
|
| 116 |
+
loss_agg_mode: "token-mean" # / "seq-mean-token-sum" / "seq-mean-token-mean"
|
| 117 |
+
# NOTE: "token-mean" is the default behavior
|
| 118 |
+
```
|
| 119 |
+
|
| 120 |
+
Setting `loss_agg_mode` to `token-mean` will mean the (policy gradient) loss across all the tokens in all the sequences in a mini-batch.
|
| 121 |
+
|
| 122 |
+
Core relevant code:
|
| 123 |
+
|
| 124 |
+
```python
|
| 125 |
+
if loss_agg_mode == "token-mean":
|
| 126 |
+
loss = verl_F.masked_mean(loss_mat, loss_mask)
|
| 127 |
+
elif loss_agg_mode == "seq-mean-token-sum":
|
| 128 |
+
seq_losses = torch.sum(loss_mat * loss_mask, dim=-1) # token-sum
|
| 129 |
+
loss = torch.mean(seq_losses) # seq-mean
|
| 130 |
+
elif loss_agg_mode == "seq-mean-token-mean":
|
| 131 |
+
seq_losses = torch.sum(loss_mat * loss_mask, dim=-1) / torch.sum(loss_mask, dim=-1) # token-mean
|
| 132 |
+
loss = torch.mean(seq_losses) # seq-mean
|
| 133 |
+
else:
|
| 134 |
+
raise ValueError(f"Invalid loss_agg_mode: {loss_agg_mode}")
|
| 135 |
+
```
|
| 136 |
+
|
| 137 |
+
### Overlong Reward Shaping
|
| 138 |
+
|
| 139 |
+
An example configuration:
|
| 140 |
+
|
| 141 |
+
```yaml
|
| 142 |
+
data:
|
| 143 |
+
max_response_length: 20480 # 16384 + 4096
|
| 144 |
+
reward_model:
|
| 145 |
+
overlong_buffer:
|
| 146 |
+
enable: True
|
| 147 |
+
len: 4096
|
| 148 |
+
penalty_factor: 1.0
|
| 149 |
+
```
|
| 150 |
+
|
| 151 |
+
Setting `overlong_buffer.enable` to `True` will penalize the outputs whose lengths are overlong but still within the hard context limit.
|
| 152 |
+
|
| 153 |
+
Specifically, the penalty increases linearly from `0` to `overlong_buffer.penalty_factor` when the length of the output exceeds the `max_response_length - overlong_buffer.len` by `0` to `overlong_buffer.len` tokens.
|
| 154 |
+
|
| 155 |
+
Core relevant code:
|
| 156 |
+
|
| 157 |
+
```python
|
| 158 |
+
if self.overlong_buffer_cfg.enable:
|
| 159 |
+
overlong_buffer_len = self.overlong_buffer_cfg.len
|
| 160 |
+
expected_len = self.max_resp_len - overlong_buffer_len
|
| 161 |
+
exceed_len = valid_response_length - expected_len
|
| 162 |
+
overlong_penalty_factor = self.overlong_buffer_cfg.penalty_factor
|
| 163 |
+
overlong_reward = min(-exceed_len / overlong_buffer_len * overlong_penalty_factor, 0)
|
| 164 |
+
reward += overlong_reward
|
| 165 |
+
```
|
| 166 |
+
|
| 167 |
+
## FAQ
|
| 168 |
+
|
| 169 |
+
### Where is the "Overlong Filtering" in the paper?
|
| 170 |
+
|
| 171 |
+
Most experiments in the paper, including the best-performant one, are run without Overlong Filtering because it's somehow overlapping with Overlong Reward Shaping in terms of properly learning from the longest outputs. So we don't implement it here.
|
| 172 |
+
|
| 173 |
+
### What's the difference between [the `recipe/dapo` directory in the `main` branch](https://github.com/volcengine/verl/tree/main/recipe/dapo) and the [`recipe/dapo` branch](https://github.com/volcengine/verl/tree/recipe/dapo/recipe/dapo)?
|
| 174 |
+
|
| 175 |
+
[The `recipe/dapo` branch](https://github.com/volcengine/verl/tree/recipe/dapo/recipe/dapo) is for **as-is reproduction** and thus won't be updated with new features.
|
| 176 |
+
|
| 177 |
+
[The `recipe/dapo` directory in the `main` branch](https://github.com/volcengine/verl/tree/main/recipe/dapo) works as an example of how to extend the latest `verl` to implement an algorithm recipe, which will be maintained with new features.
|
| 178 |
+
|
| 179 |
+
### Why can't I produce similar results after modifications?
|
| 180 |
+
|
| 181 |
+
RL infrastructures nowadays still have inherent unrobustness, on which we are still working hard to improve.
|
| 182 |
+
|
| 183 |
+
We strongly recommend to only modify one thing at a time.
|
| 184 |
+
|
| 185 |
+
We also list some known problems here:
|
| 186 |
+
|
| 187 |
+
1. Enabling CUDA graph (`enforce_eager=False`) might cause model performance degradation, whose cause is still under investigation.
|
docs/ascend_tutorial/ascend_sglang_quick_start.rst
ADDED
|
@@ -0,0 +1,113 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Ascend Quickstart with SGLang Backend
|
| 2 |
+
===================================
|
| 3 |
+
|
| 4 |
+
Last updated: 09/25/2025.
|
| 5 |
+
|
| 6 |
+
我们在 verl 上增加对华为昇腾设备的支持。
|
| 7 |
+
|
| 8 |
+
硬件支持
|
| 9 |
+
-----------------------------------
|
| 10 |
+
|
| 11 |
+
Atlas 200T A2 Box16
|
| 12 |
+
|
| 13 |
+
Atlas 900 A2 PODc
|
| 14 |
+
|
| 15 |
+
Atlas 800T A3
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
安装
|
| 19 |
+
-----------------------------------
|
| 20 |
+
|
| 21 |
+
基础环境准备
|
| 22 |
+
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
| 23 |
+
|
| 24 |
+
+-----------+-------------+
|
| 25 |
+
| software | version |
|
| 26 |
+
+-----------+-------------+
|
| 27 |
+
| Python | == 3.11 |
|
| 28 |
+
+-----------+-------------+
|
| 29 |
+
| CANN | == 8.3.RC1 |
|
| 30 |
+
+-----------+-------------+
|
| 31 |
+
| HDK | == 25.3.RC1 |
|
| 32 |
+
+-----------+-------------+
|
| 33 |
+
| torch | == 2.6.0 |
|
| 34 |
+
+-----------+-------------+
|
| 35 |
+
| torch_npu | == 2.6.0 |
|
| 36 |
+
+-----------+-------------+
|
| 37 |
+
|
| 38 |
+
**目前verl框架中sglang npu后端仅支持上述HDK、CANN和PTA版本, 商发可用版本预计2025年10月发布**
|
| 39 |
+
|
| 40 |
+
为了能够在 verl 中正常使用 sglang,需使用以下命令安装sglang、torch_memory_saver和verl。
|
| 41 |
+
|
| 42 |
+
sglang
|
| 43 |
+
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
| 44 |
+
.. code-block:: bash
|
| 45 |
+
|
| 46 |
+
# sglang
|
| 47 |
+
git clone https://github.com/sgl-project/sglang.git
|
| 48 |
+
cd sglang
|
| 49 |
+
mv python/pyproject.toml python/pyproject.toml.backup
|
| 50 |
+
mv python/pyproject_other.toml python/pyproject.toml
|
| 51 |
+
pip install -e "python[srt_npu]"
|
| 52 |
+
|
| 53 |
+
安装torch_memory_saver
|
| 54 |
+
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
| 55 |
+
.. code-block:: bash
|
| 56 |
+
|
| 57 |
+
# torch_memory_saver
|
| 58 |
+
git clone https://github.com/sgl-project/sgl-kernel-npu.git
|
| 59 |
+
cd sgl-kernel-npu
|
| 60 |
+
bash build.sh -a memory-saver
|
| 61 |
+
pip install output/torch_memory_saver*.whl
|
| 62 |
+
|
| 63 |
+
安装verl
|
| 64 |
+
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
| 65 |
+
|
| 66 |
+
.. code-block:: bash
|
| 67 |
+
|
| 68 |
+
git clone https://github.com/volcengine/verl.git
|
| 69 |
+
cd verl
|
| 70 |
+
pip install --no-deps -e .
|
| 71 |
+
pip install -r requirements-npu.txt
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
其他三方库说明
|
| 75 |
+
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
| 76 |
+
|
| 77 |
+
+--------------+---------------+
|
| 78 |
+
| software | description |
|
| 79 |
+
+--------------+---------------+
|
| 80 |
+
| transformers | v4.56.1 |
|
| 81 |
+
+--------------+---------------+
|
| 82 |
+
| triton_ascend| v3.2.0 |
|
| 83 |
+
+--------------+---------------+
|
| 84 |
+
|
| 85 |
+
1. sglang依赖 transformers v4.56.1
|
| 86 |
+
2. sglang依赖triton_ascend v3.2.0
|
| 87 |
+
3. 暂不支持多模态模型,卸载相关安装包torchvision、timm
|
| 88 |
+
|
| 89 |
+
.. code-block:: bash
|
| 90 |
+
|
| 91 |
+
pip uninstall torchvision
|
| 92 |
+
pip uninstall timm
|
| 93 |
+
pip uninstall triton
|
| 94 |
+
|
| 95 |
+
pip install transformers==4.56.1
|
| 96 |
+
pip install -i https://test.pypi.org/simple/ triton-ascend==3.2.0.dev20250925
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
快速开始
|
| 100 |
+
-----------------------------------
|
| 101 |
+
正式使用前,建议您通过对Qwen3-8B GRPO的训练尝试以检验环境准备和安装的正确性。
|
| 102 |
+
|
| 103 |
+
1.下载数据集并将数据集预处理为parquet格式,以便包含计算RL奖励所需的必要字段
|
| 104 |
+
|
| 105 |
+
.. code-block:: bash
|
| 106 |
+
|
| 107 |
+
python3 examples/data_preprocess/gsm8k.py --local_save_dir ~/data/gsm8k
|
| 108 |
+
|
| 109 |
+
2.执行训练
|
| 110 |
+
|
| 111 |
+
.. code-block:: bash
|
| 112 |
+
|
| 113 |
+
bash verl/examples/grpo_trainer/run_qwen3_8b_grpo_sglang_1k_npu.sh
|
docs/examples/multi_modal_example.rst
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Multi-Modal Example Architecture
|
| 2 |
+
=================================
|
| 3 |
+
|
| 4 |
+
Last updated: 04/28/2025.
|
| 5 |
+
|
| 6 |
+
Introduction
|
| 7 |
+
------------
|
| 8 |
+
|
| 9 |
+
Now, verl has supported multi-modal training. You can use fsdp and
|
| 10 |
+
vllm/sglang to start a multi-modal RL task. Megatron supports is also
|
| 11 |
+
on the way.
|
| 12 |
+
|
| 13 |
+
Follow the steps below to quickly start a multi-modal RL task.
|
| 14 |
+
|
| 15 |
+
Step 1: Prepare dataset
|
| 16 |
+
-----------------------
|
| 17 |
+
|
| 18 |
+
.. code:: python
|
| 19 |
+
|
| 20 |
+
# it will be saved in the $HOME/data/geo3k folder
|
| 21 |
+
python examples/data_preprocess/geo3k.py
|
| 22 |
+
|
| 23 |
+
Step 2: Download Model
|
| 24 |
+
----------------------
|
| 25 |
+
|
| 26 |
+
.. code:: bash
|
| 27 |
+
|
| 28 |
+
# download the model from huggingface
|
| 29 |
+
python3 -c "import transformers; transformers.pipeline(model='Qwen/Qwen2.5-VL-7B-Instruct')"
|
| 30 |
+
|
| 31 |
+
Step 3: Perform GRPO training with multi-modal model on Geo3K Dataset
|
| 32 |
+
---------------------------------------------------------------------
|
| 33 |
+
|
| 34 |
+
.. code:: bash
|
| 35 |
+
|
| 36 |
+
# run the task
|
| 37 |
+
bash examples/grpo_trainer/run_qwen2_5_vl-7b.sh
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
|
docs/hybrid_flow.rst
ADDED
|
@@ -0,0 +1,266 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
=========================================================
|
| 2 |
+
HybridFlow Programming Guide
|
| 3 |
+
=========================================================
|
| 4 |
+
|
| 5 |
+
Last updated: 06/02/2025.
|
| 6 |
+
|
| 7 |
+
.. _vermouth: https://github.com/vermouth1992
|
| 8 |
+
|
| 9 |
+
Author: `Chi Zhang <https://github.com/vermouth1992>`_
|
| 10 |
+
|
| 11 |
+
verl is an open source implementation of the paper `HybridFlow <https://arxiv.org/abs/2409.19256v2>`_ [1]_. In this section, we will introduce the basic concepts of HybridFlow, the motivation and how to program with verl APIs.
|
| 12 |
+
|
| 13 |
+
Motivation and Design
|
| 14 |
+
------------------------
|
| 15 |
+
We use dataflow to represent RL systems. [4]_.
|
| 16 |
+
|
| 17 |
+
DataFlow
|
| 18 |
+
~~~~~~~~~~~~~~~~~~~~
|
| 19 |
+
|
| 20 |
+
Dataflow is an abstraction of computations. Neural Network training is a typical dataflow. It can be represented by computational graph.
|
| 21 |
+
|
| 22 |
+
.. image:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/dataflow.jpeg?raw=true
|
| 23 |
+
:alt: The dataflow graph from CS231n 2024 lecture 4
|
| 24 |
+
|
| 25 |
+
This figure [2]_ represents the computation graph of a polynomial function followed by a sigmoid function. In the data flow of neural network computation, each node represents an operator, and each edge represents the direction of forward/backward propagation. The computation graph determines the architecture of the neural network.
|
| 26 |
+
|
| 27 |
+
RL as a dataflow problem
|
| 28 |
+
++++++++++++++++++++++++++++++++++++++++++++++
|
| 29 |
+
|
| 30 |
+
Reinforcement learning (RL) training can also be represented as a dataflow. Below is the dataflow graph that represents the PPO algorithm used in RLHF [3]_:
|
| 31 |
+
|
| 32 |
+
.. image:: https://picx.zhimg.com/70/v2-cb8ab5ee946a105aab6a563e92682ffa_1440w.avis?source=172ae18b&biz_tag=Post
|
| 33 |
+
:alt: PPO dataflow graph, credit to Zhihu 低级炼丹师
|
| 34 |
+
|
| 35 |
+
However, the dataflow of RL has fundamental differences compared with dataflow of neural network training as follows:
|
| 36 |
+
|
| 37 |
+
+--------------------------+--------------------------------------------------+---------------------+
|
| 38 |
+
| Workload | Node | Edge |
|
| 39 |
+
+--------------------------+--------------------------------------------------+---------------------+
|
| 40 |
+
| Neural Network Training | Operator (+/-/matmul/softmax) | Tensor movement |
|
| 41 |
+
+--------------------------+--------------------------------------------------+---------------------+
|
| 42 |
+
| Reinforcement Learning | High-level operators (rollout/model forward) | Data Movement |
|
| 43 |
+
+--------------------------+--------------------------------------------------+---------------------+
|
| 44 |
+
|
| 45 |
+
In the case of tabular reinforcement learning, each operator is a simple scalar math operation (e.g., bellman update). In deep reinforcement learning(DRL), each operator is a high-level neural network computation such as model inference/update. This makes RL a two-level dataflow problem:
|
| 46 |
+
|
| 47 |
+
- Control flow: defines how the high-level operators are executed (e.g., In PPO, we first perform rollout. Then, we perform advantage computation. Finally, we perform training). It expresses the **core logics of RL algorithms**.
|
| 48 |
+
- Computation flow: defines the dataflow of **neural network computation** (e.g., model forward/backward/optimizer).
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
Design Choices
|
| 52 |
+
~~~~~~~~~~~~~~~~~~~~
|
| 53 |
+
The model size used in DRL before the LLM era is typically small. Thus, the high-level neural network computation can be done in a single process. This enables embedding the computation flow inside the control flow as a single process.
|
| 54 |
+
|
| 55 |
+
However, in the LLM era, the computation flow (e.g., training neural network) becomes a multi-process program. This naturally leads to two design choices:
|
| 56 |
+
|
| 57 |
+
1. Convert the control flow into a multi-process program as well. Then colocate with computation flow (unified multi-controller)
|
| 58 |
+
|
| 59 |
+
- Advantages:
|
| 60 |
+
|
| 61 |
+
- Achieves the **optimal performance** under fixed computation flow and control flow as the communication overhead in both training and data transfer is minimized.
|
| 62 |
+
|
| 63 |
+
- Disadvantages:
|
| 64 |
+
|
| 65 |
+
- The computation and/or control flow is **hard to reuse** from software perspective as computation code is coupled with specific controller code. For example, the training loop of PPO is generic. Say we have an PPO training flow implemented with a specific computation flow such as FSDP. Neither the control flow or computation flow can be reused if we want to switch the computation flow from FSDP to Megatron, due to the coupling of control and computation flows.
|
| 66 |
+
- Requires more efforts from the user under flexible and dynamic control flows, due to the multi-process nature of the program.
|
| 67 |
+
|
| 68 |
+
2. Separate the flows: single process for the control flow and multi-process for computation flow
|
| 69 |
+
|
| 70 |
+
- Advantages:
|
| 71 |
+
|
| 72 |
+
- The computation flow defined elsewhere can be **easily reused** after the decoupling.
|
| 73 |
+
- The controller runs on a single process. Implementing a new RL algorithm with a **different control flow is simple and easy**.
|
| 74 |
+
|
| 75 |
+
- Disadvantages:
|
| 76 |
+
|
| 77 |
+
- Additional **data communication overhead** each time the controller process and computatation processes interact. The data has to be sent back and forth.
|
| 78 |
+
|
| 79 |
+
In verl, the latter strategy with separate control flow and computation flow is adopted. verl is designed to decouple the control flow of RL algorithms, and the implementation of computation engines.
|
| 80 |
+
|
| 81 |
+
Overall Execution Diagram
|
| 82 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 83 |
+
|
| 84 |
+
Below is a simplified diagram denoting the execution of a reinforcement learning job. In the diagram, the controller runs on a single process, while the generator/actor workers, critic workers run on multiple processes, placed with specific resource groups. For rollout, the controller passes the data to the generator to perform sample generation. When the rollout is done, the data is passed back to controller for the next step of the algorithm. Similar execution is done for other workers. With the hybrid controller design, the data flow and computation is decoupled to provide both efficiency in computation and flexibility in defining algorithm training loops.
|
| 85 |
+
|
| 86 |
+
.. figure:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/driver_worker.png?raw=true
|
| 87 |
+
:alt: The execution diagram
|
| 88 |
+
|
| 89 |
+
Codebase walkthrough (PPO)
|
| 90 |
+
------------------------------------------------
|
| 91 |
+
|
| 92 |
+
Entry function
|
| 93 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 94 |
+
Code: https://github.com/volcengine/verl/blob/main/verl/trainer/main_ppo.py
|
| 95 |
+
|
| 96 |
+
In this file, we define a remote function `main_task` that serves as the controller (driver) process as shown in the above figure. We also define a ``RewardManager``, where users can customize their reward function based on the data source in the dataset. Note that `RewardManager` should return the final token-level reward that is optimized by RL algorithms. Note that users can combine model-based rewards and rule-based rewards.
|
| 97 |
+
The ``main_task`` constructs a RayPPOTrainer instance and launch the fit. Note that ``main_task`` **runs as a single process**.
|
| 98 |
+
|
| 99 |
+
We highly recommend that the ``main_task`` is NOT scheduled on the head of the ray cluster because ``main_task`` will consume a lot of memory but the head usually contains very few resources.
|
| 100 |
+
|
| 101 |
+
Ray trainer
|
| 102 |
+
~~~~~~~~~~~~~~~~~~~~
|
| 103 |
+
Code: https://github.com/volcengine/verl/blob/main/verl/trainer/ppo/ray_trainer.py
|
| 104 |
+
|
| 105 |
+
The RayPPOTrainer manages
|
| 106 |
+
|
| 107 |
+
- Worker and WorkerGroup construction
|
| 108 |
+
- Runs the main loop of PPO algorithm
|
| 109 |
+
|
| 110 |
+
Note that, the fit function of RayPPOTrainer **runs as a single process**.
|
| 111 |
+
|
| 112 |
+
Worker and WorkerGroup construction
|
| 113 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 114 |
+
|
| 115 |
+
Each workerGroup manages a list of workers that runs remotely. Note that the worker group runs in the process of its constructor.
|
| 116 |
+
Each worker inside the WorkerGroup runs on a GPU. The worker group serves as a proxy for the controller process to interact with a list of workers, in order to perform certain computations. **In order to do so, we have to bind the methods of the worker into the method of the WorkerGroup and define the data dispatch and data collection**. This is done via simple decoration that will be introduced in the Worker definition section.
|
| 117 |
+
|
| 118 |
+
For example, in PPO, we define 3 worker groups:
|
| 119 |
+
|
| 120 |
+
- ActorRolloutRef: manages actor, rollout and reference policy. ActorRolloutRefWorker can be instantiated as a single actor, a single rollout, a single reference policy, a combined actor/rollout or a combined actor/rollout/ref. This design is aimed for the maximum code reuse in various scenarios. The reason for colocating actor and rollout is for fast weight transfer using nccl. The reason for coloating actor and reference is to implement an efficient lora PPO as the reference policy is simply the base model of PPO in lora. The colocation is done via ``verl.single_controller.ray.base.create_colocated_worker_cls``, where it creates a single ray remote class exposing all class methods from these roles.
|
| 121 |
+
- Critic: manages the critic model
|
| 122 |
+
- Reward: manages the reward model
|
| 123 |
+
|
| 124 |
+
The worker group will be constructed on the resource pool it designates. The resource pool is a set of GPUs in the ray cluster.
|
| 125 |
+
|
| 126 |
+
Worker definition
|
| 127 |
+
~~~~~~~~~~~~~~~~~~~~
|
| 128 |
+
|
| 129 |
+
.. _ActorRolloutRefWorker: https://github.com/volcengine/verl/blob/main/verl/workers/fsdp_workers.py
|
| 130 |
+
|
| 131 |
+
We take `ActorRolloutRefWorker <https://github.com/volcengine/verl/blob/main/verl/workers/fsdp_workers.py>`_ for an example.
|
| 132 |
+
The APIs it should expose to the controller process are:
|
| 133 |
+
|
| 134 |
+
- init_model: build the underlying model
|
| 135 |
+
- generate_sequences: given prompts, generate responses
|
| 136 |
+
- compute_log_prob: compute the log-probability of a generated sequence using actor
|
| 137 |
+
- compute_ref_log_prob: compute the log-probability of a generated sequence using reference policy
|
| 138 |
+
- save_checkpoint: save the checkpoint
|
| 139 |
+
|
| 140 |
+
Note that these methods are defined in the worker that can only be invoked via remote calls. For example, if the controller process wants to initialize the model, it has to call
|
| 141 |
+
|
| 142 |
+
.. code-block:: python
|
| 143 |
+
|
| 144 |
+
for worker in actor_rollout_ref_wg:
|
| 145 |
+
worker.init_model.remote()
|
| 146 |
+
|
| 147 |
+
If the controller process wants to generate sequences, it has to call
|
| 148 |
+
|
| 149 |
+
.. code-block:: python
|
| 150 |
+
|
| 151 |
+
data = xxx
|
| 152 |
+
# split the data into dp chunks
|
| 153 |
+
data_dp_lst = data.split(dp_size)
|
| 154 |
+
output_dp_lst = []
|
| 155 |
+
for i, worker in enumerate(actor_rollout_ref_wg):
|
| 156 |
+
output_future = worker.generate_sequences.remote(data_dp_lst[i])
|
| 157 |
+
output_dp_lst.append(output_future)
|
| 158 |
+
output = torch.cat(ray.get(output_dp_lst), dim=0)
|
| 159 |
+
|
| 160 |
+
We observe that controller process calling worker group methods in general can be divided into 3 parts:
|
| 161 |
+
|
| 162 |
+
- Split the data into data parallel sizes
|
| 163 |
+
- Dispatch the corresponding data into each worker
|
| 164 |
+
- Collect and concatenate the data when the computation finishes
|
| 165 |
+
|
| 166 |
+
In verl, we design a syntax sugar to encapsulate the 3 processes into a single call from the controller process.
|
| 167 |
+
|
| 168 |
+
.. code-block:: python
|
| 169 |
+
|
| 170 |
+
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)
|
| 171 |
+
def generate_sequences(data):
|
| 172 |
+
...
|
| 173 |
+
|
| 174 |
+
# on the driver
|
| 175 |
+
output = actor_rollout_ref_wg.generate_sequences(data)
|
| 176 |
+
|
| 177 |
+
We decorate the method of the worker with a ``register`` that explicitly defines how the input data should be split and dispatched to each worker, and how the output data should be collected and concatenated by the controller. For example, ``Dispatch.DP_COMPUTE_PROTO`` splits the input data into dp chunks, dispatch each data to each worker, collect the output and concatenate the results. Note that this function requires the input and output to be a DataProto defined here (https://github.com/volcengine/verl/blob/main/verl/protocol.py).
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
PPO main loop
|
| 181 |
+
~~~~~~~~~~~~~~~~~~~~
|
| 182 |
+
With the aforementioned APIs, we can implement the main loop of PPO as if it is a single process program
|
| 183 |
+
|
| 184 |
+
.. code-block:: python
|
| 185 |
+
|
| 186 |
+
for prompt in dataloader:
|
| 187 |
+
output = actor_rollout_ref_wg.generate_sequences(prompt)
|
| 188 |
+
old_log_prob = actor_rollout_ref_wg.compute_log_prob(output)
|
| 189 |
+
ref_log_prob = actor_rollout_ref_wg.compute_ref_log_prob(output)
|
| 190 |
+
values = critic_wg.compute_values(output)
|
| 191 |
+
rewards = reward_wg.compute_scores(output)
|
| 192 |
+
# compute_advantages is running directly on the control process
|
| 193 |
+
advantages = compute_advantages(values, rewards)
|
| 194 |
+
output = output.union(old_log_prob)
|
| 195 |
+
output = output.union(ref_log_prob)
|
| 196 |
+
output = output.union(values)
|
| 197 |
+
output = output.union(rewards)
|
| 198 |
+
output = output.union(advantages)
|
| 199 |
+
# update actor
|
| 200 |
+
actor_rollout_ref_wg.update_actor(output)
|
| 201 |
+
critic.update_critic(output)
|
| 202 |
+
|
| 203 |
+
Takeaways
|
| 204 |
+
~~~~~~~~~~~~~~~~~~~~
|
| 205 |
+
- This programming paradigm enables users to use different computation backend without modification of the control process.
|
| 206 |
+
- This programming paradigm enables flexible placement (by changing the mapping of WorkerGroup and ResourcePool) without modification of the control process.
|
| 207 |
+
|
| 208 |
+
Repository organization
|
| 209 |
+
------------------------------------------------
|
| 210 |
+
|
| 211 |
+
Important code files in the repository are organized as below:
|
| 212 |
+
|
| 213 |
+
.. code-block:: bash
|
| 214 |
+
|
| 215 |
+
verl # the verl package
|
| 216 |
+
trainer
|
| 217 |
+
main_ppo.py # the entrypoint for RL training
|
| 218 |
+
ppo
|
| 219 |
+
ray_trainer.py # the training loop for RL algorithms such as PPO
|
| 220 |
+
fsdp_sft_trainer.py # the SFT trainer with FSDP backend
|
| 221 |
+
config
|
| 222 |
+
generation.yaml # configuration template for rollout
|
| 223 |
+
ppo_trainer.yaml # configuration template for the RL trainer
|
| 224 |
+
workers
|
| 225 |
+
protocol.py # the interface of DataProto
|
| 226 |
+
fsdp_workers.py # the FSDP worker interfaces: ActorRolloutRefWorker, CriticWorker, RewardModelWorker
|
| 227 |
+
megatron_workers.py # the Megatron worker interfaces: ActorRolloutRefWorker, CriticWorker, RewardModelWorker
|
| 228 |
+
actor
|
| 229 |
+
dp_actor.py # data parallel actor with FSDP backend
|
| 230 |
+
megatron_actor.py # nD parallel actor with Megatron backend
|
| 231 |
+
critic
|
| 232 |
+
dp_critic.py # data parallel critic with FSDP backend
|
| 233 |
+
megatron_critic.py # nD parallel critic with FSDP backend
|
| 234 |
+
reward_model
|
| 235 |
+
megatron
|
| 236 |
+
reward_model.py # reward model with Megatron backend
|
| 237 |
+
rollout
|
| 238 |
+
vllm
|
| 239 |
+
vllm_rollout.py # rollout with vllm backend
|
| 240 |
+
hf_rollout.py # rollout with huggingface TGI backend
|
| 241 |
+
sharding_manager
|
| 242 |
+
fsdp_ulysses.py # data and model resharding when using FSDP + ulysses
|
| 243 |
+
fsdp_vllm.py # data and model resharding when using FSDP + ulysses + vllm
|
| 244 |
+
megatron_vllm.py # data and model resharding when using Megatron + vllm
|
| 245 |
+
utils
|
| 246 |
+
dataset # datasets for SFT/RM/RL
|
| 247 |
+
reward_score # function based reward
|
| 248 |
+
gsm8k.py # reward function for gsm8k dataset
|
| 249 |
+
math.py # reward function for math dataset
|
| 250 |
+
seqlen_balancing.py # the sequence balance optimization
|
| 251 |
+
models
|
| 252 |
+
llama # Megatron implementation for llama, deepseek, mistral, etc
|
| 253 |
+
transformers # ulysses integration with transformer models such as llama, qwen, etc
|
| 254 |
+
weight_loader_registery.py # registry of weight loaders for loading hf ckpt into Megatron
|
| 255 |
+
third_party
|
| 256 |
+
vllm # adaptor for vllm's usage in RL
|
| 257 |
+
vllm_spmd # vllm >= v0.7 adaptor
|
| 258 |
+
examples # example scripts
|
| 259 |
+
tests # integration and unit tests
|
| 260 |
+
.github # the configuration of continuous integration tests
|
| 261 |
+
|
| 262 |
+
|
| 263 |
+
.. [1] HybridFlow: A Flexible and Efficient RLHF Framework: https://arxiv.org/abs/2409.19256v2
|
| 264 |
+
.. [2] Data flow graph credit to CS231n 2024 lecture 4: https://cs231n.stanford.edu/slides/2024/lecture_4.pdf
|
| 265 |
+
.. [3] PPO dataflow graph credit to 低级炼丹师 from Zhihu: https://zhuanlan.zhihu.com/p/635757674
|
| 266 |
+
.. [4] RLFlow
|
docs/index.rst
ADDED
|
@@ -0,0 +1,206 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Welcome to verl's documentation!
|
| 2 |
+
================================================
|
| 3 |
+
|
| 4 |
+
verl is a flexible, efficient and production-ready RL training framework designed for large language models (LLMs) post-training. It is an open source implementation of the `HybridFlow <https://arxiv.org/pdf/2409.19256>`_ paper.
|
| 5 |
+
|
| 6 |
+
verl is flexible and easy to use with:
|
| 7 |
+
|
| 8 |
+
- **Easy extension of diverse RL algorithms**: The hybrid programming model combines the strengths of single-controller and multi-controller paradigms to enable flexible representation and efficient execution of complex Post-Training dataflows. Allowing users to build RL dataflows in a few lines of code.
|
| 9 |
+
|
| 10 |
+
- **Seamless integration of existing LLM infra with modular APIs**: Decouples computation and data dependencies, enabling seamless integration with existing LLM frameworks, such as PyTorch FSDP, Megatron-LM, vLLM and SGLang. Moreover, users can easily extend to other LLM training and inference frameworks.
|
| 11 |
+
|
| 12 |
+
- **Flexible device mapping and parallelism**: Supports various placement of models onto different sets of GPUs for efficient resource utilization and scalability across different cluster sizes.
|
| 13 |
+
|
| 14 |
+
- Ready integration with popular HuggingFace models
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
verl is fast with:
|
| 18 |
+
|
| 19 |
+
- **State-of-the-art throughput**: By seamlessly integrating existing SOTA LLM training and inference frameworks, verl achieves high generation and training throughput.
|
| 20 |
+
|
| 21 |
+
- **Efficient actor model resharding with 3D-HybridEngine**: Eliminates memory redundancy and significantly reduces communication overhead during transitions between training and generation phases.
|
| 22 |
+
|
| 23 |
+
--------------------------------------------
|
| 24 |
+
|
| 25 |
+
.. _Contents:
|
| 26 |
+
|
| 27 |
+
.. toctree::
|
| 28 |
+
:maxdepth: 2
|
| 29 |
+
:caption: Quickstart
|
| 30 |
+
|
| 31 |
+
start/install
|
| 32 |
+
start/quickstart
|
| 33 |
+
start/multinode
|
| 34 |
+
start/ray_debug_tutorial
|
| 35 |
+
start/more_resources
|
| 36 |
+
start/agentic_rl
|
| 37 |
+
|
| 38 |
+
.. toctree::
|
| 39 |
+
:maxdepth: 2
|
| 40 |
+
:caption: Programming guide
|
| 41 |
+
|
| 42 |
+
hybrid_flow
|
| 43 |
+
single_controller
|
| 44 |
+
|
| 45 |
+
.. toctree::
|
| 46 |
+
:maxdepth: 1
|
| 47 |
+
:caption: Data Preparation
|
| 48 |
+
|
| 49 |
+
preparation/prepare_data
|
| 50 |
+
preparation/reward_function
|
| 51 |
+
|
| 52 |
+
.. toctree::
|
| 53 |
+
:maxdepth: 2
|
| 54 |
+
:caption: Configurations
|
| 55 |
+
|
| 56 |
+
examples/config
|
| 57 |
+
|
| 58 |
+
.. toctree::
|
| 59 |
+
:maxdepth: 1
|
| 60 |
+
:caption: PPO Example
|
| 61 |
+
|
| 62 |
+
examples/ppo_code_architecture
|
| 63 |
+
examples/gsm8k_example
|
| 64 |
+
examples/multi_modal_example
|
| 65 |
+
examples/skypilot_examples
|
| 66 |
+
|
| 67 |
+
.. toctree::
|
| 68 |
+
:maxdepth: 1
|
| 69 |
+
:caption: Algorithms
|
| 70 |
+
|
| 71 |
+
algo/ppo.md
|
| 72 |
+
algo/grpo.md
|
| 73 |
+
algo/collabllm.md
|
| 74 |
+
algo/dapo.md
|
| 75 |
+
algo/spin.md
|
| 76 |
+
algo/sppo.md
|
| 77 |
+
algo/entropy.md
|
| 78 |
+
algo/opo.md
|
| 79 |
+
algo/baseline.md
|
| 80 |
+
algo/gpg.md
|
| 81 |
+
algo/rollout_corr.md
|
| 82 |
+
algo/rollout_corr_math.md
|
| 83 |
+
|
| 84 |
+
.. toctree::
|
| 85 |
+
:maxdepth: 1
|
| 86 |
+
:caption: PPO Trainer and Workers
|
| 87 |
+
|
| 88 |
+
workers/ray_trainer
|
| 89 |
+
workers/fsdp_workers
|
| 90 |
+
workers/megatron_workers
|
| 91 |
+
workers/sglang_worker
|
| 92 |
+
workers/model_engine
|
| 93 |
+
|
| 94 |
+
.. toctree::
|
| 95 |
+
:maxdepth: 1
|
| 96 |
+
:caption: Performance Tuning Guide
|
| 97 |
+
|
| 98 |
+
perf/dpsk.md
|
| 99 |
+
perf/best_practices
|
| 100 |
+
perf/perf_tuning
|
| 101 |
+
README_vllm0.8.md
|
| 102 |
+
perf/device_tuning
|
| 103 |
+
perf/verl_profiler_system.md
|
| 104 |
+
perf/nsight_profiling.md
|
| 105 |
+
|
| 106 |
+
.. toctree::
|
| 107 |
+
:maxdepth: 1
|
| 108 |
+
:caption: Adding new models
|
| 109 |
+
|
| 110 |
+
advance/fsdp_extension
|
| 111 |
+
advance/megatron_extension
|
| 112 |
+
|
| 113 |
+
.. toctree::
|
| 114 |
+
:maxdepth: 1
|
| 115 |
+
:caption: Advanced Features
|
| 116 |
+
|
| 117 |
+
advance/checkpoint
|
| 118 |
+
advance/rope
|
| 119 |
+
advance/attention_implementation
|
| 120 |
+
advance/ppo_lora.rst
|
| 121 |
+
sglang_multiturn/multiturn.rst
|
| 122 |
+
sglang_multiturn/interaction_system.rst
|
| 123 |
+
advance/placement
|
| 124 |
+
advance/dpo_extension
|
| 125 |
+
examples/sandbox_fusion_example
|
| 126 |
+
advance/rollout_trace.rst
|
| 127 |
+
advance/rollout_skip.rst
|
| 128 |
+
advance/one_step_off
|
| 129 |
+
advance/agent_loop
|
| 130 |
+
advance/reward_loop
|
| 131 |
+
advance/fully_async
|
| 132 |
+
data/transfer_queue.md
|
| 133 |
+
advance/grafana_prometheus.md
|
| 134 |
+
advance/fp8.md
|
| 135 |
+
advance/async-on-policy-distill
|
| 136 |
+
|
| 137 |
+
.. toctree::
|
| 138 |
+
:maxdepth: 1
|
| 139 |
+
:caption: Hardware Support
|
| 140 |
+
|
| 141 |
+
amd_tutorial/amd_build_dockerfile_page.rst
|
| 142 |
+
amd_tutorial/amd_vllm_page.rst
|
| 143 |
+
ascend_tutorial/ascend_quick_start.rst
|
| 144 |
+
ascend_tutorial/ascend_consistency.rst
|
| 145 |
+
ascend_tutorial/ascend_profiling_zh.rst
|
| 146 |
+
ascend_tutorial/ascend_profiling_en.rst
|
| 147 |
+
ascend_tutorial/dockerfile_build_guidance.rst
|
| 148 |
+
ascend_tutorial/ascend_sglang_quick_start.rst
|
| 149 |
+
|
| 150 |
+
.. toctree::
|
| 151 |
+
:maxdepth: 1
|
| 152 |
+
:caption: API References
|
| 153 |
+
|
| 154 |
+
api/data
|
| 155 |
+
api/single_controller.rst
|
| 156 |
+
api/trainer.rst
|
| 157 |
+
api/utils.rst
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
.. toctree::
|
| 161 |
+
:maxdepth: 2
|
| 162 |
+
:caption: FAQ
|
| 163 |
+
|
| 164 |
+
faq/faq
|
| 165 |
+
|
| 166 |
+
.. toctree::
|
| 167 |
+
:maxdepth: 1
|
| 168 |
+
:caption: Development Notes
|
| 169 |
+
|
| 170 |
+
sglang_multiturn/sandbox_fusion.rst
|
| 171 |
+
|
| 172 |
+
Contribution
|
| 173 |
+
-------------
|
| 174 |
+
|
| 175 |
+
verl is free software; you can redistribute it and/or modify it under the terms
|
| 176 |
+
of the Apache License 2.0. We welcome contributions.
|
| 177 |
+
Join us on `GitHub <https://github.com/volcengine/verl>`_, `Slack <https://join.slack.com/t/verlgroup/shared_invite/zt-2w5p9o4c3-yy0x2Q56s_VlGLsJ93A6vA>`_ and `Wechat <https://raw.githubusercontent.com/eric-haibin-lin/verl-community/refs/heads/main/WeChat.JPG>`_ for discussions.
|
| 178 |
+
|
| 179 |
+
Contributions from the community are welcome! Please check out our `project roadmap <https://github.com/volcengine/verl/issues/710>`_ and `good first issues <https://github.com/volcengine/verl/issues?q=is%3Aissue%20state%3Aopen%20label%3A%22good%20first%20issue%22>`_ to see where you can contribute.
|
| 180 |
+
|
| 181 |
+
Code Linting and Formatting
|
| 182 |
+
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
| 183 |
+
|
| 184 |
+
We use pre-commit to help improve code quality. To initialize pre-commit, run:
|
| 185 |
+
|
| 186 |
+
.. code-block:: bash
|
| 187 |
+
|
| 188 |
+
pip install pre-commit
|
| 189 |
+
pre-commit install
|
| 190 |
+
|
| 191 |
+
To resolve CI errors locally, you can also manually run pre-commit by:
|
| 192 |
+
|
| 193 |
+
.. code-block:: bash
|
| 194 |
+
|
| 195 |
+
pre-commit run
|
| 196 |
+
|
| 197 |
+
Adding CI tests
|
| 198 |
+
^^^^^^^^^^^^^^^^^^^^^^^^
|
| 199 |
+
|
| 200 |
+
If possible, please add CI test(s) for your new feature:
|
| 201 |
+
|
| 202 |
+
1. Find the most relevant workflow yml file, which usually corresponds to a ``hydra`` default config (e.g. ``ppo_trainer``, ``ppo_megatron_trainer``, ``sft_trainer``, etc).
|
| 203 |
+
2. Add related path patterns to the ``paths`` section if not already included.
|
| 204 |
+
3. Minimize the workload of the test script(s) (see existing scripts for examples).
|
| 205 |
+
|
| 206 |
+
We are HIRING! Send us an `email <mailto:haibin.lin@bytedance.com>`_ if you are interested in internship/FTE opportunities in MLSys/LLM reasoning/multimodal alignment.
|
docs/perf/verl_profiler_system.md
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# verl Profiler System
|
| 2 |
+
|
| 3 |
+
Last updated: 08/18/2025.
|
| 4 |
+
|
| 5 |
+
## Architecture
|
| 6 |
+
|
| 7 |
+
The architecture of verl profiler system is like below:
|
| 8 |
+
|
| 9 |
+
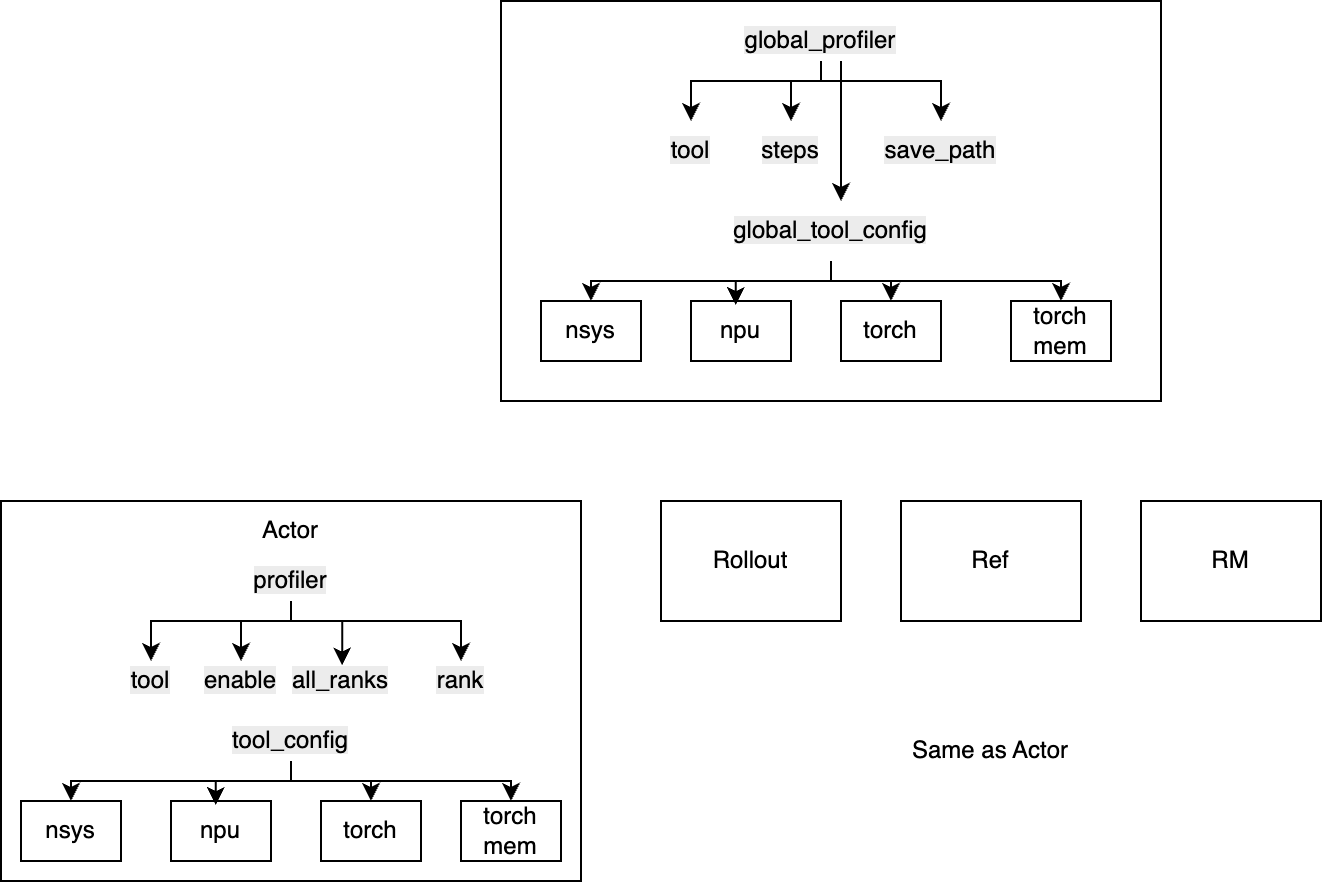
|
| 10 |
+
|
| 11 |
+
There is a global profiler and tool configuration to set some common config in single controller level, deciding
|
| 12 |
+
|
| 13 |
+
- `tool`: which tool to use
|
| 14 |
+
- `steps`: which steps to profile
|
| 15 |
+
- `save_path`: results saving path
|
| 16 |
+
|
| 17 |
+
When some tool need to profile behavior of each role, configurations in role-level is needed:
|
| 18 |
+
|
| 19 |
+
- `tool`: which tool to use
|
| 20 |
+
- `enable`: whether enable profiling on this role
|
| 21 |
+
- rank info: `all_ranks` and `rank` to decide which rank to profile or log output
|
| 22 |
+
|
| 23 |
+
For tool config in role-level, there are some detailed behavior needed to control, like the `discrete` mode in nsys profiler.
|
| 24 |
+
|
| 25 |
+
Every role has a profiler config, and by default, rollout/ref/reward models follow the Actor's behavior.
|
| 26 |
+
|
| 27 |
+
## To Add a new profiling tool
|
| 28 |
+
|
| 29 |
+
New added profiling tool shall reuse the current APIs as much as possible.
|
| 30 |
+
|
| 31 |
+
1. The logic of **whether to use the tool**: `tool == [new tool]`.
|
| 32 |
+
2. Add the global and local tool config to `ppo_trainer.yaml`/`ppo_megatron_trainer.yaml` and each `[role].yaml`, under `global_tool_config.[new tool]` and `tool_config.[new tool]`
|
| 33 |
+
3. The tool config should be implemented in `verl/utils/profiler/config.py`, inherit the `BaseConfig` class.
|
| 34 |
+
4. Implement profiling tool initialization logic using configurations in `global_profiler.global_tool_config.[new tool]` and the results saving logics (can also save in role-level profile)
|
| 35 |
+
5. For role function-level profiling, please follow the nsys profiler way in `nvtx_profiler.py`, implement a profiler class inherit `DistProfiler` and import new profiler in `verl/utils/profiler/__init__.py`
|
| 36 |
+
6. Add unit test and examples for others to use in convinience.
|
docs/sglang_multiturn/search_tool_example.rst
ADDED
|
@@ -0,0 +1,264 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
=======================
|
| 2 |
+
Search Tool Integration
|
| 3 |
+
=======================
|
| 4 |
+
|
| 5 |
+
Last updated: 05/30/2025.
|
| 6 |
+
|
| 7 |
+
Introduction
|
| 8 |
+
------------
|
| 9 |
+
- We have added a search tool calling function to Multi-Turn RL, enabling the model to initiate retrieval requests during Actor rollout and directly use retrieval results for training. **We support using a local dense retriever as the retrieval tool, as well as integrating with your own local retrieval engine.**
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
Quick Reproduction
|
| 14 |
+
------------------
|
| 15 |
+
|
| 16 |
+
Create a New Docker Container
|
| 17 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 18 |
+
|
| 19 |
+
.. code:: bash
|
| 20 |
+
|
| 21 |
+
docker run \
|
| 22 |
+
-it \
|
| 23 |
+
--shm-size 32g \
|
| 24 |
+
--gpus all \
|
| 25 |
+
-v {Huggingface-Cache-Path}:/root/.cache \
|
| 26 |
+
--ipc=host \
|
| 27 |
+
--network=host \
|
| 28 |
+
--privileged \
|
| 29 |
+
--name sglang_{your-name} \
|
| 30 |
+
lmsysorg/sglang:dev \
|
| 31 |
+
/bin/zsh
|
| 32 |
+
|
| 33 |
+
If you need to restart after exiting the container:
|
| 34 |
+
|
| 35 |
+
.. code:: bash
|
| 36 |
+
|
| 37 |
+
docker start -i sglang_{your-name}
|
| 38 |
+
|
| 39 |
+
Update Python and Configure the Virtual Environment using uv
|
| 40 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 41 |
+
|
| 42 |
+
.. code:: bash
|
| 43 |
+
|
| 44 |
+
apt update
|
| 45 |
+
apt install -y python3.10 python3.10-venv
|
| 46 |
+
|
| 47 |
+
# Create a virtual environment
|
| 48 |
+
python3 -m venv ~/.python/verl-multiturn-rollout
|
| 49 |
+
|
| 50 |
+
# Activate the virtual environment
|
| 51 |
+
source ~/.python/verl-multiturn-rollout/bin/activate
|
| 52 |
+
|
| 53 |
+
# Install uv
|
| 54 |
+
python3 -m pip install uv
|
| 55 |
+
|
| 56 |
+
Install verl Upstream
|
| 57 |
+
~~~~~~~~~~~~~~~~~~~~~
|
| 58 |
+
|
| 59 |
+
.. code:: bash
|
| 60 |
+
|
| 61 |
+
cd ~
|
| 62 |
+
git clone https://github.com/volcengine/verl.git
|
| 63 |
+
cd verl
|
| 64 |
+
|
| 65 |
+
# Install verl
|
| 66 |
+
python3 -m uv pip install .
|
| 67 |
+
python3 -m uv pip install -r ./requirements_sglang.txt
|
| 68 |
+
|
| 69 |
+
# Manually install flash-attn
|
| 70 |
+
python3 -m uv pip install wheel
|
| 71 |
+
python3 -m uv pip install packaging
|
| 72 |
+
python3 -m uv pip install flash-attn --no-build-isolation --no-deps
|
| 73 |
+
|
| 74 |
+
Set Up a Local Retrieval Engine
|
| 75 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 76 |
+
|
| 77 |
+
If you are using your own local retrieval service, you can skip this
|
| 78 |
+
step. We chose the local dense retriever provided in the search-R1
|
| 79 |
+
example; detailed instructions are in the `searchR1
|
| 80 |
+
docs <https://raw.githubusercontent.com/PeterGriffinJin/Search-R1/refs/heads/main/docs/retriever.md>`__.
|
| 81 |
+
In brief:
|
| 82 |
+
|
| 83 |
+
- The GPU version offers higher accuracy and speed; each GPU uses about
|
| 84 |
+
5–7 GB of memory.
|
| 85 |
+
- The CPU version can be used for simple testing but has lower
|
| 86 |
+
retrieval precision, which will degrade training performance. See the
|
| 87 |
+
`retriever
|
| 88 |
+
documentation <https://github.com/PeterGriffinJin/Search-R1/blob/main/docs/retriever.md>`__
|
| 89 |
+
in search-R1 for details.
|
| 90 |
+
- Recommend using Conda to install faiss-gpu=1.8.0; venv may cause errors.
|
| 91 |
+
|
| 92 |
+
**Note**: To start both the training process and the local retrieval
|
| 93 |
+
service, we launch two separate Python environments. The training uses
|
| 94 |
+
uv in the verl-multiturn-rollout environment, while the retriever uses
|
| 95 |
+
conda to install ``faiss-gpu``.
|
| 96 |
+
|
| 97 |
+
.. code:: bash
|
| 98 |
+
|
| 99 |
+
# Download the Miniconda installer script
|
| 100 |
+
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda.sh
|
| 101 |
+
|
| 102 |
+
# Install to $HOME/miniconda3 in batch mode
|
| 103 |
+
bash ~/miniconda.sh -b -p $HOME/miniconda3
|
| 104 |
+
|
| 105 |
+
# Activate conda (only in the current shell)
|
| 106 |
+
eval "$($HOME/miniconda3/bin/conda shell.bash hook)"
|
| 107 |
+
|
| 108 |
+
# (Optional) Add conda to your default shell startup
|
| 109 |
+
conda init
|
| 110 |
+
|
| 111 |
+
# Reload shell config
|
| 112 |
+
source ~/.bashrc
|
| 113 |
+
|
| 114 |
+
# Create and activate the retriever environment with Python 3.10
|
| 115 |
+
conda create -n retriever python=3.10 -y
|
| 116 |
+
conda activate retriever
|
| 117 |
+
|
| 118 |
+
# Install PyTorch (with GPU support) and related libraries
|
| 119 |
+
conda install pytorch==2.4.0 torchvision==0.19.0 torchaudio==2.4.0 pytorch-cuda=12.1 -c pytorch -c nvidia -y
|
| 120 |
+
|
| 121 |
+
# Install other Python packages
|
| 122 |
+
pip install transformers datasets pyserini huggingface_hub
|
| 123 |
+
|
| 124 |
+
# Install the GPU version of faiss
|
| 125 |
+
conda install faiss-gpu=1.8.0 -c pytorch -c nvidia -y
|
| 126 |
+
|
| 127 |
+
# Install the API service framework
|
| 128 |
+
pip install uvicorn fastapi
|
| 129 |
+
|
| 130 |
+
Download the Indexing and Corpus
|
| 131 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 132 |
+
|
| 133 |
+
The local retrieval files are large—prepare sufficient disk space.
|
| 134 |
+
Downloading is about 60–70 GB, and uncompressed takes about 132 GB:
|
| 135 |
+
|
| 136 |
+
.. code:: bash
|
| 137 |
+
|
| 138 |
+
conda activate retriever
|
| 139 |
+
|
| 140 |
+
save_path=/the/path/to/save
|
| 141 |
+
python examples/sglang_multiturn/search_r1_like/local_dense_retriever/download.py --save_path $save_path
|
| 142 |
+
cat $save_path/part_* > $save_path/e5_Flat.index
|
| 143 |
+
gzip -d $save_path/wiki-18.jsonl.gz
|
| 144 |
+
|
| 145 |
+
Start the Local flat e5 Retrieval Server
|
| 146 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 147 |
+
|
| 148 |
+
1. The first startup will download models and load the index.
|
| 149 |
+
2. Apart from the download, startup takes about 1–2 minutes.
|
| 150 |
+
3. After startup, each GPU uses about 5–7 GB of memory, leaving the rest
|
| 151 |
+
for multi-turn RL training.
|
| 152 |
+
|
| 153 |
+
.. code:: bash
|
| 154 |
+
|
| 155 |
+
conda activate retriever
|
| 156 |
+
|
| 157 |
+
index_file=$save_path/e5_Flat.index
|
| 158 |
+
corpus_file=$save_path/wiki-18.jsonl
|
| 159 |
+
retriever_name=e5
|
| 160 |
+
retriever_path=intfloat/e5-base-v2
|
| 161 |
+
|
| 162 |
+
python examples/sglang_multiturn/search_r1_like/local_dense_retriever/retrieval_server.py \
|
| 163 |
+
--index_path $index_file \
|
| 164 |
+
--corpus_path $corpus_file \
|
| 165 |
+
--topk 3 \
|
| 166 |
+
--retriever_name $retriever_name \
|
| 167 |
+
--retriever_model $retriever_path \
|
| 168 |
+
--faiss_gpu
|
| 169 |
+
|
| 170 |
+
Set Up WANDB_API_KEY
|
| 171 |
+
~~~~~~~~~~~~~~~~~~~~
|
| 172 |
+
|
| 173 |
+
.. code:: bash
|
| 174 |
+
|
| 175 |
+
export WANDB_API_KEY={YOUR_WANDB_API_KEY}
|
| 176 |
+
|
| 177 |
+
# Define a timestamp function
|
| 178 |
+
function now() {
|
| 179 |
+
date '+%Y-%m-%d-%H-%M'
|
| 180 |
+
}
|
| 181 |
+
|
| 182 |
+
**Preprocess the Dataset**
|
| 183 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 184 |
+
|
| 185 |
+
**Note:** The following data processing and training commands must be
|
| 186 |
+
run in the verl-multiturn-rollout environment.
|
| 187 |
+
|
| 188 |
+
.. code:: bash
|
| 189 |
+
|
| 190 |
+
python3 examples/data_preprocess/preprocess_search_r1_dataset.py
|
| 191 |
+
|
| 192 |
+
Testing on 8 x H20
|
| 193 |
+
~~~~~~~~~~~~~~~~~~
|
| 194 |
+
|
| 195 |
+
.. code:: bash
|
| 196 |
+
|
| 197 |
+
# Ensure the now() function is defined
|
| 198 |
+
# Create a logs directory
|
| 199 |
+
mkdir -p logs
|
| 200 |
+
|
| 201 |
+
# Set GPUs and run with a suitable log path
|
| 202 |
+
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
|
| 203 |
+
|
| 204 |
+
nohup bash examples/sglang_multiturn/search_r1_like/run_qwen2.5-3b_instruct_search_multiturn.sh \
|
| 205 |
+
trainer.experiment_name=qwen2.5-3b-it_rm-searchR1-like-sgl-multiturn-$(now) \
|
| 206 |
+
> logs/searchR1-like$(now).log 2>&1 &
|
| 207 |
+
|
| 208 |
+
Custom Search Configuration
|
| 209 |
+
---------------------------
|
| 210 |
+
|
| 211 |
+
To enable multi-turn reasoning, set the following fields in your config:
|
| 212 |
+
|
| 213 |
+
.. code:: yaml
|
| 214 |
+
|
| 215 |
+
actor_rollout_ref:
|
| 216 |
+
rollout:
|
| 217 |
+
name: "sglang"
|
| 218 |
+
multi_turn:
|
| 219 |
+
enable: True
|
| 220 |
+
|
| 221 |
+
You must specify ``retrieval_service_url`` in ``examples/sglang_multiturn/config/tool_config/search_tool_config.yaml``, and properly configure concurrency. For more details on concurrency, refer to the Sandbox Fusion example:
|
| 222 |
+
|
| 223 |
+
.. code:: yaml
|
| 224 |
+
|
| 225 |
+
tools:
|
| 226 |
+
- class_name: verl.tools.search_tool.SearchTool
|
| 227 |
+
config:
|
| 228 |
+
retrieval_service_url: http://127.0.0.1:8000/retrieve
|
| 229 |
+
num_workers: 120
|
| 230 |
+
rate_limit: 120
|
| 231 |
+
timeout: 30
|
| 232 |
+
|
| 233 |
+
The retriever input/output formats are as follows. If your service
|
| 234 |
+
parameters match, only modify ``retrieval_service_url``. You can also
|
| 235 |
+
customize in ``search_r1_like_utils.py``.
|
| 236 |
+
|
| 237 |
+
.. code:: python
|
| 238 |
+
|
| 239 |
+
Input format:
|
| 240 |
+
{
|
| 241 |
+
"queries": ["What is Python?", "Tell me about neural networks."],
|
| 242 |
+
"topk": 3,
|
| 243 |
+
"return_scores": true
|
| 244 |
+
}
|
| 245 |
+
|
| 246 |
+
Output format (when return_scores=True, similarity scores are returned):
|
| 247 |
+
{
|
| 248 |
+
"result": [
|
| 249 |
+
[ # Results for each query
|
| 250 |
+
{
|
| 251 |
+
"document": doc, "score": score
|
| 252 |
+
},
|
| 253 |
+
# ... more documents
|
| 254 |
+
],
|
| 255 |
+
# ... results for other queries
|
| 256 |
+
]
|
| 257 |
+
}
|
| 258 |
+
|
| 259 |
+
Notes
|
| 260 |
+
-----
|
| 261 |
+
|
| 262 |
+
1. The total training time is about 27 hours; meanwhile, the validation
|
| 263 |
+
dataset is very large (51 k), and each validation takes about 6000 s.
|
| 264 |
+
(Therefore, ``val_before_train=False`` by default)
|
docs/start/more_resources.rst
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
More Resources
|
| 2 |
+
==============
|
| 3 |
+
|
| 4 |
+
Last updated: 06/30/2025.
|
| 5 |
+
|
| 6 |
+
- Introduction to verl (`Slides <https://tongyx361.github.io/blogs/posts/verl-intro>`_)
|
| 7 |
+
- verl Code Walkthrough (`Slides <https://tongyx361.github.io/blogs/posts/verl-tutorial>`_, `Talk in Chinese <https://hcqnc.xetlk.com/sl/3vACOK>`_)
|
docs/start/multinode.rst
ADDED
|
@@ -0,0 +1,821 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Multinode Training
|
| 2 |
+
==================
|
| 3 |
+
|
| 4 |
+
Last updated: 06/10/2025.
|
| 5 |
+
|
| 6 |
+
.. _wuxibin89: https://github.com/wuxibin89
|
| 7 |
+
|
| 8 |
+
Author: `Xibin Wu <https://github.com/wuxibin89>`_, `Yusheng Su <https://yushengsu-thu.github.io/>`_.
|
| 9 |
+
|
| 10 |
+
Option 1: Launch Manually
|
| 11 |
+
------------------------------
|
| 12 |
+
|
| 13 |
+
Set up multinode ray cluster
|
| 14 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 15 |
+
1. Start head node with ``ray start --head --dashboard-host=0.0.0.0``, there're 2 address you should care about:
|
| 16 |
+
|
| 17 |
+
- GCS address: ``ray start --address=<address>``, where worker node should connect to.
|
| 18 |
+
- Dashboard address: ``<address>:8265``, where you should submit job to the cluster.
|
| 19 |
+
|
| 20 |
+
.. image:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/ray/head.png?raw=true
|
| 21 |
+
|
| 22 |
+
2. Start worker node with ``ray start --address=<address>`` you get above.
|
| 23 |
+
|
| 24 |
+
.. image:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/ray/worker.png?raw=true
|
| 25 |
+
|
| 26 |
+
3. Now you should see the cluster have 2 nodes with ``ray status``.
|
| 27 |
+
|
| 28 |
+
.. image:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/ray/status.png?raw=true
|
| 29 |
+
|
| 30 |
+
4. Additionally, you can access dashboard in the browser with the address you get above.
|
| 31 |
+
|
| 32 |
+
*Firewall rules maybe need configure to access the dashboard, if there's any trouble, please contact your network administrator.*
|
| 33 |
+
|
| 34 |
+
.. image:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/ray/overview.png?raw=true
|
| 35 |
+
|
| 36 |
+
Submit job to ray cluster
|
| 37 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 38 |
+
1. Submit ray job to cluster with the dashboard address you get above.
|
| 39 |
+
|
| 40 |
+
.. code-block:: bash
|
| 41 |
+
|
| 42 |
+
ray job submit --address="http://127.0.0.1:8265" \
|
| 43 |
+
--runtime-env=verl/trainer/runtime_env.yaml \
|
| 44 |
+
--no-wait \
|
| 45 |
+
-- \
|
| 46 |
+
python3 -m verl.trainer.main_ppo \
|
| 47 |
+
trainer.n_gpus_per_node=8 \
|
| 48 |
+
trainer.nnodes=2 \
|
| 49 |
+
...
|
| 50 |
+
|
| 51 |
+
.. image:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/ray/submit.png?raw=true
|
| 52 |
+
|
| 53 |
+
2. Then you can check the job status with the following commands:
|
| 54 |
+
|
| 55 |
+
- ray job list: list all jobs submitted to the cluster.
|
| 56 |
+
- ray job logs <Submission ID>: query the logs of the job.
|
| 57 |
+
- ray job status <Submission ID>: query the status of the job.
|
| 58 |
+
- ray job stop <Submission ID>: request the job to be stopped.
|
| 59 |
+
- ray job list | grep submission_id | grep JobStatus | grep RUNNING | grep -oP 'raysubmit_[^'\''"]+' | head -n 1: get the latest job submission ID of the running job.
|
| 60 |
+
- ray job logs <Submission ID> --follow: added ``--follow`` parameter to ray job logs command to enable continuous log streaming.
|
| 61 |
+
|
| 62 |
+
3. You can also access driver/task/actor logs in ``/tmp/ray/session_latest/logs/``, driver log is ``job-driver-raysubmit_<Submission ID>.log``.
|
| 63 |
+
|
| 64 |
+
4. We strongly recommend you to view job detail from dashboard in multinode training, because it provide more structure way to view the job information.
|
| 65 |
+
|
| 66 |
+
.. image:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/ray/job.png?raw=true
|
| 67 |
+
.. image:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/ray/job_detail.png?raw=true
|
| 68 |
+
|
| 69 |
+
Option 2: Launch via SkyPilot on Kubernetes or clouds
|
| 70 |
+
------------------------------------------------------
|
| 71 |
+
|
| 72 |
+
.. note::
|
| 73 |
+
Ready-to-use SkyPilot example configurations are available in the `examples/skypilot/ <https://github.com/volcengine/verl/tree/main/examples/skypilot>`_ directory:
|
| 74 |
+
|
| 75 |
+
- ``verl-ppo.yaml`` - PPO training with GSM8K dataset
|
| 76 |
+
- ``verl-grpo.yaml`` - GRPO training with MATH dataset
|
| 77 |
+
- ``verl-multiturn-tools.yaml`` - Multi-turn tool usage training
|
| 78 |
+
|
| 79 |
+
See the `SkyPilot examples README <https://github.com/volcengine/verl/tree/main/examples/skypilot>`_ for detailed usage instructions.
|
| 80 |
+
|
| 81 |
+
Step 1: Setup SkyPilot
|
| 82 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 83 |
+
SkyPilot can support different clouds, here we use GCP as example. `install skypilot <https://docs.skypilot.co/en/latest/getting-started/installation.html>`_
|
| 84 |
+
|
| 85 |
+
.. code-block:: bash
|
| 86 |
+
|
| 87 |
+
conda create -y -n sky python=3.10
|
| 88 |
+
conda activate sky
|
| 89 |
+
pip install "skypilot[gcp]"
|
| 90 |
+
|
| 91 |
+
conda install -c conda-forge google-cloud-sdk
|
| 92 |
+
gcloud init
|
| 93 |
+
|
| 94 |
+
# Run this if you don't have a credential file.
|
| 95 |
+
# This will generate ~/.config/gcloud/application_default_credentials.json.
|
| 96 |
+
gcloud auth application-default login
|
| 97 |
+
|
| 98 |
+
# Check if the GCP credential is correctly setup.
|
| 99 |
+
sky check gcp
|
| 100 |
+
|
| 101 |
+
.. image:: https://github.com/yottalabsai/open-source/blob/main/static/verl/setup_skypilot.png?raw=true
|
| 102 |
+
|
| 103 |
+
Step 2: Prepare dataset
|
| 104 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 105 |
+
|
| 106 |
+
.. code-block:: bash
|
| 107 |
+
|
| 108 |
+
git clone https://github.com/volcengine/verl.git
|
| 109 |
+
cd examples/data_preprocess
|
| 110 |
+
python3 gsm8k.py --local_save_dir ~/data/gsm8k
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
Step 3: Submit a job with SkyPilot
|
| 114 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 115 |
+
1. Create a SkyPilot YAML ``verl-cluster.yml`` with the following content:
|
| 116 |
+
|
| 117 |
+
.. parsed-literal:: workdir: . will sync all the data in the current dir to the remote cluster.
|
| 118 |
+
|
| 119 |
+
.. code-block:: yaml
|
| 120 |
+
|
| 121 |
+
resources:
|
| 122 |
+
accelerators: L4:1 # every node has 1 L4 GPU
|
| 123 |
+
image_id: docker:verlai/verl:base-verl0.5-cu126-cudnn9.8-torch2.7.0-fa2.7.4
|
| 124 |
+
memory: 64+ # every node has 64 GB memory
|
| 125 |
+
ports: 8265 # expose port for ray dashboard
|
| 126 |
+
|
| 127 |
+
num_nodes: 2 # cluster size
|
| 128 |
+
|
| 129 |
+
# --------------- Work Directory Synchronization (workdir) ---------------
|
| 130 |
+
# Defines the local working directory to be synchronized to the remote cluster.
|
| 131 |
+
# Here, '.' means synchronizing the directory where the sky submit command is currently run.
|
| 132 |
+
workdir: .
|
| 133 |
+
|
| 134 |
+
# --------------- (secrets) ---------------
|
| 135 |
+
secrets:
|
| 136 |
+
## your wandb api key ##
|
| 137 |
+
WANDB_API_KEY: null
|
| 138 |
+
|
| 139 |
+
# --------------- File Mounts/Data Upload (file_mounts) ---------------
|
| 140 |
+
# If your dataset (gsm8k folder) is local, it needs to be uploaded to the remote cluster.
|
| 141 |
+
file_mounts:
|
| 142 |
+
# Remote path (relative to remote user's home directory): Local path
|
| 143 |
+
# /remote/dir1/file: /local/dir1/file
|
| 144 |
+
data/gsm8k: ~/data/gsm8k
|
| 145 |
+
|
| 146 |
+
# --------------- Environment Setup (setup) ---------------
|
| 147 |
+
# Commands run on each node of the remote cluster to set up the environment (e.g., install dependencies). These are run directly inside Docker.
|
| 148 |
+
setup: |
|
| 149 |
+
rm -rf verl
|
| 150 |
+
git clone https://github.com/volcengine/verl.git
|
| 151 |
+
cd verl
|
| 152 |
+
pip3 install -v -e .[vllm]
|
| 153 |
+
|
| 154 |
+
# --------------- Run Command (run) ---------------
|
| 155 |
+
# The actual task commands to be executed on the remote cluster.
|
| 156 |
+
# This script will first start the Ray cluster (different ray start commands are executed on Head and Worker nodes).
|
| 157 |
+
# Then, your training script will only be run on the Head node (SKYPILOT_NODE_RANK == 0).
|
| 158 |
+
run: |
|
| 159 |
+
# Get the Head node's IP and total number of nodes (environment variables injected by SkyPilot).
|
| 160 |
+
head_ip=`echo "$SKYPILOT_NODE_IPS" | head -n1`
|
| 161 |
+
num_nodes=`echo "$SKYPILOT_NODE_IPS" | wc -l` # Here num_nodes should be equal to 2.
|
| 162 |
+
|
| 163 |
+
# login wandb
|
| 164 |
+
python3 -c "import wandb; wandb.login(relogin=True, key='$WANDB_API_KEY')"
|
| 165 |
+
|
| 166 |
+
# Start Ray based on node role (Head=0, Worker>0).
|
| 167 |
+
# This logic is a standard Ray cluster startup script.
|
| 168 |
+
if [ "$SKYPILOT_NODE_RANK" == "0" ]; then
|
| 169 |
+
# Head node starts Ray Head.
|
| 170 |
+
echo "Starting Ray head node..."
|
| 171 |
+
# Check if a Ray Head is already running to avoid duplicate starts.
|
| 172 |
+
ps aux | grep ray | grep 6379 &> /dev/null || ray start --head --disable-usage-stats \
|
| 173 |
+
--port=6379 \
|
| 174 |
+
--dashboard-host=0.0.0.0 \
|
| 175 |
+
--dashboard-port=8265
|
| 176 |
+
|
| 177 |
+
# Wait for all worker nodes to join the cluster.
|
| 178 |
+
while [ $(ray nodes | grep NODE_ID | wc -l) -lt $num_nodes ]; do
|
| 179 |
+
echo "Waiting for all nodes to join... ($(ray nodes | grep NODE_ID | wc -l)/$num_nodes)"
|
| 180 |
+
sleep 5
|
| 181 |
+
done
|
| 182 |
+
|
| 183 |
+
# Head node executes the training script.
|
| 184 |
+
echo "Executing training script on head node..."
|
| 185 |
+
|
| 186 |
+
python3 -m verl.trainer.main_ppo \
|
| 187 |
+
data.train_files=data/gsm8k/train.parquet \
|
| 188 |
+
data.val_files=data/gsm8k/test.parquet \
|
| 189 |
+
data.train_batch_size=256 \
|
| 190 |
+
data.max_prompt_length=512 \
|
| 191 |
+
data.max_response_length=256 \
|
| 192 |
+
actor_rollout_ref.model.path=Qwen/Qwen2.5-0.5B-Instruct \
|
| 193 |
+
actor_rollout_ref.actor.optim.lr=1e-6 \
|
| 194 |
+
actor_rollout_ref.actor.ppo_mini_batch_size=64 \
|
| 195 |
+
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=4 \
|
| 196 |
+
actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=8 \
|
| 197 |
+
actor_rollout_ref.rollout.tensor_model_parallel_size=1 \
|
| 198 |
+
actor_rollout_ref.rollout.name=vllm \
|
| 199 |
+
actor_rollout_ref.rollout.gpu_memory_utilization=0.4 \
|
| 200 |
+
actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=4 \
|
| 201 |
+
critic.optim.lr=1e-5 \
|
| 202 |
+
critic.model.path=Qwen/Qwen2.5-0.5B-Instruct \
|
| 203 |
+
critic.ppo_micro_batch_size_per_gpu=4 \
|
| 204 |
+
algorithm.kl_ctrl.kl_coef=0.001 \
|
| 205 |
+
trainer.logger=['console','wandb'] \
|
| 206 |
+
trainer.val_before_train=False \
|
| 207 |
+
trainer.default_hdfs_dir=null \
|
| 208 |
+
trainer.n_gpus_per_node=1 \
|
| 209 |
+
trainer.nnodes=2 \
|
| 210 |
+
trainer.save_freq=20 \
|
| 211 |
+
trainer.test_freq=20 \
|
| 212 |
+
trainer.total_epochs=2 \
|
| 213 |
+
trainer.project_name=verl_examples \
|
| 214 |
+
trainer.experiment_name=experiment_name_gsm8k
|
| 215 |
+
|
| 216 |
+
else
|
| 217 |
+
# Wait for Ray Head to start.
|
| 218 |
+
sleep 10 # Increase waiting time to ensure Head finishes starting.
|
| 219 |
+
# Worker node starts Ray Worker.
|
| 220 |
+
echo "Starting Ray worker node..."
|
| 221 |
+
|
| 222 |
+
# Check if a Ray Worker is already running to avoid duplicate starts.
|
| 223 |
+
ps aux | grep ray | grep $head_ip:6379 &> /dev/null || ray start --address $head_ip:6379 --disable-usage-stats
|
| 224 |
+
|
| 225 |
+
# Add sleep to after `ray start` to give ray enough time to daemonize
|
| 226 |
+
sleep 5 # Ensure Worker successfully connects to Head.
|
| 227 |
+
fi
|
| 228 |
+
|
| 229 |
+
# No commands are added to the Worker node here; the Worker's main task is to start Ray and wait for the Head node to assign tasks.
|
| 230 |
+
echo "Node setup and Ray start script finished for rank $SKYPILOT_NODE_RANK."
|
| 231 |
+
|
| 232 |
+
|
| 233 |
+
.. code-block:: bash
|
| 234 |
+
|
| 235 |
+
export WANDB_API_KEY=<your-wandb-api-key>
|
| 236 |
+
sky launch -c verl --secret WANDB_API_KEY verl-cluster.yml
|
| 237 |
+
|
| 238 |
+
.. image:: https://github.com/yottalabsai/open-source/blob/main/static/verl/running_job.png?raw=true
|
| 239 |
+
.. image:: https://github.com/yottalabsai/open-source/blob/main/static/verl/running_job_1.png?raw=true
|
| 240 |
+
.. image:: https://github.com/yottalabsai/open-source/blob/main/static/verl/finished.png?raw=true
|
| 241 |
+
|
| 242 |
+
**Check the cluster on GCP**
|
| 243 |
+
|
| 244 |
+
.. image:: https://github.com/yottalabsai/open-source/blob/main/static/verl/gcp_instances.png?raw=true
|
| 245 |
+
|
| 246 |
+
**Check Ray Dashboard**
|
| 247 |
+
|
| 248 |
+
We can see the cluster on the RAY Dashboard with the GCP head node:
|
| 249 |
+
|
| 250 |
+
```console
|
| 251 |
+
$ sky status --endpoint 8265 verl
|
| 252 |
+
1.2.3.4:8265
|
| 253 |
+
```
|
| 254 |
+
|
| 255 |
+
.. image:: https://github.com/yottalabsai/open-source/blob/main/static/verl/ray_dashboard_overview.png?raw=true
|
| 256 |
+
.. image:: https://github.com/yottalabsai/open-source/blob/main/static/verl/ray_dashboard_jobs.png?raw=true
|
| 257 |
+
.. image:: https://github.com/yottalabsai/open-source/blob/main/static/verl/ray_dashboard_cluster.png?raw=true
|
| 258 |
+
|
| 259 |
+
|
| 260 |
+
**Check the checkpoint of model**
|
| 261 |
+
|
| 262 |
+
.. code-block:: bash
|
| 263 |
+
|
| 264 |
+
# login the head node
|
| 265 |
+
ssh verl
|
| 266 |
+
# The global step will vary. Find the correct path from the training logs.
|
| 267 |
+
cd ~/sky_workdir/checkpoints/verl_examples/gsm8k/
|
| 268 |
+
# Then list contents to find the checkpoint, e.g.:
|
| 269 |
+
ls -R .
|
| 270 |
+
|
| 271 |
+
.. image:: https://github.com/yottalabsai/open-source/blob/main/static/verl/saved_model.png?raw=true
|
| 272 |
+
|
| 273 |
+
|
| 274 |
+
Option 3: Launch via Slurm
|
| 275 |
+
------------------------------
|
| 276 |
+
|
| 277 |
+
Ray provides users with `this <https://docs.ray.io/en/latest/cluster/vms/user-guides/community/slurm.html>`_ official
|
| 278 |
+
tutorial to start a Ray cluster on top of Slurm. We have verified the :doc:`GSM8K example<../examples/gsm8k_example>`
|
| 279 |
+
on a Slurm cluster under a multi-node setting with the following steps.
|
| 280 |
+
|
| 281 |
+
1. [Optional] If your cluster support `Apptainer or Singularity <https://apptainer.org/docs/user/main/>`_ and you wish
|
| 282 |
+
to use it, convert verl's Docker image to an Apptainer image. Alternatively, set up the environment with the package
|
| 283 |
+
manager available on your cluster or use other container runtimes (e.g. through `Slurm's OCI support <https://slurm.schedmd.com/containers.html>`_) available to you.
|
| 284 |
+
|
| 285 |
+
.. code:: bash
|
| 286 |
+
|
| 287 |
+
apptainer pull /your/dest/dir/vemlp-th2.4.0-cu124-vllm0.6.3-ray2.10-te1.7-v0.0.3.sif docker://verlai/verl:vemlp-th2.4.0-cu124-vllm0.6.3-ray2.10-te1.7-v0.0.3
|
| 288 |
+
|
| 289 |
+
2. Follow :doc:`GSM8K example<../examples/gsm8k_example>` to prepare the dataset and model checkpoints.
|
| 290 |
+
|
| 291 |
+
3. Modify `examples/slurm/ray_on_slurm.slurm <https://github.com/volcengine/verl/blob/main/examples/slurm/ray_on_slurm.slurm>`_ with your cluster's own information.
|
| 292 |
+
|
| 293 |
+
4. Submit the job script to the Slurm cluster with `sbatch`.
|
| 294 |
+
|
| 295 |
+
Please note that Slurm cluster setup may vary. If you encounter any issues, please refer to Ray's
|
| 296 |
+
`Slurm user guide <https://docs.ray.io/en/latest/cluster/vms/user-guides/community/slurm.html>`_ for common caveats.
|
| 297 |
+
|
| 298 |
+
If you changed Slurm resource specifications, please make sure to update the environment variables in the job script if necessary.
|
| 299 |
+
|
| 300 |
+
|
| 301 |
+
Option 4: Launch via dstack
|
| 302 |
+
------------------------------
|
| 303 |
+
|
| 304 |
+
`dstackai/dstack <https://github.com/dstackai/dstack>`_ is an open-source container orchestrator that simplifies distributed training across cloud providers and on-premises environments
|
| 305 |
+
without the need to use K8S or Slurm.
|
| 306 |
+
|
| 307 |
+
Prerequisite
|
| 308 |
+
~~~~~~~~~~~~
|
| 309 |
+
Once dstack is `installed <https://dstack.ai/docs/installation>`_, initialize the directory as a repo with ``dstack init``.
|
| 310 |
+
|
| 311 |
+
.. code-block:: bash
|
| 312 |
+
|
| 313 |
+
mkdir myproject && cd myproject
|
| 314 |
+
dstack init
|
| 315 |
+
|
| 316 |
+
**Create a fleet**
|
| 317 |
+
|
| 318 |
+
Before submitting distributed training jobs, create a `dstack` `fleet <https://dstack.ai/docs/concepts/fleets>`_.
|
| 319 |
+
|
| 320 |
+
Run a Ray cluster task
|
| 321 |
+
~~~~~~~~~~~~~~~~~~~~~~
|
| 322 |
+
|
| 323 |
+
Once the fleet is created, define a Ray cluster task, e.g. in ``ray-cluster.dstack.yml``:
|
| 324 |
+
|
| 325 |
+
.. code-block:: yaml
|
| 326 |
+
|
| 327 |
+
type: task
|
| 328 |
+
name: ray-verl-cluster
|
| 329 |
+
|
| 330 |
+
nodes: 2
|
| 331 |
+
|
| 332 |
+
env:
|
| 333 |
+
- WANDB_API_KEY
|
| 334 |
+
- PYTHONUNBUFFERED=1
|
| 335 |
+
- CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
|
| 336 |
+
|
| 337 |
+
image: verlai/verl:app-verl0.6-transformers4.56.1-sglang0.5.2-mcore0.13.0-te2.2
|
| 338 |
+
commands:
|
| 339 |
+
- git clone https://github.com/volcengine/verl
|
| 340 |
+
- cd verl
|
| 341 |
+
- pip install --no-deps -e .
|
| 342 |
+
- pip install hf_transfer hf_xet
|
| 343 |
+
- |
|
| 344 |
+
if [ $DSTACK_NODE_RANK = 0 ]; then
|
| 345 |
+
python3 examples/data_preprocess/gsm8k.py --local_save_dir ~/data/gsm8k
|
| 346 |
+
python3 -c "import transformers; transformers.pipeline('text-generation', model='Qwen/Qwen2.5-7B-Instruct')"
|
| 347 |
+
ray start --head --port=6379;
|
| 348 |
+
else
|
| 349 |
+
ray start --address=$DSTACK_MASTER_NODE_IP:6379
|
| 350 |
+
fi
|
| 351 |
+
|
| 352 |
+
# Expose Ray dashboard port
|
| 353 |
+
ports:
|
| 354 |
+
- 8265
|
| 355 |
+
|
| 356 |
+
resources:
|
| 357 |
+
gpu: 80GB:8
|
| 358 |
+
shm_size: 128GB
|
| 359 |
+
|
| 360 |
+
# Save checkpoints on the instance
|
| 361 |
+
volumes:
|
| 362 |
+
- /checkpoints:/checkpoints
|
| 363 |
+
|
| 364 |
+
Now, if you run this task via `dstack apply`, it will automatically forward the Ray's dashboard port to `localhost:8265`.
|
| 365 |
+
|
| 366 |
+
.. code-block:: bash
|
| 367 |
+
|
| 368 |
+
dstack apply -f ray-cluster.dstack.yml
|
| 369 |
+
|
| 370 |
+
As long as the `dstack apply` is attached, you can use `localhost:8265` to submit Ray jobs for execution
|
| 371 |
+
|
| 372 |
+
Submit Ray jobs
|
| 373 |
+
~~~~~~~~~~~~~~~
|
| 374 |
+
|
| 375 |
+
Before you can submit Ray jobs, ensure to install `ray` locally:
|
| 376 |
+
|
| 377 |
+
.. code-block:: shell
|
| 378 |
+
|
| 379 |
+
pip install ray
|
| 380 |
+
|
| 381 |
+
Now you can submit the training job to the Ray cluster which is available at ``localhost:8265``:
|
| 382 |
+
|
| 383 |
+
.. code-block:: shell
|
| 384 |
+
|
| 385 |
+
$ RAY_ADDRESS=http://localhost:8265
|
| 386 |
+
$ ray job submit \
|
| 387 |
+
-- python3 -m verl.trainer.main_ppo \
|
| 388 |
+
data.train_files=/root/data/gsm8k/train.parquet \
|
| 389 |
+
data.val_files=/root/data/gsm8k/test.parquet \
|
| 390 |
+
data.train_batch_size=256 \
|
| 391 |
+
data.max_prompt_length=512 \
|
| 392 |
+
data.max_response_length=256 \
|
| 393 |
+
actor_rollout_ref.model.path=Qwen/Qwen2.5-7B-Instruct \
|
| 394 |
+
actor_rollout_ref.actor.optim.lr=1e-6 \
|
| 395 |
+
actor_rollout_ref.actor.ppo_mini_batch_size=64 \
|
| 396 |
+
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=4 \
|
| 397 |
+
actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=8 \
|
| 398 |
+
actor_rollout_ref.rollout.tensor_model_parallel_size=1 \
|
| 399 |
+
actor_rollout_ref.rollout.gpu_memory_utilization=0.4 \
|
| 400 |
+
actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=4 \
|
| 401 |
+
critic.optim.lr=1e-5 \
|
| 402 |
+
critic.model.path=Qwen/Qwen2.5-7B-Instruct \
|
| 403 |
+
critic.ppo_micro_batch_size_per_gpu=4 \
|
| 404 |
+
algorithm.kl_ctrl.kl_coef=0.001 \
|
| 405 |
+
trainer.project_name=ppo_training \
|
| 406 |
+
trainer.experiment_name=qwen-2.5-7B \
|
| 407 |
+
trainer.val_before_train=False \
|
| 408 |
+
trainer.n_gpus_per_node=8 \
|
| 409 |
+
trainer.nnodes=2 \
|
| 410 |
+
trainer.default_local_dir=/checkpoints \
|
| 411 |
+
trainer.save_freq=10 \
|
| 412 |
+
trainer.test_freq=10 \
|
| 413 |
+
trainer.total_epochs=15 2>&1 | tee verl_demo.log \
|
| 414 |
+
trainer.resume_mode=disable
|
| 415 |
+
|
| 416 |
+
|
| 417 |
+
For more details on how `dstack` works, check out its `documentation <https://dstack.ai/docs>`_.
|
| 418 |
+
|
| 419 |
+
How to debug?
|
| 420 |
+
---------------------
|
| 421 |
+
|
| 422 |
+
|
| 423 |
+
Ray Distributed Debugger VSCode Extension (Recommended)
|
| 424 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 425 |
+
|
| 426 |
+
1. Starting with Ray 2.39, Anyscale has introduced the `Ray Distributed Debugger <https://docs.ray.io/en/latest/ray-observability/ray-distributed-debugger.html>`_ VSCode extension. Follow the extension’s installation instructions, then add your cluster using the dashboard URL you obtained earlier.
|
| 427 |
+
|
| 428 |
+
.. image:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/ray/debugger.png?raw=true
|
| 429 |
+
:alt: Ray Distributed Debugger VSCode extension screenshot
|
| 430 |
+
|
| 431 |
+
2. Prerequisites.
|
| 432 |
+
|
| 433 |
+
Ensure the following are installed (see the extension README for more detail):
|
| 434 |
+
|
| 435 |
+
- Visual Studio Code
|
| 436 |
+
- `ray[default]` >= 2.9.1
|
| 437 |
+
- `debugpy` >= 1.8.0
|
| 438 |
+
|
| 439 |
+
.. image:: https://github.com/aoshen524/verl/blob/main/docs/start/c7098b755ff689859837773a916c857.png?raw=true
|
| 440 |
+
:alt: VSCode with Ray prerequisites
|
| 441 |
+
|
| 442 |
+
3. Environment Variables.
|
| 443 |
+
|
| 444 |
+
To enable post‑mortem debugging, set:
|
| 445 |
+
|
| 446 |
+
.. code-block:: bash
|
| 447 |
+
|
| 448 |
+
export RAY_DEBUG_POST_MORTEM=1
|
| 449 |
+
|
| 450 |
+
.. admonition:: Note
|
| 451 |
+
:class: important
|
| 452 |
+
|
| 453 |
+
Be sure to remove any legacy flags before starting Ray:
|
| 454 |
+
|
| 455 |
+
- `RAY_DEBUG=legacy`
|
| 456 |
+
- `--ray-debugger-external`
|
| 457 |
+
|
| 458 |
+
4. Configuring BreakpointsSet up breakpoint() in your code, and submit job to cluster. Then the extension will show the breakpoint information.
|
| 459 |
+
|
| 460 |
+
|
| 461 |
+
1. Insert `breakpoint()` calls into your remote functions.
|
| 462 |
+
2. Submit your job to the cluster.
|
| 463 |
+
|
| 464 |
+
The extension will detect active breakpoints and display them in VSCode.
|
| 465 |
+
|
| 466 |
+
.. image:: https://github.com/aoshen524/verl/blob/main/docs/start/4ddad74395c79a1402331c0ce73316f.png?raw=true
|
| 467 |
+
:alt: Detected breakpoint in VSCode
|
| 468 |
+
|
| 469 |
+
**Note:** Breakpoints are only supported inside functions decorated with `@ray.remote`.
|
| 470 |
+
|
| 471 |
+
5. Launching the Debugger.
|
| 472 |
+
|
| 473 |
+
Run your job directly from the command line (do not use a `launch.json`):
|
| 474 |
+
|
| 475 |
+
.. code-block:: bash
|
| 476 |
+
|
| 477 |
+
python job.py
|
| 478 |
+
|
| 479 |
+
6. Attaching to a Breakpoint.
|
| 480 |
+
|
| 481 |
+
Once the process hits the first `breakpoint()`, click the Ray Distributed Debugger icon in the VSCode sidebar to attach the debugger.
|
| 482 |
+
|
| 483 |
+
.. image:: https://github.com/aoshen524/verl/blob/main/docs/start/4ddad74395c79a1402331c0ce73316f.png?raw=true
|
| 484 |
+
:alt: Attaching VSCode debugger to Ray process
|
| 485 |
+
|
| 486 |
+
7. Debugging With Multiple breakpoint().
|
| 487 |
+
|
| 488 |
+
For each subsequent task, first disconnect the current debugger session, then click the extension icon again to attach to the next breakpoint.
|
| 489 |
+
|
| 490 |
+
.. image:: https://github.com/aoshen524/verl/blob/main/docs/start/6e83c910a62c82fecb89c6619e001cd.png?raw=true
|
| 491 |
+
:alt: Disconnecting and reconnecting the debugger
|
| 492 |
+
|
| 493 |
+
Legacy Ray Debugger
|
| 494 |
+
~~~~~~~~~~~~~~~~~~~
|
| 495 |
+
1. Ray has a builtin legacy `debugger <https://docs.ray.io/en/latest/ray-observability/user-guides/debug-apps/ray-debugging.html>`_ that allows you to debug your distributed applications. To enable debugger, start ray cluster with ``RAY_DEBUG=legacy`` and ``--ray-debugger-external``.
|
| 496 |
+
|
| 497 |
+
.. code-block:: bash
|
| 498 |
+
|
| 499 |
+
# start head node
|
| 500 |
+
RAY_DEBUG=legacy ray start --head --dashboard-host=0.0.0.0 --ray-debugger-external
|
| 501 |
+
# start worker node
|
| 502 |
+
RAY_DEBUG=legacy ray start --address='10.124.46.192:6379' --ray-debugger-external
|
| 503 |
+
|
| 504 |
+
2. Set up breakpoint in your code, and submit job to cluster. Then run ``ray debug`` to wait breakpoint:
|
| 505 |
+
|
| 506 |
+
.. image:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/ray/legacy.png?raw=true
|
| 507 |
+
|
| 508 |
+
|
| 509 |
+
Multi-node training on AMD clusters
|
| 510 |
+
---------------------------------------------------------------------------------------
|
| 511 |
+
|
| 512 |
+
If you want to run multi-node training with slurm with Docker/Podman container on AMD Cluster, you can use the following script.
|
| 513 |
+
|
| 514 |
+
If you encounter any issues in using AMD GPUs running verl, please contact `Yusheng Su <https://yushengsu-thu.github.io/>`_.
|
| 515 |
+
|
| 516 |
+
.. note::
|
| 517 |
+
1. You need to use ``podman`` or ``docker`` in the following script. We will release the apptainer script later.
|
| 518 |
+
2. If you want to use ``podman``, you just replace ``docker`` with ``podman`` in the following script.
|
| 519 |
+
|
| 520 |
+
The script includes the following steps:
|
| 521 |
+
|
| 522 |
+
1. SLURM Configuration
|
| 523 |
+
2. Environment Setup
|
| 524 |
+
3. Docker/Podman Container Setup
|
| 525 |
+
4. Ray Cluster Initialization
|
| 526 |
+
5. Data Preprocessing
|
| 527 |
+
6. Model Setup
|
| 528 |
+
7. Training Launch
|
| 529 |
+
|
| 530 |
+
|
| 531 |
+
slurm_script.sh
|
| 532 |
+
~~~~~~~~~~~~~~~~~~~~
|
| 533 |
+
|
| 534 |
+
.. code-block:: bash
|
| 535 |
+
|
| 536 |
+
#!/bin/bash
|
| 537 |
+
|
| 538 |
+
#SBATCH --job-name=verl-ray-on-slurm
|
| 539 |
+
#SBATCH --nodes=2
|
| 540 |
+
#SBATCH --ntasks-per-node=2
|
| 541 |
+
#SBATCH --mem=200G
|
| 542 |
+
#SBATCH --time=30-00:00:00
|
| 543 |
+
#SBATCH --gpus-per-node=8
|
| 544 |
+
#SBATCH --cpus-per-task=28
|
| 545 |
+
#SBATCH --output=../verl_log/slurm-%j.out
|
| 546 |
+
#SBATCH --error=../verl_log/slurm-%j.err
|
| 547 |
+
#SBATCH --nodelist=gpu-[0,1]
|
| 548 |
+
|
| 549 |
+
|
| 550 |
+
# load necessary modules
|
| 551 |
+
### Run this setup
|
| 552 |
+
# [Cluster]: Use docker
|
| 553 |
+
# docker pull docker.io/rocm/vllm:rocm6.2_mi300_ubuntu20.04_py3.9_vllm_0.6.4
|
| 554 |
+
|
| 555 |
+
|
| 556 |
+
##########################################################################
|
| 557 |
+
###The following setting should be set in different project and cluster###
|
| 558 |
+
##########################################################################
|
| 559 |
+
|
| 560 |
+
### Project
|
| 561 |
+
CONTAINER_NAME="multinode_verl_training"
|
| 562 |
+
IMG="verl.rocm"
|
| 563 |
+
DOCKERFILE="docker/Dockerfile.rocm"
|
| 564 |
+
# echo $PWD
|
| 565 |
+
verl_workdir="${HOME}/projects/verl_upstream"
|
| 566 |
+
export TRANSFORMERS_CACHE="${HOME}/.cache/huggingface"
|
| 567 |
+
export HF_HOME=$TRANSFORMERS_CACHE
|
| 568 |
+
|
| 569 |
+
### Cluster Network Setting
|
| 570 |
+
export NCCL_DEBUG=TRACE
|
| 571 |
+
export GPU_MAX_HW_QUEUES=2
|
| 572 |
+
export TORCH_NCCL_HIGH_PRIORITY=1
|
| 573 |
+
export NCCL_CHECKS_DISABLE=1
|
| 574 |
+
# export NCCL_IB_HCA=rdma0,rdma1,rdma2,rdma3,rdma4,rdma5,rdma6,rdma7
|
| 575 |
+
export NCCL_IB_HCA=mlx5_0,mlx5_1,mlx5_2,mlx5_3,mlx5_4,mlx5_5,mlx5_8,mlx5_9
|
| 576 |
+
export NCCL_IB_GID_INDEX=3
|
| 577 |
+
export NCCL_CROSS_NIC=0
|
| 578 |
+
export CUDA_DEVICE_MAX_CONNECTIONS=1
|
| 579 |
+
export NCCL_PROTO=Simple
|
| 580 |
+
export RCCL_MSCCL_ENABLE=0
|
| 581 |
+
export TOKENIZERS_PARALLELISM=false
|
| 582 |
+
export HSA_NO_SCRATCH_RECLAIM=1
|
| 583 |
+
##########################################################################
|
| 584 |
+
|
| 585 |
+
### For rocm and training script
|
| 586 |
+
export HIP_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
|
| 587 |
+
export ROCR_VISIBLE_DEVICES=$HIP_VISIBLE_DEVICES
|
| 588 |
+
export CUDA_VISIBLE_DEVICES=$HIP_VISIBLE_DEVICES
|
| 589 |
+
|
| 590 |
+
|
| 591 |
+
# Build and launch the Docker container
|
| 592 |
+
srun bash -c "
|
| 593 |
+
# Exit on any error
|
| 594 |
+
set -e
|
| 595 |
+
|
| 596 |
+
# Clean up dangling images (images with <none> tag)
|
| 597 |
+
docker image prune -f
|
| 598 |
+
|
| 599 |
+
# Need to pull the docker first
|
| 600 |
+
docker pull docker.io/rocm/vllm:rocm6.2_mi300_ubuntu20.04_py3.9_vllm_0.6.4
|
| 601 |
+
|
| 602 |
+
if ! docker images --format "{{.Repository}}:{{.Tag}}" | grep -q "${IMG}"; then
|
| 603 |
+
echo \"Building ${IMG} image...\"
|
| 604 |
+
docker build -f \"${DOCKERFILE}\" -t \"${IMG}\" .
|
| 605 |
+
else
|
| 606 |
+
echo \"${IMG} image already exists, skipping build\"
|
| 607 |
+
fi
|
| 608 |
+
|
| 609 |
+
# Removing old container if exists
|
| 610 |
+
docker rm \"${CONTAINER_NAME}\" 2>/dev/null || true
|
| 611 |
+
|
| 612 |
+
# Checking network devices
|
| 613 |
+
ibdev2netdev
|
| 614 |
+
|
| 615 |
+
# Launch the docker
|
| 616 |
+
docker run --rm -d \
|
| 617 |
+
-e HYDRA_FULL_ERROR=1 \
|
| 618 |
+
-e HIP_VISIBLE_DEVICES=${HIP_VISIBLE_DEVICES} \
|
| 619 |
+
-e ROCR_VISIBLE_DEVICES=${ROCR_VISIBLE_DEVICES} \
|
| 620 |
+
-e CUDA_VISIBLE_DEVICES=${CUDA_VISIBLE_DEVICES} \
|
| 621 |
+
-e NCCL_DEBUG=${NCCL_DEBUG} \
|
| 622 |
+
-e GPU_MAX_HW_QUEUES=${GPU_MAX_HW_QUEUES} \
|
| 623 |
+
-e TORCH_NCCL_HIGH_PRIORITY=${TORCH_NCCL_HIGH_PRIORITY} \
|
| 624 |
+
-e NCCL_CHECKS_DISABLE=${NCCL_CHECKS_DISABLE} \
|
| 625 |
+
-e NCCL_IB_HCA=${NCCL_IB_HCA} \
|
| 626 |
+
-e NCCL_IB_GID_INDEX=${NCCL_IB_GID_INDEX} \
|
| 627 |
+
-e NCCL_CROSS_NIC=${NCCL_CROSS_NIC} \
|
| 628 |
+
-e CUDA_DEVICE_MAX_CONNECTIONS=${CUDA_DEVICE_MAX_CONNECTIONS} \
|
| 629 |
+
-e NCCL_PROTO=${NCCL_PROTO} \
|
| 630 |
+
-e RCCL_MSCCL_ENABLE=${RCCL_MSCCL_ENABLE} \
|
| 631 |
+
-e TOKENIZERS_PARALLELISM=${TOKENIZERS_PARALLELISM} \
|
| 632 |
+
-e HSA_NO_SCRATCH_RECLAIM=${HSA_NO_SCRATCH_RECLAIM} \
|
| 633 |
+
-e TRANSFORMERS_CACHE=${TRANSFORMERS_CACHE} \
|
| 634 |
+
-e HF_HOME=${HF_HOME} \
|
| 635 |
+
--network host \
|
| 636 |
+
--device /dev/dri \
|
| 637 |
+
--device /dev/kfd \
|
| 638 |
+
--device /dev/infiniband \
|
| 639 |
+
--group-add video \
|
| 640 |
+
--cap-add SYS_PTRACE \
|
| 641 |
+
--security-opt seccomp=unconfined \
|
| 642 |
+
--privileged \
|
| 643 |
+
-v \${HOME}:\${HOME} \
|
| 644 |
+
-v \${HOME}/.ssh:/root/.ssh \
|
| 645 |
+
-w "${verl_workdir}" \
|
| 646 |
+
--shm-size 128G \
|
| 647 |
+
--name \"${CONTAINER_NAME}\" \
|
| 648 |
+
\"${IMG}\" \
|
| 649 |
+
tail -f /dev/null
|
| 650 |
+
|
| 651 |
+
echo \"Container setup completed\"
|
| 652 |
+
"
|
| 653 |
+
# (Optional): If you do not want to root mode and require assign yuorself as the user
|
| 654 |
+
# Please add `-e HOST_UID=$(id -u)` and `-e HOST_GID=$(id -g)` into the above docker launch script.
|
| 655 |
+
|
| 656 |
+
|
| 657 |
+
|
| 658 |
+
|
| 659 |
+
|
| 660 |
+
### Ray launch the nodes before training
|
| 661 |
+
|
| 662 |
+
# Getting the node names
|
| 663 |
+
nodes_array=($(scontrol show hostnames "$SLURM_JOB_NODELIST" | tr '\n' ' '))
|
| 664 |
+
|
| 665 |
+
head_node=${nodes_array[0]}
|
| 666 |
+
head_node_ip=$(srun --nodes=1 --ntasks=1 -w "$head_node" hostname --ip-address)
|
| 667 |
+
|
| 668 |
+
# if we detect a space character in the head node IP, we'll
|
| 669 |
+
# convert it to an ipv4 address. This step is optional.
|
| 670 |
+
if [[ "$head_node_ip" == *" "* ]]; then
|
| 671 |
+
IFS=' ' read -ra ADDR <<<"$head_node_ip"
|
| 672 |
+
if [[ ${#ADDR[0]} -gt 16 ]]; then
|
| 673 |
+
head_node_ip=${ADDR[1]}
|
| 674 |
+
else
|
| 675 |
+
head_node_ip=${ADDR[0]}
|
| 676 |
+
fi
|
| 677 |
+
echo "IPV6 address detected. We split the IPV4 address as $head_node_ip"
|
| 678 |
+
fi
|
| 679 |
+
|
| 680 |
+
port=6379
|
| 681 |
+
ip_head=$head_node_ip:$port
|
| 682 |
+
export ip_head
|
| 683 |
+
echo "IP Head: $ip_head"
|
| 684 |
+
|
| 685 |
+
# make sure we set environment variables before Ray initialization
|
| 686 |
+
|
| 687 |
+
# Print out all env variables
|
| 688 |
+
printenv
|
| 689 |
+
|
| 690 |
+
echo "Starting HEAD at $head_node"
|
| 691 |
+
srun --nodes=1 --ntasks=1 -w "$head_node" \
|
| 692 |
+
docker exec "${CONTAINER_NAME}" \
|
| 693 |
+
ray start --head --node-ip-address="$head_node_ip" --port=$port \
|
| 694 |
+
--dashboard-port=8266 \
|
| 695 |
+
--num-cpus "${SLURM_CPUS_PER_TASK}" --num-gpus "${SLURM_GPUS_PER_NODE}" --block &
|
| 696 |
+
# optional, though may be useful in certain versions of Ray < 1.0.
|
| 697 |
+
sleep 10
|
| 698 |
+
|
| 699 |
+
# number of nodes other than the head node
|
| 700 |
+
worker_num=$((SLURM_JOB_NUM_NODES - 1))
|
| 701 |
+
|
| 702 |
+
for ((i = 1; i <= worker_num; i++)); do
|
| 703 |
+
node_i=${nodes_array[$i]}
|
| 704 |
+
echo "Debug: Starting worker on node_i = ${node_i}"
|
| 705 |
+
if [ -z "$node_i" ]; then
|
| 706 |
+
echo "Error: Empty node name for worker $i"
|
| 707 |
+
continue
|
| 708 |
+
fi
|
| 709 |
+
echo "Starting WORKER $i at $node_i"
|
| 710 |
+
srun --nodes=1 --ntasks=1 -w "$node_i" \
|
| 711 |
+
docker exec "${CONTAINER_NAME}" \
|
| 712 |
+
ray start --address "$ip_head" --num-cpus "${SLURM_CPUS_PER_TASK}" --num-gpus "${SLURM_GPUS_PER_NODE}" --block &
|
| 713 |
+
sleep 5
|
| 714 |
+
done
|
| 715 |
+
|
| 716 |
+
|
| 717 |
+
|
| 718 |
+
|
| 719 |
+
# Ray initlization test (See whether any error in the above execution)
|
| 720 |
+
echo "Testing Ray initialization in the slurm nodes..."
|
| 721 |
+
docker exec "${CONTAINER_NAME}" python3 -c '
|
| 722 |
+
import ray
|
| 723 |
+
try:
|
| 724 |
+
ray.init(address="auto")
|
| 725 |
+
print("\n=== Ray Cluster Status ===")
|
| 726 |
+
print(f"Number of nodes: {len(ray.nodes())}")
|
| 727 |
+
for node in ray.nodes():
|
| 728 |
+
print("Node: {}, Status: {}".format(node["NodeManagerHostname"], node["Alive"]))
|
| 729 |
+
# print(f"Node: {node}")
|
| 730 |
+
ray.shutdown()
|
| 731 |
+
print("Ray initialization successful!")
|
| 732 |
+
except Exception as e:
|
| 733 |
+
print(f"Ray initialization failed: {str(e)}")
|
| 734 |
+
'
|
| 735 |
+
echo "=== Ray test completed ==="
|
| 736 |
+
######
|
| 737 |
+
|
| 738 |
+
|
| 739 |
+
|
| 740 |
+
# Run data preprocessing
|
| 741 |
+
|
| 742 |
+
echo "Starting data preprocessing..."
|
| 743 |
+
docker exec "${CONTAINER_NAME}" \
|
| 744 |
+
python3 "examples/data_preprocess/gsm8k.py" "--local_save_dir" "../data/gsm8k"
|
| 745 |
+
|
| 746 |
+
echo "Starting data preprocessing..."
|
| 747 |
+
docker exec "${CONTAINER_NAME}" \
|
| 748 |
+
python3 "examples/data_preprocess/math_dataset.py" "--local_dir" "../data/math"
|
| 749 |
+
|
| 750 |
+
train_files="../data/gsm8k/train.parquet"
|
| 751 |
+
val_files="../data/gsm8k/test.parquet"
|
| 752 |
+
|
| 753 |
+
# Download and test model
|
| 754 |
+
echo "Loading model..."
|
| 755 |
+
docker exec "${CONTAINER_NAME}" \
|
| 756 |
+
python3 -c "import transformers; transformers.pipeline('text-generation', model='Qwen/Qwen2-7B-Instruct')"
|
| 757 |
+
MODEL_PATH="Qwen/Qwen2-7B-Instruct"
|
| 758 |
+
|
| 759 |
+
# Set model path after pipeline test
|
| 760 |
+
MODEL_PATH="Qwen/Qwen2.5-0.5B-Instruct"
|
| 761 |
+
|
| 762 |
+
echo "== Data and model loading Done =="
|
| 763 |
+
|
| 764 |
+
echo "Start to train..."
|
| 765 |
+
|
| 766 |
+
docker exec "${CONTAINER_NAME}" \
|
| 767 |
+
python3 -c "import transformers; transformers.pipeline('text-generation', model='Qwen/Qwen2-7B-Instruct')"
|
| 768 |
+
MODEL_PATH="Qwen/Qwen2-7B-Instruct"
|
| 769 |
+
|
| 770 |
+
|
| 771 |
+
PYTHONUNBUFFERED=1 srun --overlap --nodes=${SLURM_NNODES} --ntasks=1 -w "$head_node" \
|
| 772 |
+
docker exec "${CONTAINER_NAME}" \
|
| 773 |
+
python3 -m verl.trainer.main_ppo \
|
| 774 |
+
data.train_files=$train_files \
|
| 775 |
+
data.val_files=$val_files \
|
| 776 |
+
data.train_batch_size=1024 \
|
| 777 |
+
data.max_prompt_length=1024 \
|
| 778 |
+
data.max_response_length=1024 \
|
| 779 |
+
actor_rollout_ref.model.path=$MODEL_PATH \
|
| 780 |
+
actor_rollout_ref.model.enable_gradient_checkpointing=False \
|
| 781 |
+
actor_rollout_ref.actor.optim.lr=1e-6 \
|
| 782 |
+
actor_rollout_ref.model.use_remove_padding=True \
|
| 783 |
+
actor_rollout_ref.actor.ppo_mini_batch_size=256 \
|
| 784 |
+
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=8 \
|
| 785 |
+
actor_rollout_ref.model.enable_gradient_checkpointing=True \
|
| 786 |
+
actor_rollout_ref.actor.fsdp_config.param_offload=False \
|
| 787 |
+
actor_rollout_ref.actor.fsdp_config.optimizer_offload=False \
|
| 788 |
+
actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=16 \
|
| 789 |
+
actor_rollout_ref.rollout.tensor_model_parallel_size=2 \
|
| 790 |
+
actor_rollout_ref.rollout.name=vllm \
|
| 791 |
+
actor_rollout_ref.rollout.gpu_memory_utilization=0.9 \
|
| 792 |
+
actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=16 \
|
| 793 |
+
actor_rollout_ref.ref.fsdp_config.param_offload=True \
|
| 794 |
+
critic.optim.lr=1e-5 \
|
| 795 |
+
critic.model.use_remove_padding=True \
|
| 796 |
+
critic.model.path=$MODEL_PATH \
|
| 797 |
+
critic.model.enable_gradient_checkpointing=False \
|
| 798 |
+
critic.ppo_micro_batch_size_per_gpu=8 \
|
| 799 |
+
critic.model.fsdp_config.param_offload=False \
|
| 800 |
+
critic.model.fsdp_config.optimizer_offload=False \
|
| 801 |
+
algorithm.kl_ctrl.kl_coef=0.0001 \
|
| 802 |
+
trainer.critic_warmup=0 \
|
| 803 |
+
trainer.logger='["console","wandb"]' \
|
| 804 |
+
trainer.project_name='verl_example' \
|
| 805 |
+
trainer.experiment_name='Qwen2.5-32B-Instruct_function_rm' \
|
| 806 |
+
trainer.n_gpus_per_node=${SLURM_GPUS_PER_NODE} \
|
| 807 |
+
trainer.val_before_train=False \
|
| 808 |
+
trainer.nnodes=${SLURM_NNODES} \
|
| 809 |
+
trainer.save_freq=-1 \
|
| 810 |
+
trainer.test_freq=10 \
|
| 811 |
+
trainer.total_epochs=15
|
| 812 |
+
|
| 813 |
+
|
| 814 |
+
Run multi-node training with above slurm_script.sh
|
| 815 |
+
~~~~~~~~~~~~~~~~~~~~
|
| 816 |
+
Just sbatch your slurm_script.sh
|
| 817 |
+
|
| 818 |
+
.. code-block:: bash
|
| 819 |
+
|
| 820 |
+
sbatch slurm_script.sh
|
| 821 |
+
|
docs/start/ray_debug_tutorial.rst
ADDED
|
@@ -0,0 +1,96 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Ray Debug Tutorial
|
| 2 |
+
==================
|
| 3 |
+
|
| 4 |
+
Last updated: 04/23/2025
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
.. _wuxibin89: https://github.com/wuxibin89
|
| 8 |
+
|
| 9 |
+
Author: `Ao Shen <https://aoshen524.github.io/>`_.
|
| 10 |
+
|
| 11 |
+
How to debug?
|
| 12 |
+
---------------------
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
Ray Distributed Debugger VSCode Extension (Recommended)
|
| 16 |
+
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
|
| 17 |
+
|
| 18 |
+
1. Starting with Ray 2.39, Anyscale has introduced the `Ray Distributed Debugger <https://docs.ray.io/en/latest/ray-observability/ray-distributed-debugger.html>`_ VSCode extension. Follow the extension’s installation instructions, then add your cluster using the dashboard URL you obtained earlier.
|
| 19 |
+
|
| 20 |
+
.. image:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/ray/debugger.png?raw=true
|
| 21 |
+
:alt: Ray Distributed Debugger VSCode extension screenshot
|
| 22 |
+
|
| 23 |
+
2. Prerequisites.
|
| 24 |
+
|
| 25 |
+
Ensure the following are installed (see the extension README for more detail):
|
| 26 |
+
|
| 27 |
+
- Visual Studio Code
|
| 28 |
+
- `ray[default]` >= 2.9.1
|
| 29 |
+
- `debugpy` >= 1.8.0
|
| 30 |
+
|
| 31 |
+
.. image:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/ray/readme.png?raw=true
|
| 32 |
+
:alt: VSCode with Ray prerequisites
|
| 33 |
+
|
| 34 |
+
3. Environment Variables.
|
| 35 |
+
|
| 36 |
+
To enable post‑mortem debugging, set:
|
| 37 |
+
|
| 38 |
+
.. code-block:: bash
|
| 39 |
+
|
| 40 |
+
export RAY_DEBUG_POST_MORTEM=1
|
| 41 |
+
|
| 42 |
+
.. admonition:: Note
|
| 43 |
+
:class: important
|
| 44 |
+
|
| 45 |
+
Be sure to remove any legacy flags before starting Ray:
|
| 46 |
+
|
| 47 |
+
- `RAY_DEBUG=legacy`
|
| 48 |
+
- `--ray-debugger-external`
|
| 49 |
+
|
| 50 |
+
4. Configuring BreakpointsSet up breakpoint() in your code, and submit job to cluster. Then the extension will show the breakpoint information.
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
1. Insert `breakpoint()` calls into your remote functions.
|
| 54 |
+
2. Submit your job to the cluster.
|
| 55 |
+
|
| 56 |
+
The extension will detect active breakpoints and display them in VSCode.
|
| 57 |
+
|
| 58 |
+
**Note:** Breakpoints are only supported inside functions decorated with `@ray.remote`.
|
| 59 |
+
|
| 60 |
+
5. Launching the Debugger.
|
| 61 |
+
|
| 62 |
+
Run your job directly from the command line (do not use a `launch.json`):
|
| 63 |
+
|
| 64 |
+
.. code-block:: bash
|
| 65 |
+
|
| 66 |
+
python job.py
|
| 67 |
+
|
| 68 |
+
6. Attaching to a Breakpoint.
|
| 69 |
+
|
| 70 |
+
Once the process hits the first `breakpoint()`, click the Ray Distributed Debugger icon in the VSCode sidebar to attach the debugger.
|
| 71 |
+
|
| 72 |
+
.. image:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/ray/launch.png?raw=true
|
| 73 |
+
:alt: Attaching VSCode debugger to Ray process
|
| 74 |
+
|
| 75 |
+
7. Debugging With Multiple breakpoint().
|
| 76 |
+
|
| 77 |
+
For each subsequent task, first disconnect the current debugger session, then click the extension icon again to attach to the next breakpoint.
|
| 78 |
+
|
| 79 |
+
.. image:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/ray/disconnect.png?raw=true
|
| 80 |
+
:alt: Disconnecting and reconnecting the debugger
|
| 81 |
+
|
| 82 |
+
Legacy Ray Debugger
|
| 83 |
+
~~~~~~~~~~~~~~~~~~~
|
| 84 |
+
1. Ray has a builtin legacy `debugger <https://docs.ray.io/en/latest/ray-observability/user-guides/debug-apps/ray-debugging.html>`_ that allows you to debug your distributed applications. To enable debugger, start ray cluster with ``RAY_DEBUG=legacy`` and ``--ray-debugger-external``.
|
| 85 |
+
|
| 86 |
+
.. code-block:: bash
|
| 87 |
+
|
| 88 |
+
# start head node
|
| 89 |
+
RAY_DEBUG=legacy ray start --head --dashboard-host=0.0.0.0 --ray-debugger-external
|
| 90 |
+
# start worker node
|
| 91 |
+
RAY_DEBUG=legacy ray start --address='10.124.46.192:6379' --ray-debugger-external
|
| 92 |
+
|
| 93 |
+
2. Set up breakpoint in your code, and submit job to cluster. Then run ``ray debug`` to wait breakpoint:
|
| 94 |
+
|
| 95 |
+
.. image:: https://github.com/eric-haibin-lin/verl-community/blob/main/docs/ray/legacy.png?raw=true
|
| 96 |
+
|
docs/workers/model_engine.rst
ADDED
|
@@ -0,0 +1,125 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Model Engine
|
| 2 |
+
============
|
| 3 |
+
|
| 4 |
+
.. _vermouth: https://github.com/vermouth1992
|
| 5 |
+
|
| 6 |
+
Author: `Chi Zhang <https://github.com/vermouth1992>`_
|
| 7 |
+
|
| 8 |
+
Last updated: 09/25/2025.
|
| 9 |
+
|
| 10 |
+
Current Support Matrix
|
| 11 |
+
----------------------
|
| 12 |
+
|
| 13 |
+
+----------+-----------+--------------+-------------+--------------------------+
|
| 14 |
+
| Backends | Model | Scalability | Model | Pain points |
|
| 15 |
+
| | Supported | | Definition | |
|
| 16 |
+
| | | | | |
|
| 17 |
+
+==========+===========+==============+=============+==========================+
|
| 18 |
+
| FSDP | Day 1 | - Dense is OK| Huggingface | Monkey patch can be |
|
| 19 |
+
| + | support | | + monkey | easily impacted by |
|
| 20 |
+
| ulysses | HF model | - MoE is bad | patch | transformers version |
|
| 21 |
+
+----------+-----------+--------------+-------------+--------------------------+
|
| 22 |
+
| MCore | Limited | Best | GPTModel | Supporting new models is |
|
| 23 |
+
| | | | (One model | difficult |
|
| 24 |
+
| | | | for all) | |
|
| 25 |
+
+----------+-----------+--------------+-------------+--------------------------+
|
| 26 |
+
|
| 27 |
+
- We monkey patch attention function to support ulysses
|
| 28 |
+
- We monkey patch VLM models to support FSDP with mixed data with and
|
| 29 |
+
without images
|
| 30 |
+
|
| 31 |
+
Class Hierarchy
|
| 32 |
+
---------------
|
| 33 |
+
|
| 34 |
+
Note that all the workers and trainers run in **SPMD** mode. SFT/DPO/RM
|
| 35 |
+
trainer is directly invoked by ``torchrun``. The Actor/Critic worker can
|
| 36 |
+
also be invoked by a RayWorkerGroup and provides APIs to a single
|
| 37 |
+
controller.
|
| 38 |
+
|
| 39 |
+
- Base Engine level: implement model init, optimizer init, lr scheduler
|
| 40 |
+
init, sharding, checkpoint manager.
|
| 41 |
+
- Full Engine level: subclass base engine and implement
|
| 42 |
+
``forward_step``.
|
| 43 |
+
- Worker/SPMD trainer level: **engine agnostic**, implement training
|
| 44 |
+
logics using abstract engine APIs
|
| 45 |
+
|
| 46 |
+
RL trainer utilizes workers to construct HybridFlow program. This is out
|
| 47 |
+
of the scope of model engine.
|
| 48 |
+
|
| 49 |
+
Existing Model Types
|
| 50 |
+
--------------------
|
| 51 |
+
|
| 52 |
+
========== ====================== ======================
|
| 53 |
+
Model type Language model Value model
|
| 54 |
+
========== ====================== ======================
|
| 55 |
+
Input text/image/video/audio text/image/video/audio
|
| 56 |
+
Output logits for next token logits as value
|
| 57 |
+
========== ====================== ======================
|
| 58 |
+
|
| 59 |
+
Currently, we have two model types: language model and value model. We
|
| 60 |
+
expect to expand the category to include Qwen-Omni family (output both
|
| 61 |
+
text and audio) and VLA models.
|
| 62 |
+
|
| 63 |
+
Data Format
|
| 64 |
+
-----------
|
| 65 |
+
|
| 66 |
+
Currently, verl adopts left-right padding data format in RL trainer.
|
| 67 |
+
This creates massive padding when the discrepancy between response
|
| 68 |
+
length is large. We will start to implement no-padding format throughout
|
| 69 |
+
the whole system.
|
| 70 |
+
|
| 71 |
+
.. image:: https://github.com/vermouth1992/verl-data/blob/master/images/data_format.png?raw=true
|
| 72 |
+
:alt: Data Format
|
| 73 |
+
|
| 74 |
+
Here is the migration plan:
|
| 75 |
+
- Implement no-padding format in engine
|
| 76 |
+
- Add a transformation layer in Actor/Critic worker.
|
| 77 |
+
- Replace Actor/Critic Worker in RL trainer
|
| 78 |
+
- Implement no-padding throughput system
|
| 79 |
+
|
| 80 |
+
Checkpoint System
|
| 81 |
+
-----------------
|
| 82 |
+
|
| 83 |
+
.. image:: https://github.com/vermouth1992/verl-data/blob/master/images/verl-ckpt.png?raw=true
|
| 84 |
+
:alt: Model Engine Checkpoint System
|
| 85 |
+
|
| 86 |
+
The engine constructs the model using huggingface config, then load
|
| 87 |
+
weights from huggingface checkpoint. If the engine directly uses
|
| 88 |
+
huggingface model definition, it can use function provided by
|
| 89 |
+
``transformers``. Otherwise, each engine has to write their own
|
| 90 |
+
checkpoint load logic (e.g.,
|
| 91 |
+
`mbridge <https://github.com/ISEEKYAN/mbridge>`__). During model
|
| 92 |
+
training, each engine has to implement save_checkpoint and
|
| 93 |
+
load_checkpoint that save/load intermediate sharded checkpoint including
|
| 94 |
+
model, optimizer and lr scheduler states. Each engine has to implement a
|
| 95 |
+
checkpoint merge script, that merges the intermediate sharded checkpoint
|
| 96 |
+
back to huggingface format.
|
| 97 |
+
|
| 98 |
+
API
|
| 99 |
+
---
|
| 100 |
+
|
| 101 |
+
A tentative model engine API can be found:
|
| 102 |
+
https://github.com/volcengine/verl/blob/main/verl/workers/engine/base.py#L24
|
| 103 |
+
|
| 104 |
+
Extension
|
| 105 |
+
---------
|
| 106 |
+
|
| 107 |
+
Add a new backend
|
| 108 |
+
~~~~~~~~~~~~~~~~~
|
| 109 |
+
|
| 110 |
+
- Start a new folder under ``verl/workers/engine``. Then, implement
|
| 111 |
+
``transformer_impl.py``. If you want to implement a non-transformer
|
| 112 |
+
model, please contact us in advance.
|
| 113 |
+
- Add the engine config to the GSM8k SFT trainer script:
|
| 114 |
+
https://github.com/volcengine/verl/blob/main/tests/special_e2e/sft/run_sft_engine_gsm8k.sh
|
| 115 |
+
- Invoke the tests with your backend:
|
| 116 |
+
https://github.com/volcengine/verl/blob/main/tests/special_e2e/sft/test_sft_engine_all.sh.
|
| 117 |
+
This test script will run various backends and various
|
| 118 |
+
configurations, and compare the loss and grad norm of the first step
|
| 119 |
+
to make sure they are close.
|
| 120 |
+
|
| 121 |
+
Add a new model type
|
| 122 |
+
~~~~~~~~~~~~~~~~~~~~
|
| 123 |
+
|
| 124 |
+
- This is mainly reserved for models whose the output is not just text
|
| 125 |
+
(e.g., Qwen3-Omni). Please discuss with us before you proceed.
|
docs/workers/ray_trainer.rst
ADDED
|
@@ -0,0 +1,241 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
PPO Ray Trainer
|
| 2 |
+
===============
|
| 3 |
+
|
| 4 |
+
Last updated: 02/12/2025.
|
| 5 |
+
|
| 6 |
+
We implement the RayPPOTrainer, which is a trainer runs on the driver
|
| 7 |
+
process on a single CPU/GPU node (default is CPU).
|
| 8 |
+
|
| 9 |
+
The PPORayTrainer include 3 core functions for data preparation,
|
| 10 |
+
WorkerGroup initialization and PPO training loop.
|
| 11 |
+
|
| 12 |
+
Data Preparation
|
| 13 |
+
----------------
|
| 14 |
+
|
| 15 |
+
The ``PPORayTrainer``, as a single process, is responsible for loading a
|
| 16 |
+
complete batch of samples (prompts) from the dataset and then dispatch
|
| 17 |
+
to different worker_groups running on different GPUs.
|
| 18 |
+
|
| 19 |
+
To generalize the data loading, we implement the ``RLHFDataset`` class
|
| 20 |
+
to load the preprocessed parquet files, apply chat templates to the
|
| 21 |
+
prompts, add padding, truncate prompts that exceed max prompt length and
|
| 22 |
+
then tokenize.
|
| 23 |
+
|
| 24 |
+
.. code:: python
|
| 25 |
+
|
| 26 |
+
self.train_dataset = RLHFDataset(data_files=self.config.data.train_files,
|
| 27 |
+
tokenizer=self.tokenizer,
|
| 28 |
+
config=self.config.data)
|
| 29 |
+
|
| 30 |
+
Then, the dataloader will iterate the dataset under PPO mini batch size.
|
| 31 |
+
|
| 32 |
+
WorkerGroup Initialization
|
| 33 |
+
--------------------------
|
| 34 |
+
|
| 35 |
+
We first introduce a basic implementation of initializing the
|
| 36 |
+
``WorkerGroup`` of the actor model on a given set of GPUs.
|
| 37 |
+
|
| 38 |
+
.. code:: python
|
| 39 |
+
|
| 40 |
+
# max_colocate_count means the number of WorkerGroups (i.e. processes) in each RayResourcePool
|
| 41 |
+
# For FSDP backend, we recommend using max_colocate_count=1 that merge all WorkerGroups into one.
|
| 42 |
+
# For Megatron backend, we recommend using max_colocate_count>1 that can utilize different WorkerGroup for differnt models
|
| 43 |
+
resource_pool = RayResourcePool(process_on_nodes=[config.trainer.n_gpus_per_node] * config.trainer.nnodes,
|
| 44 |
+
use_gpu=True,
|
| 45 |
+
max_colocate_count=1)
|
| 46 |
+
# define actor rollout cls to be init on remote
|
| 47 |
+
actor_rollout_cls = RayClassWithInitArgs(cls=ActorRolloutWorker)
|
| 48 |
+
# define actor_rollout worker group
|
| 49 |
+
actor_rollout_worker_group = MegatronRayWorkerGroup(resource_pool=resource_pool,
|
| 50 |
+
ray_cls_with_init=actor_rollout_cls,
|
| 51 |
+
default_megatron_kwargs=config.actor_rollout.megatron)
|
| 52 |
+
|
| 53 |
+
Different WorkerGroups, like ``actor_rollout_worker_group`` ,
|
| 54 |
+
``critic_worker_group`` and ``ref_worker_group`` lies on a separate
|
| 55 |
+
process in the above implementation.
|
| 56 |
+
|
| 57 |
+
The driver process can then call the distributed compute function within
|
| 58 |
+
the ``actor_rollout_worker_group`` and other roles to construct the RL
|
| 59 |
+
training loop.
|
| 60 |
+
|
| 61 |
+
For models colocated in the same set of GPUs, we further provide a
|
| 62 |
+
fine-grain optimization, which merge the ``worker_group`` of different roles
|
| 63 |
+
in the same process. This optimization can save the redundant
|
| 64 |
+
CUDA/distributed context in different processes.
|
| 65 |
+
|
| 66 |
+
.. code:: python
|
| 67 |
+
|
| 68 |
+
# initialize WorkerGroup
|
| 69 |
+
# NOTE: if you want to use a different resource pool for each role, which can support different parallel size,
|
| 70 |
+
# you should not use `create_colocated_worker_cls`. Instead, directly pass different resource pool to different worker groups.
|
| 71 |
+
# See TODO(url) for more information.
|
| 72 |
+
all_wg = {}
|
| 73 |
+
for resource_pool, class_dict in self.resource_pool_to_cls.items():
|
| 74 |
+
worker_dict_cls = create_colocated_worker_cls(class_dict=class_dict)
|
| 75 |
+
wg_dict = self.ray_worker_group_cls(resource_pool=resource_pool, ray_cls_with_init=worker_dict_cls)
|
| 76 |
+
spawn_wg = wg_dict.spawn(prefix_set=class_dict.keys())
|
| 77 |
+
all_wg.update(spawn_wg)
|
| 78 |
+
|
| 79 |
+
if self.use_critic:
|
| 80 |
+
self.critic_wg = all_wg['critic']
|
| 81 |
+
self.critic_wg.init_model()
|
| 82 |
+
|
| 83 |
+
if self.use_reference_policy:
|
| 84 |
+
self.ref_policy_wg = all_wg['ref']
|
| 85 |
+
self.ref_policy_wg.init_model()
|
| 86 |
+
|
| 87 |
+
if self.use_rm:
|
| 88 |
+
self.rm_wg = all_wg['rm']
|
| 89 |
+
self.rm_wg.init_model()
|
| 90 |
+
|
| 91 |
+
# we should create rollout at the end so that vllm can have a better estimation of kv cache memory
|
| 92 |
+
self.actor_rollout_wg = all_wg['actor_rollout']
|
| 93 |
+
self.actor_rollout_wg.init_model()
|
| 94 |
+
|
| 95 |
+
.. note:: For megatron backend, if we merge the ``worker_groups`` into the same processes, all the roles will utilize the same 3D parallel size. To optimize this, we may need to maintain several 3D process groups for each role in the same distributed context. If you want to use different 3D parallel size for different roles, please follow the similar architecture of the first code block to initialize each role's ``worker_group``
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
PPO Training Loop
|
| 99 |
+
-----------------
|
| 100 |
+
|
| 101 |
+
We implement the PPO training loop by calling the functions in
|
| 102 |
+
worker_group of each role. The input and output data of each function is
|
| 103 |
+
a ``DataProto`` object implemented in `protocol.py <https://github.com/volcengine/verl/blob/main/verl/protocol.py>`_. In the training
|
| 104 |
+
loop, trainer will dispatch/collect the data to/from different GPUs
|
| 105 |
+
following the transfer protocols wrapped in the workers' functions. The
|
| 106 |
+
computation of PPO micro batches is processed in ``update_actor`` and
|
| 107 |
+
``update_critic`` functions.
|
| 108 |
+
|
| 109 |
+
To extend to other RLHF algorithms, such as DPO, GRPO, please refer to
|
| 110 |
+
:doc:`../advance/dpo_extension`.
|
| 111 |
+
|
| 112 |
+
.. code:: python
|
| 113 |
+
|
| 114 |
+
def fit(self):
|
| 115 |
+
"""
|
| 116 |
+
The training loop of PPO.
|
| 117 |
+
The driver process only need to call the compute functions of the worker group through RPC to construct the PPO dataflow.
|
| 118 |
+
The light-weight advantage computation is done on the driver process.
|
| 119 |
+
"""
|
| 120 |
+
from verl.utils.tracking import Tracking
|
| 121 |
+
from omegaconf import OmegaConf
|
| 122 |
+
|
| 123 |
+
logger = Tracking(project_name=self.config.trainer.project_name,
|
| 124 |
+
experiment_name=self.config.trainer.experiment_name,
|
| 125 |
+
default_backend=self.config.trainer.logger,
|
| 126 |
+
config=OmegaConf.to_container(self.config, resolve=True))
|
| 127 |
+
|
| 128 |
+
global_steps = 0
|
| 129 |
+
|
| 130 |
+
# perform validation before training
|
| 131 |
+
# currently, we only support validation using the reward_function.
|
| 132 |
+
if self.val_reward_fn is not None:
|
| 133 |
+
val_metrics = self._validate()
|
| 134 |
+
pprint(f'Initial validation metrics: {val_metrics}')
|
| 135 |
+
|
| 136 |
+
for epoch in range(self.config.trainer.total_epochs):
|
| 137 |
+
for batch_dict in self.train_dataloader:
|
| 138 |
+
metrics = {}
|
| 139 |
+
|
| 140 |
+
batch: DataProto = DataProto.from_single_dict(batch_dict)
|
| 141 |
+
# batch = batch.to('cuda')
|
| 142 |
+
|
| 143 |
+
# pop those keys for generation
|
| 144 |
+
gen_batch = batch.pop(batch_keys=['input_ids', 'attention_mask', 'position_ids'])
|
| 145 |
+
|
| 146 |
+
# generate a batch
|
| 147 |
+
with Timer(name='gen', logger=None) as timer:
|
| 148 |
+
gen_batch_output = self.actor_rollout_wg.generate_sequences(gen_batch)
|
| 149 |
+
metrics['timing/gen'] = timer.last
|
| 150 |
+
|
| 151 |
+
batch = batch.union(gen_batch_output)
|
| 152 |
+
|
| 153 |
+
if self.use_reference_policy:
|
| 154 |
+
# compute reference log_prob
|
| 155 |
+
with Timer(name='ref', logger=None) as timer:
|
| 156 |
+
ref_log_prob = self.ref_policy_wg.compute_ref_log_prob(batch)
|
| 157 |
+
batch = batch.union(ref_log_prob)
|
| 158 |
+
metrics['timing/ref'] = timer.last
|
| 159 |
+
|
| 160 |
+
# compute values
|
| 161 |
+
with Timer(name='values', logger=None) as timer:
|
| 162 |
+
values = self.critic_wg.compute_values(batch)
|
| 163 |
+
batch = batch.union(values)
|
| 164 |
+
metrics['timing/values'] = timer.last
|
| 165 |
+
|
| 166 |
+
with Timer(name='adv', logger=None) as timer:
|
| 167 |
+
# compute scores. Support both model and function-based.
|
| 168 |
+
# We first compute the scores using reward model. Then, we call reward_fn to combine
|
| 169 |
+
# the results from reward model and rule-based results.
|
| 170 |
+
if self.use_rm:
|
| 171 |
+
# we first compute reward model score
|
| 172 |
+
reward_tensor = self.rm_wg.compute_rm_score(batch)
|
| 173 |
+
batch = batch.union(reward_tensor)
|
| 174 |
+
|
| 175 |
+
# we combine with rule-based rm
|
| 176 |
+
reward_tensor = self.reward_fn(batch)
|
| 177 |
+
batch.batch['token_level_scores'] = reward_tensor
|
| 178 |
+
|
| 179 |
+
# compute rewards. apply_kl_penalty if available
|
| 180 |
+
batch, kl_metrics = apply_kl_penalty(batch,
|
| 181 |
+
kl_ctrl=self.kl_ctrl_in_reward,
|
| 182 |
+
kl_penalty=self.config.algorithm.kl_penalty)
|
| 183 |
+
metrics.update(kl_metrics)
|
| 184 |
+
|
| 185 |
+
# compute advantages, executed on the driver process
|
| 186 |
+
batch = compute_advantage(batch,
|
| 187 |
+
self.config.algorithm.gamma,
|
| 188 |
+
self.config.algorithm.lam,
|
| 189 |
+
adv_estimator=self.config.algorithm.adv_estimator)
|
| 190 |
+
metrics['timing/adv'] = timer.last
|
| 191 |
+
|
| 192 |
+
# update critic
|
| 193 |
+
if self.use_critic:
|
| 194 |
+
with Timer(name='update_critic', logger=None) as timer:
|
| 195 |
+
critic_output = self.critic_wg.update_critic(batch)
|
| 196 |
+
metrics['timing/update_critic'] = timer.last
|
| 197 |
+
critic_output_metrics = reduce_metrics(critic_output.meta_info['metrics'])
|
| 198 |
+
metrics.update(critic_output_metrics)
|
| 199 |
+
|
| 200 |
+
# implement critic warmup
|
| 201 |
+
if self.config.trainer.critic_warmup <= global_steps:
|
| 202 |
+
# update actor
|
| 203 |
+
with Timer(name='update_actor', logger=None) as timer:
|
| 204 |
+
actor_output = self.actor_rollout_wg.update_actor(batch)
|
| 205 |
+
metrics['timing/update_actor'] = timer.last
|
| 206 |
+
actor_output_metrics = reduce_metrics(actor_output.meta_info['metrics'])
|
| 207 |
+
metrics.update(actor_output_metrics)
|
| 208 |
+
|
| 209 |
+
# validate
|
| 210 |
+
if self.val_reward_fn is not None and (global_steps + 1) % self.config.trainer.test_freq == 0:
|
| 211 |
+
with Timer(name='testing', logger=None) as timer:
|
| 212 |
+
val_metrics: dict = self._validate()
|
| 213 |
+
val_metrics = {f'val/{key}': val for key, val in val_metrics.items()}
|
| 214 |
+
metrics['timing/testing'] = timer.last
|
| 215 |
+
metrics.update(val_metrics)
|
| 216 |
+
|
| 217 |
+
# collect metrics
|
| 218 |
+
data_metrics = compute_data_metrics(batch=batch)
|
| 219 |
+
metrics.update(data_metrics)
|
| 220 |
+
|
| 221 |
+
# TODO: make a canonical logger that supports various backend
|
| 222 |
+
logger.log(data=metrics, step=global_steps)
|
| 223 |
+
|
| 224 |
+
if self.config.trainer.save_freq > 0 and (global_steps + 1) % self.config.trainer.save_freq == 0:
|
| 225 |
+
actor_local_path = os.path.join(self.config.trainer.default_local_dir, 'actor',
|
| 226 |
+
f'global_step_{global_steps}')
|
| 227 |
+
actor_remote_path = os.path.join(self.config.trainer.default_hdfs_dir, 'actor')
|
| 228 |
+
self.actor_rollout_wg.save_checkpoint(actor_local_path, actor_remote_path)
|
| 229 |
+
|
| 230 |
+
if self.use_critic:
|
| 231 |
+
critic_local_path = os.path.join(self.config.trainer.default_local_dir, 'critic',
|
| 232 |
+
f'global_step_{global_steps}')
|
| 233 |
+
critic_remote_path = os.path.join(self.config.trainer.default_hdfs_dir, 'critic')
|
| 234 |
+
self.critic_wg.save_checkpoint(critic_local_path, critic_remote_path)
|
| 235 |
+
|
| 236 |
+
global_steps += 1
|
| 237 |
+
|
| 238 |
+
# perform validation after training
|
| 239 |
+
if self.val_reward_fn is not None:
|
| 240 |
+
val_metrics = self._validate()
|
| 241 |
+
pprint(f'Final validation metrics: {val_metrics}')
|
docs/workers/sglang_worker.rst
ADDED
|
@@ -0,0 +1,237 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
SGLang Backend
|
| 2 |
+
==============
|
| 3 |
+
|
| 4 |
+
Last updated: 05/31/2025.
|
| 5 |
+
|
| 6 |
+
**Authored By SGLang RL Team and listed alphabetically by last name**
|
| 7 |
+
|
| 8 |
+
`Jingyi Chen <https://github.com/fzyzcjy>`_, `Yitong Guan <https://github.com/minleminzui>`_, `Zhuobin Huang <https://zobinhuang.github.io/sec_about/>`_, `Jiajun Li <https://github.com/guapisolo>`_, `Ji Li <https://github.com/GeLee-Q>`_, `Shenggui Li <https://franklee.xyz/about>`_, `Junrong Lin <https://github.com/ocss884>`_, `Xiang Long <https://github.com/SwordFaith>`_, `Rui Lu <https://scholar.google.com/citations?user=-MGuqDcAAAAJ>`_, `Jin Pan <https://jhinpan.github.io/>`_, `Shuai Shi <https://github.com/shuaills>`_, `Yushen Su <https://yushengsu-thu.github.io/>`_, `Xinyuan Tong <https://github.com/JustinTong0323>`_, `Chendong Wang <https://github.com/cedricbeta>`_, `Hanchen Zhang <https://scholar.google.com/citations?user=pGcJcagAAAAJ>`_, `Haoran Wang <https://ubecc.github.io/about/>`_, `Yongan Xiang <https://github.com/BearBiscuit05>`_, `Chengxing Xie <https://yitianlian.github.io/>`_, `Yuhao Yang <https://github.com/yhyang201>`_, `Jinwei Yao <https://kivi-yao.github.io/>`_, `Qiaolin Yu <https://github.com/Qiaolin-Yu>`_, `Yuzhen Zhou <https://github.com/zyzshishui>`_, `Chenyang Zhao <https://github.com/zhaochenyang20>`_
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
Introduction
|
| 13 |
+
------------
|
| 14 |
+
`SGLang <https://github.com/sgl-project/sglang>`_ is an open-source state-of-the-art inference service engine, fully adopted by xAI to support all inference needs of Grok during research and serving processes.
|
| 15 |
+
|
| 16 |
+
Currently, verl fully supports using SGLang as the inference engine during the rollout phase. As a rollout engine, SGLang provides the same feature coverage as vLLM., including memory saving and multi-node rollout features. After installing verl and SGLang, simply add ``actor_rollout_ref.rollout.name=sglang`` at startup script to seamlessly switch between the two inference frameworks.
|
| 17 |
+
|
| 18 |
+
In addition, the SGLang team is actively working on supporting features such as Multi-Turn Agentic RL, VLM RLHF, Server-Based RLHF, and Partial Rollout. You can track the related development progress in the `Tracking Roadmap <https://github.com/zhaochenyang20/Awesome-ML-SYS-Tutorial/issues/74>`_.
|
| 19 |
+
|
| 20 |
+
Installation
|
| 21 |
+
------------
|
| 22 |
+
Please always follow the following command to install SGLang with verl.
|
| 23 |
+
|
| 24 |
+
.. code-block:: bash
|
| 25 |
+
|
| 26 |
+
pip install --upgrade pip
|
| 27 |
+
# Currently 0.4.8, subject to updates at any time, please refer to the latest version specified in `setup.py`
|
| 28 |
+
pip install -e ".[sglang]"
|
| 29 |
+
|
| 30 |
+
You can check the following dependencies are in your environment:
|
| 31 |
+
|
| 32 |
+
.. note::
|
| 33 |
+
|
| 34 |
+
- **PyTorch**: 2.6.0+cu124
|
| 35 |
+
- **CUDA**: 12.4
|
| 36 |
+
- **flashinfer-python**: 0.2.5+cu124torch2.6
|
| 37 |
+
- **SGLang**: 0.4.6.post5
|
| 38 |
+
- **sgl-kernel**: 0.1.4
|
| 39 |
+
|
| 40 |
+
Using SGLang as the Inference Backend for PPO Training on a Single Machine
|
| 41 |
+
-------------------------------------------------------------------------
|
| 42 |
+
We use Qwen/Qwen2-7B-Instruct on the gsm8k dataset for a simple test.
|
| 43 |
+
|
| 44 |
+
1. Run the following command to prepare the gsm8k dataset:
|
| 45 |
+
|
| 46 |
+
.. code-block:: bash
|
| 47 |
+
|
| 48 |
+
python3 examples/data_preprocess/gsm8k.py
|
| 49 |
+
|
| 50 |
+
2. Run the following script to conduct a PPO experiment on a single machine with 4 GPUs:
|
| 51 |
+
|
| 52 |
+
.. code-block:: bash
|
| 53 |
+
|
| 54 |
+
export SGL_DISABLE_TP_MEMORY_INBALANCE_CHECK=True
|
| 55 |
+
PYTHONUNBUFFERED=1 python3 -m verl.trainer.main_ppo \
|
| 56 |
+
data.train_files=$HOME/data/gsm8k/train.parquet \
|
| 57 |
+
data.val_files=$HOME/data/gsm8k/test.parquet \
|
| 58 |
+
data.train_batch_size=4096 \
|
| 59 |
+
data.max_prompt_length=4096 \
|
| 60 |
+
data.max_response_length=4096 \
|
| 61 |
+
actor_rollout_ref.rollout.name=sglang \
|
| 62 |
+
actor_rollout_ref.model.path=Qwen/Qwen2-7B-Instruct \
|
| 63 |
+
actor_rollout_ref.actor.optim.lr=1e-6 \
|
| 64 |
+
actor_rollout_ref.actor.ppo_mini_batch_size=64 \
|
| 65 |
+
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=4 \
|
| 66 |
+
actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=8 \
|
| 67 |
+
actor_rollout_ref.model.enable_gradient_checkpointing=True \
|
| 68 |
+
actor_rollout_ref.actor.fsdp_config.param_offload=True \
|
| 69 |
+
actor_rollout_ref.actor.fsdp_config.optimizer_offload=True \
|
| 70 |
+
actor_rollout_ref.rollout.tensor_model_parallel_size=2 \
|
| 71 |
+
actor_rollout_ref.rollout.gpu_memory_utilization=0.8 \
|
| 72 |
+
actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=4 \
|
| 73 |
+
critic.optim.lr=1e-5 \
|
| 74 |
+
critic.model.path=Qwen/Qwen2-7B-Instruct \
|
| 75 |
+
critic.ppo_micro_batch_size_per_gpu=4 \
|
| 76 |
+
critic.model.fsdp_config.param_offload=True \
|
| 77 |
+
critic.model.fsdp_config.optimizer_offload=True \
|
| 78 |
+
algorithm.kl_ctrl.kl_coef=0.001 \
|
| 79 |
+
trainer.logger=console \
|
| 80 |
+
trainer.val_before_train=False \
|
| 81 |
+
trainer.n_gpus_per_node=4 \
|
| 82 |
+
trainer.nnodes=1 \
|
| 83 |
+
trainer.save_freq=-1 \
|
| 84 |
+
trainer.test_freq=10 \
|
| 85 |
+
trainer.total_epochs=15 2>&1 | tee verl_demo.log
|
| 86 |
+
|
| 87 |
+
Why export SGL_DISABLE_TP_MEMORY_INBALANCE_CHECK?
|
| 88 |
+
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
| 89 |
+
|
| 90 |
+
1. ``verl`` initializes a ``SGLangRollout`` module during rollout, which is used to evaluate/generate samples.
|
| 91 |
+
|
| 92 |
+
2. ``SGLangRollout`` will initialize ``Engine``, and further initialize a ``torch.distributed.DeviceMesh``, used to support Tensor Parallel (TP).
|
| 93 |
+
|
| 94 |
+
3. ``DeviceMesh.init()`` internally checks the free GPU memory of all participating devices. If the difference is too large (more than ~10%), it directly reports an error to avoid initialization failures or deadlocks.
|
| 95 |
+
|
| 96 |
+
Why might there be inconsistent GPU memory?
|
| 97 |
+
"""""""""""""""""""""""""""""""""""""""""""
|
| 98 |
+
|
| 99 |
+
**1. Ray Distributed Actor loads the model at different times**
|
| 100 |
+
|
| 101 |
+
``verl`` uses Ray-based multi-process, multi-GPU concurrent training. Each ``WorkerDict`` may be called at different times:
|
| 102 |
+
|
| 103 |
+
.. code-block:: python
|
| 104 |
+
|
| 105 |
+
self.rollout = SGLangRollout(...)
|
| 106 |
+
|
| 107 |
+
Different workers initialize the model at different times → different memory usage.
|
| 108 |
+
|
| 109 |
+
**2. Delayed initialization causes memory bias**
|
| 110 |
+
|
| 111 |
+
Some workers start model loading/inference (e.g., ``generate_sequences()``, ``compute_log_prob()``) earlier than others.
|
| 112 |
+
Early workers already use up GPU memory → late workers still have empty memory → memory difference appears.
|
| 113 |
+
|
| 114 |
+
**3. SGLang's TP init uses "all-device broadcast", but there's no uniform release timing**
|
| 115 |
+
|
| 116 |
+
Although ``SGLangRollout`` may only involve subset of GPUs, its ``Engine`` initialization calls ``torch.distributed.init_process_group()`` and broadcasts weights, so:
|
| 117 |
+
|
| 118 |
+
- Non-rollout GPUs also join the communication.
|
| 119 |
+
- Later on, ``DeviceMesh`` init will fail due to "inconsistent memory".
|
| 120 |
+
|
| 121 |
+
**4. Different FSDP/TP loading behaviors also lead to mismatch**
|
| 122 |
+
|
| 123 |
+
If using:
|
| 124 |
+
|
| 125 |
+
.. code-block:: bash
|
| 126 |
+
|
| 127 |
+
actor.fsdp_config.param_offload=True
|
| 128 |
+
ref.fsdp_config.param_offload=True
|
| 129 |
+
|
| 130 |
+
Then some workers keep params on CPU while others already sharded to GPU → leads to asymmetric memory layout.
|
| 131 |
+
|
| 132 |
+
Using SGLang as the Inference Backend for PPO Training Across Multiple Machines
|
| 133 |
+
------------------------------------------------------------------------------
|
| 134 |
+
SGLang also supports running verl's RAY-based cross-machine inference in IPv4 and IPv6 scenarios. In the script below, we use TP=16 for cross-machine inference. Suppose we have two interconnected machines: node0 with IP 10.94.16.4 and node1 with IP 10.94.16.5.
|
| 135 |
+
|
| 136 |
+
1. Start Ray on node0:
|
| 137 |
+
|
| 138 |
+
.. code-block:: bash
|
| 139 |
+
|
| 140 |
+
ray start --head --dashboard-host=0.0.0.0
|
| 141 |
+
|
| 142 |
+
You will see the following prompt:
|
| 143 |
+
|
| 144 |
+
.. code-block:: bash
|
| 145 |
+
|
| 146 |
+
Usage stats collection is enabled. To disable this, add `--disable-usage-stats` to the command that starts the cluster, or run the following command: `ray disable-usage-stats` before starting the cluster. See https://docs.ray.io/en/master/cluster/usage-stats.html for more details.
|
| 147 |
+
|
| 148 |
+
Local node IP: 10.94.16.4
|
| 149 |
+
|
| 150 |
+
--------------------
|
| 151 |
+
Ray runtime started.
|
| 152 |
+
--------------------
|
| 153 |
+
|
| 154 |
+
Next steps
|
| 155 |
+
To add another node to this Ray cluster, run
|
| 156 |
+
ray start --address='10.94.16.4:6379'
|
| 157 |
+
|
| 158 |
+
2. Have node1 join the Ray cluster:
|
| 159 |
+
|
| 160 |
+
Run the following command on node1:
|
| 161 |
+
|
| 162 |
+
.. code-block:: bash
|
| 163 |
+
|
| 164 |
+
ray start --address='10.94.16.4:6379'
|
| 165 |
+
|
| 166 |
+
Run the following command to confirm that the Ray cluster now has two nodes:
|
| 167 |
+
|
| 168 |
+
.. code-block:: bash
|
| 169 |
+
|
| 170 |
+
ray status
|
| 171 |
+
|
| 172 |
+
You can see that the cluster has two nodes with 16 GPUs:
|
| 173 |
+
|
| 174 |
+
.. code-block:: bash
|
| 175 |
+
|
| 176 |
+
======== Autoscaler status: 2025-04-09 09:25:37.694016 ========
|
| 177 |
+
Node status
|
| 178 |
+
---------------------------------------------------------------
|
| 179 |
+
Active:
|
| 180 |
+
1 node_ef382ffd687d8f6b060c1b68e63ada7341b936fe5b1901dd04de1027
|
| 181 |
+
1 node_1eb4d7d07e793114c23a89d1a41f1f76acf6ef5b35af844a4ee8e4ba
|
| 182 |
+
Pending:
|
| 183 |
+
(no pending nodes)
|
| 184 |
+
Recent failures:
|
| 185 |
+
(no failures)
|
| 186 |
+
|
| 187 |
+
Resources
|
| 188 |
+
---------------------------------------------------------------
|
| 189 |
+
Usage:
|
| 190 |
+
0.0/360.0 CPU
|
| 191 |
+
0.0/16.0 GPU
|
| 192 |
+
0B/3.39TiB memory
|
| 193 |
+
0B/372.53GiB object_store_memory
|
| 194 |
+
|
| 195 |
+
3. Run the following script to train meta-llama/Llama-3.1-8B-Instruct with TP=16 across 2 machines using 16 GPUs:
|
| 196 |
+
|
| 197 |
+
.. code-block:: bash
|
| 198 |
+
|
| 199 |
+
DATA_DIR=$HOME/data/gsm8k
|
| 200 |
+
|
| 201 |
+
python3 -m verl.trainer.main_ppo \
|
| 202 |
+
actor_rollout_ref.rollout.name=sglang \
|
| 203 |
+
data.train_files=$DATA_DIR/train.parquet \
|
| 204 |
+
data.val_files=$DATA_DIR/test.parquet \
|
| 205 |
+
data.train_batch_size=4096 \
|
| 206 |
+
data.max_prompt_length=4096 \
|
| 207 |
+
data.max_response_length=4096 \
|
| 208 |
+
actor_rollout_ref.model.path=meta-llama/Llama-3.1-8B-Instruct \
|
| 209 |
+
actor_rollout_ref.actor.optim.lr=1e-6 \
|
| 210 |
+
actor_rollout_ref.model.use_remove_padding=True \
|
| 211 |
+
actor_rollout_ref.actor.ppo_mini_batch_size=64 \
|
| 212 |
+
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=16 \
|
| 213 |
+
actor_rollout_ref.model.enable_gradient_checkpointing=True \
|
| 214 |
+
actor_rollout_ref.actor.fsdp_config.param_offload=True \
|
| 215 |
+
actor_rollout_ref.actor.fsdp_config.optimizer_offload=True \
|
| 216 |
+
actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=16 \
|
| 217 |
+
actor_rollout_ref.rollout.tensor_model_parallel_size=16 \
|
| 218 |
+
actor_rollout_ref.rollout.gpu_memory_utilization=0.8 \
|
| 219 |
+
actor_rollout_ref.rollout.free_cache_engine=True \
|
| 220 |
+
actor_rollout_ref.ref.log_prob_micro_batch_size=16 \
|
| 221 |
+
actor_rollout_ref.ref.fsdp_config.param_offload=True \
|
| 222 |
+
critic.optim.lr=1e-5 \
|
| 223 |
+
critic.model.use_remove_padding=True \
|
| 224 |
+
critic.model.path=meta-llama/Llama-3.1-8B-Instruct \
|
| 225 |
+
critic.model.enable_gradient_checkpointing=True \
|
| 226 |
+
critic.ppo_micro_batch_size=16 \
|
| 227 |
+
critic.model.fsdp_config.param_offload=True \
|
| 228 |
+
critic.model.fsdp_config.optimizer_offload=True \
|
| 229 |
+
algorithm.kl_ctrl.kl_coef=0.001 \
|
| 230 |
+
trainer.critic_warmup=0 \
|
| 231 |
+
trainer.logger=console \
|
| 232 |
+
trainer.val_before_train=True \
|
| 233 |
+
trainer.n_gpus_per_node=8 \
|
| 234 |
+
trainer.nnodes=2 \
|
| 235 |
+
trainer.save_freq=-1 \
|
| 236 |
+
trainer.test_freq=10 \
|
| 237 |
+
trainer.total_epochs=15 2>&1 | tee verl_demo.log
|
examples/data_preprocess/preprocess_search_r1_dataset.py
ADDED
|
@@ -0,0 +1,178 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2024 Bytedance Ltd. and/or its affiliates
|
| 2 |
+
# Copyright 2023-2024 SGLang Team
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
|
| 16 |
+
import argparse
|
| 17 |
+
import logging
|
| 18 |
+
import os
|
| 19 |
+
import tempfile
|
| 20 |
+
|
| 21 |
+
import pandas as pd
|
| 22 |
+
from huggingface_hub import hf_hub_download
|
| 23 |
+
from huggingface_hub.utils import EntryNotFoundError
|
| 24 |
+
|
| 25 |
+
from verl.utils.hdfs_io import copy, makedirs
|
| 26 |
+
|
| 27 |
+
# Setup logging
|
| 28 |
+
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s")
|
| 29 |
+
logger = logging.getLogger(__name__)
|
| 30 |
+
|
| 31 |
+
# Configuration constants
|
| 32 |
+
DEFAULT_SYSTEM_CONTENT = "You are a helpful and harmless assistant."
|
| 33 |
+
DEFAULT_USER_CONTENT_PREFIX = (
|
| 34 |
+
"Answer the given question. You must conduct reasoning inside <think> and </think> "
|
| 35 |
+
"first every time you get new information. After reasoning, if you find you lack "
|
| 36 |
+
"some knowledge, you can call a search engine by <tool_call> query </tool_call> "
|
| 37 |
+
"and it will return the top searched results between <tool_response> and "
|
| 38 |
+
"</tool_response>. You can search as many times as your want. If you find no "
|
| 39 |
+
"further external knowledge needed, you can directly provide the answer inside "
|
| 40 |
+
"<answer> and </answer>, without detailed illustrations. For example, "
|
| 41 |
+
"<answer> Beijing </answer>. Question: "
|
| 42 |
+
)
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
def process_single_row(row, current_split_name, row_index):
|
| 46 |
+
"""
|
| 47 |
+
Process a single row of data for SearchR1-like format.
|
| 48 |
+
|
| 49 |
+
Args:
|
| 50 |
+
row: DataFrame row containing the original data
|
| 51 |
+
current_split_name: Name of the current split (train/test)
|
| 52 |
+
row_index: Index of the row in the DataFrame
|
| 53 |
+
|
| 54 |
+
Returns:
|
| 55 |
+
pd.Series: Processed row data in the required format
|
| 56 |
+
"""
|
| 57 |
+
question = row.get("question", "")
|
| 58 |
+
|
| 59 |
+
# Build prompt structure
|
| 60 |
+
user_content = user_content_prefix.rstrip("\n") + question
|
| 61 |
+
prompt = [{"role": "system", "content": system_content}, {"role": "user", "content": user_content}]
|
| 62 |
+
|
| 63 |
+
# Extract ground truth from reward_model or fallback to golden_answers
|
| 64 |
+
reward_model_data = row.get("reward_model")
|
| 65 |
+
if isinstance(reward_model_data, dict) and "ground_truth" in reward_model_data:
|
| 66 |
+
ground_truth = reward_model_data.get("ground_truth")
|
| 67 |
+
else:
|
| 68 |
+
ground_truth = row.get("golden_answers", [])
|
| 69 |
+
|
| 70 |
+
# Process data source
|
| 71 |
+
data_source_tagged = "searchR1_" + str(row.get("data_source", ""))
|
| 72 |
+
|
| 73 |
+
# Build tools kwargs structure
|
| 74 |
+
tools_kwargs = {
|
| 75 |
+
"search": {
|
| 76 |
+
"create_kwargs": {"ground_truth": ground_truth, "question": question, "data_source": data_source_tagged}
|
| 77 |
+
}
|
| 78 |
+
}
|
| 79 |
+
|
| 80 |
+
# Build complete extra_info structure
|
| 81 |
+
extra_info = {
|
| 82 |
+
"index": row_index,
|
| 83 |
+
"need_tools_kwargs": True,
|
| 84 |
+
"question": question,
|
| 85 |
+
"split": current_split_name,
|
| 86 |
+
"tools_kwargs": tools_kwargs,
|
| 87 |
+
}
|
| 88 |
+
|
| 89 |
+
return pd.Series(
|
| 90 |
+
{
|
| 91 |
+
"data_source": data_source_tagged,
|
| 92 |
+
"prompt": prompt,
|
| 93 |
+
"ability": row.get("ability"),
|
| 94 |
+
"reward_model": reward_model_data,
|
| 95 |
+
"extra_info": extra_info,
|
| 96 |
+
"metadata": row.get("metadata"),
|
| 97 |
+
}
|
| 98 |
+
)
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
def main():
|
| 102 |
+
local_save_dir = os.path.expanduser(args.local_dir)
|
| 103 |
+
os.makedirs(local_save_dir, exist_ok=True)
|
| 104 |
+
|
| 105 |
+
processed_files = []
|
| 106 |
+
|
| 107 |
+
# Download and process files using temporary directory
|
| 108 |
+
with tempfile.TemporaryDirectory() as tmp_download_dir:
|
| 109 |
+
for split in ["train", "test"]:
|
| 110 |
+
parquet_filename = f"{split}.parquet"
|
| 111 |
+
logger.info(f"Processing {split} split...")
|
| 112 |
+
|
| 113 |
+
try:
|
| 114 |
+
# Download Parquet file from HuggingFace
|
| 115 |
+
logger.info(f"Downloading {parquet_filename} from {args.hf_repo_id}")
|
| 116 |
+
local_parquet_filepath = hf_hub_download(
|
| 117 |
+
repo_id=args.hf_repo_id,
|
| 118 |
+
filename=parquet_filename,
|
| 119 |
+
repo_type="dataset",
|
| 120 |
+
local_dir=tmp_download_dir,
|
| 121 |
+
local_dir_use_symlinks=False,
|
| 122 |
+
)
|
| 123 |
+
|
| 124 |
+
# Load and process Parquet file
|
| 125 |
+
df_raw = pd.read_parquet(local_parquet_filepath)
|
| 126 |
+
logger.info(f"Loaded {len(df_raw)} rows from {parquet_filename}")
|
| 127 |
+
|
| 128 |
+
def apply_process_row(row, split_name=split):
|
| 129 |
+
return process_single_row(row, current_split_name=split_name, row_index=row.name)
|
| 130 |
+
|
| 131 |
+
df_processed = df_raw.apply(apply_process_row, axis=1)
|
| 132 |
+
|
| 133 |
+
# Save processed DataFrame
|
| 134 |
+
output_file_path = os.path.join(local_save_dir, f"{split}.parquet")
|
| 135 |
+
df_processed.to_parquet(output_file_path, index=False)
|
| 136 |
+
logger.info(f"Saved {len(df_processed)} processed rows to {output_file_path}")
|
| 137 |
+
processed_files.append(output_file_path)
|
| 138 |
+
|
| 139 |
+
except EntryNotFoundError:
|
| 140 |
+
logger.warning(f"{parquet_filename} not found in repository {args.hf_repo_id}")
|
| 141 |
+
except Exception as e:
|
| 142 |
+
logger.error(f"Error processing {split} split: {e}")
|
| 143 |
+
|
| 144 |
+
if not processed_files:
|
| 145 |
+
logger.warning("No data was processed or saved")
|
| 146 |
+
return
|
| 147 |
+
|
| 148 |
+
logger.info(f"Successfully processed {len(processed_files)} files to {local_save_dir}")
|
| 149 |
+
|
| 150 |
+
# Copy to HDFS if specified
|
| 151 |
+
if args.hdfs_dir:
|
| 152 |
+
try:
|
| 153 |
+
makedirs(args.hdfs_dir)
|
| 154 |
+
copy(src=local_save_dir, dst=args.hdfs_dir)
|
| 155 |
+
logger.info(f"Successfully copied files to HDFS: {args.hdfs_dir}")
|
| 156 |
+
except Exception as e:
|
| 157 |
+
logger.error(f"Error copying files to HDFS: {e}")
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
if __name__ == "__main__":
|
| 161 |
+
parser = argparse.ArgumentParser(description="Download Search-R1 from HuggingFace, process, and save to Parquet.")
|
| 162 |
+
parser.add_argument(
|
| 163 |
+
"--hf_repo_id", default="PeterJinGo/nq_hotpotqa_train", help="HuggingFace dataset repository ID."
|
| 164 |
+
)
|
| 165 |
+
parser.add_argument(
|
| 166 |
+
"--local_dir",
|
| 167 |
+
default="~/data/searchR1_processed_direct",
|
| 168 |
+
help="Local directory to save the processed Parquet files.",
|
| 169 |
+
)
|
| 170 |
+
parser.add_argument("--hdfs_dir", default=None, help="Optional HDFS directory to copy the Parquet files to.")
|
| 171 |
+
|
| 172 |
+
args = parser.parse_args()
|
| 173 |
+
|
| 174 |
+
# System and user content configuration
|
| 175 |
+
system_content = DEFAULT_SYSTEM_CONTENT
|
| 176 |
+
user_content_prefix = DEFAULT_USER_CONTENT_PREFIX
|
| 177 |
+
|
| 178 |
+
main()
|
examples/grpo_trainer/outputs/2026-01-24/22-29-52/.hydra/config.yaml
ADDED
|
@@ -0,0 +1,610 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
actor_rollout_ref:
|
| 2 |
+
actor:
|
| 3 |
+
optim:
|
| 4 |
+
_target_: verl.workers.config.FSDPOptimizerConfig
|
| 5 |
+
optimizer: AdamW
|
| 6 |
+
optimizer_impl: torch.optim
|
| 7 |
+
lr: 1.0e-06
|
| 8 |
+
lr_warmup_steps_ratio: 0.0
|
| 9 |
+
total_training_steps: -1
|
| 10 |
+
weight_decay: 0.01
|
| 11 |
+
lr_warmup_steps: -1
|
| 12 |
+
betas:
|
| 13 |
+
- 0.9
|
| 14 |
+
- 0.999
|
| 15 |
+
clip_grad: 1.0
|
| 16 |
+
min_lr_ratio: 0.0
|
| 17 |
+
num_cycles: 0.5
|
| 18 |
+
lr_scheduler_type: constant
|
| 19 |
+
warmup_style: null
|
| 20 |
+
override_optimizer_config: null
|
| 21 |
+
fsdp_config:
|
| 22 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 23 |
+
wrap_policy:
|
| 24 |
+
min_num_params: 0
|
| 25 |
+
param_offload: true
|
| 26 |
+
optimizer_offload: false
|
| 27 |
+
offload_policy: false
|
| 28 |
+
reshard_after_forward: true
|
| 29 |
+
fsdp_size: -1
|
| 30 |
+
forward_prefetch: false
|
| 31 |
+
model_dtype: fp32
|
| 32 |
+
use_orig_params: false
|
| 33 |
+
seed: 42
|
| 34 |
+
full_determinism: false
|
| 35 |
+
ulysses_sequence_parallel_size: 1
|
| 36 |
+
entropy_from_logits_with_chunking: false
|
| 37 |
+
use_torch_compile: true
|
| 38 |
+
entropy_checkpointing: false
|
| 39 |
+
forward_only: false
|
| 40 |
+
strategy: fsdp
|
| 41 |
+
dtype: bfloat16
|
| 42 |
+
_target_: verl.workers.config.FSDPActorConfig
|
| 43 |
+
rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
|
| 44 |
+
strategy: fsdp
|
| 45 |
+
ppo_mini_batch_size: 256
|
| 46 |
+
ppo_micro_batch_size: null
|
| 47 |
+
ppo_micro_batch_size_per_gpu: 32
|
| 48 |
+
use_dynamic_bsz: false
|
| 49 |
+
ppo_max_token_len_per_gpu: 16384
|
| 50 |
+
clip_ratio: 0.2
|
| 51 |
+
clip_ratio_low: 0.2
|
| 52 |
+
clip_ratio_high: 0.2
|
| 53 |
+
freeze_vision_tower: false
|
| 54 |
+
policy_loss:
|
| 55 |
+
_target_: verl.workers.config.PolicyLossConfig
|
| 56 |
+
loss_mode: vanilla
|
| 57 |
+
clip_cov_ratio: 0.0002
|
| 58 |
+
clip_cov_lb: 1.0
|
| 59 |
+
clip_cov_ub: 5.0
|
| 60 |
+
kl_cov_ratio: 0.0002
|
| 61 |
+
ppo_kl_coef: 0.1
|
| 62 |
+
clip_ratio_c: 3.0
|
| 63 |
+
loss_agg_mode: token-mean
|
| 64 |
+
loss_scale_factor: null
|
| 65 |
+
entropy_coeff: 0
|
| 66 |
+
calculate_entropy: false
|
| 67 |
+
use_kl_loss: true
|
| 68 |
+
use_torch_compile: true
|
| 69 |
+
kl_loss_coef: 0.001
|
| 70 |
+
kl_loss_type: low_var_kl
|
| 71 |
+
ppo_epochs: 1
|
| 72 |
+
shuffle: false
|
| 73 |
+
checkpoint:
|
| 74 |
+
_target_: verl.trainer.config.CheckpointConfig
|
| 75 |
+
save_contents:
|
| 76 |
+
- model
|
| 77 |
+
- optimizer
|
| 78 |
+
- extra
|
| 79 |
+
load_contents: ${.save_contents}
|
| 80 |
+
async_save: false
|
| 81 |
+
use_fused_kernels: ${oc.select:actor_rollout_ref.model.use_fused_kernels,false}
|
| 82 |
+
profiler:
|
| 83 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 84 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 85 |
+
enable: false
|
| 86 |
+
all_ranks: false
|
| 87 |
+
ranks: []
|
| 88 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 89 |
+
tool_config:
|
| 90 |
+
nsys:
|
| 91 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 92 |
+
discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
|
| 93 |
+
npu:
|
| 94 |
+
_target_: verl.utils.profiler.config.NPUToolConfig
|
| 95 |
+
contents: []
|
| 96 |
+
level: level1
|
| 97 |
+
analysis: true
|
| 98 |
+
discrete: false
|
| 99 |
+
torch:
|
| 100 |
+
_target_: verl.utils.profiler.config.TorchProfilerToolConfig
|
| 101 |
+
step_start: 0
|
| 102 |
+
step_end: null
|
| 103 |
+
torch_memory:
|
| 104 |
+
_target_: verl.utils.profiler.config.TorchMemoryToolConfig
|
| 105 |
+
trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
|
| 106 |
+
stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
|
| 107 |
+
router_replay:
|
| 108 |
+
_target_: verl.workers.config.RouterReplayConfig
|
| 109 |
+
mode: disabled
|
| 110 |
+
record_file: null
|
| 111 |
+
replay_file: null
|
| 112 |
+
grad_clip: 1.0
|
| 113 |
+
ulysses_sequence_parallel_size: 1
|
| 114 |
+
entropy_from_logits_with_chunking: false
|
| 115 |
+
entropy_checkpointing: false
|
| 116 |
+
use_remove_padding: ${oc.select:actor_rollout_ref.model.use_remove_padding,false}
|
| 117 |
+
ref:
|
| 118 |
+
rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
|
| 119 |
+
strategy: ${actor_rollout_ref.actor.strategy}
|
| 120 |
+
use_torch_compile: ${oc.select:actor_rollout_ref.actor.use_torch_compile,true}
|
| 121 |
+
log_prob_micro_batch_size: null
|
| 122 |
+
log_prob_micro_batch_size_per_gpu: 32
|
| 123 |
+
log_prob_use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
|
| 124 |
+
log_prob_max_token_len_per_gpu: ${oc.select:actor_rollout_ref.actor.ppo_max_token_len_per_gpu,16384}
|
| 125 |
+
profiler:
|
| 126 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 127 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 128 |
+
enable: false
|
| 129 |
+
all_ranks: false
|
| 130 |
+
ranks: []
|
| 131 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 132 |
+
tool_config:
|
| 133 |
+
nsys:
|
| 134 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 135 |
+
discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
|
| 136 |
+
npu:
|
| 137 |
+
_target_: verl.utils.profiler.config.NPUToolConfig
|
| 138 |
+
contents: []
|
| 139 |
+
level: level1
|
| 140 |
+
analysis: true
|
| 141 |
+
discrete: false
|
| 142 |
+
torch:
|
| 143 |
+
_target_: verl.utils.profiler.config.TorchProfilerToolConfig
|
| 144 |
+
step_start: 0
|
| 145 |
+
step_end: null
|
| 146 |
+
torch_memory:
|
| 147 |
+
_target_: verl.utils.profiler.config.TorchMemoryToolConfig
|
| 148 |
+
trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
|
| 149 |
+
stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
|
| 150 |
+
router_replay:
|
| 151 |
+
_target_: verl.workers.config.RouterReplayConfig
|
| 152 |
+
mode: disabled
|
| 153 |
+
record_file: null
|
| 154 |
+
replay_file: null
|
| 155 |
+
fsdp_config:
|
| 156 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 157 |
+
wrap_policy:
|
| 158 |
+
min_num_params: 0
|
| 159 |
+
param_offload: false
|
| 160 |
+
optimizer_offload: false
|
| 161 |
+
offload_policy: false
|
| 162 |
+
reshard_after_forward: true
|
| 163 |
+
fsdp_size: -1
|
| 164 |
+
forward_prefetch: false
|
| 165 |
+
model_dtype: fp32
|
| 166 |
+
use_orig_params: false
|
| 167 |
+
seed: 42
|
| 168 |
+
full_determinism: false
|
| 169 |
+
ulysses_sequence_parallel_size: 1
|
| 170 |
+
entropy_from_logits_with_chunking: false
|
| 171 |
+
use_torch_compile: true
|
| 172 |
+
entropy_checkpointing: false
|
| 173 |
+
forward_only: true
|
| 174 |
+
strategy: fsdp
|
| 175 |
+
dtype: bfloat16
|
| 176 |
+
_target_: verl.workers.config.FSDPActorConfig
|
| 177 |
+
ulysses_sequence_parallel_size: ${oc.select:actor_rollout_ref.actor.ulysses_sequence_parallel_size,1}
|
| 178 |
+
entropy_from_logits_with_chunking: false
|
| 179 |
+
entropy_checkpointing: false
|
| 180 |
+
rollout:
|
| 181 |
+
_target_: verl.workers.config.RolloutConfig
|
| 182 |
+
name: vllm
|
| 183 |
+
mode: async
|
| 184 |
+
temperature: 1.0
|
| 185 |
+
top_k: -1
|
| 186 |
+
top_p: 1
|
| 187 |
+
prompt_length: ${oc.select:data.max_prompt_length,512}
|
| 188 |
+
response_length: ${oc.select:data.max_response_length,512}
|
| 189 |
+
dtype: bfloat16
|
| 190 |
+
gpu_memory_utilization: 0.6
|
| 191 |
+
ignore_eos: false
|
| 192 |
+
enforce_eager: false
|
| 193 |
+
cudagraph_capture_sizes: null
|
| 194 |
+
free_cache_engine: true
|
| 195 |
+
tensor_model_parallel_size: 2
|
| 196 |
+
data_parallel_size: 1
|
| 197 |
+
expert_parallel_size: 1
|
| 198 |
+
pipeline_model_parallel_size: 1
|
| 199 |
+
max_num_batched_tokens: 8192
|
| 200 |
+
max_model_len: null
|
| 201 |
+
max_num_seqs: 1024
|
| 202 |
+
enable_chunked_prefill: true
|
| 203 |
+
enable_prefix_caching: true
|
| 204 |
+
load_format: safetensors
|
| 205 |
+
log_prob_micro_batch_size: null
|
| 206 |
+
log_prob_micro_batch_size_per_gpu: 32
|
| 207 |
+
log_prob_use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
|
| 208 |
+
log_prob_max_token_len_per_gpu: ${oc.select:actor_rollout_ref.actor.ppo_max_token_len_per_gpu,16384}
|
| 209 |
+
disable_log_stats: true
|
| 210 |
+
do_sample: true
|
| 211 |
+
'n': 5
|
| 212 |
+
over_sample_rate: 0
|
| 213 |
+
multi_stage_wake_up: false
|
| 214 |
+
engine_kwargs:
|
| 215 |
+
vllm: {}
|
| 216 |
+
sglang: {}
|
| 217 |
+
val_kwargs:
|
| 218 |
+
_target_: verl.workers.config.SamplingConfig
|
| 219 |
+
top_k: -1
|
| 220 |
+
top_p: 1.0
|
| 221 |
+
temperature: 0
|
| 222 |
+
'n': 1
|
| 223 |
+
do_sample: false
|
| 224 |
+
multi_turn:
|
| 225 |
+
_target_: verl.workers.config.MultiTurnConfig
|
| 226 |
+
enable: false
|
| 227 |
+
max_assistant_turns: null
|
| 228 |
+
tool_config_path: null
|
| 229 |
+
max_user_turns: null
|
| 230 |
+
max_parallel_calls: 1
|
| 231 |
+
max_tool_response_length: 256
|
| 232 |
+
tool_response_truncate_side: middle
|
| 233 |
+
interaction_config_path: null
|
| 234 |
+
use_inference_chat_template: false
|
| 235 |
+
tokenization_sanity_check_mode: strict
|
| 236 |
+
format: hermes
|
| 237 |
+
num_repeat_rollouts: null
|
| 238 |
+
calculate_log_probs: false
|
| 239 |
+
agent:
|
| 240 |
+
_target_: verl.workers.config.AgentLoopConfig
|
| 241 |
+
num_workers: 8
|
| 242 |
+
default_agent_loop: single_turn_agent
|
| 243 |
+
agent_loop_config_path: null
|
| 244 |
+
custom_async_server:
|
| 245 |
+
_target_: verl.workers.config.CustomAsyncServerConfig
|
| 246 |
+
path: null
|
| 247 |
+
name: null
|
| 248 |
+
update_weights_bucket_megabytes: 512
|
| 249 |
+
trace:
|
| 250 |
+
_target_: verl.workers.config.TraceConfig
|
| 251 |
+
backend: null
|
| 252 |
+
token2text: false
|
| 253 |
+
max_samples_per_step_per_worker: null
|
| 254 |
+
skip_rollout: false
|
| 255 |
+
skip_dump_dir: /tmp/rollout_dump
|
| 256 |
+
skip_tokenizer_init: true
|
| 257 |
+
enable_rollout_routing_replay: false
|
| 258 |
+
profiler:
|
| 259 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 260 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 261 |
+
enable: ${oc.select:actor_rollout_ref.actor.profiler.enable,false}
|
| 262 |
+
all_ranks: ${oc.select:actor_rollout_ref.actor.profiler.all_ranks,false}
|
| 263 |
+
ranks: ${oc.select:actor_rollout_ref.actor.profiler.ranks,[]}
|
| 264 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 265 |
+
tool_config: ${oc.select:actor_rollout_ref.actor.profiler.tool_config,null}
|
| 266 |
+
prometheus:
|
| 267 |
+
_target_: verl.workers.config.PrometheusConfig
|
| 268 |
+
enable: false
|
| 269 |
+
port: 9090
|
| 270 |
+
file: /tmp/ray/session_latest/metrics/prometheus/prometheus.yml
|
| 271 |
+
served_model_name: ${oc.select:actor_rollout_ref.model.path,null}
|
| 272 |
+
layered_summon: true
|
| 273 |
+
model:
|
| 274 |
+
_target_: verl.workers.config.HFModelConfig
|
| 275 |
+
path: Qwen/Qwen3-4B-Instruct-2507
|
| 276 |
+
hf_config_path: null
|
| 277 |
+
tokenizer_path: null
|
| 278 |
+
use_shm: false
|
| 279 |
+
trust_remote_code: false
|
| 280 |
+
custom_chat_template: null
|
| 281 |
+
external_lib: null
|
| 282 |
+
override_config: {}
|
| 283 |
+
enable_gradient_checkpointing: true
|
| 284 |
+
enable_activation_offload: false
|
| 285 |
+
use_remove_padding: true
|
| 286 |
+
lora_rank: 0
|
| 287 |
+
lora_alpha: 16
|
| 288 |
+
target_modules: all-linear
|
| 289 |
+
exclude_modules: null
|
| 290 |
+
lora_adapter_path: null
|
| 291 |
+
use_liger: false
|
| 292 |
+
use_fused_kernels: false
|
| 293 |
+
fused_kernel_options:
|
| 294 |
+
impl_backend: torch
|
| 295 |
+
hybrid_engine: true
|
| 296 |
+
nccl_timeout: 600
|
| 297 |
+
data:
|
| 298 |
+
tokenizer: null
|
| 299 |
+
use_shm: false
|
| 300 |
+
train_files: /root/data/gsm8k/train.parquet
|
| 301 |
+
val_files: /root/data/gsm8k/test.parquet
|
| 302 |
+
train_max_samples: -1
|
| 303 |
+
val_max_samples: -1
|
| 304 |
+
prompt_key: prompt
|
| 305 |
+
reward_fn_key: data_source
|
| 306 |
+
max_prompt_length: 512
|
| 307 |
+
max_response_length: 1024
|
| 308 |
+
train_batch_size: 1024
|
| 309 |
+
val_batch_size: null
|
| 310 |
+
tool_config_path: ${oc.select:actor_rollout_ref.rollout.multi_turn.tool_config_path,
|
| 311 |
+
null}
|
| 312 |
+
return_raw_input_ids: false
|
| 313 |
+
return_raw_chat: true
|
| 314 |
+
return_full_prompt: false
|
| 315 |
+
shuffle: false
|
| 316 |
+
seed: null
|
| 317 |
+
dataloader_num_workers: 8
|
| 318 |
+
image_patch_size: 14
|
| 319 |
+
validation_shuffle: false
|
| 320 |
+
filter_overlong_prompts: true
|
| 321 |
+
filter_overlong_prompts_workers: 1
|
| 322 |
+
truncation: error
|
| 323 |
+
image_key: images
|
| 324 |
+
video_key: videos
|
| 325 |
+
trust_remote_code: false
|
| 326 |
+
custom_cls:
|
| 327 |
+
path: null
|
| 328 |
+
name: null
|
| 329 |
+
return_multi_modal_inputs: true
|
| 330 |
+
sampler:
|
| 331 |
+
class_path: null
|
| 332 |
+
class_name: null
|
| 333 |
+
datagen:
|
| 334 |
+
path: null
|
| 335 |
+
name: null
|
| 336 |
+
apply_chat_template_kwargs: {}
|
| 337 |
+
reward_manager:
|
| 338 |
+
_target_: verl.trainer.config.config.RewardManagerConfig
|
| 339 |
+
source: register
|
| 340 |
+
name: ${oc.select:reward_model.reward_manager,naive}
|
| 341 |
+
module:
|
| 342 |
+
_target_: verl.trainer.config.config.ModuleConfig
|
| 343 |
+
path: null
|
| 344 |
+
name: custom_reward_manager
|
| 345 |
+
critic:
|
| 346 |
+
optim:
|
| 347 |
+
_target_: verl.workers.config.FSDPOptimizerConfig
|
| 348 |
+
optimizer: AdamW
|
| 349 |
+
optimizer_impl: torch.optim
|
| 350 |
+
lr: 1.0e-05
|
| 351 |
+
lr_warmup_steps_ratio: 0.0
|
| 352 |
+
total_training_steps: -1
|
| 353 |
+
weight_decay: 0.01
|
| 354 |
+
lr_warmup_steps: -1
|
| 355 |
+
betas:
|
| 356 |
+
- 0.9
|
| 357 |
+
- 0.999
|
| 358 |
+
clip_grad: 1.0
|
| 359 |
+
min_lr_ratio: 0.0
|
| 360 |
+
num_cycles: 0.5
|
| 361 |
+
lr_scheduler_type: constant
|
| 362 |
+
warmup_style: null
|
| 363 |
+
override_optimizer_config: null
|
| 364 |
+
model:
|
| 365 |
+
fsdp_config:
|
| 366 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 367 |
+
wrap_policy:
|
| 368 |
+
min_num_params: 0
|
| 369 |
+
param_offload: false
|
| 370 |
+
optimizer_offload: false
|
| 371 |
+
offload_policy: false
|
| 372 |
+
reshard_after_forward: true
|
| 373 |
+
fsdp_size: -1
|
| 374 |
+
forward_prefetch: false
|
| 375 |
+
model_dtype: fp32
|
| 376 |
+
use_orig_params: false
|
| 377 |
+
seed: 42
|
| 378 |
+
full_determinism: false
|
| 379 |
+
ulysses_sequence_parallel_size: 1
|
| 380 |
+
entropy_from_logits_with_chunking: false
|
| 381 |
+
use_torch_compile: true
|
| 382 |
+
entropy_checkpointing: false
|
| 383 |
+
forward_only: false
|
| 384 |
+
strategy: fsdp
|
| 385 |
+
dtype: bfloat16
|
| 386 |
+
path: ~/models/deepseek-llm-7b-chat
|
| 387 |
+
tokenizer_path: ${oc.select:actor_rollout_ref.model.path,"~/models/deepseek-llm-7b-chat"}
|
| 388 |
+
override_config: {}
|
| 389 |
+
external_lib: ${oc.select:actor_rollout_ref.model.external_lib,null}
|
| 390 |
+
trust_remote_code: ${oc.select:actor_rollout_ref.model.trust_remote_code,false}
|
| 391 |
+
_target_: verl.workers.config.FSDPCriticModelCfg
|
| 392 |
+
use_shm: false
|
| 393 |
+
enable_gradient_checkpointing: true
|
| 394 |
+
enable_activation_offload: false
|
| 395 |
+
use_remove_padding: false
|
| 396 |
+
lora_rank: 0
|
| 397 |
+
lora_alpha: 16
|
| 398 |
+
target_modules: all-linear
|
| 399 |
+
_target_: verl.workers.config.FSDPCriticConfig
|
| 400 |
+
rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
|
| 401 |
+
strategy: fsdp
|
| 402 |
+
enable: null
|
| 403 |
+
ppo_mini_batch_size: ${oc.select:actor_rollout_ref.actor.ppo_mini_batch_size,256}
|
| 404 |
+
ppo_micro_batch_size: null
|
| 405 |
+
ppo_micro_batch_size_per_gpu: ${oc.select:.ppo_micro_batch_size,null}
|
| 406 |
+
use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
|
| 407 |
+
ppo_max_token_len_per_gpu: 32768
|
| 408 |
+
forward_max_token_len_per_gpu: ${.ppo_max_token_len_per_gpu}
|
| 409 |
+
ppo_epochs: ${oc.select:actor_rollout_ref.actor.ppo_epochs,1}
|
| 410 |
+
shuffle: ${oc.select:actor_rollout_ref.actor.shuffle,false}
|
| 411 |
+
cliprange_value: 0.5
|
| 412 |
+
loss_agg_mode: ${oc.select:actor_rollout_ref.actor.loss_agg_mode,token-mean}
|
| 413 |
+
checkpoint:
|
| 414 |
+
_target_: verl.trainer.config.CheckpointConfig
|
| 415 |
+
save_contents:
|
| 416 |
+
- model
|
| 417 |
+
- optimizer
|
| 418 |
+
- extra
|
| 419 |
+
load_contents: ${.save_contents}
|
| 420 |
+
async_save: false
|
| 421 |
+
profiler:
|
| 422 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 423 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 424 |
+
enable: false
|
| 425 |
+
all_ranks: false
|
| 426 |
+
ranks: []
|
| 427 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 428 |
+
tool_config:
|
| 429 |
+
nsys:
|
| 430 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 431 |
+
discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
|
| 432 |
+
npu:
|
| 433 |
+
_target_: verl.utils.profiler.config.NPUToolConfig
|
| 434 |
+
contents: []
|
| 435 |
+
level: level1
|
| 436 |
+
analysis: true
|
| 437 |
+
discrete: false
|
| 438 |
+
torch:
|
| 439 |
+
_target_: verl.utils.profiler.config.TorchProfilerToolConfig
|
| 440 |
+
step_start: 0
|
| 441 |
+
step_end: null
|
| 442 |
+
torch_memory:
|
| 443 |
+
_target_: verl.utils.profiler.config.TorchMemoryToolConfig
|
| 444 |
+
trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
|
| 445 |
+
stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
|
| 446 |
+
forward_micro_batch_size: ${oc.select:.ppo_micro_batch_size,null}
|
| 447 |
+
forward_micro_batch_size_per_gpu: ${oc.select:.ppo_micro_batch_size_per_gpu,null}
|
| 448 |
+
ulysses_sequence_parallel_size: 1
|
| 449 |
+
grad_clip: 1.0
|
| 450 |
+
reward_model:
|
| 451 |
+
enable: true
|
| 452 |
+
enable_resource_pool: false
|
| 453 |
+
n_gpus_per_node: 0
|
| 454 |
+
nnodes: 0
|
| 455 |
+
strategy: fsdp
|
| 456 |
+
model:
|
| 457 |
+
input_tokenizer: Qwen/Qwen3-4B-Instruct-2507
|
| 458 |
+
path: /data/models/reward/qwen3_4b_prm
|
| 459 |
+
external_lib: ${actor_rollout_ref.model.external_lib}
|
| 460 |
+
trust_remote_code: false
|
| 461 |
+
override_config: {}
|
| 462 |
+
use_shm: false
|
| 463 |
+
use_remove_padding: false
|
| 464 |
+
use_fused_kernels: ${actor_rollout_ref.model.use_fused_kernels}
|
| 465 |
+
fsdp_config:
|
| 466 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 467 |
+
wrap_policy:
|
| 468 |
+
min_num_params: 0
|
| 469 |
+
param_offload: false
|
| 470 |
+
reshard_after_forward: true
|
| 471 |
+
fsdp_size: -1
|
| 472 |
+
forward_prefetch: false
|
| 473 |
+
micro_batch_size: null
|
| 474 |
+
micro_batch_size_per_gpu: 32
|
| 475 |
+
max_length: null
|
| 476 |
+
use_dynamic_bsz: ${critic.use_dynamic_bsz}
|
| 477 |
+
forward_max_token_len_per_gpu: ${critic.forward_max_token_len_per_gpu}
|
| 478 |
+
reward_manager: naive
|
| 479 |
+
launch_reward_fn_async: false
|
| 480 |
+
sandbox_fusion:
|
| 481 |
+
url: null
|
| 482 |
+
max_concurrent: 64
|
| 483 |
+
memory_limit_mb: 1024
|
| 484 |
+
profiler:
|
| 485 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 486 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 487 |
+
enable: false
|
| 488 |
+
all_ranks: false
|
| 489 |
+
ranks: []
|
| 490 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 491 |
+
tool_config: ${oc.select:actor_rollout_ref.actor.profiler.tool_config,null}
|
| 492 |
+
ulysses_sequence_parallel_size: 1
|
| 493 |
+
use_reward_loop: true
|
| 494 |
+
rollout:
|
| 495 |
+
_target_: verl.workers.config.RolloutConfig
|
| 496 |
+
name: ???
|
| 497 |
+
dtype: bfloat16
|
| 498 |
+
gpu_memory_utilization: 0.5
|
| 499 |
+
enforce_eager: true
|
| 500 |
+
cudagraph_capture_sizes: null
|
| 501 |
+
free_cache_engine: true
|
| 502 |
+
data_parallel_size: 1
|
| 503 |
+
expert_parallel_size: 1
|
| 504 |
+
tensor_model_parallel_size: 2
|
| 505 |
+
max_num_batched_tokens: 8192
|
| 506 |
+
max_model_len: null
|
| 507 |
+
max_num_seqs: 1024
|
| 508 |
+
load_format: auto
|
| 509 |
+
engine_kwargs: {}
|
| 510 |
+
limit_images: null
|
| 511 |
+
enable_chunked_prefill: true
|
| 512 |
+
enable_prefix_caching: true
|
| 513 |
+
disable_log_stats: true
|
| 514 |
+
skip_tokenizer_init: true
|
| 515 |
+
prompt_length: 512
|
| 516 |
+
response_length: 512
|
| 517 |
+
algorithm:
|
| 518 |
+
rollout_correction:
|
| 519 |
+
rollout_is: null
|
| 520 |
+
rollout_is_threshold: 2.0
|
| 521 |
+
rollout_rs: null
|
| 522 |
+
rollout_rs_threshold: null
|
| 523 |
+
rollout_rs_threshold_lower: null
|
| 524 |
+
rollout_token_veto_threshold: null
|
| 525 |
+
bypass_mode: false
|
| 526 |
+
use_policy_gradient: false
|
| 527 |
+
rollout_is_batch_normalize: false
|
| 528 |
+
_target_: verl.trainer.config.AlgoConfig
|
| 529 |
+
gamma: 1.0
|
| 530 |
+
lam: 1.0
|
| 531 |
+
adv_estimator: grpo
|
| 532 |
+
norm_adv_by_std_in_grpo: true
|
| 533 |
+
use_kl_in_reward: false
|
| 534 |
+
kl_penalty: kl
|
| 535 |
+
kl_ctrl:
|
| 536 |
+
_target_: verl.trainer.config.KLControlConfig
|
| 537 |
+
type: fixed
|
| 538 |
+
kl_coef: 0.001
|
| 539 |
+
horizon: 10000
|
| 540 |
+
target_kl: 0.1
|
| 541 |
+
use_pf_ppo: false
|
| 542 |
+
pf_ppo:
|
| 543 |
+
reweight_method: pow
|
| 544 |
+
weight_pow: 2.0
|
| 545 |
+
custom_reward_function:
|
| 546 |
+
path: null
|
| 547 |
+
name: compute_score
|
| 548 |
+
trainer:
|
| 549 |
+
balance_batch: true
|
| 550 |
+
total_epochs: 15
|
| 551 |
+
total_training_steps: null
|
| 552 |
+
project_name: verl_grpo_gsm8k
|
| 553 |
+
experiment_name: qwen3_4b_gsm8k_grpo
|
| 554 |
+
logger:
|
| 555 |
+
- console
|
| 556 |
+
- wandb
|
| 557 |
+
log_val_generations: 0
|
| 558 |
+
rollout_data_dir: null
|
| 559 |
+
validation_data_dir: null
|
| 560 |
+
nnodes: 1
|
| 561 |
+
n_gpus_per_node: 8
|
| 562 |
+
save_freq: 20
|
| 563 |
+
esi_redundant_time: 0
|
| 564 |
+
resume_mode: disable
|
| 565 |
+
resume_from_path: null
|
| 566 |
+
val_before_train: true
|
| 567 |
+
val_only: false
|
| 568 |
+
test_freq: 5
|
| 569 |
+
critic_warmup: 0
|
| 570 |
+
default_hdfs_dir: null
|
| 571 |
+
del_local_ckpt_after_load: false
|
| 572 |
+
default_local_dir: checkpoints/${trainer.project_name}/${trainer.experiment_name}
|
| 573 |
+
max_actor_ckpt_to_keep: null
|
| 574 |
+
max_critic_ckpt_to_keep: null
|
| 575 |
+
ray_wait_register_center_timeout: 300
|
| 576 |
+
device: cuda
|
| 577 |
+
use_legacy_worker_impl: auto
|
| 578 |
+
global_profiler:
|
| 579 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 580 |
+
tool: null
|
| 581 |
+
steps: null
|
| 582 |
+
profile_continuous_steps: false
|
| 583 |
+
save_path: outputs/profile
|
| 584 |
+
global_tool_config:
|
| 585 |
+
nsys:
|
| 586 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 587 |
+
discrete: false
|
| 588 |
+
controller_nsight_options:
|
| 589 |
+
trace: cuda,nvtx,cublas,ucx
|
| 590 |
+
cuda-memory-usage: 'true'
|
| 591 |
+
cuda-graph-trace: graph
|
| 592 |
+
worker_nsight_options:
|
| 593 |
+
trace: cuda,nvtx,cublas,ucx
|
| 594 |
+
cuda-memory-usage: 'true'
|
| 595 |
+
cuda-graph-trace: graph
|
| 596 |
+
capture-range: cudaProfilerApi
|
| 597 |
+
capture-range-end: null
|
| 598 |
+
kill: none
|
| 599 |
+
torch_memory:
|
| 600 |
+
trace_alloc_max_entries: 100000
|
| 601 |
+
stack_depth: 32
|
| 602 |
+
context: all
|
| 603 |
+
stacks: all
|
| 604 |
+
kw_args: {}
|
| 605 |
+
transfer_queue:
|
| 606 |
+
enable: false
|
| 607 |
+
ray_kwargs:
|
| 608 |
+
ray_init:
|
| 609 |
+
num_cpus: null
|
| 610 |
+
timeline_json_file: null
|
examples/grpo_trainer/outputs/2026-01-24/22-48-33/.hydra/hydra.yaml
ADDED
|
@@ -0,0 +1,212 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
hydra:
|
| 2 |
+
run:
|
| 3 |
+
dir: outputs/${now:%Y-%m-%d}/${now:%H-%M-%S}
|
| 4 |
+
sweep:
|
| 5 |
+
dir: multirun/${now:%Y-%m-%d}/${now:%H-%M-%S}
|
| 6 |
+
subdir: ${hydra.job.num}
|
| 7 |
+
launcher:
|
| 8 |
+
_target_: hydra._internal.core_plugins.basic_launcher.BasicLauncher
|
| 9 |
+
sweeper:
|
| 10 |
+
_target_: hydra._internal.core_plugins.basic_sweeper.BasicSweeper
|
| 11 |
+
max_batch_size: null
|
| 12 |
+
params: null
|
| 13 |
+
help:
|
| 14 |
+
app_name: ${hydra.job.name}
|
| 15 |
+
header: '${hydra.help.app_name} is powered by Hydra.
|
| 16 |
+
|
| 17 |
+
'
|
| 18 |
+
footer: 'Powered by Hydra (https://hydra.cc)
|
| 19 |
+
|
| 20 |
+
Use --hydra-help to view Hydra specific help
|
| 21 |
+
|
| 22 |
+
'
|
| 23 |
+
template: '${hydra.help.header}
|
| 24 |
+
|
| 25 |
+
== Configuration groups ==
|
| 26 |
+
|
| 27 |
+
Compose your configuration from those groups (group=option)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
$APP_CONFIG_GROUPS
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
== Config ==
|
| 34 |
+
|
| 35 |
+
Override anything in the config (foo.bar=value)
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
$CONFIG
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
${hydra.help.footer}
|
| 42 |
+
|
| 43 |
+
'
|
| 44 |
+
hydra_help:
|
| 45 |
+
template: 'Hydra (${hydra.runtime.version})
|
| 46 |
+
|
| 47 |
+
See https://hydra.cc for more info.
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
== Flags ==
|
| 51 |
+
|
| 52 |
+
$FLAGS_HELP
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
== Configuration groups ==
|
| 56 |
+
|
| 57 |
+
Compose your configuration from those groups (For example, append hydra/job_logging=disabled
|
| 58 |
+
to command line)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
$HYDRA_CONFIG_GROUPS
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
Use ''--cfg hydra'' to Show the Hydra config.
|
| 65 |
+
|
| 66 |
+
'
|
| 67 |
+
hydra_help: ???
|
| 68 |
+
hydra_logging:
|
| 69 |
+
version: 1
|
| 70 |
+
formatters:
|
| 71 |
+
simple:
|
| 72 |
+
format: '[%(asctime)s][HYDRA] %(message)s'
|
| 73 |
+
handlers:
|
| 74 |
+
console:
|
| 75 |
+
class: logging.StreamHandler
|
| 76 |
+
formatter: simple
|
| 77 |
+
stream: ext://sys.stdout
|
| 78 |
+
root:
|
| 79 |
+
level: INFO
|
| 80 |
+
handlers:
|
| 81 |
+
- console
|
| 82 |
+
loggers:
|
| 83 |
+
logging_example:
|
| 84 |
+
level: DEBUG
|
| 85 |
+
disable_existing_loggers: false
|
| 86 |
+
job_logging:
|
| 87 |
+
version: 1
|
| 88 |
+
formatters:
|
| 89 |
+
simple:
|
| 90 |
+
format: '[%(asctime)s][%(name)s][%(levelname)s] - %(message)s'
|
| 91 |
+
handlers:
|
| 92 |
+
console:
|
| 93 |
+
class: logging.StreamHandler
|
| 94 |
+
formatter: simple
|
| 95 |
+
stream: ext://sys.stdout
|
| 96 |
+
file:
|
| 97 |
+
class: logging.FileHandler
|
| 98 |
+
formatter: simple
|
| 99 |
+
filename: ${hydra.runtime.output_dir}/${hydra.job.name}.log
|
| 100 |
+
root:
|
| 101 |
+
level: INFO
|
| 102 |
+
handlers:
|
| 103 |
+
- console
|
| 104 |
+
- file
|
| 105 |
+
disable_existing_loggers: false
|
| 106 |
+
env: {}
|
| 107 |
+
mode: RUN
|
| 108 |
+
searchpath: []
|
| 109 |
+
callbacks: {}
|
| 110 |
+
output_subdir: .hydra
|
| 111 |
+
overrides:
|
| 112 |
+
hydra:
|
| 113 |
+
- hydra.mode=RUN
|
| 114 |
+
task:
|
| 115 |
+
- algorithm.adv_estimator=grpo
|
| 116 |
+
- data.train_files=/root/data/gsm8k/train.parquet
|
| 117 |
+
- data.val_files=/root/data/gsm8k/test.parquet
|
| 118 |
+
- data.train_batch_size=1024
|
| 119 |
+
- data.max_prompt_length=512
|
| 120 |
+
- data.max_response_length=1024
|
| 121 |
+
- data.filter_overlong_prompts=True
|
| 122 |
+
- data.truncation=error
|
| 123 |
+
- data.shuffle=False
|
| 124 |
+
- actor_rollout_ref.model.path=Qwen/Qwen3-4B-Instruct-2507
|
| 125 |
+
- actor_rollout_ref.actor.optim.lr=1e-6
|
| 126 |
+
- actor_rollout_ref.model.use_remove_padding=True
|
| 127 |
+
- actor_rollout_ref.actor.ppo_mini_batch_size=256
|
| 128 |
+
- actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=32
|
| 129 |
+
- actor_rollout_ref.actor.use_kl_loss=True
|
| 130 |
+
- actor_rollout_ref.actor.kl_loss_coef=0.001
|
| 131 |
+
- actor_rollout_ref.actor.kl_loss_type=low_var_kl
|
| 132 |
+
- actor_rollout_ref.actor.entropy_coeff=0
|
| 133 |
+
- actor_rollout_ref.model.enable_gradient_checkpointing=True
|
| 134 |
+
- actor_rollout_ref.actor.fsdp_config.param_offload=True
|
| 135 |
+
- actor_rollout_ref.actor.fsdp_config.optimizer_offload=False
|
| 136 |
+
- actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32
|
| 137 |
+
- actor_rollout_ref.rollout.tensor_model_parallel_size=2
|
| 138 |
+
- actor_rollout_ref.rollout.name=vllm
|
| 139 |
+
- actor_rollout_ref.rollout.gpu_memory_utilization=0.6
|
| 140 |
+
- actor_rollout_ref.rollout.n=5
|
| 141 |
+
- actor_rollout_ref.rollout.load_format=safetensors
|
| 142 |
+
- actor_rollout_ref.rollout.layered_summon=True
|
| 143 |
+
- actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32
|
| 144 |
+
- actor_rollout_ref.ref.fsdp_config.param_offload=False
|
| 145 |
+
- algorithm.use_kl_in_reward=False
|
| 146 |
+
- reward_model.enable=True
|
| 147 |
+
- reward_model.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 148 |
+
- reward_model.model.input_tokenizer=Qwen/Qwen3-4B-Instruct-2507
|
| 149 |
+
- reward_model.micro_batch_size_per_gpu=32
|
| 150 |
+
- trainer.critic_warmup=0
|
| 151 |
+
- trainer.logger=["console","wandb"]
|
| 152 |
+
- trainer.project_name=verl_grpo_gsm8k
|
| 153 |
+
- trainer.experiment_name=qwen3_4b_gsm8k_grpo
|
| 154 |
+
- trainer.n_gpus_per_node=8
|
| 155 |
+
- trainer.nnodes=1
|
| 156 |
+
- trainer.save_freq=20
|
| 157 |
+
- trainer.test_freq=5
|
| 158 |
+
- trainer.total_epochs=15
|
| 159 |
+
- trainer.resume_mode=disable
|
| 160 |
+
job:
|
| 161 |
+
name: main_ppo
|
| 162 |
+
chdir: null
|
| 163 |
+
override_dirname: actor_rollout_ref.actor.entropy_coeff=0,actor_rollout_ref.actor.fsdp_config.optimizer_offload=False,actor_rollout_ref.actor.fsdp_config.param_offload=True,actor_rollout_ref.actor.kl_loss_coef=0.001,actor_rollout_ref.actor.kl_loss_type=low_var_kl,actor_rollout_ref.actor.optim.lr=1e-6,actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=32,actor_rollout_ref.actor.ppo_mini_batch_size=256,actor_rollout_ref.actor.use_kl_loss=True,actor_rollout_ref.model.enable_gradient_checkpointing=True,actor_rollout_ref.model.path=Qwen/Qwen3-4B-Instruct-2507,actor_rollout_ref.model.use_remove_padding=True,actor_rollout_ref.ref.fsdp_config.param_offload=False,actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32,actor_rollout_ref.rollout.gpu_memory_utilization=0.6,actor_rollout_ref.rollout.layered_summon=True,actor_rollout_ref.rollout.load_format=safetensors,actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32,actor_rollout_ref.rollout.n=5,actor_rollout_ref.rollout.name=vllm,actor_rollout_ref.rollout.tensor_model_parallel_size=2,algorithm.adv_estimator=grpo,algorithm.use_kl_in_reward=False,data.filter_overlong_prompts=True,data.max_prompt_length=512,data.max_response_length=1024,data.shuffle=False,data.train_batch_size=1024,data.train_files=/root/data/gsm8k/train.parquet,data.truncation=error,data.val_files=/root/data/gsm8k/test.parquet,reward_model.enable=True,reward_model.micro_batch_size_per_gpu=32,reward_model.model.input_tokenizer=Qwen/Qwen3-4B-Instruct-2507,reward_model.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507,trainer.critic_warmup=0,trainer.experiment_name=qwen3_4b_gsm8k_grpo,trainer.logger=["console","wandb"],trainer.n_gpus_per_node=8,trainer.nnodes=1,trainer.project_name=verl_grpo_gsm8k,trainer.resume_mode=disable,trainer.save_freq=20,trainer.test_freq=5,trainer.total_epochs=15
|
| 164 |
+
id: ???
|
| 165 |
+
num: ???
|
| 166 |
+
config_name: ppo_trainer
|
| 167 |
+
env_set: {}
|
| 168 |
+
env_copy: []
|
| 169 |
+
config:
|
| 170 |
+
override_dirname:
|
| 171 |
+
kv_sep: '='
|
| 172 |
+
item_sep: ','
|
| 173 |
+
exclude_keys: []
|
| 174 |
+
runtime:
|
| 175 |
+
version: 1.3.2
|
| 176 |
+
version_base: '1.3'
|
| 177 |
+
cwd: /mnt/tidal-alsh01/usr/zhangruiqi1/my/verl/examples/grpo_trainer
|
| 178 |
+
config_sources:
|
| 179 |
+
- path: hydra.conf
|
| 180 |
+
schema: pkg
|
| 181 |
+
provider: hydra
|
| 182 |
+
- path: /mnt/tidal-alsh01/usr/zhangruiqi1/my/verl/verl/trainer/config
|
| 183 |
+
schema: file
|
| 184 |
+
provider: main
|
| 185 |
+
- path: ''
|
| 186 |
+
schema: structured
|
| 187 |
+
provider: schema
|
| 188 |
+
output_dir: /mnt/tidal-alsh01/usr/zhangruiqi1/my/verl/examples/grpo_trainer/outputs/2026-01-24/22-48-33
|
| 189 |
+
choices:
|
| 190 |
+
algorithm@algorithm.rollout_correction: rollout_correction
|
| 191 |
+
reward_model: dp_reward_loop
|
| 192 |
+
critic: dp_critic
|
| 193 |
+
critic/../engine@critic.model.fsdp_config: fsdp
|
| 194 |
+
critic/../optim@critic.optim: fsdp
|
| 195 |
+
model@actor_rollout_ref.model: hf_model
|
| 196 |
+
rollout@actor_rollout_ref.rollout: rollout
|
| 197 |
+
ref@actor_rollout_ref.ref: dp_ref
|
| 198 |
+
ref/../engine@actor_rollout_ref.ref.fsdp_config: fsdp
|
| 199 |
+
data: legacy_data
|
| 200 |
+
actor@actor_rollout_ref.actor: dp_actor
|
| 201 |
+
actor/../engine@actor_rollout_ref.actor.fsdp_config: fsdp
|
| 202 |
+
actor/../optim@actor_rollout_ref.actor.optim: fsdp
|
| 203 |
+
hydra/env: default
|
| 204 |
+
hydra/callbacks: null
|
| 205 |
+
hydra/job_logging: default
|
| 206 |
+
hydra/hydra_logging: default
|
| 207 |
+
hydra/hydra_help: default
|
| 208 |
+
hydra/help: default
|
| 209 |
+
hydra/sweeper: basic
|
| 210 |
+
hydra/launcher: basic
|
| 211 |
+
hydra/output: default
|
| 212 |
+
verbose: false
|
examples/grpo_trainer/outputs/2026-01-24/22-51-12/.hydra/config.yaml
ADDED
|
@@ -0,0 +1,610 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
actor_rollout_ref:
|
| 2 |
+
actor:
|
| 3 |
+
optim:
|
| 4 |
+
_target_: verl.workers.config.FSDPOptimizerConfig
|
| 5 |
+
optimizer: AdamW
|
| 6 |
+
optimizer_impl: torch.optim
|
| 7 |
+
lr: 1.0e-06
|
| 8 |
+
lr_warmup_steps_ratio: 0.0
|
| 9 |
+
total_training_steps: -1
|
| 10 |
+
weight_decay: 0.01
|
| 11 |
+
lr_warmup_steps: -1
|
| 12 |
+
betas:
|
| 13 |
+
- 0.9
|
| 14 |
+
- 0.999
|
| 15 |
+
clip_grad: 1.0
|
| 16 |
+
min_lr_ratio: 0.0
|
| 17 |
+
num_cycles: 0.5
|
| 18 |
+
lr_scheduler_type: constant
|
| 19 |
+
warmup_style: null
|
| 20 |
+
override_optimizer_config: null
|
| 21 |
+
fsdp_config:
|
| 22 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 23 |
+
wrap_policy:
|
| 24 |
+
min_num_params: 0
|
| 25 |
+
param_offload: true
|
| 26 |
+
optimizer_offload: false
|
| 27 |
+
offload_policy: false
|
| 28 |
+
reshard_after_forward: true
|
| 29 |
+
fsdp_size: -1
|
| 30 |
+
forward_prefetch: false
|
| 31 |
+
model_dtype: fp32
|
| 32 |
+
use_orig_params: false
|
| 33 |
+
seed: 42
|
| 34 |
+
full_determinism: false
|
| 35 |
+
ulysses_sequence_parallel_size: 1
|
| 36 |
+
entropy_from_logits_with_chunking: false
|
| 37 |
+
use_torch_compile: true
|
| 38 |
+
entropy_checkpointing: false
|
| 39 |
+
forward_only: false
|
| 40 |
+
strategy: fsdp
|
| 41 |
+
dtype: bfloat16
|
| 42 |
+
_target_: verl.workers.config.FSDPActorConfig
|
| 43 |
+
rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
|
| 44 |
+
strategy: fsdp
|
| 45 |
+
ppo_mini_batch_size: 256
|
| 46 |
+
ppo_micro_batch_size: null
|
| 47 |
+
ppo_micro_batch_size_per_gpu: 32
|
| 48 |
+
use_dynamic_bsz: false
|
| 49 |
+
ppo_max_token_len_per_gpu: 16384
|
| 50 |
+
clip_ratio: 0.2
|
| 51 |
+
clip_ratio_low: 0.2
|
| 52 |
+
clip_ratio_high: 0.2
|
| 53 |
+
freeze_vision_tower: false
|
| 54 |
+
policy_loss:
|
| 55 |
+
_target_: verl.workers.config.PolicyLossConfig
|
| 56 |
+
loss_mode: vanilla
|
| 57 |
+
clip_cov_ratio: 0.0002
|
| 58 |
+
clip_cov_lb: 1.0
|
| 59 |
+
clip_cov_ub: 5.0
|
| 60 |
+
kl_cov_ratio: 0.0002
|
| 61 |
+
ppo_kl_coef: 0.1
|
| 62 |
+
clip_ratio_c: 3.0
|
| 63 |
+
loss_agg_mode: token-mean
|
| 64 |
+
loss_scale_factor: null
|
| 65 |
+
entropy_coeff: 0
|
| 66 |
+
calculate_entropy: false
|
| 67 |
+
use_kl_loss: true
|
| 68 |
+
use_torch_compile: true
|
| 69 |
+
kl_loss_coef: 0.001
|
| 70 |
+
kl_loss_type: low_var_kl
|
| 71 |
+
ppo_epochs: 1
|
| 72 |
+
shuffle: false
|
| 73 |
+
checkpoint:
|
| 74 |
+
_target_: verl.trainer.config.CheckpointConfig
|
| 75 |
+
save_contents:
|
| 76 |
+
- model
|
| 77 |
+
- optimizer
|
| 78 |
+
- extra
|
| 79 |
+
load_contents: ${.save_contents}
|
| 80 |
+
async_save: false
|
| 81 |
+
use_fused_kernels: ${oc.select:actor_rollout_ref.model.use_fused_kernels,false}
|
| 82 |
+
profiler:
|
| 83 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 84 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 85 |
+
enable: false
|
| 86 |
+
all_ranks: false
|
| 87 |
+
ranks: []
|
| 88 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 89 |
+
tool_config:
|
| 90 |
+
nsys:
|
| 91 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 92 |
+
discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
|
| 93 |
+
npu:
|
| 94 |
+
_target_: verl.utils.profiler.config.NPUToolConfig
|
| 95 |
+
contents: []
|
| 96 |
+
level: level1
|
| 97 |
+
analysis: true
|
| 98 |
+
discrete: false
|
| 99 |
+
torch:
|
| 100 |
+
_target_: verl.utils.profiler.config.TorchProfilerToolConfig
|
| 101 |
+
step_start: 0
|
| 102 |
+
step_end: null
|
| 103 |
+
torch_memory:
|
| 104 |
+
_target_: verl.utils.profiler.config.TorchMemoryToolConfig
|
| 105 |
+
trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
|
| 106 |
+
stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
|
| 107 |
+
router_replay:
|
| 108 |
+
_target_: verl.workers.config.RouterReplayConfig
|
| 109 |
+
mode: disabled
|
| 110 |
+
record_file: null
|
| 111 |
+
replay_file: null
|
| 112 |
+
grad_clip: 1.0
|
| 113 |
+
ulysses_sequence_parallel_size: 1
|
| 114 |
+
entropy_from_logits_with_chunking: false
|
| 115 |
+
entropy_checkpointing: false
|
| 116 |
+
use_remove_padding: ${oc.select:actor_rollout_ref.model.use_remove_padding,false}
|
| 117 |
+
ref:
|
| 118 |
+
rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
|
| 119 |
+
strategy: ${actor_rollout_ref.actor.strategy}
|
| 120 |
+
use_torch_compile: ${oc.select:actor_rollout_ref.actor.use_torch_compile,true}
|
| 121 |
+
log_prob_micro_batch_size: null
|
| 122 |
+
log_prob_micro_batch_size_per_gpu: 32
|
| 123 |
+
log_prob_use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
|
| 124 |
+
log_prob_max_token_len_per_gpu: ${oc.select:actor_rollout_ref.actor.ppo_max_token_len_per_gpu,16384}
|
| 125 |
+
profiler:
|
| 126 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 127 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 128 |
+
enable: false
|
| 129 |
+
all_ranks: false
|
| 130 |
+
ranks: []
|
| 131 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 132 |
+
tool_config:
|
| 133 |
+
nsys:
|
| 134 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 135 |
+
discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
|
| 136 |
+
npu:
|
| 137 |
+
_target_: verl.utils.profiler.config.NPUToolConfig
|
| 138 |
+
contents: []
|
| 139 |
+
level: level1
|
| 140 |
+
analysis: true
|
| 141 |
+
discrete: false
|
| 142 |
+
torch:
|
| 143 |
+
_target_: verl.utils.profiler.config.TorchProfilerToolConfig
|
| 144 |
+
step_start: 0
|
| 145 |
+
step_end: null
|
| 146 |
+
torch_memory:
|
| 147 |
+
_target_: verl.utils.profiler.config.TorchMemoryToolConfig
|
| 148 |
+
trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
|
| 149 |
+
stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
|
| 150 |
+
router_replay:
|
| 151 |
+
_target_: verl.workers.config.RouterReplayConfig
|
| 152 |
+
mode: disabled
|
| 153 |
+
record_file: null
|
| 154 |
+
replay_file: null
|
| 155 |
+
fsdp_config:
|
| 156 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 157 |
+
wrap_policy:
|
| 158 |
+
min_num_params: 0
|
| 159 |
+
param_offload: false
|
| 160 |
+
optimizer_offload: false
|
| 161 |
+
offload_policy: false
|
| 162 |
+
reshard_after_forward: true
|
| 163 |
+
fsdp_size: -1
|
| 164 |
+
forward_prefetch: false
|
| 165 |
+
model_dtype: fp32
|
| 166 |
+
use_orig_params: false
|
| 167 |
+
seed: 42
|
| 168 |
+
full_determinism: false
|
| 169 |
+
ulysses_sequence_parallel_size: 1
|
| 170 |
+
entropy_from_logits_with_chunking: false
|
| 171 |
+
use_torch_compile: true
|
| 172 |
+
entropy_checkpointing: false
|
| 173 |
+
forward_only: true
|
| 174 |
+
strategy: fsdp
|
| 175 |
+
dtype: bfloat16
|
| 176 |
+
_target_: verl.workers.config.FSDPActorConfig
|
| 177 |
+
ulysses_sequence_parallel_size: ${oc.select:actor_rollout_ref.actor.ulysses_sequence_parallel_size,1}
|
| 178 |
+
entropy_from_logits_with_chunking: false
|
| 179 |
+
entropy_checkpointing: false
|
| 180 |
+
rollout:
|
| 181 |
+
_target_: verl.workers.config.RolloutConfig
|
| 182 |
+
name: vllm
|
| 183 |
+
mode: async
|
| 184 |
+
temperature: 1.0
|
| 185 |
+
top_k: -1
|
| 186 |
+
top_p: 1
|
| 187 |
+
prompt_length: ${oc.select:data.max_prompt_length,512}
|
| 188 |
+
response_length: ${oc.select:data.max_response_length,512}
|
| 189 |
+
dtype: bfloat16
|
| 190 |
+
gpu_memory_utilization: 0.6
|
| 191 |
+
ignore_eos: false
|
| 192 |
+
enforce_eager: false
|
| 193 |
+
cudagraph_capture_sizes: null
|
| 194 |
+
free_cache_engine: true
|
| 195 |
+
tensor_model_parallel_size: 2
|
| 196 |
+
data_parallel_size: 1
|
| 197 |
+
expert_parallel_size: 1
|
| 198 |
+
pipeline_model_parallel_size: 1
|
| 199 |
+
max_num_batched_tokens: 8192
|
| 200 |
+
max_model_len: null
|
| 201 |
+
max_num_seqs: 1024
|
| 202 |
+
enable_chunked_prefill: true
|
| 203 |
+
enable_prefix_caching: true
|
| 204 |
+
load_format: safetensors
|
| 205 |
+
log_prob_micro_batch_size: null
|
| 206 |
+
log_prob_micro_batch_size_per_gpu: 32
|
| 207 |
+
log_prob_use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
|
| 208 |
+
log_prob_max_token_len_per_gpu: ${oc.select:actor_rollout_ref.actor.ppo_max_token_len_per_gpu,16384}
|
| 209 |
+
disable_log_stats: true
|
| 210 |
+
do_sample: true
|
| 211 |
+
'n': 5
|
| 212 |
+
over_sample_rate: 0
|
| 213 |
+
multi_stage_wake_up: false
|
| 214 |
+
engine_kwargs:
|
| 215 |
+
vllm: {}
|
| 216 |
+
sglang: {}
|
| 217 |
+
val_kwargs:
|
| 218 |
+
_target_: verl.workers.config.SamplingConfig
|
| 219 |
+
top_k: -1
|
| 220 |
+
top_p: 1.0
|
| 221 |
+
temperature: 0
|
| 222 |
+
'n': 1
|
| 223 |
+
do_sample: false
|
| 224 |
+
multi_turn:
|
| 225 |
+
_target_: verl.workers.config.MultiTurnConfig
|
| 226 |
+
enable: false
|
| 227 |
+
max_assistant_turns: null
|
| 228 |
+
tool_config_path: null
|
| 229 |
+
max_user_turns: null
|
| 230 |
+
max_parallel_calls: 1
|
| 231 |
+
max_tool_response_length: 256
|
| 232 |
+
tool_response_truncate_side: middle
|
| 233 |
+
interaction_config_path: null
|
| 234 |
+
use_inference_chat_template: false
|
| 235 |
+
tokenization_sanity_check_mode: strict
|
| 236 |
+
format: hermes
|
| 237 |
+
num_repeat_rollouts: null
|
| 238 |
+
calculate_log_probs: false
|
| 239 |
+
agent:
|
| 240 |
+
_target_: verl.workers.config.AgentLoopConfig
|
| 241 |
+
num_workers: 8
|
| 242 |
+
default_agent_loop: single_turn_agent
|
| 243 |
+
agent_loop_config_path: null
|
| 244 |
+
custom_async_server:
|
| 245 |
+
_target_: verl.workers.config.CustomAsyncServerConfig
|
| 246 |
+
path: null
|
| 247 |
+
name: null
|
| 248 |
+
update_weights_bucket_megabytes: 512
|
| 249 |
+
trace:
|
| 250 |
+
_target_: verl.workers.config.TraceConfig
|
| 251 |
+
backend: null
|
| 252 |
+
token2text: false
|
| 253 |
+
max_samples_per_step_per_worker: null
|
| 254 |
+
skip_rollout: false
|
| 255 |
+
skip_dump_dir: /tmp/rollout_dump
|
| 256 |
+
skip_tokenizer_init: true
|
| 257 |
+
enable_rollout_routing_replay: false
|
| 258 |
+
profiler:
|
| 259 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 260 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 261 |
+
enable: ${oc.select:actor_rollout_ref.actor.profiler.enable,false}
|
| 262 |
+
all_ranks: ${oc.select:actor_rollout_ref.actor.profiler.all_ranks,false}
|
| 263 |
+
ranks: ${oc.select:actor_rollout_ref.actor.profiler.ranks,[]}
|
| 264 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 265 |
+
tool_config: ${oc.select:actor_rollout_ref.actor.profiler.tool_config,null}
|
| 266 |
+
prometheus:
|
| 267 |
+
_target_: verl.workers.config.PrometheusConfig
|
| 268 |
+
enable: false
|
| 269 |
+
port: 9090
|
| 270 |
+
file: /tmp/ray/session_latest/metrics/prometheus/prometheus.yml
|
| 271 |
+
served_model_name: ${oc.select:actor_rollout_ref.model.path,null}
|
| 272 |
+
layered_summon: true
|
| 273 |
+
model:
|
| 274 |
+
_target_: verl.workers.config.HFModelConfig
|
| 275 |
+
path: Qwen/Qwen3-4B-Instruct-2507
|
| 276 |
+
hf_config_path: null
|
| 277 |
+
tokenizer_path: null
|
| 278 |
+
use_shm: false
|
| 279 |
+
trust_remote_code: false
|
| 280 |
+
custom_chat_template: null
|
| 281 |
+
external_lib: null
|
| 282 |
+
override_config: {}
|
| 283 |
+
enable_gradient_checkpointing: true
|
| 284 |
+
enable_activation_offload: false
|
| 285 |
+
use_remove_padding: true
|
| 286 |
+
lora_rank: 0
|
| 287 |
+
lora_alpha: 16
|
| 288 |
+
target_modules: all-linear
|
| 289 |
+
exclude_modules: null
|
| 290 |
+
lora_adapter_path: null
|
| 291 |
+
use_liger: false
|
| 292 |
+
use_fused_kernels: false
|
| 293 |
+
fused_kernel_options:
|
| 294 |
+
impl_backend: torch
|
| 295 |
+
hybrid_engine: true
|
| 296 |
+
nccl_timeout: 600
|
| 297 |
+
data:
|
| 298 |
+
tokenizer: null
|
| 299 |
+
use_shm: false
|
| 300 |
+
train_files: /root/data/gsm8k/train.parquet
|
| 301 |
+
val_files: /root/data/gsm8k/test.parquet
|
| 302 |
+
train_max_samples: -1
|
| 303 |
+
val_max_samples: -1
|
| 304 |
+
prompt_key: prompt
|
| 305 |
+
reward_fn_key: data_source
|
| 306 |
+
max_prompt_length: 512
|
| 307 |
+
max_response_length: 1024
|
| 308 |
+
train_batch_size: 1024
|
| 309 |
+
val_batch_size: null
|
| 310 |
+
tool_config_path: ${oc.select:actor_rollout_ref.rollout.multi_turn.tool_config_path,
|
| 311 |
+
null}
|
| 312 |
+
return_raw_input_ids: false
|
| 313 |
+
return_raw_chat: true
|
| 314 |
+
return_full_prompt: false
|
| 315 |
+
shuffle: false
|
| 316 |
+
seed: null
|
| 317 |
+
dataloader_num_workers: 8
|
| 318 |
+
image_patch_size: 14
|
| 319 |
+
validation_shuffle: false
|
| 320 |
+
filter_overlong_prompts: true
|
| 321 |
+
filter_overlong_prompts_workers: 1
|
| 322 |
+
truncation: error
|
| 323 |
+
image_key: images
|
| 324 |
+
video_key: videos
|
| 325 |
+
trust_remote_code: false
|
| 326 |
+
custom_cls:
|
| 327 |
+
path: null
|
| 328 |
+
name: null
|
| 329 |
+
return_multi_modal_inputs: true
|
| 330 |
+
sampler:
|
| 331 |
+
class_path: null
|
| 332 |
+
class_name: null
|
| 333 |
+
datagen:
|
| 334 |
+
path: null
|
| 335 |
+
name: null
|
| 336 |
+
apply_chat_template_kwargs: {}
|
| 337 |
+
reward_manager:
|
| 338 |
+
_target_: verl.trainer.config.config.RewardManagerConfig
|
| 339 |
+
source: register
|
| 340 |
+
name: ${oc.select:reward_model.reward_manager,naive}
|
| 341 |
+
module:
|
| 342 |
+
_target_: verl.trainer.config.config.ModuleConfig
|
| 343 |
+
path: null
|
| 344 |
+
name: custom_reward_manager
|
| 345 |
+
critic:
|
| 346 |
+
optim:
|
| 347 |
+
_target_: verl.workers.config.FSDPOptimizerConfig
|
| 348 |
+
optimizer: AdamW
|
| 349 |
+
optimizer_impl: torch.optim
|
| 350 |
+
lr: 1.0e-05
|
| 351 |
+
lr_warmup_steps_ratio: 0.0
|
| 352 |
+
total_training_steps: -1
|
| 353 |
+
weight_decay: 0.01
|
| 354 |
+
lr_warmup_steps: -1
|
| 355 |
+
betas:
|
| 356 |
+
- 0.9
|
| 357 |
+
- 0.999
|
| 358 |
+
clip_grad: 1.0
|
| 359 |
+
min_lr_ratio: 0.0
|
| 360 |
+
num_cycles: 0.5
|
| 361 |
+
lr_scheduler_type: constant
|
| 362 |
+
warmup_style: null
|
| 363 |
+
override_optimizer_config: null
|
| 364 |
+
model:
|
| 365 |
+
fsdp_config:
|
| 366 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 367 |
+
wrap_policy:
|
| 368 |
+
min_num_params: 0
|
| 369 |
+
param_offload: false
|
| 370 |
+
optimizer_offload: false
|
| 371 |
+
offload_policy: false
|
| 372 |
+
reshard_after_forward: true
|
| 373 |
+
fsdp_size: -1
|
| 374 |
+
forward_prefetch: false
|
| 375 |
+
model_dtype: fp32
|
| 376 |
+
use_orig_params: false
|
| 377 |
+
seed: 42
|
| 378 |
+
full_determinism: false
|
| 379 |
+
ulysses_sequence_parallel_size: 1
|
| 380 |
+
entropy_from_logits_with_chunking: false
|
| 381 |
+
use_torch_compile: true
|
| 382 |
+
entropy_checkpointing: false
|
| 383 |
+
forward_only: false
|
| 384 |
+
strategy: fsdp
|
| 385 |
+
dtype: bfloat16
|
| 386 |
+
path: ~/models/deepseek-llm-7b-chat
|
| 387 |
+
tokenizer_path: ${oc.select:actor_rollout_ref.model.path,"~/models/deepseek-llm-7b-chat"}
|
| 388 |
+
override_config: {}
|
| 389 |
+
external_lib: ${oc.select:actor_rollout_ref.model.external_lib,null}
|
| 390 |
+
trust_remote_code: ${oc.select:actor_rollout_ref.model.trust_remote_code,false}
|
| 391 |
+
_target_: verl.workers.config.FSDPCriticModelCfg
|
| 392 |
+
use_shm: false
|
| 393 |
+
enable_gradient_checkpointing: true
|
| 394 |
+
enable_activation_offload: false
|
| 395 |
+
use_remove_padding: false
|
| 396 |
+
lora_rank: 0
|
| 397 |
+
lora_alpha: 16
|
| 398 |
+
target_modules: all-linear
|
| 399 |
+
_target_: verl.workers.config.FSDPCriticConfig
|
| 400 |
+
rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
|
| 401 |
+
strategy: fsdp
|
| 402 |
+
enable: null
|
| 403 |
+
ppo_mini_batch_size: ${oc.select:actor_rollout_ref.actor.ppo_mini_batch_size,256}
|
| 404 |
+
ppo_micro_batch_size: null
|
| 405 |
+
ppo_micro_batch_size_per_gpu: ${oc.select:.ppo_micro_batch_size,null}
|
| 406 |
+
use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
|
| 407 |
+
ppo_max_token_len_per_gpu: 32768
|
| 408 |
+
forward_max_token_len_per_gpu: ${.ppo_max_token_len_per_gpu}
|
| 409 |
+
ppo_epochs: ${oc.select:actor_rollout_ref.actor.ppo_epochs,1}
|
| 410 |
+
shuffle: ${oc.select:actor_rollout_ref.actor.shuffle,false}
|
| 411 |
+
cliprange_value: 0.5
|
| 412 |
+
loss_agg_mode: ${oc.select:actor_rollout_ref.actor.loss_agg_mode,token-mean}
|
| 413 |
+
checkpoint:
|
| 414 |
+
_target_: verl.trainer.config.CheckpointConfig
|
| 415 |
+
save_contents:
|
| 416 |
+
- model
|
| 417 |
+
- optimizer
|
| 418 |
+
- extra
|
| 419 |
+
load_contents: ${.save_contents}
|
| 420 |
+
async_save: false
|
| 421 |
+
profiler:
|
| 422 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 423 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 424 |
+
enable: false
|
| 425 |
+
all_ranks: false
|
| 426 |
+
ranks: []
|
| 427 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 428 |
+
tool_config:
|
| 429 |
+
nsys:
|
| 430 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 431 |
+
discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
|
| 432 |
+
npu:
|
| 433 |
+
_target_: verl.utils.profiler.config.NPUToolConfig
|
| 434 |
+
contents: []
|
| 435 |
+
level: level1
|
| 436 |
+
analysis: true
|
| 437 |
+
discrete: false
|
| 438 |
+
torch:
|
| 439 |
+
_target_: verl.utils.profiler.config.TorchProfilerToolConfig
|
| 440 |
+
step_start: 0
|
| 441 |
+
step_end: null
|
| 442 |
+
torch_memory:
|
| 443 |
+
_target_: verl.utils.profiler.config.TorchMemoryToolConfig
|
| 444 |
+
trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
|
| 445 |
+
stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
|
| 446 |
+
forward_micro_batch_size: ${oc.select:.ppo_micro_batch_size,null}
|
| 447 |
+
forward_micro_batch_size_per_gpu: ${oc.select:.ppo_micro_batch_size_per_gpu,null}
|
| 448 |
+
ulysses_sequence_parallel_size: 1
|
| 449 |
+
grad_clip: 1.0
|
| 450 |
+
reward_model:
|
| 451 |
+
enable: true
|
| 452 |
+
enable_resource_pool: false
|
| 453 |
+
n_gpus_per_node: 0
|
| 454 |
+
nnodes: 0
|
| 455 |
+
strategy: fsdp
|
| 456 |
+
model:
|
| 457 |
+
input_tokenizer: ${actor_rollout_ref.model.path}
|
| 458 |
+
path: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 459 |
+
external_lib: ${actor_rollout_ref.model.external_lib}
|
| 460 |
+
trust_remote_code: false
|
| 461 |
+
override_config: {}
|
| 462 |
+
use_shm: false
|
| 463 |
+
use_remove_padding: false
|
| 464 |
+
use_fused_kernels: ${actor_rollout_ref.model.use_fused_kernels}
|
| 465 |
+
fsdp_config:
|
| 466 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 467 |
+
wrap_policy:
|
| 468 |
+
min_num_params: 0
|
| 469 |
+
param_offload: false
|
| 470 |
+
reshard_after_forward: true
|
| 471 |
+
fsdp_size: -1
|
| 472 |
+
forward_prefetch: false
|
| 473 |
+
micro_batch_size: null
|
| 474 |
+
micro_batch_size_per_gpu: 32
|
| 475 |
+
max_length: null
|
| 476 |
+
use_dynamic_bsz: ${critic.use_dynamic_bsz}
|
| 477 |
+
forward_max_token_len_per_gpu: ${critic.forward_max_token_len_per_gpu}
|
| 478 |
+
reward_manager: naive
|
| 479 |
+
launch_reward_fn_async: false
|
| 480 |
+
sandbox_fusion:
|
| 481 |
+
url: null
|
| 482 |
+
max_concurrent: 64
|
| 483 |
+
memory_limit_mb: 1024
|
| 484 |
+
profiler:
|
| 485 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 486 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 487 |
+
enable: false
|
| 488 |
+
all_ranks: false
|
| 489 |
+
ranks: []
|
| 490 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 491 |
+
tool_config: ${oc.select:actor_rollout_ref.actor.profiler.tool_config,null}
|
| 492 |
+
ulysses_sequence_parallel_size: 1
|
| 493 |
+
use_reward_loop: true
|
| 494 |
+
rollout:
|
| 495 |
+
_target_: verl.workers.config.RolloutConfig
|
| 496 |
+
name: ???
|
| 497 |
+
dtype: bfloat16
|
| 498 |
+
gpu_memory_utilization: 0.5
|
| 499 |
+
enforce_eager: true
|
| 500 |
+
cudagraph_capture_sizes: null
|
| 501 |
+
free_cache_engine: true
|
| 502 |
+
data_parallel_size: 1
|
| 503 |
+
expert_parallel_size: 1
|
| 504 |
+
tensor_model_parallel_size: 2
|
| 505 |
+
max_num_batched_tokens: 8192
|
| 506 |
+
max_model_len: null
|
| 507 |
+
max_num_seqs: 1024
|
| 508 |
+
load_format: auto
|
| 509 |
+
engine_kwargs: {}
|
| 510 |
+
limit_images: null
|
| 511 |
+
enable_chunked_prefill: true
|
| 512 |
+
enable_prefix_caching: true
|
| 513 |
+
disable_log_stats: true
|
| 514 |
+
skip_tokenizer_init: true
|
| 515 |
+
prompt_length: 512
|
| 516 |
+
response_length: 512
|
| 517 |
+
algorithm:
|
| 518 |
+
rollout_correction:
|
| 519 |
+
rollout_is: null
|
| 520 |
+
rollout_is_threshold: 2.0
|
| 521 |
+
rollout_rs: null
|
| 522 |
+
rollout_rs_threshold: null
|
| 523 |
+
rollout_rs_threshold_lower: null
|
| 524 |
+
rollout_token_veto_threshold: null
|
| 525 |
+
bypass_mode: false
|
| 526 |
+
use_policy_gradient: false
|
| 527 |
+
rollout_is_batch_normalize: false
|
| 528 |
+
_target_: verl.trainer.config.AlgoConfig
|
| 529 |
+
gamma: 1.0
|
| 530 |
+
lam: 1.0
|
| 531 |
+
adv_estimator: grpo
|
| 532 |
+
norm_adv_by_std_in_grpo: true
|
| 533 |
+
use_kl_in_reward: false
|
| 534 |
+
kl_penalty: kl
|
| 535 |
+
kl_ctrl:
|
| 536 |
+
_target_: verl.trainer.config.KLControlConfig
|
| 537 |
+
type: fixed
|
| 538 |
+
kl_coef: 0.001
|
| 539 |
+
horizon: 10000
|
| 540 |
+
target_kl: 0.1
|
| 541 |
+
use_pf_ppo: false
|
| 542 |
+
pf_ppo:
|
| 543 |
+
reweight_method: pow
|
| 544 |
+
weight_pow: 2.0
|
| 545 |
+
custom_reward_function:
|
| 546 |
+
path: null
|
| 547 |
+
name: compute_score
|
| 548 |
+
trainer:
|
| 549 |
+
balance_batch: true
|
| 550 |
+
total_epochs: 15
|
| 551 |
+
total_training_steps: null
|
| 552 |
+
project_name: verl_grpo_gsm8k
|
| 553 |
+
experiment_name: qwen3_4b_gsm8k_grpo
|
| 554 |
+
logger:
|
| 555 |
+
- console
|
| 556 |
+
- wandb
|
| 557 |
+
log_val_generations: 0
|
| 558 |
+
rollout_data_dir: null
|
| 559 |
+
validation_data_dir: null
|
| 560 |
+
nnodes: 1
|
| 561 |
+
n_gpus_per_node: 8
|
| 562 |
+
save_freq: 20
|
| 563 |
+
esi_redundant_time: 0
|
| 564 |
+
resume_mode: disable
|
| 565 |
+
resume_from_path: null
|
| 566 |
+
val_before_train: true
|
| 567 |
+
val_only: false
|
| 568 |
+
test_freq: 5
|
| 569 |
+
critic_warmup: 0
|
| 570 |
+
default_hdfs_dir: null
|
| 571 |
+
del_local_ckpt_after_load: false
|
| 572 |
+
default_local_dir: checkpoints/${trainer.project_name}/${trainer.experiment_name}
|
| 573 |
+
max_actor_ckpt_to_keep: null
|
| 574 |
+
max_critic_ckpt_to_keep: null
|
| 575 |
+
ray_wait_register_center_timeout: 300
|
| 576 |
+
device: cuda
|
| 577 |
+
use_legacy_worker_impl: auto
|
| 578 |
+
global_profiler:
|
| 579 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 580 |
+
tool: null
|
| 581 |
+
steps: null
|
| 582 |
+
profile_continuous_steps: false
|
| 583 |
+
save_path: outputs/profile
|
| 584 |
+
global_tool_config:
|
| 585 |
+
nsys:
|
| 586 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 587 |
+
discrete: false
|
| 588 |
+
controller_nsight_options:
|
| 589 |
+
trace: cuda,nvtx,cublas,ucx
|
| 590 |
+
cuda-memory-usage: 'true'
|
| 591 |
+
cuda-graph-trace: graph
|
| 592 |
+
worker_nsight_options:
|
| 593 |
+
trace: cuda,nvtx,cublas,ucx
|
| 594 |
+
cuda-memory-usage: 'true'
|
| 595 |
+
cuda-graph-trace: graph
|
| 596 |
+
capture-range: cudaProfilerApi
|
| 597 |
+
capture-range-end: null
|
| 598 |
+
kill: none
|
| 599 |
+
torch_memory:
|
| 600 |
+
trace_alloc_max_entries: 100000
|
| 601 |
+
stack_depth: 32
|
| 602 |
+
context: all
|
| 603 |
+
stacks: all
|
| 604 |
+
kw_args: {}
|
| 605 |
+
transfer_queue:
|
| 606 |
+
enable: false
|
| 607 |
+
ray_kwargs:
|
| 608 |
+
ray_init:
|
| 609 |
+
num_cpus: null
|
| 610 |
+
timeline_json_file: null
|
examples/grpo_trainer/outputs/2026-01-24/22-51-12/.hydra/overrides.yaml
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
- algorithm.adv_estimator=grpo
|
| 2 |
+
- data.train_files=/root/data/gsm8k/train.parquet
|
| 3 |
+
- data.val_files=/root/data/gsm8k/test.parquet
|
| 4 |
+
- data.train_batch_size=1024
|
| 5 |
+
- data.max_prompt_length=512
|
| 6 |
+
- data.max_response_length=1024
|
| 7 |
+
- data.filter_overlong_prompts=True
|
| 8 |
+
- data.truncation=error
|
| 9 |
+
- data.shuffle=False
|
| 10 |
+
- actor_rollout_ref.model.path=Qwen/Qwen3-4B-Instruct-2507
|
| 11 |
+
- actor_rollout_ref.actor.optim.lr=1e-6
|
| 12 |
+
- actor_rollout_ref.model.use_remove_padding=True
|
| 13 |
+
- actor_rollout_ref.actor.ppo_mini_batch_size=256
|
| 14 |
+
- actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=32
|
| 15 |
+
- actor_rollout_ref.actor.use_kl_loss=True
|
| 16 |
+
- actor_rollout_ref.actor.kl_loss_coef=0.001
|
| 17 |
+
- actor_rollout_ref.actor.kl_loss_type=low_var_kl
|
| 18 |
+
- actor_rollout_ref.actor.entropy_coeff=0
|
| 19 |
+
- actor_rollout_ref.model.enable_gradient_checkpointing=True
|
| 20 |
+
- actor_rollout_ref.actor.fsdp_config.param_offload=True
|
| 21 |
+
- actor_rollout_ref.actor.fsdp_config.optimizer_offload=False
|
| 22 |
+
- actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32
|
| 23 |
+
- actor_rollout_ref.rollout.tensor_model_parallel_size=2
|
| 24 |
+
- actor_rollout_ref.rollout.name=vllm
|
| 25 |
+
- actor_rollout_ref.rollout.gpu_memory_utilization=0.6
|
| 26 |
+
- actor_rollout_ref.rollout.n=5
|
| 27 |
+
- actor_rollout_ref.rollout.load_format=safetensors
|
| 28 |
+
- actor_rollout_ref.rollout.layered_summon=True
|
| 29 |
+
- actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32
|
| 30 |
+
- actor_rollout_ref.ref.fsdp_config.param_offload=False
|
| 31 |
+
- algorithm.use_kl_in_reward=False
|
| 32 |
+
- reward_model.enable=True
|
| 33 |
+
- reward_model.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 34 |
+
- reward_model.micro_batch_size_per_gpu=32
|
| 35 |
+
- trainer.critic_warmup=0
|
| 36 |
+
- trainer.logger=["console","wandb"]
|
| 37 |
+
- trainer.project_name=verl_grpo_gsm8k
|
| 38 |
+
- trainer.experiment_name=qwen3_4b_gsm8k_grpo
|
| 39 |
+
- trainer.n_gpus_per_node=8
|
| 40 |
+
- trainer.nnodes=1
|
| 41 |
+
- trainer.save_freq=20
|
| 42 |
+
- trainer.test_freq=5
|
| 43 |
+
- trainer.total_epochs=15
|
| 44 |
+
- trainer.resume_mode=disable
|
examples/grpo_trainer/outputs/2026-01-24/22-52-15/.hydra/overrides.yaml
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
- algorithm.adv_estimator=grpo
|
| 2 |
+
- data.train_files=/root/data/gsm8k/train.parquet
|
| 3 |
+
- data.val_files=/root/data/gsm8k/test.parquet
|
| 4 |
+
- data.train_batch_size=1024
|
| 5 |
+
- data.max_prompt_length=512
|
| 6 |
+
- data.max_response_length=1024
|
| 7 |
+
- data.filter_overlong_prompts=True
|
| 8 |
+
- data.truncation=error
|
| 9 |
+
- data.shuffle=False
|
| 10 |
+
- actor_rollout_ref.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 11 |
+
- actor_rollout_ref.actor.optim.lr=1e-6
|
| 12 |
+
- actor_rollout_ref.model.use_remove_padding=True
|
| 13 |
+
- actor_rollout_ref.actor.ppo_mini_batch_size=256
|
| 14 |
+
- actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=32
|
| 15 |
+
- actor_rollout_ref.actor.use_kl_loss=True
|
| 16 |
+
- actor_rollout_ref.actor.kl_loss_coef=0.001
|
| 17 |
+
- actor_rollout_ref.actor.kl_loss_type=low_var_kl
|
| 18 |
+
- actor_rollout_ref.actor.entropy_coeff=0
|
| 19 |
+
- actor_rollout_ref.model.enable_gradient_checkpointing=True
|
| 20 |
+
- actor_rollout_ref.actor.fsdp_config.param_offload=True
|
| 21 |
+
- actor_rollout_ref.actor.fsdp_config.optimizer_offload=False
|
| 22 |
+
- actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32
|
| 23 |
+
- actor_rollout_ref.rollout.tensor_model_parallel_size=2
|
| 24 |
+
- actor_rollout_ref.rollout.name=vllm
|
| 25 |
+
- actor_rollout_ref.rollout.gpu_memory_utilization=0.6
|
| 26 |
+
- actor_rollout_ref.rollout.n=5
|
| 27 |
+
- actor_rollout_ref.rollout.load_format=safetensors
|
| 28 |
+
- actor_rollout_ref.rollout.layered_summon=True
|
| 29 |
+
- actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32
|
| 30 |
+
- actor_rollout_ref.ref.fsdp_config.param_offload=False
|
| 31 |
+
- algorithm.use_kl_in_reward=False
|
| 32 |
+
- reward_model.enable=True
|
| 33 |
+
- reward_model.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/reward_model/best_model.pt
|
| 34 |
+
- reward_model.micro_batch_size_per_gpu=32
|
| 35 |
+
- trainer.critic_warmup=0
|
| 36 |
+
- trainer.logger=["console","wandb"]
|
| 37 |
+
- trainer.project_name=verl_grpo_gsm8k
|
| 38 |
+
- trainer.experiment_name=qwen3_4b_gsm8k_grpo
|
| 39 |
+
- trainer.n_gpus_per_node=8
|
| 40 |
+
- trainer.nnodes=1
|
| 41 |
+
- trainer.save_freq=20
|
| 42 |
+
- trainer.test_freq=5
|
| 43 |
+
- trainer.total_epochs=15
|
| 44 |
+
- trainer.resume_mode=disable
|
examples/grpo_trainer/outputs/2026-01-24/22-53-56/.hydra/hydra.yaml
ADDED
|
@@ -0,0 +1,212 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
hydra:
|
| 2 |
+
run:
|
| 3 |
+
dir: outputs/${now:%Y-%m-%d}/${now:%H-%M-%S}
|
| 4 |
+
sweep:
|
| 5 |
+
dir: multirun/${now:%Y-%m-%d}/${now:%H-%M-%S}
|
| 6 |
+
subdir: ${hydra.job.num}
|
| 7 |
+
launcher:
|
| 8 |
+
_target_: hydra._internal.core_plugins.basic_launcher.BasicLauncher
|
| 9 |
+
sweeper:
|
| 10 |
+
_target_: hydra._internal.core_plugins.basic_sweeper.BasicSweeper
|
| 11 |
+
max_batch_size: null
|
| 12 |
+
params: null
|
| 13 |
+
help:
|
| 14 |
+
app_name: ${hydra.job.name}
|
| 15 |
+
header: '${hydra.help.app_name} is powered by Hydra.
|
| 16 |
+
|
| 17 |
+
'
|
| 18 |
+
footer: 'Powered by Hydra (https://hydra.cc)
|
| 19 |
+
|
| 20 |
+
Use --hydra-help to view Hydra specific help
|
| 21 |
+
|
| 22 |
+
'
|
| 23 |
+
template: '${hydra.help.header}
|
| 24 |
+
|
| 25 |
+
== Configuration groups ==
|
| 26 |
+
|
| 27 |
+
Compose your configuration from those groups (group=option)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
$APP_CONFIG_GROUPS
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
== Config ==
|
| 34 |
+
|
| 35 |
+
Override anything in the config (foo.bar=value)
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
$CONFIG
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
${hydra.help.footer}
|
| 42 |
+
|
| 43 |
+
'
|
| 44 |
+
hydra_help:
|
| 45 |
+
template: 'Hydra (${hydra.runtime.version})
|
| 46 |
+
|
| 47 |
+
See https://hydra.cc for more info.
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
== Flags ==
|
| 51 |
+
|
| 52 |
+
$FLAGS_HELP
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
== Configuration groups ==
|
| 56 |
+
|
| 57 |
+
Compose your configuration from those groups (For example, append hydra/job_logging=disabled
|
| 58 |
+
to command line)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
$HYDRA_CONFIG_GROUPS
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
Use ''--cfg hydra'' to Show the Hydra config.
|
| 65 |
+
|
| 66 |
+
'
|
| 67 |
+
hydra_help: ???
|
| 68 |
+
hydra_logging:
|
| 69 |
+
version: 1
|
| 70 |
+
formatters:
|
| 71 |
+
simple:
|
| 72 |
+
format: '[%(asctime)s][HYDRA] %(message)s'
|
| 73 |
+
handlers:
|
| 74 |
+
console:
|
| 75 |
+
class: logging.StreamHandler
|
| 76 |
+
formatter: simple
|
| 77 |
+
stream: ext://sys.stdout
|
| 78 |
+
root:
|
| 79 |
+
level: INFO
|
| 80 |
+
handlers:
|
| 81 |
+
- console
|
| 82 |
+
loggers:
|
| 83 |
+
logging_example:
|
| 84 |
+
level: DEBUG
|
| 85 |
+
disable_existing_loggers: false
|
| 86 |
+
job_logging:
|
| 87 |
+
version: 1
|
| 88 |
+
formatters:
|
| 89 |
+
simple:
|
| 90 |
+
format: '[%(asctime)s][%(name)s][%(levelname)s] - %(message)s'
|
| 91 |
+
handlers:
|
| 92 |
+
console:
|
| 93 |
+
class: logging.StreamHandler
|
| 94 |
+
formatter: simple
|
| 95 |
+
stream: ext://sys.stdout
|
| 96 |
+
file:
|
| 97 |
+
class: logging.FileHandler
|
| 98 |
+
formatter: simple
|
| 99 |
+
filename: ${hydra.runtime.output_dir}/${hydra.job.name}.log
|
| 100 |
+
root:
|
| 101 |
+
level: INFO
|
| 102 |
+
handlers:
|
| 103 |
+
- console
|
| 104 |
+
- file
|
| 105 |
+
disable_existing_loggers: false
|
| 106 |
+
env: {}
|
| 107 |
+
mode: RUN
|
| 108 |
+
searchpath: []
|
| 109 |
+
callbacks: {}
|
| 110 |
+
output_subdir: .hydra
|
| 111 |
+
overrides:
|
| 112 |
+
hydra:
|
| 113 |
+
- hydra.mode=RUN
|
| 114 |
+
task:
|
| 115 |
+
- algorithm.adv_estimator=grpo
|
| 116 |
+
- data.train_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/train.parquet
|
| 117 |
+
- data.val_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/test.parquet
|
| 118 |
+
- data.train_batch_size=1024
|
| 119 |
+
- data.max_prompt_length=512
|
| 120 |
+
- data.max_response_length=1024
|
| 121 |
+
- data.filter_overlong_prompts=True
|
| 122 |
+
- data.truncation=error
|
| 123 |
+
- data.shuffle=False
|
| 124 |
+
- actor_rollout_ref.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 125 |
+
- actor_rollout_ref.actor.optim.lr=1e-6
|
| 126 |
+
- actor_rollout_ref.model.use_remove_padding=True
|
| 127 |
+
- actor_rollout_ref.actor.ppo_mini_batch_size=256
|
| 128 |
+
- actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=32
|
| 129 |
+
- actor_rollout_ref.actor.use_kl_loss=True
|
| 130 |
+
- actor_rollout_ref.actor.kl_loss_coef=0.001
|
| 131 |
+
- actor_rollout_ref.actor.kl_loss_type=low_var_kl
|
| 132 |
+
- actor_rollout_ref.actor.entropy_coeff=0
|
| 133 |
+
- actor_rollout_ref.model.enable_gradient_checkpointing=True
|
| 134 |
+
- actor_rollout_ref.actor.fsdp_config.param_offload=True
|
| 135 |
+
- actor_rollout_ref.actor.fsdp_config.optimizer_offload=False
|
| 136 |
+
- actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32
|
| 137 |
+
- actor_rollout_ref.rollout.tensor_model_parallel_size=2
|
| 138 |
+
- actor_rollout_ref.rollout.name=vllm
|
| 139 |
+
- actor_rollout_ref.rollout.gpu_memory_utilization=0.6
|
| 140 |
+
- actor_rollout_ref.rollout.n=5
|
| 141 |
+
- actor_rollout_ref.rollout.load_format=safetensors
|
| 142 |
+
- actor_rollout_ref.rollout.layered_summon=True
|
| 143 |
+
- actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32
|
| 144 |
+
- actor_rollout_ref.ref.fsdp_config.param_offload=False
|
| 145 |
+
- algorithm.use_kl_in_reward=False
|
| 146 |
+
- reward_model.enable=True
|
| 147 |
+
- reward_model.model.path=/data/models/reward/qwen3_4b_prm
|
| 148 |
+
- reward_model.model.input_tokenizer=Qwen/Qwen3-4B-Instruct-2507
|
| 149 |
+
- reward_model.micro_batch_size_per_gpu=32
|
| 150 |
+
- trainer.critic_warmup=0
|
| 151 |
+
- trainer.logger=["console","wandb"]
|
| 152 |
+
- trainer.project_name=verl_grpo_gsm8k
|
| 153 |
+
- trainer.experiment_name=qwen3_4b_gsm8k_grpo
|
| 154 |
+
- trainer.n_gpus_per_node=8
|
| 155 |
+
- trainer.nnodes=1
|
| 156 |
+
- trainer.save_freq=20
|
| 157 |
+
- trainer.test_freq=5
|
| 158 |
+
- trainer.total_epochs=15
|
| 159 |
+
- trainer.resume_mode=disable
|
| 160 |
+
job:
|
| 161 |
+
name: main_ppo
|
| 162 |
+
chdir: null
|
| 163 |
+
override_dirname: actor_rollout_ref.actor.entropy_coeff=0,actor_rollout_ref.actor.fsdp_config.optimizer_offload=False,actor_rollout_ref.actor.fsdp_config.param_offload=True,actor_rollout_ref.actor.kl_loss_coef=0.001,actor_rollout_ref.actor.kl_loss_type=low_var_kl,actor_rollout_ref.actor.optim.lr=1e-6,actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=32,actor_rollout_ref.actor.ppo_mini_batch_size=256,actor_rollout_ref.actor.use_kl_loss=True,actor_rollout_ref.model.enable_gradient_checkpointing=True,actor_rollout_ref.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507,actor_rollout_ref.model.use_remove_padding=True,actor_rollout_ref.ref.fsdp_config.param_offload=False,actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32,actor_rollout_ref.rollout.gpu_memory_utilization=0.6,actor_rollout_ref.rollout.layered_summon=True,actor_rollout_ref.rollout.load_format=safetensors,actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32,actor_rollout_ref.rollout.n=5,actor_rollout_ref.rollout.name=vllm,actor_rollout_ref.rollout.tensor_model_parallel_size=2,algorithm.adv_estimator=grpo,algorithm.use_kl_in_reward=False,data.filter_overlong_prompts=True,data.max_prompt_length=512,data.max_response_length=1024,data.shuffle=False,data.train_batch_size=1024,data.train_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/train.parquet,data.truncation=error,data.val_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/test.parquet,reward_model.enable=True,reward_model.micro_batch_size_per_gpu=32,reward_model.model.input_tokenizer=Qwen/Qwen3-4B-Instruct-2507,reward_model.model.path=/data/models/reward/qwen3_4b_prm,trainer.critic_warmup=0,trainer.experiment_name=qwen3_4b_gsm8k_grpo,trainer.logger=["console","wandb"],trainer.n_gpus_per_node=8,trainer.nnodes=1,trainer.project_name=verl_grpo_gsm8k,trainer.resume_mode=disable,trainer.save_freq=20,trainer.test_freq=5,trainer.total_epochs=15
|
| 164 |
+
id: ???
|
| 165 |
+
num: ???
|
| 166 |
+
config_name: ppo_trainer
|
| 167 |
+
env_set: {}
|
| 168 |
+
env_copy: []
|
| 169 |
+
config:
|
| 170 |
+
override_dirname:
|
| 171 |
+
kv_sep: '='
|
| 172 |
+
item_sep: ','
|
| 173 |
+
exclude_keys: []
|
| 174 |
+
runtime:
|
| 175 |
+
version: 1.3.2
|
| 176 |
+
version_base: '1.3'
|
| 177 |
+
cwd: /mnt/tidal-alsh01/usr/zhangruiqi1/my/verl/examples/grpo_trainer
|
| 178 |
+
config_sources:
|
| 179 |
+
- path: hydra.conf
|
| 180 |
+
schema: pkg
|
| 181 |
+
provider: hydra
|
| 182 |
+
- path: /mnt/tidal-alsh01/usr/zhangruiqi1/my/verl/verl/trainer/config
|
| 183 |
+
schema: file
|
| 184 |
+
provider: main
|
| 185 |
+
- path: ''
|
| 186 |
+
schema: structured
|
| 187 |
+
provider: schema
|
| 188 |
+
output_dir: /mnt/tidal-alsh01/usr/zhangruiqi1/my/verl/examples/grpo_trainer/outputs/2026-01-24/22-53-56
|
| 189 |
+
choices:
|
| 190 |
+
algorithm@algorithm.rollout_correction: rollout_correction
|
| 191 |
+
reward_model: dp_reward_loop
|
| 192 |
+
critic: dp_critic
|
| 193 |
+
critic/../engine@critic.model.fsdp_config: fsdp
|
| 194 |
+
critic/../optim@critic.optim: fsdp
|
| 195 |
+
model@actor_rollout_ref.model: hf_model
|
| 196 |
+
rollout@actor_rollout_ref.rollout: rollout
|
| 197 |
+
ref@actor_rollout_ref.ref: dp_ref
|
| 198 |
+
ref/../engine@actor_rollout_ref.ref.fsdp_config: fsdp
|
| 199 |
+
data: legacy_data
|
| 200 |
+
actor@actor_rollout_ref.actor: dp_actor
|
| 201 |
+
actor/../engine@actor_rollout_ref.actor.fsdp_config: fsdp
|
| 202 |
+
actor/../optim@actor_rollout_ref.actor.optim: fsdp
|
| 203 |
+
hydra/env: default
|
| 204 |
+
hydra/callbacks: null
|
| 205 |
+
hydra/job_logging: default
|
| 206 |
+
hydra/hydra_logging: default
|
| 207 |
+
hydra/hydra_help: default
|
| 208 |
+
hydra/help: default
|
| 209 |
+
hydra/sweeper: basic
|
| 210 |
+
hydra/launcher: basic
|
| 211 |
+
hydra/output: default
|
| 212 |
+
verbose: false
|
examples/grpo_trainer/outputs/2026-01-24/22-53-56/.hydra/overrides.yaml
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
- algorithm.adv_estimator=grpo
|
| 2 |
+
- data.train_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/train.parquet
|
| 3 |
+
- data.val_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/test.parquet
|
| 4 |
+
- data.train_batch_size=1024
|
| 5 |
+
- data.max_prompt_length=512
|
| 6 |
+
- data.max_response_length=1024
|
| 7 |
+
- data.filter_overlong_prompts=True
|
| 8 |
+
- data.truncation=error
|
| 9 |
+
- data.shuffle=False
|
| 10 |
+
- actor_rollout_ref.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 11 |
+
- actor_rollout_ref.actor.optim.lr=1e-6
|
| 12 |
+
- actor_rollout_ref.model.use_remove_padding=True
|
| 13 |
+
- actor_rollout_ref.actor.ppo_mini_batch_size=256
|
| 14 |
+
- actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=32
|
| 15 |
+
- actor_rollout_ref.actor.use_kl_loss=True
|
| 16 |
+
- actor_rollout_ref.actor.kl_loss_coef=0.001
|
| 17 |
+
- actor_rollout_ref.actor.kl_loss_type=low_var_kl
|
| 18 |
+
- actor_rollout_ref.actor.entropy_coeff=0
|
| 19 |
+
- actor_rollout_ref.model.enable_gradient_checkpointing=True
|
| 20 |
+
- actor_rollout_ref.actor.fsdp_config.param_offload=True
|
| 21 |
+
- actor_rollout_ref.actor.fsdp_config.optimizer_offload=False
|
| 22 |
+
- actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32
|
| 23 |
+
- actor_rollout_ref.rollout.tensor_model_parallel_size=2
|
| 24 |
+
- actor_rollout_ref.rollout.name=vllm
|
| 25 |
+
- actor_rollout_ref.rollout.gpu_memory_utilization=0.6
|
| 26 |
+
- actor_rollout_ref.rollout.n=5
|
| 27 |
+
- actor_rollout_ref.rollout.load_format=safetensors
|
| 28 |
+
- actor_rollout_ref.rollout.layered_summon=True
|
| 29 |
+
- actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32
|
| 30 |
+
- actor_rollout_ref.ref.fsdp_config.param_offload=False
|
| 31 |
+
- algorithm.use_kl_in_reward=False
|
| 32 |
+
- reward_model.enable=True
|
| 33 |
+
- reward_model.model.path=/data/models/reward/qwen3_4b_prm
|
| 34 |
+
- reward_model.model.input_tokenizer=Qwen/Qwen3-4B-Instruct-2507
|
| 35 |
+
- reward_model.micro_batch_size_per_gpu=32
|
| 36 |
+
- trainer.critic_warmup=0
|
| 37 |
+
- trainer.logger=["console","wandb"]
|
| 38 |
+
- trainer.project_name=verl_grpo_gsm8k
|
| 39 |
+
- trainer.experiment_name=qwen3_4b_gsm8k_grpo
|
| 40 |
+
- trainer.n_gpus_per_node=8
|
| 41 |
+
- trainer.nnodes=1
|
| 42 |
+
- trainer.save_freq=20
|
| 43 |
+
- trainer.test_freq=5
|
| 44 |
+
- trainer.total_epochs=15
|
| 45 |
+
- trainer.resume_mode=disable
|
examples/grpo_trainer/outputs/2026-01-24/22-56-04/.hydra/config.yaml
ADDED
|
@@ -0,0 +1,610 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
actor_rollout_ref:
|
| 2 |
+
actor:
|
| 3 |
+
optim:
|
| 4 |
+
_target_: verl.workers.config.FSDPOptimizerConfig
|
| 5 |
+
optimizer: AdamW
|
| 6 |
+
optimizer_impl: torch.optim
|
| 7 |
+
lr: 1.0e-06
|
| 8 |
+
lr_warmup_steps_ratio: 0.0
|
| 9 |
+
total_training_steps: -1
|
| 10 |
+
weight_decay: 0.01
|
| 11 |
+
lr_warmup_steps: -1
|
| 12 |
+
betas:
|
| 13 |
+
- 0.9
|
| 14 |
+
- 0.999
|
| 15 |
+
clip_grad: 1.0
|
| 16 |
+
min_lr_ratio: 0.0
|
| 17 |
+
num_cycles: 0.5
|
| 18 |
+
lr_scheduler_type: constant
|
| 19 |
+
warmup_style: null
|
| 20 |
+
override_optimizer_config: null
|
| 21 |
+
fsdp_config:
|
| 22 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 23 |
+
wrap_policy:
|
| 24 |
+
min_num_params: 0
|
| 25 |
+
param_offload: true
|
| 26 |
+
optimizer_offload: false
|
| 27 |
+
offload_policy: false
|
| 28 |
+
reshard_after_forward: true
|
| 29 |
+
fsdp_size: -1
|
| 30 |
+
forward_prefetch: false
|
| 31 |
+
model_dtype: fp32
|
| 32 |
+
use_orig_params: false
|
| 33 |
+
seed: 42
|
| 34 |
+
full_determinism: false
|
| 35 |
+
ulysses_sequence_parallel_size: 1
|
| 36 |
+
entropy_from_logits_with_chunking: false
|
| 37 |
+
use_torch_compile: true
|
| 38 |
+
entropy_checkpointing: false
|
| 39 |
+
forward_only: false
|
| 40 |
+
strategy: fsdp
|
| 41 |
+
dtype: bfloat16
|
| 42 |
+
_target_: verl.workers.config.FSDPActorConfig
|
| 43 |
+
rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
|
| 44 |
+
strategy: fsdp
|
| 45 |
+
ppo_mini_batch_size: 256
|
| 46 |
+
ppo_micro_batch_size: null
|
| 47 |
+
ppo_micro_batch_size_per_gpu: 32
|
| 48 |
+
use_dynamic_bsz: false
|
| 49 |
+
ppo_max_token_len_per_gpu: 16384
|
| 50 |
+
clip_ratio: 0.2
|
| 51 |
+
clip_ratio_low: 0.2
|
| 52 |
+
clip_ratio_high: 0.2
|
| 53 |
+
freeze_vision_tower: false
|
| 54 |
+
policy_loss:
|
| 55 |
+
_target_: verl.workers.config.PolicyLossConfig
|
| 56 |
+
loss_mode: vanilla
|
| 57 |
+
clip_cov_ratio: 0.0002
|
| 58 |
+
clip_cov_lb: 1.0
|
| 59 |
+
clip_cov_ub: 5.0
|
| 60 |
+
kl_cov_ratio: 0.0002
|
| 61 |
+
ppo_kl_coef: 0.1
|
| 62 |
+
clip_ratio_c: 3.0
|
| 63 |
+
loss_agg_mode: token-mean
|
| 64 |
+
loss_scale_factor: null
|
| 65 |
+
entropy_coeff: 0
|
| 66 |
+
calculate_entropy: false
|
| 67 |
+
use_kl_loss: true
|
| 68 |
+
use_torch_compile: true
|
| 69 |
+
kl_loss_coef: 0.001
|
| 70 |
+
kl_loss_type: low_var_kl
|
| 71 |
+
ppo_epochs: 1
|
| 72 |
+
shuffle: false
|
| 73 |
+
checkpoint:
|
| 74 |
+
_target_: verl.trainer.config.CheckpointConfig
|
| 75 |
+
save_contents:
|
| 76 |
+
- model
|
| 77 |
+
- optimizer
|
| 78 |
+
- extra
|
| 79 |
+
load_contents: ${.save_contents}
|
| 80 |
+
async_save: false
|
| 81 |
+
use_fused_kernels: ${oc.select:actor_rollout_ref.model.use_fused_kernels,false}
|
| 82 |
+
profiler:
|
| 83 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 84 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 85 |
+
enable: false
|
| 86 |
+
all_ranks: false
|
| 87 |
+
ranks: []
|
| 88 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 89 |
+
tool_config:
|
| 90 |
+
nsys:
|
| 91 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 92 |
+
discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
|
| 93 |
+
npu:
|
| 94 |
+
_target_: verl.utils.profiler.config.NPUToolConfig
|
| 95 |
+
contents: []
|
| 96 |
+
level: level1
|
| 97 |
+
analysis: true
|
| 98 |
+
discrete: false
|
| 99 |
+
torch:
|
| 100 |
+
_target_: verl.utils.profiler.config.TorchProfilerToolConfig
|
| 101 |
+
step_start: 0
|
| 102 |
+
step_end: null
|
| 103 |
+
torch_memory:
|
| 104 |
+
_target_: verl.utils.profiler.config.TorchMemoryToolConfig
|
| 105 |
+
trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
|
| 106 |
+
stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
|
| 107 |
+
router_replay:
|
| 108 |
+
_target_: verl.workers.config.RouterReplayConfig
|
| 109 |
+
mode: disabled
|
| 110 |
+
record_file: null
|
| 111 |
+
replay_file: null
|
| 112 |
+
grad_clip: 1.0
|
| 113 |
+
ulysses_sequence_parallel_size: 1
|
| 114 |
+
entropy_from_logits_with_chunking: false
|
| 115 |
+
entropy_checkpointing: false
|
| 116 |
+
use_remove_padding: ${oc.select:actor_rollout_ref.model.use_remove_padding,false}
|
| 117 |
+
ref:
|
| 118 |
+
rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
|
| 119 |
+
strategy: ${actor_rollout_ref.actor.strategy}
|
| 120 |
+
use_torch_compile: ${oc.select:actor_rollout_ref.actor.use_torch_compile,true}
|
| 121 |
+
log_prob_micro_batch_size: null
|
| 122 |
+
log_prob_micro_batch_size_per_gpu: 32
|
| 123 |
+
log_prob_use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
|
| 124 |
+
log_prob_max_token_len_per_gpu: ${oc.select:actor_rollout_ref.actor.ppo_max_token_len_per_gpu,16384}
|
| 125 |
+
profiler:
|
| 126 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 127 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 128 |
+
enable: false
|
| 129 |
+
all_ranks: false
|
| 130 |
+
ranks: []
|
| 131 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 132 |
+
tool_config:
|
| 133 |
+
nsys:
|
| 134 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 135 |
+
discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
|
| 136 |
+
npu:
|
| 137 |
+
_target_: verl.utils.profiler.config.NPUToolConfig
|
| 138 |
+
contents: []
|
| 139 |
+
level: level1
|
| 140 |
+
analysis: true
|
| 141 |
+
discrete: false
|
| 142 |
+
torch:
|
| 143 |
+
_target_: verl.utils.profiler.config.TorchProfilerToolConfig
|
| 144 |
+
step_start: 0
|
| 145 |
+
step_end: null
|
| 146 |
+
torch_memory:
|
| 147 |
+
_target_: verl.utils.profiler.config.TorchMemoryToolConfig
|
| 148 |
+
trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
|
| 149 |
+
stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
|
| 150 |
+
router_replay:
|
| 151 |
+
_target_: verl.workers.config.RouterReplayConfig
|
| 152 |
+
mode: disabled
|
| 153 |
+
record_file: null
|
| 154 |
+
replay_file: null
|
| 155 |
+
fsdp_config:
|
| 156 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 157 |
+
wrap_policy:
|
| 158 |
+
min_num_params: 0
|
| 159 |
+
param_offload: false
|
| 160 |
+
optimizer_offload: false
|
| 161 |
+
offload_policy: false
|
| 162 |
+
reshard_after_forward: true
|
| 163 |
+
fsdp_size: -1
|
| 164 |
+
forward_prefetch: false
|
| 165 |
+
model_dtype: fp32
|
| 166 |
+
use_orig_params: false
|
| 167 |
+
seed: 42
|
| 168 |
+
full_determinism: false
|
| 169 |
+
ulysses_sequence_parallel_size: 1
|
| 170 |
+
entropy_from_logits_with_chunking: false
|
| 171 |
+
use_torch_compile: true
|
| 172 |
+
entropy_checkpointing: false
|
| 173 |
+
forward_only: true
|
| 174 |
+
strategy: fsdp
|
| 175 |
+
dtype: bfloat16
|
| 176 |
+
_target_: verl.workers.config.FSDPActorConfig
|
| 177 |
+
ulysses_sequence_parallel_size: ${oc.select:actor_rollout_ref.actor.ulysses_sequence_parallel_size,1}
|
| 178 |
+
entropy_from_logits_with_chunking: false
|
| 179 |
+
entropy_checkpointing: false
|
| 180 |
+
rollout:
|
| 181 |
+
_target_: verl.workers.config.RolloutConfig
|
| 182 |
+
name: vllm
|
| 183 |
+
mode: async
|
| 184 |
+
temperature: 1.0
|
| 185 |
+
top_k: -1
|
| 186 |
+
top_p: 1
|
| 187 |
+
prompt_length: ${oc.select:data.max_prompt_length,512}
|
| 188 |
+
response_length: ${oc.select:data.max_response_length,512}
|
| 189 |
+
dtype: bfloat16
|
| 190 |
+
gpu_memory_utilization: 0.6
|
| 191 |
+
ignore_eos: false
|
| 192 |
+
enforce_eager: false
|
| 193 |
+
cudagraph_capture_sizes: null
|
| 194 |
+
free_cache_engine: true
|
| 195 |
+
tensor_model_parallel_size: 2
|
| 196 |
+
data_parallel_size: 1
|
| 197 |
+
expert_parallel_size: 1
|
| 198 |
+
pipeline_model_parallel_size: 1
|
| 199 |
+
max_num_batched_tokens: 8192
|
| 200 |
+
max_model_len: null
|
| 201 |
+
max_num_seqs: 1024
|
| 202 |
+
enable_chunked_prefill: true
|
| 203 |
+
enable_prefix_caching: true
|
| 204 |
+
load_format: safetensors
|
| 205 |
+
log_prob_micro_batch_size: null
|
| 206 |
+
log_prob_micro_batch_size_per_gpu: 32
|
| 207 |
+
log_prob_use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
|
| 208 |
+
log_prob_max_token_len_per_gpu: ${oc.select:actor_rollout_ref.actor.ppo_max_token_len_per_gpu,16384}
|
| 209 |
+
disable_log_stats: true
|
| 210 |
+
do_sample: true
|
| 211 |
+
'n': 5
|
| 212 |
+
over_sample_rate: 0
|
| 213 |
+
multi_stage_wake_up: false
|
| 214 |
+
engine_kwargs:
|
| 215 |
+
vllm: {}
|
| 216 |
+
sglang: {}
|
| 217 |
+
val_kwargs:
|
| 218 |
+
_target_: verl.workers.config.SamplingConfig
|
| 219 |
+
top_k: -1
|
| 220 |
+
top_p: 1.0
|
| 221 |
+
temperature: 0
|
| 222 |
+
'n': 1
|
| 223 |
+
do_sample: false
|
| 224 |
+
multi_turn:
|
| 225 |
+
_target_: verl.workers.config.MultiTurnConfig
|
| 226 |
+
enable: false
|
| 227 |
+
max_assistant_turns: null
|
| 228 |
+
tool_config_path: null
|
| 229 |
+
max_user_turns: null
|
| 230 |
+
max_parallel_calls: 1
|
| 231 |
+
max_tool_response_length: 256
|
| 232 |
+
tool_response_truncate_side: middle
|
| 233 |
+
interaction_config_path: null
|
| 234 |
+
use_inference_chat_template: false
|
| 235 |
+
tokenization_sanity_check_mode: strict
|
| 236 |
+
format: hermes
|
| 237 |
+
num_repeat_rollouts: null
|
| 238 |
+
calculate_log_probs: false
|
| 239 |
+
agent:
|
| 240 |
+
_target_: verl.workers.config.AgentLoopConfig
|
| 241 |
+
num_workers: 8
|
| 242 |
+
default_agent_loop: single_turn_agent
|
| 243 |
+
agent_loop_config_path: null
|
| 244 |
+
custom_async_server:
|
| 245 |
+
_target_: verl.workers.config.CustomAsyncServerConfig
|
| 246 |
+
path: null
|
| 247 |
+
name: null
|
| 248 |
+
update_weights_bucket_megabytes: 512
|
| 249 |
+
trace:
|
| 250 |
+
_target_: verl.workers.config.TraceConfig
|
| 251 |
+
backend: null
|
| 252 |
+
token2text: false
|
| 253 |
+
max_samples_per_step_per_worker: null
|
| 254 |
+
skip_rollout: false
|
| 255 |
+
skip_dump_dir: /tmp/rollout_dump
|
| 256 |
+
skip_tokenizer_init: true
|
| 257 |
+
enable_rollout_routing_replay: false
|
| 258 |
+
profiler:
|
| 259 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 260 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 261 |
+
enable: ${oc.select:actor_rollout_ref.actor.profiler.enable,false}
|
| 262 |
+
all_ranks: ${oc.select:actor_rollout_ref.actor.profiler.all_ranks,false}
|
| 263 |
+
ranks: ${oc.select:actor_rollout_ref.actor.profiler.ranks,[]}
|
| 264 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 265 |
+
tool_config: ${oc.select:actor_rollout_ref.actor.profiler.tool_config,null}
|
| 266 |
+
prometheus:
|
| 267 |
+
_target_: verl.workers.config.PrometheusConfig
|
| 268 |
+
enable: false
|
| 269 |
+
port: 9090
|
| 270 |
+
file: /tmp/ray/session_latest/metrics/prometheus/prometheus.yml
|
| 271 |
+
served_model_name: ${oc.select:actor_rollout_ref.model.path,null}
|
| 272 |
+
layered_summon: true
|
| 273 |
+
model:
|
| 274 |
+
_target_: verl.workers.config.HFModelConfig
|
| 275 |
+
path: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 276 |
+
hf_config_path: null
|
| 277 |
+
tokenizer_path: null
|
| 278 |
+
use_shm: false
|
| 279 |
+
trust_remote_code: false
|
| 280 |
+
custom_chat_template: null
|
| 281 |
+
external_lib: null
|
| 282 |
+
override_config: {}
|
| 283 |
+
enable_gradient_checkpointing: true
|
| 284 |
+
enable_activation_offload: false
|
| 285 |
+
use_remove_padding: true
|
| 286 |
+
lora_rank: 0
|
| 287 |
+
lora_alpha: 16
|
| 288 |
+
target_modules: all-linear
|
| 289 |
+
exclude_modules: null
|
| 290 |
+
lora_adapter_path: null
|
| 291 |
+
use_liger: false
|
| 292 |
+
use_fused_kernels: false
|
| 293 |
+
fused_kernel_options:
|
| 294 |
+
impl_backend: torch
|
| 295 |
+
hybrid_engine: true
|
| 296 |
+
nccl_timeout: 600
|
| 297 |
+
data:
|
| 298 |
+
tokenizer: null
|
| 299 |
+
use_shm: false
|
| 300 |
+
train_files: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/train.parquet
|
| 301 |
+
val_files: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/test.parquet
|
| 302 |
+
train_max_samples: -1
|
| 303 |
+
val_max_samples: -1
|
| 304 |
+
prompt_key: prompt
|
| 305 |
+
reward_fn_key: data_source
|
| 306 |
+
max_prompt_length: 512
|
| 307 |
+
max_response_length: 1024
|
| 308 |
+
train_batch_size: 1024
|
| 309 |
+
val_batch_size: null
|
| 310 |
+
tool_config_path: ${oc.select:actor_rollout_ref.rollout.multi_turn.tool_config_path,
|
| 311 |
+
null}
|
| 312 |
+
return_raw_input_ids: false
|
| 313 |
+
return_raw_chat: true
|
| 314 |
+
return_full_prompt: false
|
| 315 |
+
shuffle: false
|
| 316 |
+
seed: null
|
| 317 |
+
dataloader_num_workers: 8
|
| 318 |
+
image_patch_size: 14
|
| 319 |
+
validation_shuffle: false
|
| 320 |
+
filter_overlong_prompts: true
|
| 321 |
+
filter_overlong_prompts_workers: 1
|
| 322 |
+
truncation: error
|
| 323 |
+
image_key: images
|
| 324 |
+
video_key: videos
|
| 325 |
+
trust_remote_code: false
|
| 326 |
+
custom_cls:
|
| 327 |
+
path: null
|
| 328 |
+
name: null
|
| 329 |
+
return_multi_modal_inputs: true
|
| 330 |
+
sampler:
|
| 331 |
+
class_path: null
|
| 332 |
+
class_name: null
|
| 333 |
+
datagen:
|
| 334 |
+
path: null
|
| 335 |
+
name: null
|
| 336 |
+
apply_chat_template_kwargs: {}
|
| 337 |
+
reward_manager:
|
| 338 |
+
_target_: verl.trainer.config.config.RewardManagerConfig
|
| 339 |
+
source: register
|
| 340 |
+
name: ${oc.select:reward_model.reward_manager,naive}
|
| 341 |
+
module:
|
| 342 |
+
_target_: verl.trainer.config.config.ModuleConfig
|
| 343 |
+
path: null
|
| 344 |
+
name: custom_reward_manager
|
| 345 |
+
critic:
|
| 346 |
+
optim:
|
| 347 |
+
_target_: verl.workers.config.FSDPOptimizerConfig
|
| 348 |
+
optimizer: AdamW
|
| 349 |
+
optimizer_impl: torch.optim
|
| 350 |
+
lr: 1.0e-05
|
| 351 |
+
lr_warmup_steps_ratio: 0.0
|
| 352 |
+
total_training_steps: -1
|
| 353 |
+
weight_decay: 0.01
|
| 354 |
+
lr_warmup_steps: -1
|
| 355 |
+
betas:
|
| 356 |
+
- 0.9
|
| 357 |
+
- 0.999
|
| 358 |
+
clip_grad: 1.0
|
| 359 |
+
min_lr_ratio: 0.0
|
| 360 |
+
num_cycles: 0.5
|
| 361 |
+
lr_scheduler_type: constant
|
| 362 |
+
warmup_style: null
|
| 363 |
+
override_optimizer_config: null
|
| 364 |
+
model:
|
| 365 |
+
fsdp_config:
|
| 366 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 367 |
+
wrap_policy:
|
| 368 |
+
min_num_params: 0
|
| 369 |
+
param_offload: false
|
| 370 |
+
optimizer_offload: false
|
| 371 |
+
offload_policy: false
|
| 372 |
+
reshard_after_forward: true
|
| 373 |
+
fsdp_size: -1
|
| 374 |
+
forward_prefetch: false
|
| 375 |
+
model_dtype: fp32
|
| 376 |
+
use_orig_params: false
|
| 377 |
+
seed: 42
|
| 378 |
+
full_determinism: false
|
| 379 |
+
ulysses_sequence_parallel_size: 1
|
| 380 |
+
entropy_from_logits_with_chunking: false
|
| 381 |
+
use_torch_compile: true
|
| 382 |
+
entropy_checkpointing: false
|
| 383 |
+
forward_only: false
|
| 384 |
+
strategy: fsdp
|
| 385 |
+
dtype: bfloat16
|
| 386 |
+
path: ~/models/deepseek-llm-7b-chat
|
| 387 |
+
tokenizer_path: ${oc.select:actor_rollout_ref.model.path,"~/models/deepseek-llm-7b-chat"}
|
| 388 |
+
override_config: {}
|
| 389 |
+
external_lib: ${oc.select:actor_rollout_ref.model.external_lib,null}
|
| 390 |
+
trust_remote_code: ${oc.select:actor_rollout_ref.model.trust_remote_code,false}
|
| 391 |
+
_target_: verl.workers.config.FSDPCriticModelCfg
|
| 392 |
+
use_shm: false
|
| 393 |
+
enable_gradient_checkpointing: true
|
| 394 |
+
enable_activation_offload: false
|
| 395 |
+
use_remove_padding: false
|
| 396 |
+
lora_rank: 0
|
| 397 |
+
lora_alpha: 16
|
| 398 |
+
target_modules: all-linear
|
| 399 |
+
_target_: verl.workers.config.FSDPCriticConfig
|
| 400 |
+
rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
|
| 401 |
+
strategy: fsdp
|
| 402 |
+
enable: null
|
| 403 |
+
ppo_mini_batch_size: ${oc.select:actor_rollout_ref.actor.ppo_mini_batch_size,256}
|
| 404 |
+
ppo_micro_batch_size: null
|
| 405 |
+
ppo_micro_batch_size_per_gpu: ${oc.select:.ppo_micro_batch_size,null}
|
| 406 |
+
use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
|
| 407 |
+
ppo_max_token_len_per_gpu: 32768
|
| 408 |
+
forward_max_token_len_per_gpu: ${.ppo_max_token_len_per_gpu}
|
| 409 |
+
ppo_epochs: ${oc.select:actor_rollout_ref.actor.ppo_epochs,1}
|
| 410 |
+
shuffle: ${oc.select:actor_rollout_ref.actor.shuffle,false}
|
| 411 |
+
cliprange_value: 0.5
|
| 412 |
+
loss_agg_mode: ${oc.select:actor_rollout_ref.actor.loss_agg_mode,token-mean}
|
| 413 |
+
checkpoint:
|
| 414 |
+
_target_: verl.trainer.config.CheckpointConfig
|
| 415 |
+
save_contents:
|
| 416 |
+
- model
|
| 417 |
+
- optimizer
|
| 418 |
+
- extra
|
| 419 |
+
load_contents: ${.save_contents}
|
| 420 |
+
async_save: false
|
| 421 |
+
profiler:
|
| 422 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 423 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 424 |
+
enable: false
|
| 425 |
+
all_ranks: false
|
| 426 |
+
ranks: []
|
| 427 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 428 |
+
tool_config:
|
| 429 |
+
nsys:
|
| 430 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 431 |
+
discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
|
| 432 |
+
npu:
|
| 433 |
+
_target_: verl.utils.profiler.config.NPUToolConfig
|
| 434 |
+
contents: []
|
| 435 |
+
level: level1
|
| 436 |
+
analysis: true
|
| 437 |
+
discrete: false
|
| 438 |
+
torch:
|
| 439 |
+
_target_: verl.utils.profiler.config.TorchProfilerToolConfig
|
| 440 |
+
step_start: 0
|
| 441 |
+
step_end: null
|
| 442 |
+
torch_memory:
|
| 443 |
+
_target_: verl.utils.profiler.config.TorchMemoryToolConfig
|
| 444 |
+
trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
|
| 445 |
+
stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
|
| 446 |
+
forward_micro_batch_size: ${oc.select:.ppo_micro_batch_size,null}
|
| 447 |
+
forward_micro_batch_size_per_gpu: ${oc.select:.ppo_micro_batch_size_per_gpu,null}
|
| 448 |
+
ulysses_sequence_parallel_size: 1
|
| 449 |
+
grad_clip: 1.0
|
| 450 |
+
reward_model:
|
| 451 |
+
enable: true
|
| 452 |
+
enable_resource_pool: false
|
| 453 |
+
n_gpus_per_node: 0
|
| 454 |
+
nnodes: 0
|
| 455 |
+
strategy: fsdp
|
| 456 |
+
model:
|
| 457 |
+
input_tokenizer: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 458 |
+
path: /data/models/reward/qwen3_4b_prm
|
| 459 |
+
external_lib: ${actor_rollout_ref.model.external_lib}
|
| 460 |
+
trust_remote_code: false
|
| 461 |
+
override_config: {}
|
| 462 |
+
use_shm: false
|
| 463 |
+
use_remove_padding: false
|
| 464 |
+
use_fused_kernels: ${actor_rollout_ref.model.use_fused_kernels}
|
| 465 |
+
fsdp_config:
|
| 466 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 467 |
+
wrap_policy:
|
| 468 |
+
min_num_params: 0
|
| 469 |
+
param_offload: false
|
| 470 |
+
reshard_after_forward: true
|
| 471 |
+
fsdp_size: -1
|
| 472 |
+
forward_prefetch: false
|
| 473 |
+
micro_batch_size: null
|
| 474 |
+
micro_batch_size_per_gpu: 32
|
| 475 |
+
max_length: null
|
| 476 |
+
use_dynamic_bsz: ${critic.use_dynamic_bsz}
|
| 477 |
+
forward_max_token_len_per_gpu: ${critic.forward_max_token_len_per_gpu}
|
| 478 |
+
reward_manager: naive
|
| 479 |
+
launch_reward_fn_async: false
|
| 480 |
+
sandbox_fusion:
|
| 481 |
+
url: null
|
| 482 |
+
max_concurrent: 64
|
| 483 |
+
memory_limit_mb: 1024
|
| 484 |
+
profiler:
|
| 485 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 486 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 487 |
+
enable: false
|
| 488 |
+
all_ranks: false
|
| 489 |
+
ranks: []
|
| 490 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 491 |
+
tool_config: ${oc.select:actor_rollout_ref.actor.profiler.tool_config,null}
|
| 492 |
+
ulysses_sequence_parallel_size: 1
|
| 493 |
+
use_reward_loop: true
|
| 494 |
+
rollout:
|
| 495 |
+
_target_: verl.workers.config.RolloutConfig
|
| 496 |
+
name: ???
|
| 497 |
+
dtype: bfloat16
|
| 498 |
+
gpu_memory_utilization: 0.5
|
| 499 |
+
enforce_eager: true
|
| 500 |
+
cudagraph_capture_sizes: null
|
| 501 |
+
free_cache_engine: true
|
| 502 |
+
data_parallel_size: 1
|
| 503 |
+
expert_parallel_size: 1
|
| 504 |
+
tensor_model_parallel_size: 2
|
| 505 |
+
max_num_batched_tokens: 8192
|
| 506 |
+
max_model_len: null
|
| 507 |
+
max_num_seqs: 1024
|
| 508 |
+
load_format: auto
|
| 509 |
+
engine_kwargs: {}
|
| 510 |
+
limit_images: null
|
| 511 |
+
enable_chunked_prefill: true
|
| 512 |
+
enable_prefix_caching: true
|
| 513 |
+
disable_log_stats: true
|
| 514 |
+
skip_tokenizer_init: true
|
| 515 |
+
prompt_length: 512
|
| 516 |
+
response_length: 512
|
| 517 |
+
algorithm:
|
| 518 |
+
rollout_correction:
|
| 519 |
+
rollout_is: null
|
| 520 |
+
rollout_is_threshold: 2.0
|
| 521 |
+
rollout_rs: null
|
| 522 |
+
rollout_rs_threshold: null
|
| 523 |
+
rollout_rs_threshold_lower: null
|
| 524 |
+
rollout_token_veto_threshold: null
|
| 525 |
+
bypass_mode: false
|
| 526 |
+
use_policy_gradient: false
|
| 527 |
+
rollout_is_batch_normalize: false
|
| 528 |
+
_target_: verl.trainer.config.AlgoConfig
|
| 529 |
+
gamma: 1.0
|
| 530 |
+
lam: 1.0
|
| 531 |
+
adv_estimator: grpo
|
| 532 |
+
norm_adv_by_std_in_grpo: true
|
| 533 |
+
use_kl_in_reward: false
|
| 534 |
+
kl_penalty: kl
|
| 535 |
+
kl_ctrl:
|
| 536 |
+
_target_: verl.trainer.config.KLControlConfig
|
| 537 |
+
type: fixed
|
| 538 |
+
kl_coef: 0.001
|
| 539 |
+
horizon: 10000
|
| 540 |
+
target_kl: 0.1
|
| 541 |
+
use_pf_ppo: false
|
| 542 |
+
pf_ppo:
|
| 543 |
+
reweight_method: pow
|
| 544 |
+
weight_pow: 2.0
|
| 545 |
+
custom_reward_function:
|
| 546 |
+
path: null
|
| 547 |
+
name: compute_score
|
| 548 |
+
trainer:
|
| 549 |
+
balance_batch: true
|
| 550 |
+
total_epochs: 15
|
| 551 |
+
total_training_steps: null
|
| 552 |
+
project_name: verl_grpo_gsm8k
|
| 553 |
+
experiment_name: qwen3_4b_gsm8k_grpo
|
| 554 |
+
logger:
|
| 555 |
+
- console
|
| 556 |
+
- wandb
|
| 557 |
+
log_val_generations: 0
|
| 558 |
+
rollout_data_dir: null
|
| 559 |
+
validation_data_dir: null
|
| 560 |
+
nnodes: 1
|
| 561 |
+
n_gpus_per_node: 8
|
| 562 |
+
save_freq: 20
|
| 563 |
+
esi_redundant_time: 0
|
| 564 |
+
resume_mode: disable
|
| 565 |
+
resume_from_path: null
|
| 566 |
+
val_before_train: true
|
| 567 |
+
val_only: false
|
| 568 |
+
test_freq: 5
|
| 569 |
+
critic_warmup: 0
|
| 570 |
+
default_hdfs_dir: null
|
| 571 |
+
del_local_ckpt_after_load: false
|
| 572 |
+
default_local_dir: checkpoints/${trainer.project_name}/${trainer.experiment_name}
|
| 573 |
+
max_actor_ckpt_to_keep: null
|
| 574 |
+
max_critic_ckpt_to_keep: null
|
| 575 |
+
ray_wait_register_center_timeout: 300
|
| 576 |
+
device: cuda
|
| 577 |
+
use_legacy_worker_impl: auto
|
| 578 |
+
global_profiler:
|
| 579 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 580 |
+
tool: null
|
| 581 |
+
steps: null
|
| 582 |
+
profile_continuous_steps: false
|
| 583 |
+
save_path: outputs/profile
|
| 584 |
+
global_tool_config:
|
| 585 |
+
nsys:
|
| 586 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 587 |
+
discrete: false
|
| 588 |
+
controller_nsight_options:
|
| 589 |
+
trace: cuda,nvtx,cublas,ucx
|
| 590 |
+
cuda-memory-usage: 'true'
|
| 591 |
+
cuda-graph-trace: graph
|
| 592 |
+
worker_nsight_options:
|
| 593 |
+
trace: cuda,nvtx,cublas,ucx
|
| 594 |
+
cuda-memory-usage: 'true'
|
| 595 |
+
cuda-graph-trace: graph
|
| 596 |
+
capture-range: cudaProfilerApi
|
| 597 |
+
capture-range-end: null
|
| 598 |
+
kill: none
|
| 599 |
+
torch_memory:
|
| 600 |
+
trace_alloc_max_entries: 100000
|
| 601 |
+
stack_depth: 32
|
| 602 |
+
context: all
|
| 603 |
+
stacks: all
|
| 604 |
+
kw_args: {}
|
| 605 |
+
transfer_queue:
|
| 606 |
+
enable: false
|
| 607 |
+
ray_kwargs:
|
| 608 |
+
ray_init:
|
| 609 |
+
num_cpus: null
|
| 610 |
+
timeline_json_file: null
|
examples/grpo_trainer/outputs/2026-01-24/22-56-04/.hydra/hydra.yaml
ADDED
|
@@ -0,0 +1,212 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
hydra:
|
| 2 |
+
run:
|
| 3 |
+
dir: outputs/${now:%Y-%m-%d}/${now:%H-%M-%S}
|
| 4 |
+
sweep:
|
| 5 |
+
dir: multirun/${now:%Y-%m-%d}/${now:%H-%M-%S}
|
| 6 |
+
subdir: ${hydra.job.num}
|
| 7 |
+
launcher:
|
| 8 |
+
_target_: hydra._internal.core_plugins.basic_launcher.BasicLauncher
|
| 9 |
+
sweeper:
|
| 10 |
+
_target_: hydra._internal.core_plugins.basic_sweeper.BasicSweeper
|
| 11 |
+
max_batch_size: null
|
| 12 |
+
params: null
|
| 13 |
+
help:
|
| 14 |
+
app_name: ${hydra.job.name}
|
| 15 |
+
header: '${hydra.help.app_name} is powered by Hydra.
|
| 16 |
+
|
| 17 |
+
'
|
| 18 |
+
footer: 'Powered by Hydra (https://hydra.cc)
|
| 19 |
+
|
| 20 |
+
Use --hydra-help to view Hydra specific help
|
| 21 |
+
|
| 22 |
+
'
|
| 23 |
+
template: '${hydra.help.header}
|
| 24 |
+
|
| 25 |
+
== Configuration groups ==
|
| 26 |
+
|
| 27 |
+
Compose your configuration from those groups (group=option)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
$APP_CONFIG_GROUPS
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
== Config ==
|
| 34 |
+
|
| 35 |
+
Override anything in the config (foo.bar=value)
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
$CONFIG
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
${hydra.help.footer}
|
| 42 |
+
|
| 43 |
+
'
|
| 44 |
+
hydra_help:
|
| 45 |
+
template: 'Hydra (${hydra.runtime.version})
|
| 46 |
+
|
| 47 |
+
See https://hydra.cc for more info.
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
== Flags ==
|
| 51 |
+
|
| 52 |
+
$FLAGS_HELP
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
== Configuration groups ==
|
| 56 |
+
|
| 57 |
+
Compose your configuration from those groups (For example, append hydra/job_logging=disabled
|
| 58 |
+
to command line)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
$HYDRA_CONFIG_GROUPS
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
Use ''--cfg hydra'' to Show the Hydra config.
|
| 65 |
+
|
| 66 |
+
'
|
| 67 |
+
hydra_help: ???
|
| 68 |
+
hydra_logging:
|
| 69 |
+
version: 1
|
| 70 |
+
formatters:
|
| 71 |
+
simple:
|
| 72 |
+
format: '[%(asctime)s][HYDRA] %(message)s'
|
| 73 |
+
handlers:
|
| 74 |
+
console:
|
| 75 |
+
class: logging.StreamHandler
|
| 76 |
+
formatter: simple
|
| 77 |
+
stream: ext://sys.stdout
|
| 78 |
+
root:
|
| 79 |
+
level: INFO
|
| 80 |
+
handlers:
|
| 81 |
+
- console
|
| 82 |
+
loggers:
|
| 83 |
+
logging_example:
|
| 84 |
+
level: DEBUG
|
| 85 |
+
disable_existing_loggers: false
|
| 86 |
+
job_logging:
|
| 87 |
+
version: 1
|
| 88 |
+
formatters:
|
| 89 |
+
simple:
|
| 90 |
+
format: '[%(asctime)s][%(name)s][%(levelname)s] - %(message)s'
|
| 91 |
+
handlers:
|
| 92 |
+
console:
|
| 93 |
+
class: logging.StreamHandler
|
| 94 |
+
formatter: simple
|
| 95 |
+
stream: ext://sys.stdout
|
| 96 |
+
file:
|
| 97 |
+
class: logging.FileHandler
|
| 98 |
+
formatter: simple
|
| 99 |
+
filename: ${hydra.runtime.output_dir}/${hydra.job.name}.log
|
| 100 |
+
root:
|
| 101 |
+
level: INFO
|
| 102 |
+
handlers:
|
| 103 |
+
- console
|
| 104 |
+
- file
|
| 105 |
+
disable_existing_loggers: false
|
| 106 |
+
env: {}
|
| 107 |
+
mode: RUN
|
| 108 |
+
searchpath: []
|
| 109 |
+
callbacks: {}
|
| 110 |
+
output_subdir: .hydra
|
| 111 |
+
overrides:
|
| 112 |
+
hydra:
|
| 113 |
+
- hydra.mode=RUN
|
| 114 |
+
task:
|
| 115 |
+
- algorithm.adv_estimator=grpo
|
| 116 |
+
- data.train_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/train.parquet
|
| 117 |
+
- data.val_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/test.parquet
|
| 118 |
+
- data.train_batch_size=1024
|
| 119 |
+
- data.max_prompt_length=512
|
| 120 |
+
- data.max_response_length=1024
|
| 121 |
+
- data.filter_overlong_prompts=True
|
| 122 |
+
- data.truncation=error
|
| 123 |
+
- data.shuffle=False
|
| 124 |
+
- actor_rollout_ref.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 125 |
+
- actor_rollout_ref.actor.optim.lr=1e-6
|
| 126 |
+
- actor_rollout_ref.model.use_remove_padding=True
|
| 127 |
+
- actor_rollout_ref.actor.ppo_mini_batch_size=256
|
| 128 |
+
- actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=32
|
| 129 |
+
- actor_rollout_ref.actor.use_kl_loss=True
|
| 130 |
+
- actor_rollout_ref.actor.kl_loss_coef=0.001
|
| 131 |
+
- actor_rollout_ref.actor.kl_loss_type=low_var_kl
|
| 132 |
+
- actor_rollout_ref.actor.entropy_coeff=0
|
| 133 |
+
- actor_rollout_ref.model.enable_gradient_checkpointing=True
|
| 134 |
+
- actor_rollout_ref.actor.fsdp_config.param_offload=True
|
| 135 |
+
- actor_rollout_ref.actor.fsdp_config.optimizer_offload=False
|
| 136 |
+
- actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32
|
| 137 |
+
- actor_rollout_ref.rollout.tensor_model_parallel_size=2
|
| 138 |
+
- actor_rollout_ref.rollout.name=vllm
|
| 139 |
+
- actor_rollout_ref.rollout.gpu_memory_utilization=0.6
|
| 140 |
+
- actor_rollout_ref.rollout.n=5
|
| 141 |
+
- actor_rollout_ref.rollout.load_format=safetensors
|
| 142 |
+
- actor_rollout_ref.rollout.layered_summon=True
|
| 143 |
+
- actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32
|
| 144 |
+
- actor_rollout_ref.ref.fsdp_config.param_offload=False
|
| 145 |
+
- algorithm.use_kl_in_reward=False
|
| 146 |
+
- reward_model.enable=True
|
| 147 |
+
- reward_model.model.path=/data/models/reward/qwen3_4b_prm
|
| 148 |
+
- reward_model.model.input_tokenizer=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 149 |
+
- reward_model.micro_batch_size_per_gpu=32
|
| 150 |
+
- trainer.critic_warmup=0
|
| 151 |
+
- trainer.logger=["console","wandb"]
|
| 152 |
+
- trainer.project_name=verl_grpo_gsm8k
|
| 153 |
+
- trainer.experiment_name=qwen3_4b_gsm8k_grpo
|
| 154 |
+
- trainer.n_gpus_per_node=8
|
| 155 |
+
- trainer.nnodes=1
|
| 156 |
+
- trainer.save_freq=20
|
| 157 |
+
- trainer.test_freq=5
|
| 158 |
+
- trainer.total_epochs=15
|
| 159 |
+
- trainer.resume_mode=disable
|
| 160 |
+
job:
|
| 161 |
+
name: main_ppo
|
| 162 |
+
chdir: null
|
| 163 |
+
override_dirname: actor_rollout_ref.actor.entropy_coeff=0,actor_rollout_ref.actor.fsdp_config.optimizer_offload=False,actor_rollout_ref.actor.fsdp_config.param_offload=True,actor_rollout_ref.actor.kl_loss_coef=0.001,actor_rollout_ref.actor.kl_loss_type=low_var_kl,actor_rollout_ref.actor.optim.lr=1e-6,actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=32,actor_rollout_ref.actor.ppo_mini_batch_size=256,actor_rollout_ref.actor.use_kl_loss=True,actor_rollout_ref.model.enable_gradient_checkpointing=True,actor_rollout_ref.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507,actor_rollout_ref.model.use_remove_padding=True,actor_rollout_ref.ref.fsdp_config.param_offload=False,actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32,actor_rollout_ref.rollout.gpu_memory_utilization=0.6,actor_rollout_ref.rollout.layered_summon=True,actor_rollout_ref.rollout.load_format=safetensors,actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32,actor_rollout_ref.rollout.n=5,actor_rollout_ref.rollout.name=vllm,actor_rollout_ref.rollout.tensor_model_parallel_size=2,algorithm.adv_estimator=grpo,algorithm.use_kl_in_reward=False,data.filter_overlong_prompts=True,data.max_prompt_length=512,data.max_response_length=1024,data.shuffle=False,data.train_batch_size=1024,data.train_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/train.parquet,data.truncation=error,data.val_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/test.parquet,reward_model.enable=True,reward_model.micro_batch_size_per_gpu=32,reward_model.model.input_tokenizer=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507,reward_model.model.path=/data/models/reward/qwen3_4b_prm,trainer.critic_warmup=0,trainer.experiment_name=qwen3_4b_gsm8k_grpo,trainer.logger=["console","wandb"],trainer.n_gpus_per_node=8,trainer.nnodes=1,trainer.project_name=verl_grpo_gsm8k,trainer.resume_mode=disable,trainer.save_freq=20,trainer.test_freq=5,trainer.total_epochs=15
|
| 164 |
+
id: ???
|
| 165 |
+
num: ???
|
| 166 |
+
config_name: ppo_trainer
|
| 167 |
+
env_set: {}
|
| 168 |
+
env_copy: []
|
| 169 |
+
config:
|
| 170 |
+
override_dirname:
|
| 171 |
+
kv_sep: '='
|
| 172 |
+
item_sep: ','
|
| 173 |
+
exclude_keys: []
|
| 174 |
+
runtime:
|
| 175 |
+
version: 1.3.2
|
| 176 |
+
version_base: '1.3'
|
| 177 |
+
cwd: /mnt/tidal-alsh01/usr/zhangruiqi1/my/verl/examples/grpo_trainer
|
| 178 |
+
config_sources:
|
| 179 |
+
- path: hydra.conf
|
| 180 |
+
schema: pkg
|
| 181 |
+
provider: hydra
|
| 182 |
+
- path: /mnt/tidal-alsh01/usr/zhangruiqi1/my/verl/verl/trainer/config
|
| 183 |
+
schema: file
|
| 184 |
+
provider: main
|
| 185 |
+
- path: ''
|
| 186 |
+
schema: structured
|
| 187 |
+
provider: schema
|
| 188 |
+
output_dir: /mnt/tidal-alsh01/usr/zhangruiqi1/my/verl/examples/grpo_trainer/outputs/2026-01-24/22-56-04
|
| 189 |
+
choices:
|
| 190 |
+
algorithm@algorithm.rollout_correction: rollout_correction
|
| 191 |
+
reward_model: dp_reward_loop
|
| 192 |
+
critic: dp_critic
|
| 193 |
+
critic/../engine@critic.model.fsdp_config: fsdp
|
| 194 |
+
critic/../optim@critic.optim: fsdp
|
| 195 |
+
model@actor_rollout_ref.model: hf_model
|
| 196 |
+
rollout@actor_rollout_ref.rollout: rollout
|
| 197 |
+
ref@actor_rollout_ref.ref: dp_ref
|
| 198 |
+
ref/../engine@actor_rollout_ref.ref.fsdp_config: fsdp
|
| 199 |
+
data: legacy_data
|
| 200 |
+
actor@actor_rollout_ref.actor: dp_actor
|
| 201 |
+
actor/../engine@actor_rollout_ref.actor.fsdp_config: fsdp
|
| 202 |
+
actor/../optim@actor_rollout_ref.actor.optim: fsdp
|
| 203 |
+
hydra/env: default
|
| 204 |
+
hydra/callbacks: null
|
| 205 |
+
hydra/job_logging: default
|
| 206 |
+
hydra/hydra_logging: default
|
| 207 |
+
hydra/hydra_help: default
|
| 208 |
+
hydra/help: default
|
| 209 |
+
hydra/sweeper: basic
|
| 210 |
+
hydra/launcher: basic
|
| 211 |
+
hydra/output: default
|
| 212 |
+
verbose: false
|
examples/grpo_trainer/outputs/2026-01-24/22-59-57/.hydra/config.yaml
ADDED
|
@@ -0,0 +1,610 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
actor_rollout_ref:
|
| 2 |
+
actor:
|
| 3 |
+
optim:
|
| 4 |
+
_target_: verl.workers.config.FSDPOptimizerConfig
|
| 5 |
+
optimizer: AdamW
|
| 6 |
+
optimizer_impl: torch.optim
|
| 7 |
+
lr: 1.0e-06
|
| 8 |
+
lr_warmup_steps_ratio: 0.0
|
| 9 |
+
total_training_steps: -1
|
| 10 |
+
weight_decay: 0.01
|
| 11 |
+
lr_warmup_steps: -1
|
| 12 |
+
betas:
|
| 13 |
+
- 0.9
|
| 14 |
+
- 0.999
|
| 15 |
+
clip_grad: 1.0
|
| 16 |
+
min_lr_ratio: 0.0
|
| 17 |
+
num_cycles: 0.5
|
| 18 |
+
lr_scheduler_type: constant
|
| 19 |
+
warmup_style: null
|
| 20 |
+
override_optimizer_config: null
|
| 21 |
+
fsdp_config:
|
| 22 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 23 |
+
wrap_policy:
|
| 24 |
+
min_num_params: 0
|
| 25 |
+
param_offload: true
|
| 26 |
+
optimizer_offload: false
|
| 27 |
+
offload_policy: false
|
| 28 |
+
reshard_after_forward: true
|
| 29 |
+
fsdp_size: -1
|
| 30 |
+
forward_prefetch: false
|
| 31 |
+
model_dtype: fp32
|
| 32 |
+
use_orig_params: false
|
| 33 |
+
seed: 42
|
| 34 |
+
full_determinism: false
|
| 35 |
+
ulysses_sequence_parallel_size: 1
|
| 36 |
+
entropy_from_logits_with_chunking: false
|
| 37 |
+
use_torch_compile: true
|
| 38 |
+
entropy_checkpointing: false
|
| 39 |
+
forward_only: false
|
| 40 |
+
strategy: fsdp
|
| 41 |
+
dtype: bfloat16
|
| 42 |
+
_target_: verl.workers.config.FSDPActorConfig
|
| 43 |
+
rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
|
| 44 |
+
strategy: fsdp
|
| 45 |
+
ppo_mini_batch_size: 256
|
| 46 |
+
ppo_micro_batch_size: null
|
| 47 |
+
ppo_micro_batch_size_per_gpu: 32
|
| 48 |
+
use_dynamic_bsz: false
|
| 49 |
+
ppo_max_token_len_per_gpu: 16384
|
| 50 |
+
clip_ratio: 0.2
|
| 51 |
+
clip_ratio_low: 0.2
|
| 52 |
+
clip_ratio_high: 0.2
|
| 53 |
+
freeze_vision_tower: false
|
| 54 |
+
policy_loss:
|
| 55 |
+
_target_: verl.workers.config.PolicyLossConfig
|
| 56 |
+
loss_mode: vanilla
|
| 57 |
+
clip_cov_ratio: 0.0002
|
| 58 |
+
clip_cov_lb: 1.0
|
| 59 |
+
clip_cov_ub: 5.0
|
| 60 |
+
kl_cov_ratio: 0.0002
|
| 61 |
+
ppo_kl_coef: 0.1
|
| 62 |
+
clip_ratio_c: 3.0
|
| 63 |
+
loss_agg_mode: token-mean
|
| 64 |
+
loss_scale_factor: null
|
| 65 |
+
entropy_coeff: 0
|
| 66 |
+
calculate_entropy: false
|
| 67 |
+
use_kl_loss: true
|
| 68 |
+
use_torch_compile: true
|
| 69 |
+
kl_loss_coef: 0.001
|
| 70 |
+
kl_loss_type: low_var_kl
|
| 71 |
+
ppo_epochs: 1
|
| 72 |
+
shuffle: false
|
| 73 |
+
checkpoint:
|
| 74 |
+
_target_: verl.trainer.config.CheckpointConfig
|
| 75 |
+
save_contents:
|
| 76 |
+
- model
|
| 77 |
+
- optimizer
|
| 78 |
+
- extra
|
| 79 |
+
load_contents: ${.save_contents}
|
| 80 |
+
async_save: false
|
| 81 |
+
use_fused_kernels: ${oc.select:actor_rollout_ref.model.use_fused_kernels,false}
|
| 82 |
+
profiler:
|
| 83 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 84 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 85 |
+
enable: false
|
| 86 |
+
all_ranks: false
|
| 87 |
+
ranks: []
|
| 88 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 89 |
+
tool_config:
|
| 90 |
+
nsys:
|
| 91 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 92 |
+
discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
|
| 93 |
+
npu:
|
| 94 |
+
_target_: verl.utils.profiler.config.NPUToolConfig
|
| 95 |
+
contents: []
|
| 96 |
+
level: level1
|
| 97 |
+
analysis: true
|
| 98 |
+
discrete: false
|
| 99 |
+
torch:
|
| 100 |
+
_target_: verl.utils.profiler.config.TorchProfilerToolConfig
|
| 101 |
+
step_start: 0
|
| 102 |
+
step_end: null
|
| 103 |
+
torch_memory:
|
| 104 |
+
_target_: verl.utils.profiler.config.TorchMemoryToolConfig
|
| 105 |
+
trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
|
| 106 |
+
stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
|
| 107 |
+
router_replay:
|
| 108 |
+
_target_: verl.workers.config.RouterReplayConfig
|
| 109 |
+
mode: disabled
|
| 110 |
+
record_file: null
|
| 111 |
+
replay_file: null
|
| 112 |
+
grad_clip: 1.0
|
| 113 |
+
ulysses_sequence_parallel_size: 1
|
| 114 |
+
entropy_from_logits_with_chunking: false
|
| 115 |
+
entropy_checkpointing: false
|
| 116 |
+
use_remove_padding: ${oc.select:actor_rollout_ref.model.use_remove_padding,false}
|
| 117 |
+
ref:
|
| 118 |
+
rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
|
| 119 |
+
strategy: ${actor_rollout_ref.actor.strategy}
|
| 120 |
+
use_torch_compile: ${oc.select:actor_rollout_ref.actor.use_torch_compile,true}
|
| 121 |
+
log_prob_micro_batch_size: null
|
| 122 |
+
log_prob_micro_batch_size_per_gpu: 32
|
| 123 |
+
log_prob_use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
|
| 124 |
+
log_prob_max_token_len_per_gpu: ${oc.select:actor_rollout_ref.actor.ppo_max_token_len_per_gpu,16384}
|
| 125 |
+
profiler:
|
| 126 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 127 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 128 |
+
enable: false
|
| 129 |
+
all_ranks: false
|
| 130 |
+
ranks: []
|
| 131 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 132 |
+
tool_config:
|
| 133 |
+
nsys:
|
| 134 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 135 |
+
discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
|
| 136 |
+
npu:
|
| 137 |
+
_target_: verl.utils.profiler.config.NPUToolConfig
|
| 138 |
+
contents: []
|
| 139 |
+
level: level1
|
| 140 |
+
analysis: true
|
| 141 |
+
discrete: false
|
| 142 |
+
torch:
|
| 143 |
+
_target_: verl.utils.profiler.config.TorchProfilerToolConfig
|
| 144 |
+
step_start: 0
|
| 145 |
+
step_end: null
|
| 146 |
+
torch_memory:
|
| 147 |
+
_target_: verl.utils.profiler.config.TorchMemoryToolConfig
|
| 148 |
+
trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
|
| 149 |
+
stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
|
| 150 |
+
router_replay:
|
| 151 |
+
_target_: verl.workers.config.RouterReplayConfig
|
| 152 |
+
mode: disabled
|
| 153 |
+
record_file: null
|
| 154 |
+
replay_file: null
|
| 155 |
+
fsdp_config:
|
| 156 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 157 |
+
wrap_policy:
|
| 158 |
+
min_num_params: 0
|
| 159 |
+
param_offload: false
|
| 160 |
+
optimizer_offload: false
|
| 161 |
+
offload_policy: false
|
| 162 |
+
reshard_after_forward: true
|
| 163 |
+
fsdp_size: -1
|
| 164 |
+
forward_prefetch: false
|
| 165 |
+
model_dtype: fp32
|
| 166 |
+
use_orig_params: false
|
| 167 |
+
seed: 42
|
| 168 |
+
full_determinism: false
|
| 169 |
+
ulysses_sequence_parallel_size: 1
|
| 170 |
+
entropy_from_logits_with_chunking: false
|
| 171 |
+
use_torch_compile: true
|
| 172 |
+
entropy_checkpointing: false
|
| 173 |
+
forward_only: true
|
| 174 |
+
strategy: fsdp
|
| 175 |
+
dtype: bfloat16
|
| 176 |
+
_target_: verl.workers.config.FSDPActorConfig
|
| 177 |
+
ulysses_sequence_parallel_size: ${oc.select:actor_rollout_ref.actor.ulysses_sequence_parallel_size,1}
|
| 178 |
+
entropy_from_logits_with_chunking: false
|
| 179 |
+
entropy_checkpointing: false
|
| 180 |
+
rollout:
|
| 181 |
+
_target_: verl.workers.config.RolloutConfig
|
| 182 |
+
name: vllm
|
| 183 |
+
mode: async
|
| 184 |
+
temperature: 1.0
|
| 185 |
+
top_k: -1
|
| 186 |
+
top_p: 1
|
| 187 |
+
prompt_length: ${oc.select:data.max_prompt_length,512}
|
| 188 |
+
response_length: ${oc.select:data.max_response_length,512}
|
| 189 |
+
dtype: bfloat16
|
| 190 |
+
gpu_memory_utilization: 0.6
|
| 191 |
+
ignore_eos: false
|
| 192 |
+
enforce_eager: false
|
| 193 |
+
cudagraph_capture_sizes: null
|
| 194 |
+
free_cache_engine: true
|
| 195 |
+
tensor_model_parallel_size: 2
|
| 196 |
+
data_parallel_size: 1
|
| 197 |
+
expert_parallel_size: 1
|
| 198 |
+
pipeline_model_parallel_size: 1
|
| 199 |
+
max_num_batched_tokens: 8192
|
| 200 |
+
max_model_len: null
|
| 201 |
+
max_num_seqs: 1024
|
| 202 |
+
enable_chunked_prefill: true
|
| 203 |
+
enable_prefix_caching: true
|
| 204 |
+
load_format: safetensors
|
| 205 |
+
log_prob_micro_batch_size: null
|
| 206 |
+
log_prob_micro_batch_size_per_gpu: 32
|
| 207 |
+
log_prob_use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
|
| 208 |
+
log_prob_max_token_len_per_gpu: ${oc.select:actor_rollout_ref.actor.ppo_max_token_len_per_gpu,16384}
|
| 209 |
+
disable_log_stats: true
|
| 210 |
+
do_sample: true
|
| 211 |
+
'n': 5
|
| 212 |
+
over_sample_rate: 0
|
| 213 |
+
multi_stage_wake_up: false
|
| 214 |
+
engine_kwargs:
|
| 215 |
+
vllm: {}
|
| 216 |
+
sglang: {}
|
| 217 |
+
val_kwargs:
|
| 218 |
+
_target_: verl.workers.config.SamplingConfig
|
| 219 |
+
top_k: -1
|
| 220 |
+
top_p: 1.0
|
| 221 |
+
temperature: 0
|
| 222 |
+
'n': 1
|
| 223 |
+
do_sample: false
|
| 224 |
+
multi_turn:
|
| 225 |
+
_target_: verl.workers.config.MultiTurnConfig
|
| 226 |
+
enable: false
|
| 227 |
+
max_assistant_turns: null
|
| 228 |
+
tool_config_path: null
|
| 229 |
+
max_user_turns: null
|
| 230 |
+
max_parallel_calls: 1
|
| 231 |
+
max_tool_response_length: 256
|
| 232 |
+
tool_response_truncate_side: middle
|
| 233 |
+
interaction_config_path: null
|
| 234 |
+
use_inference_chat_template: false
|
| 235 |
+
tokenization_sanity_check_mode: strict
|
| 236 |
+
format: hermes
|
| 237 |
+
num_repeat_rollouts: null
|
| 238 |
+
calculate_log_probs: false
|
| 239 |
+
agent:
|
| 240 |
+
_target_: verl.workers.config.AgentLoopConfig
|
| 241 |
+
num_workers: 8
|
| 242 |
+
default_agent_loop: single_turn_agent
|
| 243 |
+
agent_loop_config_path: null
|
| 244 |
+
custom_async_server:
|
| 245 |
+
_target_: verl.workers.config.CustomAsyncServerConfig
|
| 246 |
+
path: null
|
| 247 |
+
name: null
|
| 248 |
+
update_weights_bucket_megabytes: 512
|
| 249 |
+
trace:
|
| 250 |
+
_target_: verl.workers.config.TraceConfig
|
| 251 |
+
backend: null
|
| 252 |
+
token2text: false
|
| 253 |
+
max_samples_per_step_per_worker: null
|
| 254 |
+
skip_rollout: false
|
| 255 |
+
skip_dump_dir: /tmp/rollout_dump
|
| 256 |
+
skip_tokenizer_init: true
|
| 257 |
+
enable_rollout_routing_replay: false
|
| 258 |
+
profiler:
|
| 259 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 260 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 261 |
+
enable: ${oc.select:actor_rollout_ref.actor.profiler.enable,false}
|
| 262 |
+
all_ranks: ${oc.select:actor_rollout_ref.actor.profiler.all_ranks,false}
|
| 263 |
+
ranks: ${oc.select:actor_rollout_ref.actor.profiler.ranks,[]}
|
| 264 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 265 |
+
tool_config: ${oc.select:actor_rollout_ref.actor.profiler.tool_config,null}
|
| 266 |
+
prometheus:
|
| 267 |
+
_target_: verl.workers.config.PrometheusConfig
|
| 268 |
+
enable: false
|
| 269 |
+
port: 9090
|
| 270 |
+
file: /tmp/ray/session_latest/metrics/prometheus/prometheus.yml
|
| 271 |
+
served_model_name: ${oc.select:actor_rollout_ref.model.path,null}
|
| 272 |
+
layered_summon: true
|
| 273 |
+
model:
|
| 274 |
+
_target_: verl.workers.config.HFModelConfig
|
| 275 |
+
path: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 276 |
+
hf_config_path: null
|
| 277 |
+
tokenizer_path: null
|
| 278 |
+
use_shm: false
|
| 279 |
+
trust_remote_code: false
|
| 280 |
+
custom_chat_template: null
|
| 281 |
+
external_lib: null
|
| 282 |
+
override_config: {}
|
| 283 |
+
enable_gradient_checkpointing: true
|
| 284 |
+
enable_activation_offload: false
|
| 285 |
+
use_remove_padding: true
|
| 286 |
+
lora_rank: 0
|
| 287 |
+
lora_alpha: 16
|
| 288 |
+
target_modules: all-linear
|
| 289 |
+
exclude_modules: null
|
| 290 |
+
lora_adapter_path: null
|
| 291 |
+
use_liger: false
|
| 292 |
+
use_fused_kernels: false
|
| 293 |
+
fused_kernel_options:
|
| 294 |
+
impl_backend: torch
|
| 295 |
+
hybrid_engine: true
|
| 296 |
+
nccl_timeout: 600
|
| 297 |
+
data:
|
| 298 |
+
tokenizer: null
|
| 299 |
+
use_shm: false
|
| 300 |
+
train_files: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/train.parquet
|
| 301 |
+
val_files: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/test.parquet
|
| 302 |
+
train_max_samples: -1
|
| 303 |
+
val_max_samples: -1
|
| 304 |
+
prompt_key: prompt
|
| 305 |
+
reward_fn_key: data_source
|
| 306 |
+
max_prompt_length: 512
|
| 307 |
+
max_response_length: 1024
|
| 308 |
+
train_batch_size: 1024
|
| 309 |
+
val_batch_size: null
|
| 310 |
+
tool_config_path: ${oc.select:actor_rollout_ref.rollout.multi_turn.tool_config_path,
|
| 311 |
+
null}
|
| 312 |
+
return_raw_input_ids: false
|
| 313 |
+
return_raw_chat: true
|
| 314 |
+
return_full_prompt: false
|
| 315 |
+
shuffle: false
|
| 316 |
+
seed: null
|
| 317 |
+
dataloader_num_workers: 8
|
| 318 |
+
image_patch_size: 14
|
| 319 |
+
validation_shuffle: false
|
| 320 |
+
filter_overlong_prompts: true
|
| 321 |
+
filter_overlong_prompts_workers: 1
|
| 322 |
+
truncation: error
|
| 323 |
+
image_key: images
|
| 324 |
+
video_key: videos
|
| 325 |
+
trust_remote_code: false
|
| 326 |
+
custom_cls:
|
| 327 |
+
path: null
|
| 328 |
+
name: null
|
| 329 |
+
return_multi_modal_inputs: true
|
| 330 |
+
sampler:
|
| 331 |
+
class_path: null
|
| 332 |
+
class_name: null
|
| 333 |
+
datagen:
|
| 334 |
+
path: null
|
| 335 |
+
name: null
|
| 336 |
+
apply_chat_template_kwargs: {}
|
| 337 |
+
reward_manager:
|
| 338 |
+
_target_: verl.trainer.config.config.RewardManagerConfig
|
| 339 |
+
source: register
|
| 340 |
+
name: ${oc.select:reward_model.reward_manager,naive}
|
| 341 |
+
module:
|
| 342 |
+
_target_: verl.trainer.config.config.ModuleConfig
|
| 343 |
+
path: null
|
| 344 |
+
name: custom_reward_manager
|
| 345 |
+
critic:
|
| 346 |
+
optim:
|
| 347 |
+
_target_: verl.workers.config.FSDPOptimizerConfig
|
| 348 |
+
optimizer: AdamW
|
| 349 |
+
optimizer_impl: torch.optim
|
| 350 |
+
lr: 1.0e-05
|
| 351 |
+
lr_warmup_steps_ratio: 0.0
|
| 352 |
+
total_training_steps: -1
|
| 353 |
+
weight_decay: 0.01
|
| 354 |
+
lr_warmup_steps: -1
|
| 355 |
+
betas:
|
| 356 |
+
- 0.9
|
| 357 |
+
- 0.999
|
| 358 |
+
clip_grad: 1.0
|
| 359 |
+
min_lr_ratio: 0.0
|
| 360 |
+
num_cycles: 0.5
|
| 361 |
+
lr_scheduler_type: constant
|
| 362 |
+
warmup_style: null
|
| 363 |
+
override_optimizer_config: null
|
| 364 |
+
model:
|
| 365 |
+
fsdp_config:
|
| 366 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 367 |
+
wrap_policy:
|
| 368 |
+
min_num_params: 0
|
| 369 |
+
param_offload: false
|
| 370 |
+
optimizer_offload: false
|
| 371 |
+
offload_policy: false
|
| 372 |
+
reshard_after_forward: true
|
| 373 |
+
fsdp_size: -1
|
| 374 |
+
forward_prefetch: false
|
| 375 |
+
model_dtype: fp32
|
| 376 |
+
use_orig_params: false
|
| 377 |
+
seed: 42
|
| 378 |
+
full_determinism: false
|
| 379 |
+
ulysses_sequence_parallel_size: 1
|
| 380 |
+
entropy_from_logits_with_chunking: false
|
| 381 |
+
use_torch_compile: true
|
| 382 |
+
entropy_checkpointing: false
|
| 383 |
+
forward_only: false
|
| 384 |
+
strategy: fsdp
|
| 385 |
+
dtype: bfloat16
|
| 386 |
+
path: ~/models/deepseek-llm-7b-chat
|
| 387 |
+
tokenizer_path: ${oc.select:actor_rollout_ref.model.path,"~/models/deepseek-llm-7b-chat"}
|
| 388 |
+
override_config: {}
|
| 389 |
+
external_lib: ${oc.select:actor_rollout_ref.model.external_lib,null}
|
| 390 |
+
trust_remote_code: ${oc.select:actor_rollout_ref.model.trust_remote_code,false}
|
| 391 |
+
_target_: verl.workers.config.FSDPCriticModelCfg
|
| 392 |
+
use_shm: false
|
| 393 |
+
enable_gradient_checkpointing: true
|
| 394 |
+
enable_activation_offload: false
|
| 395 |
+
use_remove_padding: false
|
| 396 |
+
lora_rank: 0
|
| 397 |
+
lora_alpha: 16
|
| 398 |
+
target_modules: all-linear
|
| 399 |
+
_target_: verl.workers.config.FSDPCriticConfig
|
| 400 |
+
rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
|
| 401 |
+
strategy: fsdp
|
| 402 |
+
enable: null
|
| 403 |
+
ppo_mini_batch_size: ${oc.select:actor_rollout_ref.actor.ppo_mini_batch_size,256}
|
| 404 |
+
ppo_micro_batch_size: null
|
| 405 |
+
ppo_micro_batch_size_per_gpu: ${oc.select:.ppo_micro_batch_size,null}
|
| 406 |
+
use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
|
| 407 |
+
ppo_max_token_len_per_gpu: 32768
|
| 408 |
+
forward_max_token_len_per_gpu: ${.ppo_max_token_len_per_gpu}
|
| 409 |
+
ppo_epochs: ${oc.select:actor_rollout_ref.actor.ppo_epochs,1}
|
| 410 |
+
shuffle: ${oc.select:actor_rollout_ref.actor.shuffle,false}
|
| 411 |
+
cliprange_value: 0.5
|
| 412 |
+
loss_agg_mode: ${oc.select:actor_rollout_ref.actor.loss_agg_mode,token-mean}
|
| 413 |
+
checkpoint:
|
| 414 |
+
_target_: verl.trainer.config.CheckpointConfig
|
| 415 |
+
save_contents:
|
| 416 |
+
- model
|
| 417 |
+
- optimizer
|
| 418 |
+
- extra
|
| 419 |
+
load_contents: ${.save_contents}
|
| 420 |
+
async_save: false
|
| 421 |
+
profiler:
|
| 422 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 423 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 424 |
+
enable: false
|
| 425 |
+
all_ranks: false
|
| 426 |
+
ranks: []
|
| 427 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 428 |
+
tool_config:
|
| 429 |
+
nsys:
|
| 430 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 431 |
+
discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
|
| 432 |
+
npu:
|
| 433 |
+
_target_: verl.utils.profiler.config.NPUToolConfig
|
| 434 |
+
contents: []
|
| 435 |
+
level: level1
|
| 436 |
+
analysis: true
|
| 437 |
+
discrete: false
|
| 438 |
+
torch:
|
| 439 |
+
_target_: verl.utils.profiler.config.TorchProfilerToolConfig
|
| 440 |
+
step_start: 0
|
| 441 |
+
step_end: null
|
| 442 |
+
torch_memory:
|
| 443 |
+
_target_: verl.utils.profiler.config.TorchMemoryToolConfig
|
| 444 |
+
trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
|
| 445 |
+
stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
|
| 446 |
+
forward_micro_batch_size: ${oc.select:.ppo_micro_batch_size,null}
|
| 447 |
+
forward_micro_batch_size_per_gpu: ${oc.select:.ppo_micro_batch_size_per_gpu,null}
|
| 448 |
+
ulysses_sequence_parallel_size: 1
|
| 449 |
+
grad_clip: 1.0
|
| 450 |
+
reward_model:
|
| 451 |
+
enable: true
|
| 452 |
+
enable_resource_pool: false
|
| 453 |
+
n_gpus_per_node: 0
|
| 454 |
+
nnodes: 0
|
| 455 |
+
strategy: fsdp
|
| 456 |
+
model:
|
| 457 |
+
input_tokenizer: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 458 |
+
path: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/reward_model/best_model.pt
|
| 459 |
+
external_lib: ${actor_rollout_ref.model.external_lib}
|
| 460 |
+
trust_remote_code: false
|
| 461 |
+
override_config: {}
|
| 462 |
+
use_shm: false
|
| 463 |
+
use_remove_padding: false
|
| 464 |
+
use_fused_kernels: ${actor_rollout_ref.model.use_fused_kernels}
|
| 465 |
+
fsdp_config:
|
| 466 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 467 |
+
wrap_policy:
|
| 468 |
+
min_num_params: 0
|
| 469 |
+
param_offload: false
|
| 470 |
+
reshard_after_forward: true
|
| 471 |
+
fsdp_size: -1
|
| 472 |
+
forward_prefetch: false
|
| 473 |
+
micro_batch_size: null
|
| 474 |
+
micro_batch_size_per_gpu: 32
|
| 475 |
+
max_length: null
|
| 476 |
+
use_dynamic_bsz: ${critic.use_dynamic_bsz}
|
| 477 |
+
forward_max_token_len_per_gpu: ${critic.forward_max_token_len_per_gpu}
|
| 478 |
+
reward_manager: naive
|
| 479 |
+
launch_reward_fn_async: false
|
| 480 |
+
sandbox_fusion:
|
| 481 |
+
url: null
|
| 482 |
+
max_concurrent: 64
|
| 483 |
+
memory_limit_mb: 1024
|
| 484 |
+
profiler:
|
| 485 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 486 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 487 |
+
enable: false
|
| 488 |
+
all_ranks: false
|
| 489 |
+
ranks: []
|
| 490 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 491 |
+
tool_config: ${oc.select:actor_rollout_ref.actor.profiler.tool_config,null}
|
| 492 |
+
ulysses_sequence_parallel_size: 1
|
| 493 |
+
use_reward_loop: true
|
| 494 |
+
rollout:
|
| 495 |
+
_target_: verl.workers.config.RolloutConfig
|
| 496 |
+
name: ???
|
| 497 |
+
dtype: bfloat16
|
| 498 |
+
gpu_memory_utilization: 0.5
|
| 499 |
+
enforce_eager: true
|
| 500 |
+
cudagraph_capture_sizes: null
|
| 501 |
+
free_cache_engine: true
|
| 502 |
+
data_parallel_size: 1
|
| 503 |
+
expert_parallel_size: 1
|
| 504 |
+
tensor_model_parallel_size: 2
|
| 505 |
+
max_num_batched_tokens: 8192
|
| 506 |
+
max_model_len: null
|
| 507 |
+
max_num_seqs: 1024
|
| 508 |
+
load_format: auto
|
| 509 |
+
engine_kwargs: {}
|
| 510 |
+
limit_images: null
|
| 511 |
+
enable_chunked_prefill: true
|
| 512 |
+
enable_prefix_caching: true
|
| 513 |
+
disable_log_stats: true
|
| 514 |
+
skip_tokenizer_init: true
|
| 515 |
+
prompt_length: 512
|
| 516 |
+
response_length: 512
|
| 517 |
+
algorithm:
|
| 518 |
+
rollout_correction:
|
| 519 |
+
rollout_is: null
|
| 520 |
+
rollout_is_threshold: 2.0
|
| 521 |
+
rollout_rs: null
|
| 522 |
+
rollout_rs_threshold: null
|
| 523 |
+
rollout_rs_threshold_lower: null
|
| 524 |
+
rollout_token_veto_threshold: null
|
| 525 |
+
bypass_mode: false
|
| 526 |
+
use_policy_gradient: false
|
| 527 |
+
rollout_is_batch_normalize: false
|
| 528 |
+
_target_: verl.trainer.config.AlgoConfig
|
| 529 |
+
gamma: 1.0
|
| 530 |
+
lam: 1.0
|
| 531 |
+
adv_estimator: grpo
|
| 532 |
+
norm_adv_by_std_in_grpo: true
|
| 533 |
+
use_kl_in_reward: false
|
| 534 |
+
kl_penalty: kl
|
| 535 |
+
kl_ctrl:
|
| 536 |
+
_target_: verl.trainer.config.KLControlConfig
|
| 537 |
+
type: fixed
|
| 538 |
+
kl_coef: 0.001
|
| 539 |
+
horizon: 10000
|
| 540 |
+
target_kl: 0.1
|
| 541 |
+
use_pf_ppo: false
|
| 542 |
+
pf_ppo:
|
| 543 |
+
reweight_method: pow
|
| 544 |
+
weight_pow: 2.0
|
| 545 |
+
custom_reward_function:
|
| 546 |
+
path: null
|
| 547 |
+
name: compute_score
|
| 548 |
+
trainer:
|
| 549 |
+
balance_batch: true
|
| 550 |
+
total_epochs: 15
|
| 551 |
+
total_training_steps: null
|
| 552 |
+
project_name: verl_grpo_gsm8k
|
| 553 |
+
experiment_name: qwen3_4b_gsm8k_grpo
|
| 554 |
+
logger:
|
| 555 |
+
- console
|
| 556 |
+
- wandb
|
| 557 |
+
log_val_generations: 0
|
| 558 |
+
rollout_data_dir: null
|
| 559 |
+
validation_data_dir: null
|
| 560 |
+
nnodes: 1
|
| 561 |
+
n_gpus_per_node: 8
|
| 562 |
+
save_freq: 20
|
| 563 |
+
esi_redundant_time: 0
|
| 564 |
+
resume_mode: disable
|
| 565 |
+
resume_from_path: null
|
| 566 |
+
val_before_train: true
|
| 567 |
+
val_only: false
|
| 568 |
+
test_freq: 5
|
| 569 |
+
critic_warmup: 0
|
| 570 |
+
default_hdfs_dir: null
|
| 571 |
+
del_local_ckpt_after_load: false
|
| 572 |
+
default_local_dir: checkpoints/${trainer.project_name}/${trainer.experiment_name}
|
| 573 |
+
max_actor_ckpt_to_keep: null
|
| 574 |
+
max_critic_ckpt_to_keep: null
|
| 575 |
+
ray_wait_register_center_timeout: 300
|
| 576 |
+
device: cuda
|
| 577 |
+
use_legacy_worker_impl: auto
|
| 578 |
+
global_profiler:
|
| 579 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 580 |
+
tool: null
|
| 581 |
+
steps: null
|
| 582 |
+
profile_continuous_steps: false
|
| 583 |
+
save_path: outputs/profile
|
| 584 |
+
global_tool_config:
|
| 585 |
+
nsys:
|
| 586 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 587 |
+
discrete: false
|
| 588 |
+
controller_nsight_options:
|
| 589 |
+
trace: cuda,nvtx,cublas,ucx
|
| 590 |
+
cuda-memory-usage: 'true'
|
| 591 |
+
cuda-graph-trace: graph
|
| 592 |
+
worker_nsight_options:
|
| 593 |
+
trace: cuda,nvtx,cublas,ucx
|
| 594 |
+
cuda-memory-usage: 'true'
|
| 595 |
+
cuda-graph-trace: graph
|
| 596 |
+
capture-range: cudaProfilerApi
|
| 597 |
+
capture-range-end: null
|
| 598 |
+
kill: none
|
| 599 |
+
torch_memory:
|
| 600 |
+
trace_alloc_max_entries: 100000
|
| 601 |
+
stack_depth: 32
|
| 602 |
+
context: all
|
| 603 |
+
stacks: all
|
| 604 |
+
kw_args: {}
|
| 605 |
+
transfer_queue:
|
| 606 |
+
enable: false
|
| 607 |
+
ray_kwargs:
|
| 608 |
+
ray_init:
|
| 609 |
+
num_cpus: null
|
| 610 |
+
timeline_json_file: null
|
examples/grpo_trainer/outputs/2026-01-24/22-59-57/.hydra/overrides.yaml
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
- algorithm.adv_estimator=grpo
|
| 2 |
+
- data.train_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/train.parquet
|
| 3 |
+
- data.val_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/test.parquet
|
| 4 |
+
- data.train_batch_size=1024
|
| 5 |
+
- data.max_prompt_length=512
|
| 6 |
+
- data.max_response_length=1024
|
| 7 |
+
- data.filter_overlong_prompts=True
|
| 8 |
+
- data.truncation=error
|
| 9 |
+
- data.shuffle=False
|
| 10 |
+
- actor_rollout_ref.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 11 |
+
- actor_rollout_ref.actor.optim.lr=1e-6
|
| 12 |
+
- actor_rollout_ref.model.use_remove_padding=True
|
| 13 |
+
- actor_rollout_ref.actor.ppo_mini_batch_size=256
|
| 14 |
+
- actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=32
|
| 15 |
+
- actor_rollout_ref.actor.use_kl_loss=True
|
| 16 |
+
- actor_rollout_ref.actor.kl_loss_coef=0.001
|
| 17 |
+
- actor_rollout_ref.actor.kl_loss_type=low_var_kl
|
| 18 |
+
- actor_rollout_ref.actor.entropy_coeff=0
|
| 19 |
+
- actor_rollout_ref.model.enable_gradient_checkpointing=True
|
| 20 |
+
- actor_rollout_ref.actor.fsdp_config.param_offload=True
|
| 21 |
+
- actor_rollout_ref.actor.fsdp_config.optimizer_offload=False
|
| 22 |
+
- actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32
|
| 23 |
+
- actor_rollout_ref.rollout.tensor_model_parallel_size=2
|
| 24 |
+
- actor_rollout_ref.rollout.name=vllm
|
| 25 |
+
- actor_rollout_ref.rollout.gpu_memory_utilization=0.6
|
| 26 |
+
- actor_rollout_ref.rollout.n=5
|
| 27 |
+
- actor_rollout_ref.rollout.load_format=safetensors
|
| 28 |
+
- actor_rollout_ref.rollout.layered_summon=True
|
| 29 |
+
- actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32
|
| 30 |
+
- actor_rollout_ref.ref.fsdp_config.param_offload=False
|
| 31 |
+
- algorithm.use_kl_in_reward=False
|
| 32 |
+
- reward_model.enable=True
|
| 33 |
+
- reward_model.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/reward_model/best_model.pt
|
| 34 |
+
- reward_model.model.input_tokenizer=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 35 |
+
- reward_model.micro_batch_size_per_gpu=32
|
| 36 |
+
- trainer.critic_warmup=0
|
| 37 |
+
- trainer.logger=["console","wandb"]
|
| 38 |
+
- trainer.project_name=verl_grpo_gsm8k
|
| 39 |
+
- trainer.experiment_name=qwen3_4b_gsm8k_grpo
|
| 40 |
+
- trainer.n_gpus_per_node=8
|
| 41 |
+
- trainer.nnodes=1
|
| 42 |
+
- trainer.save_freq=20
|
| 43 |
+
- trainer.test_freq=5
|
| 44 |
+
- trainer.total_epochs=15
|
| 45 |
+
- trainer.resume_mode=disable
|
examples/grpo_trainer/outputs/2026-01-24/23-39-12/.hydra/hydra.yaml
ADDED
|
@@ -0,0 +1,213 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
hydra:
|
| 2 |
+
run:
|
| 3 |
+
dir: outputs/${now:%Y-%m-%d}/${now:%H-%M-%S}
|
| 4 |
+
sweep:
|
| 5 |
+
dir: multirun/${now:%Y-%m-%d}/${now:%H-%M-%S}
|
| 6 |
+
subdir: ${hydra.job.num}
|
| 7 |
+
launcher:
|
| 8 |
+
_target_: hydra._internal.core_plugins.basic_launcher.BasicLauncher
|
| 9 |
+
sweeper:
|
| 10 |
+
_target_: hydra._internal.core_plugins.basic_sweeper.BasicSweeper
|
| 11 |
+
max_batch_size: null
|
| 12 |
+
params: null
|
| 13 |
+
help:
|
| 14 |
+
app_name: ${hydra.job.name}
|
| 15 |
+
header: '${hydra.help.app_name} is powered by Hydra.
|
| 16 |
+
|
| 17 |
+
'
|
| 18 |
+
footer: 'Powered by Hydra (https://hydra.cc)
|
| 19 |
+
|
| 20 |
+
Use --hydra-help to view Hydra specific help
|
| 21 |
+
|
| 22 |
+
'
|
| 23 |
+
template: '${hydra.help.header}
|
| 24 |
+
|
| 25 |
+
== Configuration groups ==
|
| 26 |
+
|
| 27 |
+
Compose your configuration from those groups (group=option)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
$APP_CONFIG_GROUPS
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
== Config ==
|
| 34 |
+
|
| 35 |
+
Override anything in the config (foo.bar=value)
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
$CONFIG
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
${hydra.help.footer}
|
| 42 |
+
|
| 43 |
+
'
|
| 44 |
+
hydra_help:
|
| 45 |
+
template: 'Hydra (${hydra.runtime.version})
|
| 46 |
+
|
| 47 |
+
See https://hydra.cc for more info.
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
== Flags ==
|
| 51 |
+
|
| 52 |
+
$FLAGS_HELP
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
== Configuration groups ==
|
| 56 |
+
|
| 57 |
+
Compose your configuration from those groups (For example, append hydra/job_logging=disabled
|
| 58 |
+
to command line)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
$HYDRA_CONFIG_GROUPS
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
Use ''--cfg hydra'' to Show the Hydra config.
|
| 65 |
+
|
| 66 |
+
'
|
| 67 |
+
hydra_help: ???
|
| 68 |
+
hydra_logging:
|
| 69 |
+
version: 1
|
| 70 |
+
formatters:
|
| 71 |
+
simple:
|
| 72 |
+
format: '[%(asctime)s][HYDRA] %(message)s'
|
| 73 |
+
handlers:
|
| 74 |
+
console:
|
| 75 |
+
class: logging.StreamHandler
|
| 76 |
+
formatter: simple
|
| 77 |
+
stream: ext://sys.stdout
|
| 78 |
+
root:
|
| 79 |
+
level: INFO
|
| 80 |
+
handlers:
|
| 81 |
+
- console
|
| 82 |
+
loggers:
|
| 83 |
+
logging_example:
|
| 84 |
+
level: DEBUG
|
| 85 |
+
disable_existing_loggers: false
|
| 86 |
+
job_logging:
|
| 87 |
+
version: 1
|
| 88 |
+
formatters:
|
| 89 |
+
simple:
|
| 90 |
+
format: '[%(asctime)s][%(name)s][%(levelname)s] - %(message)s'
|
| 91 |
+
handlers:
|
| 92 |
+
console:
|
| 93 |
+
class: logging.StreamHandler
|
| 94 |
+
formatter: simple
|
| 95 |
+
stream: ext://sys.stdout
|
| 96 |
+
file:
|
| 97 |
+
class: logging.FileHandler
|
| 98 |
+
formatter: simple
|
| 99 |
+
filename: ${hydra.runtime.output_dir}/${hydra.job.name}.log
|
| 100 |
+
root:
|
| 101 |
+
level: INFO
|
| 102 |
+
handlers:
|
| 103 |
+
- console
|
| 104 |
+
- file
|
| 105 |
+
disable_existing_loggers: false
|
| 106 |
+
env: {}
|
| 107 |
+
mode: RUN
|
| 108 |
+
searchpath: []
|
| 109 |
+
callbacks: {}
|
| 110 |
+
output_subdir: .hydra
|
| 111 |
+
overrides:
|
| 112 |
+
hydra:
|
| 113 |
+
- hydra.mode=RUN
|
| 114 |
+
task:
|
| 115 |
+
- algorithm.adv_estimator=grpo
|
| 116 |
+
- data.train_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/train.parquet
|
| 117 |
+
- data.val_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/test.parquet
|
| 118 |
+
- data.train_batch_size=1024
|
| 119 |
+
- data.max_prompt_length=512
|
| 120 |
+
- data.max_response_length=1024
|
| 121 |
+
- data.filter_overlong_prompts=True
|
| 122 |
+
- data.truncation=error
|
| 123 |
+
- data.shuffle=False
|
| 124 |
+
- actor_rollout_ref.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 125 |
+
- actor_rollout_ref.actor.optim.lr=1e-6
|
| 126 |
+
- actor_rollout_ref.model.use_remove_padding=True
|
| 127 |
+
- actor_rollout_ref.actor.ppo_mini_batch_size=256
|
| 128 |
+
- actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=32
|
| 129 |
+
- actor_rollout_ref.actor.use_kl_loss=True
|
| 130 |
+
- actor_rollout_ref.actor.kl_loss_coef=0.001
|
| 131 |
+
- actor_rollout_ref.actor.kl_loss_type=low_var_kl
|
| 132 |
+
- actor_rollout_ref.actor.entropy_coeff=0
|
| 133 |
+
- actor_rollout_ref.model.enable_gradient_checkpointing=True
|
| 134 |
+
- actor_rollout_ref.actor.fsdp_config.param_offload=True
|
| 135 |
+
- actor_rollout_ref.actor.fsdp_config.optimizer_offload=False
|
| 136 |
+
- actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32
|
| 137 |
+
- actor_rollout_ref.rollout.tensor_model_parallel_size=2
|
| 138 |
+
- actor_rollout_ref.rollout.name=vllm
|
| 139 |
+
- actor_rollout_ref.rollout.gpu_memory_utilization=0.6
|
| 140 |
+
- actor_rollout_ref.rollout.n=5
|
| 141 |
+
- actor_rollout_ref.rollout.load_format=safetensors
|
| 142 |
+
- actor_rollout_ref.rollout.layered_summon=True
|
| 143 |
+
- actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32
|
| 144 |
+
- actor_rollout_ref.ref.fsdp_config.param_offload=False
|
| 145 |
+
- algorithm.use_kl_in_reward=False
|
| 146 |
+
- reward_model.enable=True
|
| 147 |
+
- reward_model.enable=True
|
| 148 |
+
- reward_model.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/reward_model/best_model.pt
|
| 149 |
+
- reward_model.model.input_tokenizer=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 150 |
+
- reward_model.micro_batch_size_per_gpu=32
|
| 151 |
+
- trainer.critic_warmup=0
|
| 152 |
+
- trainer.logger=["console","wandb"]
|
| 153 |
+
- trainer.project_name=verl_grpo_gsm8k
|
| 154 |
+
- trainer.experiment_name=qwen3_4b_gsm8k_grpo
|
| 155 |
+
- trainer.n_gpus_per_node=8
|
| 156 |
+
- trainer.nnodes=1
|
| 157 |
+
- trainer.save_freq=20
|
| 158 |
+
- trainer.test_freq=5
|
| 159 |
+
- trainer.total_epochs=15
|
| 160 |
+
- trainer.resume_mode=disable
|
| 161 |
+
job:
|
| 162 |
+
name: main_ppo
|
| 163 |
+
chdir: null
|
| 164 |
+
override_dirname: actor_rollout_ref.actor.entropy_coeff=0,actor_rollout_ref.actor.fsdp_config.optimizer_offload=False,actor_rollout_ref.actor.fsdp_config.param_offload=True,actor_rollout_ref.actor.kl_loss_coef=0.001,actor_rollout_ref.actor.kl_loss_type=low_var_kl,actor_rollout_ref.actor.optim.lr=1e-6,actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=32,actor_rollout_ref.actor.ppo_mini_batch_size=256,actor_rollout_ref.actor.use_kl_loss=True,actor_rollout_ref.model.enable_gradient_checkpointing=True,actor_rollout_ref.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507,actor_rollout_ref.model.use_remove_padding=True,actor_rollout_ref.ref.fsdp_config.param_offload=False,actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32,actor_rollout_ref.rollout.gpu_memory_utilization=0.6,actor_rollout_ref.rollout.layered_summon=True,actor_rollout_ref.rollout.load_format=safetensors,actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32,actor_rollout_ref.rollout.n=5,actor_rollout_ref.rollout.name=vllm,actor_rollout_ref.rollout.tensor_model_parallel_size=2,algorithm.adv_estimator=grpo,algorithm.use_kl_in_reward=False,data.filter_overlong_prompts=True,data.max_prompt_length=512,data.max_response_length=1024,data.shuffle=False,data.train_batch_size=1024,data.train_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/train.parquet,data.truncation=error,data.val_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/test.parquet,reward_model.enable=True,reward_model.enable=True,reward_model.micro_batch_size_per_gpu=32,reward_model.model.input_tokenizer=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507,reward_model.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/reward_model/best_model.pt,trainer.critic_warmup=0,trainer.experiment_name=qwen3_4b_gsm8k_grpo,trainer.logger=["console","wandb"],trainer.n_gpus_per_node=8,trainer.nnodes=1,trainer.project_name=verl_grpo_gsm8k,trainer.resume_mode=disable,trainer.save_freq=20,trainer.test_freq=5,trainer.total_epochs=15
|
| 165 |
+
id: ???
|
| 166 |
+
num: ???
|
| 167 |
+
config_name: ppo_trainer
|
| 168 |
+
env_set: {}
|
| 169 |
+
env_copy: []
|
| 170 |
+
config:
|
| 171 |
+
override_dirname:
|
| 172 |
+
kv_sep: '='
|
| 173 |
+
item_sep: ','
|
| 174 |
+
exclude_keys: []
|
| 175 |
+
runtime:
|
| 176 |
+
version: 1.3.2
|
| 177 |
+
version_base: '1.3'
|
| 178 |
+
cwd: /mnt/tidal-alsh01/usr/zhangruiqi1/my/verl/examples/grpo_trainer
|
| 179 |
+
config_sources:
|
| 180 |
+
- path: hydra.conf
|
| 181 |
+
schema: pkg
|
| 182 |
+
provider: hydra
|
| 183 |
+
- path: /mnt/tidal-alsh01/usr/zhangruiqi1/my/verl/verl/trainer/config
|
| 184 |
+
schema: file
|
| 185 |
+
provider: main
|
| 186 |
+
- path: ''
|
| 187 |
+
schema: structured
|
| 188 |
+
provider: schema
|
| 189 |
+
output_dir: /mnt/tidal-alsh01/usr/zhangruiqi1/my/verl/examples/grpo_trainer/outputs/2026-01-24/23-39-12
|
| 190 |
+
choices:
|
| 191 |
+
algorithm@algorithm.rollout_correction: rollout_correction
|
| 192 |
+
reward_model: dp_reward_loop
|
| 193 |
+
critic: dp_critic
|
| 194 |
+
critic/../engine@critic.model.fsdp_config: fsdp
|
| 195 |
+
critic/../optim@critic.optim: fsdp
|
| 196 |
+
model@actor_rollout_ref.model: hf_model
|
| 197 |
+
rollout@actor_rollout_ref.rollout: rollout
|
| 198 |
+
ref@actor_rollout_ref.ref: dp_ref
|
| 199 |
+
ref/../engine@actor_rollout_ref.ref.fsdp_config: fsdp
|
| 200 |
+
data: legacy_data
|
| 201 |
+
actor@actor_rollout_ref.actor: dp_actor
|
| 202 |
+
actor/../engine@actor_rollout_ref.actor.fsdp_config: fsdp
|
| 203 |
+
actor/../optim@actor_rollout_ref.actor.optim: fsdp
|
| 204 |
+
hydra/env: default
|
| 205 |
+
hydra/callbacks: null
|
| 206 |
+
hydra/job_logging: default
|
| 207 |
+
hydra/hydra_logging: default
|
| 208 |
+
hydra/hydra_help: default
|
| 209 |
+
hydra/help: default
|
| 210 |
+
hydra/sweeper: basic
|
| 211 |
+
hydra/launcher: basic
|
| 212 |
+
hydra/output: default
|
| 213 |
+
verbose: false
|
examples/grpo_trainer/outputs/2026-01-24/23-39-12/main_ppo.log
ADDED
|
File without changes
|
examples/grpo_trainer/outputs/2026-01-24/23-57-09/main_ppo.log
ADDED
|
File without changes
|
examples/grpo_trainer/outputs/2026-01-24/23-59-39/main_ppo.log
ADDED
|
File without changes
|
examples/grpo_trainer/outputs/2026-01-25/12-11-49/.hydra/overrides.yaml
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
- algorithm.adv_estimator=grpo
|
| 2 |
+
- data.train_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/train.parquet
|
| 3 |
+
- data.val_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/test.parquet
|
| 4 |
+
- data.train_batch_size=1024
|
| 5 |
+
- data.max_prompt_length=512
|
| 6 |
+
- data.max_response_length=40
|
| 7 |
+
- data.filter_overlong_prompts=True
|
| 8 |
+
- data.truncation=error
|
| 9 |
+
- data.shuffle=False
|
| 10 |
+
- actor_rollout_ref.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 11 |
+
- actor_rollout_ref.actor.optim.lr=1e-6
|
| 12 |
+
- actor_rollout_ref.model.use_remove_padding=True
|
| 13 |
+
- actor_rollout_ref.actor.ppo_mini_batch_size=256
|
| 14 |
+
- actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=32
|
| 15 |
+
- actor_rollout_ref.actor.use_kl_loss=True
|
| 16 |
+
- actor_rollout_ref.actor.kl_loss_coef=0.001
|
| 17 |
+
- actor_rollout_ref.actor.kl_loss_type=low_var_kl
|
| 18 |
+
- actor_rollout_ref.actor.entropy_coeff=0
|
| 19 |
+
- actor_rollout_ref.model.enable_gradient_checkpointing=True
|
| 20 |
+
- actor_rollout_ref.actor.fsdp_config.param_offload=True
|
| 21 |
+
- actor_rollout_ref.actor.fsdp_config.optimizer_offload=False
|
| 22 |
+
- actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32
|
| 23 |
+
- actor_rollout_ref.rollout.tensor_model_parallel_size=2
|
| 24 |
+
- actor_rollout_ref.rollout.name=vllm
|
| 25 |
+
- actor_rollout_ref.rollout.gpu_memory_utilization=0.6
|
| 26 |
+
- actor_rollout_ref.rollout.n=5
|
| 27 |
+
- actor_rollout_ref.rollout.load_format=safetensors
|
| 28 |
+
- actor_rollout_ref.rollout.layered_summon=True
|
| 29 |
+
- actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32
|
| 30 |
+
- actor_rollout_ref.ref.fsdp_config.param_offload=False
|
| 31 |
+
- algorithm.use_kl_in_reward=False
|
| 32 |
+
- reward_model.enable=True
|
| 33 |
+
- reward_model.enable=True
|
| 34 |
+
- reward_model.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/reward_model_converted
|
| 35 |
+
- reward_model.micro_batch_size_per_gpu=32
|
| 36 |
+
- trainer.critic_warmup=0
|
| 37 |
+
- trainer.logger=["console","wandb"]
|
| 38 |
+
- trainer.project_name=verl_grpo_gsm8k
|
| 39 |
+
- trainer.experiment_name=qwen3_4b_gsm8k_grpo
|
| 40 |
+
- trainer.n_gpus_per_node=8
|
| 41 |
+
- trainer.default_local_dir=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/train_output/grpo_0125
|
| 42 |
+
- trainer.rollout_data_dir=outputs/grpo_rollouts
|
| 43 |
+
- trainer.nnodes=1
|
| 44 |
+
- trainer.save_freq=20
|
| 45 |
+
- trainer.test_freq=5
|
| 46 |
+
- trainer.total_epochs=15
|
| 47 |
+
- trainer.resume_mode=disable
|
examples/grpo_trainer/outputs/2026-01-25/12-26-13/.hydra/config.yaml
ADDED
|
@@ -0,0 +1,610 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
actor_rollout_ref:
|
| 2 |
+
actor:
|
| 3 |
+
optim:
|
| 4 |
+
_target_: verl.workers.config.FSDPOptimizerConfig
|
| 5 |
+
optimizer: AdamW
|
| 6 |
+
optimizer_impl: torch.optim
|
| 7 |
+
lr: 1.0e-06
|
| 8 |
+
lr_warmup_steps_ratio: 0.0
|
| 9 |
+
total_training_steps: -1
|
| 10 |
+
weight_decay: 0.01
|
| 11 |
+
lr_warmup_steps: -1
|
| 12 |
+
betas:
|
| 13 |
+
- 0.9
|
| 14 |
+
- 0.999
|
| 15 |
+
clip_grad: 1.0
|
| 16 |
+
min_lr_ratio: 0.0
|
| 17 |
+
num_cycles: 0.5
|
| 18 |
+
lr_scheduler_type: constant
|
| 19 |
+
warmup_style: null
|
| 20 |
+
override_optimizer_config: null
|
| 21 |
+
fsdp_config:
|
| 22 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 23 |
+
wrap_policy:
|
| 24 |
+
min_num_params: 0
|
| 25 |
+
param_offload: true
|
| 26 |
+
optimizer_offload: false
|
| 27 |
+
offload_policy: false
|
| 28 |
+
reshard_after_forward: true
|
| 29 |
+
fsdp_size: -1
|
| 30 |
+
forward_prefetch: false
|
| 31 |
+
model_dtype: fp32
|
| 32 |
+
use_orig_params: false
|
| 33 |
+
seed: 42
|
| 34 |
+
full_determinism: false
|
| 35 |
+
ulysses_sequence_parallel_size: 1
|
| 36 |
+
entropy_from_logits_with_chunking: false
|
| 37 |
+
use_torch_compile: true
|
| 38 |
+
entropy_checkpointing: false
|
| 39 |
+
forward_only: false
|
| 40 |
+
strategy: fsdp
|
| 41 |
+
dtype: bfloat16
|
| 42 |
+
_target_: verl.workers.config.FSDPActorConfig
|
| 43 |
+
rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
|
| 44 |
+
strategy: fsdp
|
| 45 |
+
ppo_mini_batch_size: 256
|
| 46 |
+
ppo_micro_batch_size: null
|
| 47 |
+
ppo_micro_batch_size_per_gpu: 32
|
| 48 |
+
use_dynamic_bsz: false
|
| 49 |
+
ppo_max_token_len_per_gpu: 16384
|
| 50 |
+
clip_ratio: 0.2
|
| 51 |
+
clip_ratio_low: 0.2
|
| 52 |
+
clip_ratio_high: 0.2
|
| 53 |
+
freeze_vision_tower: false
|
| 54 |
+
policy_loss:
|
| 55 |
+
_target_: verl.workers.config.PolicyLossConfig
|
| 56 |
+
loss_mode: vanilla
|
| 57 |
+
clip_cov_ratio: 0.0002
|
| 58 |
+
clip_cov_lb: 1.0
|
| 59 |
+
clip_cov_ub: 5.0
|
| 60 |
+
kl_cov_ratio: 0.0002
|
| 61 |
+
ppo_kl_coef: 0.1
|
| 62 |
+
clip_ratio_c: 3.0
|
| 63 |
+
loss_agg_mode: token-mean
|
| 64 |
+
loss_scale_factor: null
|
| 65 |
+
entropy_coeff: 0
|
| 66 |
+
calculate_entropy: false
|
| 67 |
+
use_kl_loss: true
|
| 68 |
+
use_torch_compile: true
|
| 69 |
+
kl_loss_coef: 0.001
|
| 70 |
+
kl_loss_type: low_var_kl
|
| 71 |
+
ppo_epochs: 1
|
| 72 |
+
shuffle: false
|
| 73 |
+
checkpoint:
|
| 74 |
+
_target_: verl.trainer.config.CheckpointConfig
|
| 75 |
+
save_contents:
|
| 76 |
+
- model
|
| 77 |
+
- optimizer
|
| 78 |
+
- extra
|
| 79 |
+
load_contents: ${.save_contents}
|
| 80 |
+
async_save: false
|
| 81 |
+
use_fused_kernels: ${oc.select:actor_rollout_ref.model.use_fused_kernels,false}
|
| 82 |
+
profiler:
|
| 83 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 84 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 85 |
+
enable: false
|
| 86 |
+
all_ranks: false
|
| 87 |
+
ranks: []
|
| 88 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 89 |
+
tool_config:
|
| 90 |
+
nsys:
|
| 91 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 92 |
+
discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
|
| 93 |
+
npu:
|
| 94 |
+
_target_: verl.utils.profiler.config.NPUToolConfig
|
| 95 |
+
contents: []
|
| 96 |
+
level: level1
|
| 97 |
+
analysis: true
|
| 98 |
+
discrete: false
|
| 99 |
+
torch:
|
| 100 |
+
_target_: verl.utils.profiler.config.TorchProfilerToolConfig
|
| 101 |
+
step_start: 0
|
| 102 |
+
step_end: null
|
| 103 |
+
torch_memory:
|
| 104 |
+
_target_: verl.utils.profiler.config.TorchMemoryToolConfig
|
| 105 |
+
trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
|
| 106 |
+
stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
|
| 107 |
+
router_replay:
|
| 108 |
+
_target_: verl.workers.config.RouterReplayConfig
|
| 109 |
+
mode: disabled
|
| 110 |
+
record_file: null
|
| 111 |
+
replay_file: null
|
| 112 |
+
grad_clip: 1.0
|
| 113 |
+
ulysses_sequence_parallel_size: 1
|
| 114 |
+
entropy_from_logits_with_chunking: false
|
| 115 |
+
entropy_checkpointing: false
|
| 116 |
+
use_remove_padding: ${oc.select:actor_rollout_ref.model.use_remove_padding,false}
|
| 117 |
+
ref:
|
| 118 |
+
rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
|
| 119 |
+
strategy: ${actor_rollout_ref.actor.strategy}
|
| 120 |
+
use_torch_compile: ${oc.select:actor_rollout_ref.actor.use_torch_compile,true}
|
| 121 |
+
log_prob_micro_batch_size: null
|
| 122 |
+
log_prob_micro_batch_size_per_gpu: 32
|
| 123 |
+
log_prob_use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
|
| 124 |
+
log_prob_max_token_len_per_gpu: ${oc.select:actor_rollout_ref.actor.ppo_max_token_len_per_gpu,16384}
|
| 125 |
+
profiler:
|
| 126 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 127 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 128 |
+
enable: false
|
| 129 |
+
all_ranks: false
|
| 130 |
+
ranks: []
|
| 131 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 132 |
+
tool_config:
|
| 133 |
+
nsys:
|
| 134 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 135 |
+
discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
|
| 136 |
+
npu:
|
| 137 |
+
_target_: verl.utils.profiler.config.NPUToolConfig
|
| 138 |
+
contents: []
|
| 139 |
+
level: level1
|
| 140 |
+
analysis: true
|
| 141 |
+
discrete: false
|
| 142 |
+
torch:
|
| 143 |
+
_target_: verl.utils.profiler.config.TorchProfilerToolConfig
|
| 144 |
+
step_start: 0
|
| 145 |
+
step_end: null
|
| 146 |
+
torch_memory:
|
| 147 |
+
_target_: verl.utils.profiler.config.TorchMemoryToolConfig
|
| 148 |
+
trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
|
| 149 |
+
stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
|
| 150 |
+
router_replay:
|
| 151 |
+
_target_: verl.workers.config.RouterReplayConfig
|
| 152 |
+
mode: disabled
|
| 153 |
+
record_file: null
|
| 154 |
+
replay_file: null
|
| 155 |
+
fsdp_config:
|
| 156 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 157 |
+
wrap_policy:
|
| 158 |
+
min_num_params: 0
|
| 159 |
+
param_offload: false
|
| 160 |
+
optimizer_offload: false
|
| 161 |
+
offload_policy: false
|
| 162 |
+
reshard_after_forward: true
|
| 163 |
+
fsdp_size: -1
|
| 164 |
+
forward_prefetch: false
|
| 165 |
+
model_dtype: fp32
|
| 166 |
+
use_orig_params: false
|
| 167 |
+
seed: 42
|
| 168 |
+
full_determinism: false
|
| 169 |
+
ulysses_sequence_parallel_size: 1
|
| 170 |
+
entropy_from_logits_with_chunking: false
|
| 171 |
+
use_torch_compile: true
|
| 172 |
+
entropy_checkpointing: false
|
| 173 |
+
forward_only: true
|
| 174 |
+
strategy: fsdp
|
| 175 |
+
dtype: bfloat16
|
| 176 |
+
_target_: verl.workers.config.FSDPActorConfig
|
| 177 |
+
ulysses_sequence_parallel_size: ${oc.select:actor_rollout_ref.actor.ulysses_sequence_parallel_size,1}
|
| 178 |
+
entropy_from_logits_with_chunking: false
|
| 179 |
+
entropy_checkpointing: false
|
| 180 |
+
rollout:
|
| 181 |
+
_target_: verl.workers.config.RolloutConfig
|
| 182 |
+
name: vllm
|
| 183 |
+
mode: async
|
| 184 |
+
temperature: 1.0
|
| 185 |
+
top_k: -1
|
| 186 |
+
top_p: 1
|
| 187 |
+
prompt_length: ${oc.select:data.max_prompt_length,512}
|
| 188 |
+
response_length: ${oc.select:data.max_response_length,512}
|
| 189 |
+
dtype: bfloat16
|
| 190 |
+
gpu_memory_utilization: 0.6
|
| 191 |
+
ignore_eos: false
|
| 192 |
+
enforce_eager: false
|
| 193 |
+
cudagraph_capture_sizes: null
|
| 194 |
+
free_cache_engine: true
|
| 195 |
+
tensor_model_parallel_size: 2
|
| 196 |
+
data_parallel_size: 1
|
| 197 |
+
expert_parallel_size: 1
|
| 198 |
+
pipeline_model_parallel_size: 1
|
| 199 |
+
max_num_batched_tokens: 8192
|
| 200 |
+
max_model_len: null
|
| 201 |
+
max_num_seqs: 1024
|
| 202 |
+
enable_chunked_prefill: true
|
| 203 |
+
enable_prefix_caching: true
|
| 204 |
+
load_format: safetensors
|
| 205 |
+
log_prob_micro_batch_size: null
|
| 206 |
+
log_prob_micro_batch_size_per_gpu: 32
|
| 207 |
+
log_prob_use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
|
| 208 |
+
log_prob_max_token_len_per_gpu: ${oc.select:actor_rollout_ref.actor.ppo_max_token_len_per_gpu,16384}
|
| 209 |
+
disable_log_stats: true
|
| 210 |
+
do_sample: true
|
| 211 |
+
'n': 5
|
| 212 |
+
over_sample_rate: 0
|
| 213 |
+
multi_stage_wake_up: false
|
| 214 |
+
engine_kwargs:
|
| 215 |
+
vllm: {}
|
| 216 |
+
sglang: {}
|
| 217 |
+
val_kwargs:
|
| 218 |
+
_target_: verl.workers.config.SamplingConfig
|
| 219 |
+
top_k: -1
|
| 220 |
+
top_p: 1.0
|
| 221 |
+
temperature: 0
|
| 222 |
+
'n': 1
|
| 223 |
+
do_sample: false
|
| 224 |
+
multi_turn:
|
| 225 |
+
_target_: verl.workers.config.MultiTurnConfig
|
| 226 |
+
enable: false
|
| 227 |
+
max_assistant_turns: null
|
| 228 |
+
tool_config_path: null
|
| 229 |
+
max_user_turns: null
|
| 230 |
+
max_parallel_calls: 1
|
| 231 |
+
max_tool_response_length: 256
|
| 232 |
+
tool_response_truncate_side: middle
|
| 233 |
+
interaction_config_path: null
|
| 234 |
+
use_inference_chat_template: false
|
| 235 |
+
tokenization_sanity_check_mode: strict
|
| 236 |
+
format: hermes
|
| 237 |
+
num_repeat_rollouts: null
|
| 238 |
+
calculate_log_probs: false
|
| 239 |
+
agent:
|
| 240 |
+
_target_: verl.workers.config.AgentLoopConfig
|
| 241 |
+
num_workers: 8
|
| 242 |
+
default_agent_loop: single_turn_agent
|
| 243 |
+
agent_loop_config_path: null
|
| 244 |
+
custom_async_server:
|
| 245 |
+
_target_: verl.workers.config.CustomAsyncServerConfig
|
| 246 |
+
path: null
|
| 247 |
+
name: null
|
| 248 |
+
update_weights_bucket_megabytes: 512
|
| 249 |
+
trace:
|
| 250 |
+
_target_: verl.workers.config.TraceConfig
|
| 251 |
+
backend: null
|
| 252 |
+
token2text: false
|
| 253 |
+
max_samples_per_step_per_worker: null
|
| 254 |
+
skip_rollout: false
|
| 255 |
+
skip_dump_dir: /tmp/rollout_dump
|
| 256 |
+
skip_tokenizer_init: true
|
| 257 |
+
enable_rollout_routing_replay: false
|
| 258 |
+
profiler:
|
| 259 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 260 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 261 |
+
enable: ${oc.select:actor_rollout_ref.actor.profiler.enable,false}
|
| 262 |
+
all_ranks: ${oc.select:actor_rollout_ref.actor.profiler.all_ranks,false}
|
| 263 |
+
ranks: ${oc.select:actor_rollout_ref.actor.profiler.ranks,[]}
|
| 264 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 265 |
+
tool_config: ${oc.select:actor_rollout_ref.actor.profiler.tool_config,null}
|
| 266 |
+
prometheus:
|
| 267 |
+
_target_: verl.workers.config.PrometheusConfig
|
| 268 |
+
enable: false
|
| 269 |
+
port: 9090
|
| 270 |
+
file: /tmp/ray/session_latest/metrics/prometheus/prometheus.yml
|
| 271 |
+
served_model_name: ${oc.select:actor_rollout_ref.model.path,null}
|
| 272 |
+
layered_summon: true
|
| 273 |
+
model:
|
| 274 |
+
_target_: verl.workers.config.HFModelConfig
|
| 275 |
+
path: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 276 |
+
hf_config_path: null
|
| 277 |
+
tokenizer_path: null
|
| 278 |
+
use_shm: false
|
| 279 |
+
trust_remote_code: false
|
| 280 |
+
custom_chat_template: null
|
| 281 |
+
external_lib: null
|
| 282 |
+
override_config: {}
|
| 283 |
+
enable_gradient_checkpointing: true
|
| 284 |
+
enable_activation_offload: false
|
| 285 |
+
use_remove_padding: true
|
| 286 |
+
lora_rank: 0
|
| 287 |
+
lora_alpha: 16
|
| 288 |
+
target_modules: all-linear
|
| 289 |
+
exclude_modules: null
|
| 290 |
+
lora_adapter_path: null
|
| 291 |
+
use_liger: false
|
| 292 |
+
use_fused_kernels: false
|
| 293 |
+
fused_kernel_options:
|
| 294 |
+
impl_backend: torch
|
| 295 |
+
hybrid_engine: true
|
| 296 |
+
nccl_timeout: 600
|
| 297 |
+
data:
|
| 298 |
+
tokenizer: null
|
| 299 |
+
use_shm: false
|
| 300 |
+
train_files: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/train.parquet
|
| 301 |
+
val_files: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/test.parquet
|
| 302 |
+
train_max_samples: -1
|
| 303 |
+
val_max_samples: -1
|
| 304 |
+
prompt_key: prompt
|
| 305 |
+
reward_fn_key: data_source
|
| 306 |
+
max_prompt_length: 512
|
| 307 |
+
max_response_length: 40
|
| 308 |
+
train_batch_size: 1024
|
| 309 |
+
val_batch_size: null
|
| 310 |
+
tool_config_path: ${oc.select:actor_rollout_ref.rollout.multi_turn.tool_config_path,
|
| 311 |
+
null}
|
| 312 |
+
return_raw_input_ids: false
|
| 313 |
+
return_raw_chat: true
|
| 314 |
+
return_full_prompt: false
|
| 315 |
+
shuffle: false
|
| 316 |
+
seed: null
|
| 317 |
+
dataloader_num_workers: 8
|
| 318 |
+
image_patch_size: 14
|
| 319 |
+
validation_shuffle: false
|
| 320 |
+
filter_overlong_prompts: true
|
| 321 |
+
filter_overlong_prompts_workers: 1
|
| 322 |
+
truncation: error
|
| 323 |
+
image_key: images
|
| 324 |
+
video_key: videos
|
| 325 |
+
trust_remote_code: false
|
| 326 |
+
custom_cls:
|
| 327 |
+
path: null
|
| 328 |
+
name: null
|
| 329 |
+
return_multi_modal_inputs: true
|
| 330 |
+
sampler:
|
| 331 |
+
class_path: null
|
| 332 |
+
class_name: null
|
| 333 |
+
datagen:
|
| 334 |
+
path: null
|
| 335 |
+
name: null
|
| 336 |
+
apply_chat_template_kwargs: {}
|
| 337 |
+
reward_manager:
|
| 338 |
+
_target_: verl.trainer.config.config.RewardManagerConfig
|
| 339 |
+
source: register
|
| 340 |
+
name: ${oc.select:reward_model.reward_manager,naive}
|
| 341 |
+
module:
|
| 342 |
+
_target_: verl.trainer.config.config.ModuleConfig
|
| 343 |
+
path: null
|
| 344 |
+
name: custom_reward_manager
|
| 345 |
+
critic:
|
| 346 |
+
optim:
|
| 347 |
+
_target_: verl.workers.config.FSDPOptimizerConfig
|
| 348 |
+
optimizer: AdamW
|
| 349 |
+
optimizer_impl: torch.optim
|
| 350 |
+
lr: 1.0e-05
|
| 351 |
+
lr_warmup_steps_ratio: 0.0
|
| 352 |
+
total_training_steps: -1
|
| 353 |
+
weight_decay: 0.01
|
| 354 |
+
lr_warmup_steps: -1
|
| 355 |
+
betas:
|
| 356 |
+
- 0.9
|
| 357 |
+
- 0.999
|
| 358 |
+
clip_grad: 1.0
|
| 359 |
+
min_lr_ratio: 0.0
|
| 360 |
+
num_cycles: 0.5
|
| 361 |
+
lr_scheduler_type: constant
|
| 362 |
+
warmup_style: null
|
| 363 |
+
override_optimizer_config: null
|
| 364 |
+
model:
|
| 365 |
+
fsdp_config:
|
| 366 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 367 |
+
wrap_policy:
|
| 368 |
+
min_num_params: 0
|
| 369 |
+
param_offload: false
|
| 370 |
+
optimizer_offload: false
|
| 371 |
+
offload_policy: false
|
| 372 |
+
reshard_after_forward: true
|
| 373 |
+
fsdp_size: -1
|
| 374 |
+
forward_prefetch: false
|
| 375 |
+
model_dtype: fp32
|
| 376 |
+
use_orig_params: false
|
| 377 |
+
seed: 42
|
| 378 |
+
full_determinism: false
|
| 379 |
+
ulysses_sequence_parallel_size: 1
|
| 380 |
+
entropy_from_logits_with_chunking: false
|
| 381 |
+
use_torch_compile: true
|
| 382 |
+
entropy_checkpointing: false
|
| 383 |
+
forward_only: false
|
| 384 |
+
strategy: fsdp
|
| 385 |
+
dtype: bfloat16
|
| 386 |
+
path: ~/models/deepseek-llm-7b-chat
|
| 387 |
+
tokenizer_path: ${oc.select:actor_rollout_ref.model.path,"~/models/deepseek-llm-7b-chat"}
|
| 388 |
+
override_config: {}
|
| 389 |
+
external_lib: ${oc.select:actor_rollout_ref.model.external_lib,null}
|
| 390 |
+
trust_remote_code: ${oc.select:actor_rollout_ref.model.trust_remote_code,false}
|
| 391 |
+
_target_: verl.workers.config.FSDPCriticModelCfg
|
| 392 |
+
use_shm: false
|
| 393 |
+
enable_gradient_checkpointing: true
|
| 394 |
+
enable_activation_offload: false
|
| 395 |
+
use_remove_padding: false
|
| 396 |
+
lora_rank: 0
|
| 397 |
+
lora_alpha: 16
|
| 398 |
+
target_modules: all-linear
|
| 399 |
+
_target_: verl.workers.config.FSDPCriticConfig
|
| 400 |
+
rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
|
| 401 |
+
strategy: fsdp
|
| 402 |
+
enable: null
|
| 403 |
+
ppo_mini_batch_size: ${oc.select:actor_rollout_ref.actor.ppo_mini_batch_size,256}
|
| 404 |
+
ppo_micro_batch_size: null
|
| 405 |
+
ppo_micro_batch_size_per_gpu: ${oc.select:.ppo_micro_batch_size,null}
|
| 406 |
+
use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
|
| 407 |
+
ppo_max_token_len_per_gpu: 32768
|
| 408 |
+
forward_max_token_len_per_gpu: ${.ppo_max_token_len_per_gpu}
|
| 409 |
+
ppo_epochs: ${oc.select:actor_rollout_ref.actor.ppo_epochs,1}
|
| 410 |
+
shuffle: ${oc.select:actor_rollout_ref.actor.shuffle,false}
|
| 411 |
+
cliprange_value: 0.5
|
| 412 |
+
loss_agg_mode: ${oc.select:actor_rollout_ref.actor.loss_agg_mode,token-mean}
|
| 413 |
+
checkpoint:
|
| 414 |
+
_target_: verl.trainer.config.CheckpointConfig
|
| 415 |
+
save_contents:
|
| 416 |
+
- model
|
| 417 |
+
- optimizer
|
| 418 |
+
- extra
|
| 419 |
+
load_contents: ${.save_contents}
|
| 420 |
+
async_save: false
|
| 421 |
+
profiler:
|
| 422 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 423 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 424 |
+
enable: false
|
| 425 |
+
all_ranks: false
|
| 426 |
+
ranks: []
|
| 427 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 428 |
+
tool_config:
|
| 429 |
+
nsys:
|
| 430 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 431 |
+
discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
|
| 432 |
+
npu:
|
| 433 |
+
_target_: verl.utils.profiler.config.NPUToolConfig
|
| 434 |
+
contents: []
|
| 435 |
+
level: level1
|
| 436 |
+
analysis: true
|
| 437 |
+
discrete: false
|
| 438 |
+
torch:
|
| 439 |
+
_target_: verl.utils.profiler.config.TorchProfilerToolConfig
|
| 440 |
+
step_start: 0
|
| 441 |
+
step_end: null
|
| 442 |
+
torch_memory:
|
| 443 |
+
_target_: verl.utils.profiler.config.TorchMemoryToolConfig
|
| 444 |
+
trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
|
| 445 |
+
stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
|
| 446 |
+
forward_micro_batch_size: ${oc.select:.ppo_micro_batch_size,null}
|
| 447 |
+
forward_micro_batch_size_per_gpu: ${oc.select:.ppo_micro_batch_size_per_gpu,null}
|
| 448 |
+
ulysses_sequence_parallel_size: 1
|
| 449 |
+
grad_clip: 1.0
|
| 450 |
+
reward_model:
|
| 451 |
+
enable: true
|
| 452 |
+
enable_resource_pool: false
|
| 453 |
+
n_gpus_per_node: 0
|
| 454 |
+
nnodes: 0
|
| 455 |
+
strategy: fsdp
|
| 456 |
+
model:
|
| 457 |
+
input_tokenizer: ${actor_rollout_ref.model.path}
|
| 458 |
+
path: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/reward_model_converted
|
| 459 |
+
external_lib: ${actor_rollout_ref.model.external_lib}
|
| 460 |
+
trust_remote_code: false
|
| 461 |
+
override_config: {}
|
| 462 |
+
use_shm: false
|
| 463 |
+
use_remove_padding: false
|
| 464 |
+
use_fused_kernels: ${actor_rollout_ref.model.use_fused_kernels}
|
| 465 |
+
fsdp_config:
|
| 466 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 467 |
+
wrap_policy:
|
| 468 |
+
min_num_params: 0
|
| 469 |
+
param_offload: false
|
| 470 |
+
reshard_after_forward: true
|
| 471 |
+
fsdp_size: -1
|
| 472 |
+
forward_prefetch: false
|
| 473 |
+
micro_batch_size: null
|
| 474 |
+
micro_batch_size_per_gpu: 32
|
| 475 |
+
max_length: null
|
| 476 |
+
use_dynamic_bsz: ${critic.use_dynamic_bsz}
|
| 477 |
+
forward_max_token_len_per_gpu: ${critic.forward_max_token_len_per_gpu}
|
| 478 |
+
reward_manager: naive
|
| 479 |
+
launch_reward_fn_async: false
|
| 480 |
+
sandbox_fusion:
|
| 481 |
+
url: null
|
| 482 |
+
max_concurrent: 64
|
| 483 |
+
memory_limit_mb: 1024
|
| 484 |
+
profiler:
|
| 485 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 486 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 487 |
+
enable: false
|
| 488 |
+
all_ranks: false
|
| 489 |
+
ranks: []
|
| 490 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 491 |
+
tool_config: ${oc.select:actor_rollout_ref.actor.profiler.tool_config,null}
|
| 492 |
+
ulysses_sequence_parallel_size: 1
|
| 493 |
+
use_reward_loop: true
|
| 494 |
+
rollout:
|
| 495 |
+
_target_: verl.workers.config.RolloutConfig
|
| 496 |
+
name: ???
|
| 497 |
+
dtype: bfloat16
|
| 498 |
+
gpu_memory_utilization: 0.5
|
| 499 |
+
enforce_eager: true
|
| 500 |
+
cudagraph_capture_sizes: null
|
| 501 |
+
free_cache_engine: true
|
| 502 |
+
data_parallel_size: 1
|
| 503 |
+
expert_parallel_size: 1
|
| 504 |
+
tensor_model_parallel_size: 2
|
| 505 |
+
max_num_batched_tokens: 8192
|
| 506 |
+
max_model_len: null
|
| 507 |
+
max_num_seqs: 1024
|
| 508 |
+
load_format: auto
|
| 509 |
+
engine_kwargs: {}
|
| 510 |
+
limit_images: null
|
| 511 |
+
enable_chunked_prefill: true
|
| 512 |
+
enable_prefix_caching: true
|
| 513 |
+
disable_log_stats: true
|
| 514 |
+
skip_tokenizer_init: true
|
| 515 |
+
prompt_length: 512
|
| 516 |
+
response_length: 512
|
| 517 |
+
algorithm:
|
| 518 |
+
rollout_correction:
|
| 519 |
+
rollout_is: null
|
| 520 |
+
rollout_is_threshold: 2.0
|
| 521 |
+
rollout_rs: null
|
| 522 |
+
rollout_rs_threshold: null
|
| 523 |
+
rollout_rs_threshold_lower: null
|
| 524 |
+
rollout_token_veto_threshold: null
|
| 525 |
+
bypass_mode: false
|
| 526 |
+
use_policy_gradient: false
|
| 527 |
+
rollout_is_batch_normalize: false
|
| 528 |
+
_target_: verl.trainer.config.AlgoConfig
|
| 529 |
+
gamma: 1.0
|
| 530 |
+
lam: 1.0
|
| 531 |
+
adv_estimator: grpo
|
| 532 |
+
norm_adv_by_std_in_grpo: true
|
| 533 |
+
use_kl_in_reward: false
|
| 534 |
+
kl_penalty: kl
|
| 535 |
+
kl_ctrl:
|
| 536 |
+
_target_: verl.trainer.config.KLControlConfig
|
| 537 |
+
type: fixed
|
| 538 |
+
kl_coef: 0.001
|
| 539 |
+
horizon: 10000
|
| 540 |
+
target_kl: 0.1
|
| 541 |
+
use_pf_ppo: false
|
| 542 |
+
pf_ppo:
|
| 543 |
+
reweight_method: pow
|
| 544 |
+
weight_pow: 2.0
|
| 545 |
+
custom_reward_function:
|
| 546 |
+
path: null
|
| 547 |
+
name: compute_score
|
| 548 |
+
trainer:
|
| 549 |
+
balance_batch: true
|
| 550 |
+
total_epochs: 30
|
| 551 |
+
total_training_steps: null
|
| 552 |
+
project_name: verl_grpo_gsm8k
|
| 553 |
+
experiment_name: qwen3_4b_gsm8k_grpo
|
| 554 |
+
logger:
|
| 555 |
+
- console
|
| 556 |
+
- wandb
|
| 557 |
+
log_val_generations: 0
|
| 558 |
+
rollout_data_dir: null
|
| 559 |
+
validation_data_dir: null
|
| 560 |
+
nnodes: 1
|
| 561 |
+
n_gpus_per_node: 8
|
| 562 |
+
save_freq: -1
|
| 563 |
+
esi_redundant_time: 0
|
| 564 |
+
resume_mode: auto
|
| 565 |
+
resume_from_path: null
|
| 566 |
+
val_before_train: true
|
| 567 |
+
val_only: false
|
| 568 |
+
test_freq: -1
|
| 569 |
+
critic_warmup: 0
|
| 570 |
+
default_hdfs_dir: null
|
| 571 |
+
del_local_ckpt_after_load: false
|
| 572 |
+
default_local_dir: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/train_output/grpo_0125
|
| 573 |
+
max_actor_ckpt_to_keep: null
|
| 574 |
+
max_critic_ckpt_to_keep: null
|
| 575 |
+
ray_wait_register_center_timeout: 300
|
| 576 |
+
device: cuda
|
| 577 |
+
use_legacy_worker_impl: auto
|
| 578 |
+
global_profiler:
|
| 579 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 580 |
+
tool: null
|
| 581 |
+
steps: null
|
| 582 |
+
profile_continuous_steps: false
|
| 583 |
+
save_path: outputs/profile
|
| 584 |
+
global_tool_config:
|
| 585 |
+
nsys:
|
| 586 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 587 |
+
discrete: false
|
| 588 |
+
controller_nsight_options:
|
| 589 |
+
trace: cuda,nvtx,cublas,ucx
|
| 590 |
+
cuda-memory-usage: 'true'
|
| 591 |
+
cuda-graph-trace: graph
|
| 592 |
+
worker_nsight_options:
|
| 593 |
+
trace: cuda,nvtx,cublas,ucx
|
| 594 |
+
cuda-memory-usage: 'true'
|
| 595 |
+
cuda-graph-trace: graph
|
| 596 |
+
capture-range: cudaProfilerApi
|
| 597 |
+
capture-range-end: null
|
| 598 |
+
kill: none
|
| 599 |
+
torch_memory:
|
| 600 |
+
trace_alloc_max_entries: 100000
|
| 601 |
+
stack_depth: 32
|
| 602 |
+
context: all
|
| 603 |
+
stacks: all
|
| 604 |
+
kw_args: {}
|
| 605 |
+
transfer_queue:
|
| 606 |
+
enable: false
|
| 607 |
+
ray_kwargs:
|
| 608 |
+
ray_init:
|
| 609 |
+
num_cpus: null
|
| 610 |
+
timeline_json_file: null
|
examples/grpo_trainer/outputs/2026-01-25/12-30-14/.hydra/overrides.yaml
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
- algorithm.adv_estimator=grpo
|
| 2 |
+
- data.train_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/train.parquet
|
| 3 |
+
- data.val_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/test.parquet
|
| 4 |
+
- data.train_batch_size=1024
|
| 5 |
+
- data.max_prompt_length=512
|
| 6 |
+
- data.max_response_length=40
|
| 7 |
+
- data.filter_overlong_prompts=True
|
| 8 |
+
- data.truncation=error
|
| 9 |
+
- data.shuffle=False
|
| 10 |
+
- actor_rollout_ref.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 11 |
+
- actor_rollout_ref.actor.optim.lr=1e-6
|
| 12 |
+
- actor_rollout_ref.model.use_remove_padding=True
|
| 13 |
+
- actor_rollout_ref.actor.ppo_mini_batch_size=256
|
| 14 |
+
- actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=32
|
| 15 |
+
- actor_rollout_ref.actor.use_kl_loss=True
|
| 16 |
+
- actor_rollout_ref.actor.kl_loss_coef=0.001
|
| 17 |
+
- actor_rollout_ref.actor.kl_loss_type=low_var_kl
|
| 18 |
+
- actor_rollout_ref.actor.entropy_coeff=0
|
| 19 |
+
- actor_rollout_ref.model.enable_gradient_checkpointing=True
|
| 20 |
+
- actor_rollout_ref.actor.fsdp_config.param_offload=True
|
| 21 |
+
- actor_rollout_ref.actor.fsdp_config.optimizer_offload=False
|
| 22 |
+
- actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32
|
| 23 |
+
- actor_rollout_ref.rollout.tensor_model_parallel_size=2
|
| 24 |
+
- actor_rollout_ref.rollout.name=vllm
|
| 25 |
+
- actor_rollout_ref.rollout.gpu_memory_utilization=0.6
|
| 26 |
+
- actor_rollout_ref.rollout.n=5
|
| 27 |
+
- actor_rollout_ref.rollout.load_format=safetensors
|
| 28 |
+
- actor_rollout_ref.rollout.layered_summon=True
|
| 29 |
+
- actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32
|
| 30 |
+
- actor_rollout_ref.ref.fsdp_config.param_offload=False
|
| 31 |
+
- algorithm.use_kl_in_reward=False
|
| 32 |
+
- reward_model.enable=True
|
| 33 |
+
- reward_model.enable=True
|
| 34 |
+
- reward_model.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/reward_model_converted
|
| 35 |
+
- reward_model.micro_batch_size_per_gpu=32
|
| 36 |
+
- trainer.critic_warmup=0
|
| 37 |
+
- trainer.logger=["console","wandb"]
|
| 38 |
+
- trainer.project_name=verl_grpo_gsm8k
|
| 39 |
+
- trainer.experiment_name=qwen3_4b_gsm8k_grpo
|
| 40 |
+
- trainer.n_gpus_per_node=8
|
| 41 |
+
- trainer.default_local_dir=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/train_output/grpo_0125
|
examples/grpo_trainer/outputs/2026-01-25/12-31-47/.hydra/hydra.yaml
ADDED
|
@@ -0,0 +1,208 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
hydra:
|
| 2 |
+
run:
|
| 3 |
+
dir: outputs/${now:%Y-%m-%d}/${now:%H-%M-%S}
|
| 4 |
+
sweep:
|
| 5 |
+
dir: multirun/${now:%Y-%m-%d}/${now:%H-%M-%S}
|
| 6 |
+
subdir: ${hydra.job.num}
|
| 7 |
+
launcher:
|
| 8 |
+
_target_: hydra._internal.core_plugins.basic_launcher.BasicLauncher
|
| 9 |
+
sweeper:
|
| 10 |
+
_target_: hydra._internal.core_plugins.basic_sweeper.BasicSweeper
|
| 11 |
+
max_batch_size: null
|
| 12 |
+
params: null
|
| 13 |
+
help:
|
| 14 |
+
app_name: ${hydra.job.name}
|
| 15 |
+
header: '${hydra.help.app_name} is powered by Hydra.
|
| 16 |
+
|
| 17 |
+
'
|
| 18 |
+
footer: 'Powered by Hydra (https://hydra.cc)
|
| 19 |
+
|
| 20 |
+
Use --hydra-help to view Hydra specific help
|
| 21 |
+
|
| 22 |
+
'
|
| 23 |
+
template: '${hydra.help.header}
|
| 24 |
+
|
| 25 |
+
== Configuration groups ==
|
| 26 |
+
|
| 27 |
+
Compose your configuration from those groups (group=option)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
$APP_CONFIG_GROUPS
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
== Config ==
|
| 34 |
+
|
| 35 |
+
Override anything in the config (foo.bar=value)
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
$CONFIG
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
${hydra.help.footer}
|
| 42 |
+
|
| 43 |
+
'
|
| 44 |
+
hydra_help:
|
| 45 |
+
template: 'Hydra (${hydra.runtime.version})
|
| 46 |
+
|
| 47 |
+
See https://hydra.cc for more info.
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
== Flags ==
|
| 51 |
+
|
| 52 |
+
$FLAGS_HELP
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
== Configuration groups ==
|
| 56 |
+
|
| 57 |
+
Compose your configuration from those groups (For example, append hydra/job_logging=disabled
|
| 58 |
+
to command line)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
$HYDRA_CONFIG_GROUPS
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
Use ''--cfg hydra'' to Show the Hydra config.
|
| 65 |
+
|
| 66 |
+
'
|
| 67 |
+
hydra_help: ???
|
| 68 |
+
hydra_logging:
|
| 69 |
+
version: 1
|
| 70 |
+
formatters:
|
| 71 |
+
simple:
|
| 72 |
+
format: '[%(asctime)s][HYDRA] %(message)s'
|
| 73 |
+
handlers:
|
| 74 |
+
console:
|
| 75 |
+
class: logging.StreamHandler
|
| 76 |
+
formatter: simple
|
| 77 |
+
stream: ext://sys.stdout
|
| 78 |
+
root:
|
| 79 |
+
level: INFO
|
| 80 |
+
handlers:
|
| 81 |
+
- console
|
| 82 |
+
loggers:
|
| 83 |
+
logging_example:
|
| 84 |
+
level: DEBUG
|
| 85 |
+
disable_existing_loggers: false
|
| 86 |
+
job_logging:
|
| 87 |
+
version: 1
|
| 88 |
+
formatters:
|
| 89 |
+
simple:
|
| 90 |
+
format: '[%(asctime)s][%(name)s][%(levelname)s] - %(message)s'
|
| 91 |
+
handlers:
|
| 92 |
+
console:
|
| 93 |
+
class: logging.StreamHandler
|
| 94 |
+
formatter: simple
|
| 95 |
+
stream: ext://sys.stdout
|
| 96 |
+
file:
|
| 97 |
+
class: logging.FileHandler
|
| 98 |
+
formatter: simple
|
| 99 |
+
filename: ${hydra.runtime.output_dir}/${hydra.job.name}.log
|
| 100 |
+
root:
|
| 101 |
+
level: INFO
|
| 102 |
+
handlers:
|
| 103 |
+
- console
|
| 104 |
+
- file
|
| 105 |
+
disable_existing_loggers: false
|
| 106 |
+
env: {}
|
| 107 |
+
mode: RUN
|
| 108 |
+
searchpath: []
|
| 109 |
+
callbacks: {}
|
| 110 |
+
output_subdir: .hydra
|
| 111 |
+
overrides:
|
| 112 |
+
hydra:
|
| 113 |
+
- hydra.mode=RUN
|
| 114 |
+
task:
|
| 115 |
+
- algorithm.adv_estimator=grpo
|
| 116 |
+
- data.train_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/train.parquet
|
| 117 |
+
- data.val_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/test.parquet
|
| 118 |
+
- data.train_batch_size=1024
|
| 119 |
+
- data.max_prompt_length=512
|
| 120 |
+
- data.max_response_length=40
|
| 121 |
+
- data.filter_overlong_prompts=True
|
| 122 |
+
- data.truncation=error
|
| 123 |
+
- data.shuffle=False
|
| 124 |
+
- actor_rollout_ref.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 125 |
+
- actor_rollout_ref.actor.optim.lr=1e-6
|
| 126 |
+
- actor_rollout_ref.model.use_remove_padding=True
|
| 127 |
+
- actor_rollout_ref.actor.ppo_mini_batch_size=256
|
| 128 |
+
- actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=32
|
| 129 |
+
- actor_rollout_ref.actor.use_kl_loss=True
|
| 130 |
+
- actor_rollout_ref.actor.kl_loss_coef=0.001
|
| 131 |
+
- actor_rollout_ref.actor.kl_loss_type=low_var_kl
|
| 132 |
+
- actor_rollout_ref.actor.entropy_coeff=0
|
| 133 |
+
- actor_rollout_ref.model.enable_gradient_checkpointing=True
|
| 134 |
+
- actor_rollout_ref.actor.fsdp_config.param_offload=True
|
| 135 |
+
- actor_rollout_ref.actor.fsdp_config.optimizer_offload=False
|
| 136 |
+
- actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32
|
| 137 |
+
- actor_rollout_ref.rollout.tensor_model_parallel_size=2
|
| 138 |
+
- actor_rollout_ref.rollout.name=vllm
|
| 139 |
+
- actor_rollout_ref.rollout.gpu_memory_utilization=0.6
|
| 140 |
+
- actor_rollout_ref.rollout.n=5
|
| 141 |
+
- actor_rollout_ref.rollout.load_format=safetensors
|
| 142 |
+
- actor_rollout_ref.rollout.layered_summon=True
|
| 143 |
+
- actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32
|
| 144 |
+
- actor_rollout_ref.ref.fsdp_config.param_offload=False
|
| 145 |
+
- algorithm.use_kl_in_reward=False
|
| 146 |
+
- reward_model.enable=True
|
| 147 |
+
- reward_model.enable=True
|
| 148 |
+
- reward_model.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/reward_model_converted
|
| 149 |
+
- reward_model.micro_batch_size_per_gpu=32
|
| 150 |
+
- trainer.critic_warmup=0
|
| 151 |
+
- trainer.logger=["console","wandb"]
|
| 152 |
+
- trainer.project_name=verl_grpo_gsm8k
|
| 153 |
+
- trainer.experiment_name=qwen3_4b_gsm8k_grpo
|
| 154 |
+
- trainer.n_gpus_per_node=8
|
| 155 |
+
- trainer.default_local_dir=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/train_output/grpo_0125
|
| 156 |
+
job:
|
| 157 |
+
name: main_ppo
|
| 158 |
+
chdir: null
|
| 159 |
+
override_dirname: actor_rollout_ref.actor.entropy_coeff=0,actor_rollout_ref.actor.fsdp_config.optimizer_offload=False,actor_rollout_ref.actor.fsdp_config.param_offload=True,actor_rollout_ref.actor.kl_loss_coef=0.001,actor_rollout_ref.actor.kl_loss_type=low_var_kl,actor_rollout_ref.actor.optim.lr=1e-6,actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=32,actor_rollout_ref.actor.ppo_mini_batch_size=256,actor_rollout_ref.actor.use_kl_loss=True,actor_rollout_ref.model.enable_gradient_checkpointing=True,actor_rollout_ref.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507,actor_rollout_ref.model.use_remove_padding=True,actor_rollout_ref.ref.fsdp_config.param_offload=False,actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32,actor_rollout_ref.rollout.gpu_memory_utilization=0.6,actor_rollout_ref.rollout.layered_summon=True,actor_rollout_ref.rollout.load_format=safetensors,actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32,actor_rollout_ref.rollout.n=5,actor_rollout_ref.rollout.name=vllm,actor_rollout_ref.rollout.tensor_model_parallel_size=2,algorithm.adv_estimator=grpo,algorithm.use_kl_in_reward=False,data.filter_overlong_prompts=True,data.max_prompt_length=512,data.max_response_length=40,data.shuffle=False,data.train_batch_size=1024,data.train_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/train.parquet,data.truncation=error,data.val_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/test.parquet,reward_model.enable=True,reward_model.enable=True,reward_model.micro_batch_size_per_gpu=32,reward_model.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/reward_model_converted,trainer.critic_warmup=0,trainer.default_local_dir=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/train_output/grpo_0125,trainer.experiment_name=qwen3_4b_gsm8k_grpo,trainer.logger=["console","wandb"],trainer.n_gpus_per_node=8,trainer.project_name=verl_grpo_gsm8k
|
| 160 |
+
id: ???
|
| 161 |
+
num: ???
|
| 162 |
+
config_name: ppo_trainer
|
| 163 |
+
env_set: {}
|
| 164 |
+
env_copy: []
|
| 165 |
+
config:
|
| 166 |
+
override_dirname:
|
| 167 |
+
kv_sep: '='
|
| 168 |
+
item_sep: ','
|
| 169 |
+
exclude_keys: []
|
| 170 |
+
runtime:
|
| 171 |
+
version: 1.3.2
|
| 172 |
+
version_base: '1.3'
|
| 173 |
+
cwd: /mnt/tidal-alsh01/usr/zhangruiqi1/my/verl/examples/grpo_trainer
|
| 174 |
+
config_sources:
|
| 175 |
+
- path: hydra.conf
|
| 176 |
+
schema: pkg
|
| 177 |
+
provider: hydra
|
| 178 |
+
- path: /mnt/tidal-alsh01/usr/zhangruiqi1/my/verl/verl/trainer/config
|
| 179 |
+
schema: file
|
| 180 |
+
provider: main
|
| 181 |
+
- path: ''
|
| 182 |
+
schema: structured
|
| 183 |
+
provider: schema
|
| 184 |
+
output_dir: /mnt/tidal-alsh01/usr/zhangruiqi1/my/verl/examples/grpo_trainer/outputs/2026-01-25/12-31-47
|
| 185 |
+
choices:
|
| 186 |
+
algorithm@algorithm.rollout_correction: rollout_correction
|
| 187 |
+
reward_model: dp_reward_loop
|
| 188 |
+
critic: dp_critic
|
| 189 |
+
critic/../engine@critic.model.fsdp_config: fsdp
|
| 190 |
+
critic/../optim@critic.optim: fsdp
|
| 191 |
+
model@actor_rollout_ref.model: hf_model
|
| 192 |
+
rollout@actor_rollout_ref.rollout: rollout
|
| 193 |
+
ref@actor_rollout_ref.ref: dp_ref
|
| 194 |
+
ref/../engine@actor_rollout_ref.ref.fsdp_config: fsdp
|
| 195 |
+
data: legacy_data
|
| 196 |
+
actor@actor_rollout_ref.actor: dp_actor
|
| 197 |
+
actor/../engine@actor_rollout_ref.actor.fsdp_config: fsdp
|
| 198 |
+
actor/../optim@actor_rollout_ref.actor.optim: fsdp
|
| 199 |
+
hydra/env: default
|
| 200 |
+
hydra/callbacks: null
|
| 201 |
+
hydra/job_logging: default
|
| 202 |
+
hydra/hydra_logging: default
|
| 203 |
+
hydra/hydra_help: default
|
| 204 |
+
hydra/help: default
|
| 205 |
+
hydra/sweeper: basic
|
| 206 |
+
hydra/launcher: basic
|
| 207 |
+
hydra/output: default
|
| 208 |
+
verbose: false
|
examples/grpo_trainer/outputs/2026-01-25/12-35-51/.hydra/hydra.yaml
ADDED
|
@@ -0,0 +1,213 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
hydra:
|
| 2 |
+
run:
|
| 3 |
+
dir: outputs/${now:%Y-%m-%d}/${now:%H-%M-%S}
|
| 4 |
+
sweep:
|
| 5 |
+
dir: multirun/${now:%Y-%m-%d}/${now:%H-%M-%S}
|
| 6 |
+
subdir: ${hydra.job.num}
|
| 7 |
+
launcher:
|
| 8 |
+
_target_: hydra._internal.core_plugins.basic_launcher.BasicLauncher
|
| 9 |
+
sweeper:
|
| 10 |
+
_target_: hydra._internal.core_plugins.basic_sweeper.BasicSweeper
|
| 11 |
+
max_batch_size: null
|
| 12 |
+
params: null
|
| 13 |
+
help:
|
| 14 |
+
app_name: ${hydra.job.name}
|
| 15 |
+
header: '${hydra.help.app_name} is powered by Hydra.
|
| 16 |
+
|
| 17 |
+
'
|
| 18 |
+
footer: 'Powered by Hydra (https://hydra.cc)
|
| 19 |
+
|
| 20 |
+
Use --hydra-help to view Hydra specific help
|
| 21 |
+
|
| 22 |
+
'
|
| 23 |
+
template: '${hydra.help.header}
|
| 24 |
+
|
| 25 |
+
== Configuration groups ==
|
| 26 |
+
|
| 27 |
+
Compose your configuration from those groups (group=option)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
$APP_CONFIG_GROUPS
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
== Config ==
|
| 34 |
+
|
| 35 |
+
Override anything in the config (foo.bar=value)
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
$CONFIG
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
${hydra.help.footer}
|
| 42 |
+
|
| 43 |
+
'
|
| 44 |
+
hydra_help:
|
| 45 |
+
template: 'Hydra (${hydra.runtime.version})
|
| 46 |
+
|
| 47 |
+
See https://hydra.cc for more info.
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
== Flags ==
|
| 51 |
+
|
| 52 |
+
$FLAGS_HELP
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
== Configuration groups ==
|
| 56 |
+
|
| 57 |
+
Compose your configuration from those groups (For example, append hydra/job_logging=disabled
|
| 58 |
+
to command line)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
$HYDRA_CONFIG_GROUPS
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
Use ''--cfg hydra'' to Show the Hydra config.
|
| 65 |
+
|
| 66 |
+
'
|
| 67 |
+
hydra_help: ???
|
| 68 |
+
hydra_logging:
|
| 69 |
+
version: 1
|
| 70 |
+
formatters:
|
| 71 |
+
simple:
|
| 72 |
+
format: '[%(asctime)s][HYDRA] %(message)s'
|
| 73 |
+
handlers:
|
| 74 |
+
console:
|
| 75 |
+
class: logging.StreamHandler
|
| 76 |
+
formatter: simple
|
| 77 |
+
stream: ext://sys.stdout
|
| 78 |
+
root:
|
| 79 |
+
level: INFO
|
| 80 |
+
handlers:
|
| 81 |
+
- console
|
| 82 |
+
loggers:
|
| 83 |
+
logging_example:
|
| 84 |
+
level: DEBUG
|
| 85 |
+
disable_existing_loggers: false
|
| 86 |
+
job_logging:
|
| 87 |
+
version: 1
|
| 88 |
+
formatters:
|
| 89 |
+
simple:
|
| 90 |
+
format: '[%(asctime)s][%(name)s][%(levelname)s] - %(message)s'
|
| 91 |
+
handlers:
|
| 92 |
+
console:
|
| 93 |
+
class: logging.StreamHandler
|
| 94 |
+
formatter: simple
|
| 95 |
+
stream: ext://sys.stdout
|
| 96 |
+
file:
|
| 97 |
+
class: logging.FileHandler
|
| 98 |
+
formatter: simple
|
| 99 |
+
filename: ${hydra.runtime.output_dir}/${hydra.job.name}.log
|
| 100 |
+
root:
|
| 101 |
+
level: INFO
|
| 102 |
+
handlers:
|
| 103 |
+
- console
|
| 104 |
+
- file
|
| 105 |
+
disable_existing_loggers: false
|
| 106 |
+
env: {}
|
| 107 |
+
mode: RUN
|
| 108 |
+
searchpath: []
|
| 109 |
+
callbacks: {}
|
| 110 |
+
output_subdir: .hydra
|
| 111 |
+
overrides:
|
| 112 |
+
hydra:
|
| 113 |
+
- hydra.mode=RUN
|
| 114 |
+
task:
|
| 115 |
+
- algorithm.adv_estimator=grpo
|
| 116 |
+
- data.train_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/train.parquet
|
| 117 |
+
- data.val_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/test.parquet
|
| 118 |
+
- data.train_batch_size=1024
|
| 119 |
+
- data.max_prompt_length=512
|
| 120 |
+
- data.max_response_length=40
|
| 121 |
+
- data.filter_overlong_prompts=True
|
| 122 |
+
- data.truncation=error
|
| 123 |
+
- data.shuffle=False
|
| 124 |
+
- actor_rollout_ref.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 125 |
+
- actor_rollout_ref.actor.optim.lr=1e-6
|
| 126 |
+
- actor_rollout_ref.model.use_remove_padding=True
|
| 127 |
+
- actor_rollout_ref.actor.ppo_mini_batch_size=256
|
| 128 |
+
- actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=32
|
| 129 |
+
- actor_rollout_ref.actor.use_kl_loss=True
|
| 130 |
+
- actor_rollout_ref.actor.kl_loss_coef=0.001
|
| 131 |
+
- actor_rollout_ref.actor.kl_loss_type=low_var_kl
|
| 132 |
+
- actor_rollout_ref.actor.entropy_coeff=0
|
| 133 |
+
- actor_rollout_ref.model.enable_gradient_checkpointing=True
|
| 134 |
+
- actor_rollout_ref.actor.fsdp_config.param_offload=True
|
| 135 |
+
- actor_rollout_ref.actor.fsdp_config.optimizer_offload=False
|
| 136 |
+
- actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32
|
| 137 |
+
- actor_rollout_ref.rollout.tensor_model_parallel_size=2
|
| 138 |
+
- actor_rollout_ref.rollout.name=vllm
|
| 139 |
+
- actor_rollout_ref.rollout.gpu_memory_utilization=0.6
|
| 140 |
+
- actor_rollout_ref.rollout.n=5
|
| 141 |
+
- actor_rollout_ref.rollout.load_format=safetensors
|
| 142 |
+
- actor_rollout_ref.rollout.layered_summon=True
|
| 143 |
+
- actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32
|
| 144 |
+
- actor_rollout_ref.ref.fsdp_config.param_offload=False
|
| 145 |
+
- algorithm.use_kl_in_reward=False
|
| 146 |
+
- reward_model.enable=True
|
| 147 |
+
- reward_model.enable=True
|
| 148 |
+
- reward_model.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/reward_model_converted
|
| 149 |
+
- reward_model.micro_batch_size_per_gpu=32
|
| 150 |
+
- trainer.critic_warmup=0
|
| 151 |
+
- trainer.logger=["console","wandb"]
|
| 152 |
+
- trainer.project_name=verl_grpo_gsm8k
|
| 153 |
+
- trainer.experiment_name=qwen3_4b_gsm8k_grpo
|
| 154 |
+
- trainer.n_gpus_per_node=8
|
| 155 |
+
- trainer.default_local_dir=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/train_output/grpo_0125
|
| 156 |
+
- trainer.nnodes=1
|
| 157 |
+
- trainer.save_freq=20
|
| 158 |
+
- trainer.test_freq=5
|
| 159 |
+
- trainer.total_epochs=15
|
| 160 |
+
- trainer.resume_mode=disable
|
| 161 |
+
job:
|
| 162 |
+
name: main_ppo
|
| 163 |
+
chdir: null
|
| 164 |
+
override_dirname: actor_rollout_ref.actor.entropy_coeff=0,actor_rollout_ref.actor.fsdp_config.optimizer_offload=False,actor_rollout_ref.actor.fsdp_config.param_offload=True,actor_rollout_ref.actor.kl_loss_coef=0.001,actor_rollout_ref.actor.kl_loss_type=low_var_kl,actor_rollout_ref.actor.optim.lr=1e-6,actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=32,actor_rollout_ref.actor.ppo_mini_batch_size=256,actor_rollout_ref.actor.use_kl_loss=True,actor_rollout_ref.model.enable_gradient_checkpointing=True,actor_rollout_ref.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507,actor_rollout_ref.model.use_remove_padding=True,actor_rollout_ref.ref.fsdp_config.param_offload=False,actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32,actor_rollout_ref.rollout.gpu_memory_utilization=0.6,actor_rollout_ref.rollout.layered_summon=True,actor_rollout_ref.rollout.load_format=safetensors,actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32,actor_rollout_ref.rollout.n=5,actor_rollout_ref.rollout.name=vllm,actor_rollout_ref.rollout.tensor_model_parallel_size=2,algorithm.adv_estimator=grpo,algorithm.use_kl_in_reward=False,data.filter_overlong_prompts=True,data.max_prompt_length=512,data.max_response_length=40,data.shuffle=False,data.train_batch_size=1024,data.train_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/train.parquet,data.truncation=error,data.val_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/test.parquet,reward_model.enable=True,reward_model.enable=True,reward_model.micro_batch_size_per_gpu=32,reward_model.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/reward_model_converted,trainer.critic_warmup=0,trainer.default_local_dir=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/train_output/grpo_0125,trainer.experiment_name=qwen3_4b_gsm8k_grpo,trainer.logger=["console","wandb"],trainer.n_gpus_per_node=8,trainer.nnodes=1,trainer.project_name=verl_grpo_gsm8k,trainer.resume_mode=disable,trainer.save_freq=20,trainer.test_freq=5,trainer.total_epochs=15
|
| 165 |
+
id: ???
|
| 166 |
+
num: ???
|
| 167 |
+
config_name: ppo_trainer
|
| 168 |
+
env_set: {}
|
| 169 |
+
env_copy: []
|
| 170 |
+
config:
|
| 171 |
+
override_dirname:
|
| 172 |
+
kv_sep: '='
|
| 173 |
+
item_sep: ','
|
| 174 |
+
exclude_keys: []
|
| 175 |
+
runtime:
|
| 176 |
+
version: 1.3.2
|
| 177 |
+
version_base: '1.3'
|
| 178 |
+
cwd: /mnt/tidal-alsh01/usr/zhangruiqi1/my/verl/examples/grpo_trainer
|
| 179 |
+
config_sources:
|
| 180 |
+
- path: hydra.conf
|
| 181 |
+
schema: pkg
|
| 182 |
+
provider: hydra
|
| 183 |
+
- path: /mnt/tidal-alsh01/usr/zhangruiqi1/my/verl/verl/trainer/config
|
| 184 |
+
schema: file
|
| 185 |
+
provider: main
|
| 186 |
+
- path: ''
|
| 187 |
+
schema: structured
|
| 188 |
+
provider: schema
|
| 189 |
+
output_dir: /mnt/tidal-alsh01/usr/zhangruiqi1/my/verl/examples/grpo_trainer/outputs/2026-01-25/12-35-51
|
| 190 |
+
choices:
|
| 191 |
+
algorithm@algorithm.rollout_correction: rollout_correction
|
| 192 |
+
reward_model: dp_reward_loop
|
| 193 |
+
critic: dp_critic
|
| 194 |
+
critic/../engine@critic.model.fsdp_config: fsdp
|
| 195 |
+
critic/../optim@critic.optim: fsdp
|
| 196 |
+
model@actor_rollout_ref.model: hf_model
|
| 197 |
+
rollout@actor_rollout_ref.rollout: rollout
|
| 198 |
+
ref@actor_rollout_ref.ref: dp_ref
|
| 199 |
+
ref/../engine@actor_rollout_ref.ref.fsdp_config: fsdp
|
| 200 |
+
data: legacy_data
|
| 201 |
+
actor@actor_rollout_ref.actor: dp_actor
|
| 202 |
+
actor/../engine@actor_rollout_ref.actor.fsdp_config: fsdp
|
| 203 |
+
actor/../optim@actor_rollout_ref.actor.optim: fsdp
|
| 204 |
+
hydra/env: default
|
| 205 |
+
hydra/callbacks: null
|
| 206 |
+
hydra/job_logging: default
|
| 207 |
+
hydra/hydra_logging: default
|
| 208 |
+
hydra/hydra_help: default
|
| 209 |
+
hydra/help: default
|
| 210 |
+
hydra/sweeper: basic
|
| 211 |
+
hydra/launcher: basic
|
| 212 |
+
hydra/output: default
|
| 213 |
+
verbose: false
|
examples/grpo_trainer/outputs/2026-01-25/12-36-58/.hydra/hydra.yaml
ADDED
|
@@ -0,0 +1,212 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
hydra:
|
| 2 |
+
run:
|
| 3 |
+
dir: outputs/${now:%Y-%m-%d}/${now:%H-%M-%S}
|
| 4 |
+
sweep:
|
| 5 |
+
dir: multirun/${now:%Y-%m-%d}/${now:%H-%M-%S}
|
| 6 |
+
subdir: ${hydra.job.num}
|
| 7 |
+
launcher:
|
| 8 |
+
_target_: hydra._internal.core_plugins.basic_launcher.BasicLauncher
|
| 9 |
+
sweeper:
|
| 10 |
+
_target_: hydra._internal.core_plugins.basic_sweeper.BasicSweeper
|
| 11 |
+
max_batch_size: null
|
| 12 |
+
params: null
|
| 13 |
+
help:
|
| 14 |
+
app_name: ${hydra.job.name}
|
| 15 |
+
header: '${hydra.help.app_name} is powered by Hydra.
|
| 16 |
+
|
| 17 |
+
'
|
| 18 |
+
footer: 'Powered by Hydra (https://hydra.cc)
|
| 19 |
+
|
| 20 |
+
Use --hydra-help to view Hydra specific help
|
| 21 |
+
|
| 22 |
+
'
|
| 23 |
+
template: '${hydra.help.header}
|
| 24 |
+
|
| 25 |
+
== Configuration groups ==
|
| 26 |
+
|
| 27 |
+
Compose your configuration from those groups (group=option)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
$APP_CONFIG_GROUPS
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
== Config ==
|
| 34 |
+
|
| 35 |
+
Override anything in the config (foo.bar=value)
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
$CONFIG
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
${hydra.help.footer}
|
| 42 |
+
|
| 43 |
+
'
|
| 44 |
+
hydra_help:
|
| 45 |
+
template: 'Hydra (${hydra.runtime.version})
|
| 46 |
+
|
| 47 |
+
See https://hydra.cc for more info.
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
== Flags ==
|
| 51 |
+
|
| 52 |
+
$FLAGS_HELP
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
== Configuration groups ==
|
| 56 |
+
|
| 57 |
+
Compose your configuration from those groups (For example, append hydra/job_logging=disabled
|
| 58 |
+
to command line)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
$HYDRA_CONFIG_GROUPS
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
Use ''--cfg hydra'' to Show the Hydra config.
|
| 65 |
+
|
| 66 |
+
'
|
| 67 |
+
hydra_help: ???
|
| 68 |
+
hydra_logging:
|
| 69 |
+
version: 1
|
| 70 |
+
formatters:
|
| 71 |
+
simple:
|
| 72 |
+
format: '[%(asctime)s][HYDRA] %(message)s'
|
| 73 |
+
handlers:
|
| 74 |
+
console:
|
| 75 |
+
class: logging.StreamHandler
|
| 76 |
+
formatter: simple
|
| 77 |
+
stream: ext://sys.stdout
|
| 78 |
+
root:
|
| 79 |
+
level: INFO
|
| 80 |
+
handlers:
|
| 81 |
+
- console
|
| 82 |
+
loggers:
|
| 83 |
+
logging_example:
|
| 84 |
+
level: DEBUG
|
| 85 |
+
disable_existing_loggers: false
|
| 86 |
+
job_logging:
|
| 87 |
+
version: 1
|
| 88 |
+
formatters:
|
| 89 |
+
simple:
|
| 90 |
+
format: '[%(asctime)s][%(name)s][%(levelname)s] - %(message)s'
|
| 91 |
+
handlers:
|
| 92 |
+
console:
|
| 93 |
+
class: logging.StreamHandler
|
| 94 |
+
formatter: simple
|
| 95 |
+
stream: ext://sys.stdout
|
| 96 |
+
file:
|
| 97 |
+
class: logging.FileHandler
|
| 98 |
+
formatter: simple
|
| 99 |
+
filename: ${hydra.runtime.output_dir}/${hydra.job.name}.log
|
| 100 |
+
root:
|
| 101 |
+
level: INFO
|
| 102 |
+
handlers:
|
| 103 |
+
- console
|
| 104 |
+
- file
|
| 105 |
+
disable_existing_loggers: false
|
| 106 |
+
env: {}
|
| 107 |
+
mode: RUN
|
| 108 |
+
searchpath: []
|
| 109 |
+
callbacks: {}
|
| 110 |
+
output_subdir: .hydra
|
| 111 |
+
overrides:
|
| 112 |
+
hydra:
|
| 113 |
+
- hydra.mode=RUN
|
| 114 |
+
task:
|
| 115 |
+
- algorithm.adv_estimator=grpo
|
| 116 |
+
- data.train_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/train.parquet
|
| 117 |
+
- data.val_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/test.parquet
|
| 118 |
+
- data.train_batch_size=1024
|
| 119 |
+
- data.max_prompt_length=512
|
| 120 |
+
- data.max_response_length=64
|
| 121 |
+
- data.filter_overlong_prompts=True
|
| 122 |
+
- data.truncation=error
|
| 123 |
+
- data.shuffle=False
|
| 124 |
+
- actor_rollout_ref.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 125 |
+
- actor_rollout_ref.actor.optim.lr=1e-6
|
| 126 |
+
- actor_rollout_ref.model.use_remove_padding=True
|
| 127 |
+
- actor_rollout_ref.actor.ppo_mini_batch_size=256
|
| 128 |
+
- actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=32
|
| 129 |
+
- actor_rollout_ref.actor.use_kl_loss=True
|
| 130 |
+
- actor_rollout_ref.actor.kl_loss_coef=0.001
|
| 131 |
+
- actor_rollout_ref.actor.kl_loss_type=low_var_kl
|
| 132 |
+
- actor_rollout_ref.actor.entropy_coeff=0
|
| 133 |
+
- actor_rollout_ref.model.enable_gradient_checkpointing=True
|
| 134 |
+
- actor_rollout_ref.actor.fsdp_config.param_offload=True
|
| 135 |
+
- actor_rollout_ref.actor.fsdp_config.optimizer_offload=False
|
| 136 |
+
- actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32
|
| 137 |
+
- actor_rollout_ref.rollout.tensor_model_parallel_size=2
|
| 138 |
+
- actor_rollout_ref.rollout.name=vllm
|
| 139 |
+
- actor_rollout_ref.rollout.gpu_memory_utilization=0.6
|
| 140 |
+
- actor_rollout_ref.rollout.n=5
|
| 141 |
+
- actor_rollout_ref.rollout.load_format=safetensors
|
| 142 |
+
- actor_rollout_ref.rollout.layered_summon=True
|
| 143 |
+
- actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32
|
| 144 |
+
- actor_rollout_ref.ref.fsdp_config.param_offload=False
|
| 145 |
+
- algorithm.use_kl_in_reward=False
|
| 146 |
+
- reward_model.enable=True
|
| 147 |
+
- reward_model.enable=True
|
| 148 |
+
- reward_model.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/reward_model_converted
|
| 149 |
+
- reward_model.micro_batch_size_per_gpu=32
|
| 150 |
+
- trainer.critic_warmup=0
|
| 151 |
+
- trainer.logger=["console","wandb"]
|
| 152 |
+
- trainer.project_name=verl_grpo_gsm8k
|
| 153 |
+
- trainer.experiment_name=qwen3_4b_gsm8k_grpo
|
| 154 |
+
- trainer.n_gpus_per_node=8
|
| 155 |
+
- trainer.nnodes=1
|
| 156 |
+
- trainer.save_freq=20
|
| 157 |
+
- trainer.test_freq=5
|
| 158 |
+
- trainer.total_epochs=15
|
| 159 |
+
- trainer.resume_mode=disable
|
| 160 |
+
job:
|
| 161 |
+
name: main_ppo
|
| 162 |
+
chdir: null
|
| 163 |
+
override_dirname: actor_rollout_ref.actor.entropy_coeff=0,actor_rollout_ref.actor.fsdp_config.optimizer_offload=False,actor_rollout_ref.actor.fsdp_config.param_offload=True,actor_rollout_ref.actor.kl_loss_coef=0.001,actor_rollout_ref.actor.kl_loss_type=low_var_kl,actor_rollout_ref.actor.optim.lr=1e-6,actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=32,actor_rollout_ref.actor.ppo_mini_batch_size=256,actor_rollout_ref.actor.use_kl_loss=True,actor_rollout_ref.model.enable_gradient_checkpointing=True,actor_rollout_ref.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507,actor_rollout_ref.model.use_remove_padding=True,actor_rollout_ref.ref.fsdp_config.param_offload=False,actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32,actor_rollout_ref.rollout.gpu_memory_utilization=0.6,actor_rollout_ref.rollout.layered_summon=True,actor_rollout_ref.rollout.load_format=safetensors,actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32,actor_rollout_ref.rollout.n=5,actor_rollout_ref.rollout.name=vllm,actor_rollout_ref.rollout.tensor_model_parallel_size=2,algorithm.adv_estimator=grpo,algorithm.use_kl_in_reward=False,data.filter_overlong_prompts=True,data.max_prompt_length=512,data.max_response_length=64,data.shuffle=False,data.train_batch_size=1024,data.train_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/train.parquet,data.truncation=error,data.val_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/test.parquet,reward_model.enable=True,reward_model.enable=True,reward_model.micro_batch_size_per_gpu=32,reward_model.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/reward_model_converted,trainer.critic_warmup=0,trainer.experiment_name=qwen3_4b_gsm8k_grpo,trainer.logger=["console","wandb"],trainer.n_gpus_per_node=8,trainer.nnodes=1,trainer.project_name=verl_grpo_gsm8k,trainer.resume_mode=disable,trainer.save_freq=20,trainer.test_freq=5,trainer.total_epochs=15
|
| 164 |
+
id: ???
|
| 165 |
+
num: ???
|
| 166 |
+
config_name: ppo_trainer
|
| 167 |
+
env_set: {}
|
| 168 |
+
env_copy: []
|
| 169 |
+
config:
|
| 170 |
+
override_dirname:
|
| 171 |
+
kv_sep: '='
|
| 172 |
+
item_sep: ','
|
| 173 |
+
exclude_keys: []
|
| 174 |
+
runtime:
|
| 175 |
+
version: 1.3.2
|
| 176 |
+
version_base: '1.3'
|
| 177 |
+
cwd: /mnt/tidal-alsh01/usr/zhangruiqi1/my/verl/examples/grpo_trainer
|
| 178 |
+
config_sources:
|
| 179 |
+
- path: hydra.conf
|
| 180 |
+
schema: pkg
|
| 181 |
+
provider: hydra
|
| 182 |
+
- path: /mnt/tidal-alsh01/usr/zhangruiqi1/my/verl/verl/trainer/config
|
| 183 |
+
schema: file
|
| 184 |
+
provider: main
|
| 185 |
+
- path: ''
|
| 186 |
+
schema: structured
|
| 187 |
+
provider: schema
|
| 188 |
+
output_dir: /mnt/tidal-alsh01/usr/zhangruiqi1/my/verl/examples/grpo_trainer/outputs/2026-01-25/12-36-58
|
| 189 |
+
choices:
|
| 190 |
+
algorithm@algorithm.rollout_correction: rollout_correction
|
| 191 |
+
reward_model: dp_reward_loop
|
| 192 |
+
critic: dp_critic
|
| 193 |
+
critic/../engine@critic.model.fsdp_config: fsdp
|
| 194 |
+
critic/../optim@critic.optim: fsdp
|
| 195 |
+
model@actor_rollout_ref.model: hf_model
|
| 196 |
+
rollout@actor_rollout_ref.rollout: rollout
|
| 197 |
+
ref@actor_rollout_ref.ref: dp_ref
|
| 198 |
+
ref/../engine@actor_rollout_ref.ref.fsdp_config: fsdp
|
| 199 |
+
data: legacy_data
|
| 200 |
+
actor@actor_rollout_ref.actor: dp_actor
|
| 201 |
+
actor/../engine@actor_rollout_ref.actor.fsdp_config: fsdp
|
| 202 |
+
actor/../optim@actor_rollout_ref.actor.optim: fsdp
|
| 203 |
+
hydra/env: default
|
| 204 |
+
hydra/callbacks: null
|
| 205 |
+
hydra/job_logging: default
|
| 206 |
+
hydra/hydra_logging: default
|
| 207 |
+
hydra/hydra_help: default
|
| 208 |
+
hydra/help: default
|
| 209 |
+
hydra/sweeper: basic
|
| 210 |
+
hydra/launcher: basic
|
| 211 |
+
hydra/output: default
|
| 212 |
+
verbose: false
|
examples/grpo_trainer/outputs/2026-01-25/12-38-17/.hydra/overrides.yaml
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
- algorithm.adv_estimator=grpo
|
| 2 |
+
- data.train_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/train.parquet
|
| 3 |
+
- data.val_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/test.parquet
|
| 4 |
+
- data.train_batch_size=1024
|
| 5 |
+
- data.max_prompt_length=512
|
| 6 |
+
- data.max_response_length=64
|
| 7 |
+
- data.filter_overlong_prompts=True
|
| 8 |
+
- data.truncation=error
|
| 9 |
+
- data.shuffle=False
|
| 10 |
+
- actor_rollout_ref.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 11 |
+
- actor_rollout_ref.actor.optim.lr=1e-6
|
| 12 |
+
- actor_rollout_ref.model.use_remove_padding=True
|
| 13 |
+
- actor_rollout_ref.actor.ppo_mini_batch_size=256
|
| 14 |
+
- actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=32
|
| 15 |
+
- actor_rollout_ref.actor.use_kl_loss=True
|
| 16 |
+
- actor_rollout_ref.actor.kl_loss_coef=0.001
|
| 17 |
+
- actor_rollout_ref.actor.kl_loss_type=low_var_kl
|
| 18 |
+
- actor_rollout_ref.actor.entropy_coeff=0
|
| 19 |
+
- actor_rollout_ref.model.enable_gradient_checkpointing=True
|
| 20 |
+
- actor_rollout_ref.actor.fsdp_config.param_offload=True
|
| 21 |
+
- actor_rollout_ref.actor.fsdp_config.optimizer_offload=False
|
| 22 |
+
- actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32
|
| 23 |
+
- actor_rollout_ref.rollout.tensor_model_parallel_size=2
|
| 24 |
+
- actor_rollout_ref.rollout.name=vllm
|
| 25 |
+
- actor_rollout_ref.rollout.gpu_memory_utilization=0.6
|
| 26 |
+
- actor_rollout_ref.rollout.n=5
|
| 27 |
+
- actor_rollout_ref.rollout.load_format=safetensors
|
| 28 |
+
- actor_rollout_ref.rollout.layered_summon=True
|
| 29 |
+
- actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32
|
| 30 |
+
- actor_rollout_ref.ref.fsdp_config.param_offload=False
|
| 31 |
+
- algorithm.use_kl_in_reward=False
|
| 32 |
+
- reward_model.enable=True
|
| 33 |
+
- reward_model.enable=True
|
| 34 |
+
- reward_model.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/reward_model_converted
|
| 35 |
+
- reward_model.micro_batch_size_per_gpu=32
|
| 36 |
+
- trainer.critic_warmup=0
|
| 37 |
+
- trainer.logger=["console","wandb"]
|
| 38 |
+
- trainer.project_name=verl_grpo_gsm8k
|
| 39 |
+
- trainer.experiment_name=qwen3_4b_gsm8k_grpo
|
| 40 |
+
- trainer.n_gpus_per_node=8
|
| 41 |
+
- trainer.nnodes=1
|
| 42 |
+
- trainer.save_freq=20
|
| 43 |
+
- trainer.test_freq=5
|
| 44 |
+
- trainer.total_epochs=15
|
| 45 |
+
- trainer.resume_mode=disable
|
examples/grpo_trainer/outputs/2026-01-25/12-39-19/.hydra/config.yaml
ADDED
|
@@ -0,0 +1,610 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
actor_rollout_ref:
|
| 2 |
+
actor:
|
| 3 |
+
optim:
|
| 4 |
+
_target_: verl.workers.config.FSDPOptimizerConfig
|
| 5 |
+
optimizer: AdamW
|
| 6 |
+
optimizer_impl: torch.optim
|
| 7 |
+
lr: 1.0e-06
|
| 8 |
+
lr_warmup_steps_ratio: 0.0
|
| 9 |
+
total_training_steps: -1
|
| 10 |
+
weight_decay: 0.01
|
| 11 |
+
lr_warmup_steps: -1
|
| 12 |
+
betas:
|
| 13 |
+
- 0.9
|
| 14 |
+
- 0.999
|
| 15 |
+
clip_grad: 1.0
|
| 16 |
+
min_lr_ratio: 0.0
|
| 17 |
+
num_cycles: 0.5
|
| 18 |
+
lr_scheduler_type: constant
|
| 19 |
+
warmup_style: null
|
| 20 |
+
override_optimizer_config: null
|
| 21 |
+
fsdp_config:
|
| 22 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 23 |
+
wrap_policy:
|
| 24 |
+
min_num_params: 0
|
| 25 |
+
param_offload: true
|
| 26 |
+
optimizer_offload: false
|
| 27 |
+
offload_policy: false
|
| 28 |
+
reshard_after_forward: true
|
| 29 |
+
fsdp_size: -1
|
| 30 |
+
forward_prefetch: false
|
| 31 |
+
model_dtype: fp32
|
| 32 |
+
use_orig_params: false
|
| 33 |
+
seed: 42
|
| 34 |
+
full_determinism: false
|
| 35 |
+
ulysses_sequence_parallel_size: 1
|
| 36 |
+
entropy_from_logits_with_chunking: false
|
| 37 |
+
use_torch_compile: true
|
| 38 |
+
entropy_checkpointing: false
|
| 39 |
+
forward_only: false
|
| 40 |
+
strategy: fsdp
|
| 41 |
+
dtype: bfloat16
|
| 42 |
+
_target_: verl.workers.config.FSDPActorConfig
|
| 43 |
+
rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
|
| 44 |
+
strategy: fsdp
|
| 45 |
+
ppo_mini_batch_size: 256
|
| 46 |
+
ppo_micro_batch_size: null
|
| 47 |
+
ppo_micro_batch_size_per_gpu: 32
|
| 48 |
+
use_dynamic_bsz: false
|
| 49 |
+
ppo_max_token_len_per_gpu: 16384
|
| 50 |
+
clip_ratio: 0.2
|
| 51 |
+
clip_ratio_low: 0.2
|
| 52 |
+
clip_ratio_high: 0.2
|
| 53 |
+
freeze_vision_tower: false
|
| 54 |
+
policy_loss:
|
| 55 |
+
_target_: verl.workers.config.PolicyLossConfig
|
| 56 |
+
loss_mode: vanilla
|
| 57 |
+
clip_cov_ratio: 0.0002
|
| 58 |
+
clip_cov_lb: 1.0
|
| 59 |
+
clip_cov_ub: 5.0
|
| 60 |
+
kl_cov_ratio: 0.0002
|
| 61 |
+
ppo_kl_coef: 0.1
|
| 62 |
+
clip_ratio_c: 3.0
|
| 63 |
+
loss_agg_mode: token-mean
|
| 64 |
+
loss_scale_factor: null
|
| 65 |
+
entropy_coeff: 0
|
| 66 |
+
calculate_entropy: false
|
| 67 |
+
use_kl_loss: true
|
| 68 |
+
use_torch_compile: true
|
| 69 |
+
kl_loss_coef: 0.001
|
| 70 |
+
kl_loss_type: low_var_kl
|
| 71 |
+
ppo_epochs: 1
|
| 72 |
+
shuffle: false
|
| 73 |
+
checkpoint:
|
| 74 |
+
_target_: verl.trainer.config.CheckpointConfig
|
| 75 |
+
save_contents:
|
| 76 |
+
- model
|
| 77 |
+
- optimizer
|
| 78 |
+
- extra
|
| 79 |
+
load_contents: ${.save_contents}
|
| 80 |
+
async_save: false
|
| 81 |
+
use_fused_kernels: ${oc.select:actor_rollout_ref.model.use_fused_kernels,false}
|
| 82 |
+
profiler:
|
| 83 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 84 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 85 |
+
enable: false
|
| 86 |
+
all_ranks: false
|
| 87 |
+
ranks: []
|
| 88 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 89 |
+
tool_config:
|
| 90 |
+
nsys:
|
| 91 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 92 |
+
discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
|
| 93 |
+
npu:
|
| 94 |
+
_target_: verl.utils.profiler.config.NPUToolConfig
|
| 95 |
+
contents: []
|
| 96 |
+
level: level1
|
| 97 |
+
analysis: true
|
| 98 |
+
discrete: false
|
| 99 |
+
torch:
|
| 100 |
+
_target_: verl.utils.profiler.config.TorchProfilerToolConfig
|
| 101 |
+
step_start: 0
|
| 102 |
+
step_end: null
|
| 103 |
+
torch_memory:
|
| 104 |
+
_target_: verl.utils.profiler.config.TorchMemoryToolConfig
|
| 105 |
+
trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
|
| 106 |
+
stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
|
| 107 |
+
router_replay:
|
| 108 |
+
_target_: verl.workers.config.RouterReplayConfig
|
| 109 |
+
mode: disabled
|
| 110 |
+
record_file: null
|
| 111 |
+
replay_file: null
|
| 112 |
+
grad_clip: 1.0
|
| 113 |
+
ulysses_sequence_parallel_size: 1
|
| 114 |
+
entropy_from_logits_with_chunking: false
|
| 115 |
+
entropy_checkpointing: false
|
| 116 |
+
use_remove_padding: ${oc.select:actor_rollout_ref.model.use_remove_padding,false}
|
| 117 |
+
ref:
|
| 118 |
+
rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
|
| 119 |
+
strategy: ${actor_rollout_ref.actor.strategy}
|
| 120 |
+
use_torch_compile: ${oc.select:actor_rollout_ref.actor.use_torch_compile,true}
|
| 121 |
+
log_prob_micro_batch_size: null
|
| 122 |
+
log_prob_micro_batch_size_per_gpu: 32
|
| 123 |
+
log_prob_use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
|
| 124 |
+
log_prob_max_token_len_per_gpu: ${oc.select:actor_rollout_ref.actor.ppo_max_token_len_per_gpu,16384}
|
| 125 |
+
profiler:
|
| 126 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 127 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 128 |
+
enable: false
|
| 129 |
+
all_ranks: false
|
| 130 |
+
ranks: []
|
| 131 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 132 |
+
tool_config:
|
| 133 |
+
nsys:
|
| 134 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 135 |
+
discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
|
| 136 |
+
npu:
|
| 137 |
+
_target_: verl.utils.profiler.config.NPUToolConfig
|
| 138 |
+
contents: []
|
| 139 |
+
level: level1
|
| 140 |
+
analysis: true
|
| 141 |
+
discrete: false
|
| 142 |
+
torch:
|
| 143 |
+
_target_: verl.utils.profiler.config.TorchProfilerToolConfig
|
| 144 |
+
step_start: 0
|
| 145 |
+
step_end: null
|
| 146 |
+
torch_memory:
|
| 147 |
+
_target_: verl.utils.profiler.config.TorchMemoryToolConfig
|
| 148 |
+
trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
|
| 149 |
+
stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
|
| 150 |
+
router_replay:
|
| 151 |
+
_target_: verl.workers.config.RouterReplayConfig
|
| 152 |
+
mode: disabled
|
| 153 |
+
record_file: null
|
| 154 |
+
replay_file: null
|
| 155 |
+
fsdp_config:
|
| 156 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 157 |
+
wrap_policy:
|
| 158 |
+
min_num_params: 0
|
| 159 |
+
param_offload: false
|
| 160 |
+
optimizer_offload: false
|
| 161 |
+
offload_policy: false
|
| 162 |
+
reshard_after_forward: true
|
| 163 |
+
fsdp_size: -1
|
| 164 |
+
forward_prefetch: false
|
| 165 |
+
model_dtype: fp32
|
| 166 |
+
use_orig_params: false
|
| 167 |
+
seed: 42
|
| 168 |
+
full_determinism: false
|
| 169 |
+
ulysses_sequence_parallel_size: 1
|
| 170 |
+
entropy_from_logits_with_chunking: false
|
| 171 |
+
use_torch_compile: true
|
| 172 |
+
entropy_checkpointing: false
|
| 173 |
+
forward_only: true
|
| 174 |
+
strategy: fsdp
|
| 175 |
+
dtype: bfloat16
|
| 176 |
+
_target_: verl.workers.config.FSDPActorConfig
|
| 177 |
+
ulysses_sequence_parallel_size: ${oc.select:actor_rollout_ref.actor.ulysses_sequence_parallel_size,1}
|
| 178 |
+
entropy_from_logits_with_chunking: false
|
| 179 |
+
entropy_checkpointing: false
|
| 180 |
+
rollout:
|
| 181 |
+
_target_: verl.workers.config.RolloutConfig
|
| 182 |
+
name: vllm
|
| 183 |
+
mode: async
|
| 184 |
+
temperature: 1.0
|
| 185 |
+
top_k: -1
|
| 186 |
+
top_p: 1
|
| 187 |
+
prompt_length: ${oc.select:data.max_prompt_length,512}
|
| 188 |
+
response_length: ${oc.select:data.max_response_length,512}
|
| 189 |
+
dtype: bfloat16
|
| 190 |
+
gpu_memory_utilization: 0.6
|
| 191 |
+
ignore_eos: false
|
| 192 |
+
enforce_eager: false
|
| 193 |
+
cudagraph_capture_sizes: null
|
| 194 |
+
free_cache_engine: true
|
| 195 |
+
tensor_model_parallel_size: 2
|
| 196 |
+
data_parallel_size: 1
|
| 197 |
+
expert_parallel_size: 1
|
| 198 |
+
pipeline_model_parallel_size: 1
|
| 199 |
+
max_num_batched_tokens: 8192
|
| 200 |
+
max_model_len: null
|
| 201 |
+
max_num_seqs: 1024
|
| 202 |
+
enable_chunked_prefill: true
|
| 203 |
+
enable_prefix_caching: true
|
| 204 |
+
load_format: safetensors
|
| 205 |
+
log_prob_micro_batch_size: null
|
| 206 |
+
log_prob_micro_batch_size_per_gpu: 32
|
| 207 |
+
log_prob_use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
|
| 208 |
+
log_prob_max_token_len_per_gpu: ${oc.select:actor_rollout_ref.actor.ppo_max_token_len_per_gpu,16384}
|
| 209 |
+
disable_log_stats: true
|
| 210 |
+
do_sample: true
|
| 211 |
+
'n': 5
|
| 212 |
+
over_sample_rate: 0
|
| 213 |
+
multi_stage_wake_up: false
|
| 214 |
+
engine_kwargs:
|
| 215 |
+
vllm: {}
|
| 216 |
+
sglang: {}
|
| 217 |
+
val_kwargs:
|
| 218 |
+
_target_: verl.workers.config.SamplingConfig
|
| 219 |
+
top_k: -1
|
| 220 |
+
top_p: 1.0
|
| 221 |
+
temperature: 0
|
| 222 |
+
'n': 1
|
| 223 |
+
do_sample: false
|
| 224 |
+
multi_turn:
|
| 225 |
+
_target_: verl.workers.config.MultiTurnConfig
|
| 226 |
+
enable: false
|
| 227 |
+
max_assistant_turns: null
|
| 228 |
+
tool_config_path: null
|
| 229 |
+
max_user_turns: null
|
| 230 |
+
max_parallel_calls: 1
|
| 231 |
+
max_tool_response_length: 256
|
| 232 |
+
tool_response_truncate_side: middle
|
| 233 |
+
interaction_config_path: null
|
| 234 |
+
use_inference_chat_template: false
|
| 235 |
+
tokenization_sanity_check_mode: strict
|
| 236 |
+
format: hermes
|
| 237 |
+
num_repeat_rollouts: null
|
| 238 |
+
calculate_log_probs: false
|
| 239 |
+
agent:
|
| 240 |
+
_target_: verl.workers.config.AgentLoopConfig
|
| 241 |
+
num_workers: 8
|
| 242 |
+
default_agent_loop: single_turn_agent
|
| 243 |
+
agent_loop_config_path: null
|
| 244 |
+
custom_async_server:
|
| 245 |
+
_target_: verl.workers.config.CustomAsyncServerConfig
|
| 246 |
+
path: null
|
| 247 |
+
name: null
|
| 248 |
+
update_weights_bucket_megabytes: 512
|
| 249 |
+
trace:
|
| 250 |
+
_target_: verl.workers.config.TraceConfig
|
| 251 |
+
backend: null
|
| 252 |
+
token2text: false
|
| 253 |
+
max_samples_per_step_per_worker: null
|
| 254 |
+
skip_rollout: false
|
| 255 |
+
skip_dump_dir: /tmp/rollout_dump
|
| 256 |
+
skip_tokenizer_init: true
|
| 257 |
+
enable_rollout_routing_replay: false
|
| 258 |
+
profiler:
|
| 259 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 260 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 261 |
+
enable: ${oc.select:actor_rollout_ref.actor.profiler.enable,false}
|
| 262 |
+
all_ranks: ${oc.select:actor_rollout_ref.actor.profiler.all_ranks,false}
|
| 263 |
+
ranks: ${oc.select:actor_rollout_ref.actor.profiler.ranks,[]}
|
| 264 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 265 |
+
tool_config: ${oc.select:actor_rollout_ref.actor.profiler.tool_config,null}
|
| 266 |
+
prometheus:
|
| 267 |
+
_target_: verl.workers.config.PrometheusConfig
|
| 268 |
+
enable: false
|
| 269 |
+
port: 9090
|
| 270 |
+
file: /tmp/ray/session_latest/metrics/prometheus/prometheus.yml
|
| 271 |
+
served_model_name: ${oc.select:actor_rollout_ref.model.path,null}
|
| 272 |
+
layered_summon: true
|
| 273 |
+
model:
|
| 274 |
+
_target_: verl.workers.config.HFModelConfig
|
| 275 |
+
path: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 276 |
+
hf_config_path: null
|
| 277 |
+
tokenizer_path: null
|
| 278 |
+
use_shm: false
|
| 279 |
+
trust_remote_code: false
|
| 280 |
+
custom_chat_template: null
|
| 281 |
+
external_lib: null
|
| 282 |
+
override_config: {}
|
| 283 |
+
enable_gradient_checkpointing: true
|
| 284 |
+
enable_activation_offload: false
|
| 285 |
+
use_remove_padding: true
|
| 286 |
+
lora_rank: 0
|
| 287 |
+
lora_alpha: 16
|
| 288 |
+
target_modules: all-linear
|
| 289 |
+
exclude_modules: null
|
| 290 |
+
lora_adapter_path: null
|
| 291 |
+
use_liger: false
|
| 292 |
+
use_fused_kernels: false
|
| 293 |
+
fused_kernel_options:
|
| 294 |
+
impl_backend: torch
|
| 295 |
+
hybrid_engine: true
|
| 296 |
+
nccl_timeout: 600
|
| 297 |
+
data:
|
| 298 |
+
tokenizer: null
|
| 299 |
+
use_shm: false
|
| 300 |
+
train_files: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/train.parquet
|
| 301 |
+
val_files: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/test.parquet
|
| 302 |
+
train_max_samples: -1
|
| 303 |
+
val_max_samples: -1
|
| 304 |
+
prompt_key: prompt
|
| 305 |
+
reward_fn_key: data_source
|
| 306 |
+
max_prompt_length: 512
|
| 307 |
+
max_response_length: 64
|
| 308 |
+
train_batch_size: 1024
|
| 309 |
+
val_batch_size: null
|
| 310 |
+
tool_config_path: ${oc.select:actor_rollout_ref.rollout.multi_turn.tool_config_path,
|
| 311 |
+
null}
|
| 312 |
+
return_raw_input_ids: false
|
| 313 |
+
return_raw_chat: true
|
| 314 |
+
return_full_prompt: false
|
| 315 |
+
shuffle: false
|
| 316 |
+
seed: null
|
| 317 |
+
dataloader_num_workers: 8
|
| 318 |
+
image_patch_size: 14
|
| 319 |
+
validation_shuffle: false
|
| 320 |
+
filter_overlong_prompts: true
|
| 321 |
+
filter_overlong_prompts_workers: 1
|
| 322 |
+
truncation: error
|
| 323 |
+
image_key: images
|
| 324 |
+
video_key: videos
|
| 325 |
+
trust_remote_code: false
|
| 326 |
+
custom_cls:
|
| 327 |
+
path: null
|
| 328 |
+
name: null
|
| 329 |
+
return_multi_modal_inputs: true
|
| 330 |
+
sampler:
|
| 331 |
+
class_path: null
|
| 332 |
+
class_name: null
|
| 333 |
+
datagen:
|
| 334 |
+
path: null
|
| 335 |
+
name: null
|
| 336 |
+
apply_chat_template_kwargs: {}
|
| 337 |
+
reward_manager:
|
| 338 |
+
_target_: verl.trainer.config.config.RewardManagerConfig
|
| 339 |
+
source: register
|
| 340 |
+
name: ${oc.select:reward_model.reward_manager,naive}
|
| 341 |
+
module:
|
| 342 |
+
_target_: verl.trainer.config.config.ModuleConfig
|
| 343 |
+
path: null
|
| 344 |
+
name: custom_reward_manager
|
| 345 |
+
critic:
|
| 346 |
+
optim:
|
| 347 |
+
_target_: verl.workers.config.FSDPOptimizerConfig
|
| 348 |
+
optimizer: AdamW
|
| 349 |
+
optimizer_impl: torch.optim
|
| 350 |
+
lr: 1.0e-05
|
| 351 |
+
lr_warmup_steps_ratio: 0.0
|
| 352 |
+
total_training_steps: -1
|
| 353 |
+
weight_decay: 0.01
|
| 354 |
+
lr_warmup_steps: -1
|
| 355 |
+
betas:
|
| 356 |
+
- 0.9
|
| 357 |
+
- 0.999
|
| 358 |
+
clip_grad: 1.0
|
| 359 |
+
min_lr_ratio: 0.0
|
| 360 |
+
num_cycles: 0.5
|
| 361 |
+
lr_scheduler_type: constant
|
| 362 |
+
warmup_style: null
|
| 363 |
+
override_optimizer_config: null
|
| 364 |
+
model:
|
| 365 |
+
fsdp_config:
|
| 366 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 367 |
+
wrap_policy:
|
| 368 |
+
min_num_params: 0
|
| 369 |
+
param_offload: false
|
| 370 |
+
optimizer_offload: false
|
| 371 |
+
offload_policy: false
|
| 372 |
+
reshard_after_forward: true
|
| 373 |
+
fsdp_size: -1
|
| 374 |
+
forward_prefetch: false
|
| 375 |
+
model_dtype: fp32
|
| 376 |
+
use_orig_params: false
|
| 377 |
+
seed: 42
|
| 378 |
+
full_determinism: false
|
| 379 |
+
ulysses_sequence_parallel_size: 1
|
| 380 |
+
entropy_from_logits_with_chunking: false
|
| 381 |
+
use_torch_compile: true
|
| 382 |
+
entropy_checkpointing: false
|
| 383 |
+
forward_only: false
|
| 384 |
+
strategy: fsdp
|
| 385 |
+
dtype: bfloat16
|
| 386 |
+
path: ~/models/deepseek-llm-7b-chat
|
| 387 |
+
tokenizer_path: ${oc.select:actor_rollout_ref.model.path,"~/models/deepseek-llm-7b-chat"}
|
| 388 |
+
override_config: {}
|
| 389 |
+
external_lib: ${oc.select:actor_rollout_ref.model.external_lib,null}
|
| 390 |
+
trust_remote_code: ${oc.select:actor_rollout_ref.model.trust_remote_code,false}
|
| 391 |
+
_target_: verl.workers.config.FSDPCriticModelCfg
|
| 392 |
+
use_shm: false
|
| 393 |
+
enable_gradient_checkpointing: true
|
| 394 |
+
enable_activation_offload: false
|
| 395 |
+
use_remove_padding: false
|
| 396 |
+
lora_rank: 0
|
| 397 |
+
lora_alpha: 16
|
| 398 |
+
target_modules: all-linear
|
| 399 |
+
_target_: verl.workers.config.FSDPCriticConfig
|
| 400 |
+
rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
|
| 401 |
+
strategy: fsdp
|
| 402 |
+
enable: null
|
| 403 |
+
ppo_mini_batch_size: ${oc.select:actor_rollout_ref.actor.ppo_mini_batch_size,256}
|
| 404 |
+
ppo_micro_batch_size: null
|
| 405 |
+
ppo_micro_batch_size_per_gpu: ${oc.select:.ppo_micro_batch_size,null}
|
| 406 |
+
use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
|
| 407 |
+
ppo_max_token_len_per_gpu: 32768
|
| 408 |
+
forward_max_token_len_per_gpu: ${.ppo_max_token_len_per_gpu}
|
| 409 |
+
ppo_epochs: ${oc.select:actor_rollout_ref.actor.ppo_epochs,1}
|
| 410 |
+
shuffle: ${oc.select:actor_rollout_ref.actor.shuffle,false}
|
| 411 |
+
cliprange_value: 0.5
|
| 412 |
+
loss_agg_mode: ${oc.select:actor_rollout_ref.actor.loss_agg_mode,token-mean}
|
| 413 |
+
checkpoint:
|
| 414 |
+
_target_: verl.trainer.config.CheckpointConfig
|
| 415 |
+
save_contents:
|
| 416 |
+
- model
|
| 417 |
+
- optimizer
|
| 418 |
+
- extra
|
| 419 |
+
load_contents: ${.save_contents}
|
| 420 |
+
async_save: false
|
| 421 |
+
profiler:
|
| 422 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 423 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 424 |
+
enable: false
|
| 425 |
+
all_ranks: false
|
| 426 |
+
ranks: []
|
| 427 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 428 |
+
tool_config:
|
| 429 |
+
nsys:
|
| 430 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 431 |
+
discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
|
| 432 |
+
npu:
|
| 433 |
+
_target_: verl.utils.profiler.config.NPUToolConfig
|
| 434 |
+
contents: []
|
| 435 |
+
level: level1
|
| 436 |
+
analysis: true
|
| 437 |
+
discrete: false
|
| 438 |
+
torch:
|
| 439 |
+
_target_: verl.utils.profiler.config.TorchProfilerToolConfig
|
| 440 |
+
step_start: 0
|
| 441 |
+
step_end: null
|
| 442 |
+
torch_memory:
|
| 443 |
+
_target_: verl.utils.profiler.config.TorchMemoryToolConfig
|
| 444 |
+
trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
|
| 445 |
+
stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
|
| 446 |
+
forward_micro_batch_size: ${oc.select:.ppo_micro_batch_size,null}
|
| 447 |
+
forward_micro_batch_size_per_gpu: ${oc.select:.ppo_micro_batch_size_per_gpu,null}
|
| 448 |
+
ulysses_sequence_parallel_size: 1
|
| 449 |
+
grad_clip: 1.0
|
| 450 |
+
reward_model:
|
| 451 |
+
enable: true
|
| 452 |
+
enable_resource_pool: false
|
| 453 |
+
n_gpus_per_node: 0
|
| 454 |
+
nnodes: 0
|
| 455 |
+
strategy: fsdp
|
| 456 |
+
model:
|
| 457 |
+
input_tokenizer: ${actor_rollout_ref.model.path}
|
| 458 |
+
path: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/reward_model_converted
|
| 459 |
+
external_lib: ${actor_rollout_ref.model.external_lib}
|
| 460 |
+
trust_remote_code: false
|
| 461 |
+
override_config: {}
|
| 462 |
+
use_shm: false
|
| 463 |
+
use_remove_padding: false
|
| 464 |
+
use_fused_kernels: ${actor_rollout_ref.model.use_fused_kernels}
|
| 465 |
+
fsdp_config:
|
| 466 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 467 |
+
wrap_policy:
|
| 468 |
+
min_num_params: 0
|
| 469 |
+
param_offload: false
|
| 470 |
+
reshard_after_forward: true
|
| 471 |
+
fsdp_size: -1
|
| 472 |
+
forward_prefetch: false
|
| 473 |
+
micro_batch_size: null
|
| 474 |
+
micro_batch_size_per_gpu: 32
|
| 475 |
+
max_length: null
|
| 476 |
+
use_dynamic_bsz: ${critic.use_dynamic_bsz}
|
| 477 |
+
forward_max_token_len_per_gpu: ${critic.forward_max_token_len_per_gpu}
|
| 478 |
+
reward_manager: naive
|
| 479 |
+
launch_reward_fn_async: false
|
| 480 |
+
sandbox_fusion:
|
| 481 |
+
url: null
|
| 482 |
+
max_concurrent: 64
|
| 483 |
+
memory_limit_mb: 1024
|
| 484 |
+
profiler:
|
| 485 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 486 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 487 |
+
enable: false
|
| 488 |
+
all_ranks: false
|
| 489 |
+
ranks: []
|
| 490 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 491 |
+
tool_config: ${oc.select:actor_rollout_ref.actor.profiler.tool_config,null}
|
| 492 |
+
ulysses_sequence_parallel_size: 1
|
| 493 |
+
use_reward_loop: true
|
| 494 |
+
rollout:
|
| 495 |
+
_target_: verl.workers.config.RolloutConfig
|
| 496 |
+
name: ???
|
| 497 |
+
dtype: bfloat16
|
| 498 |
+
gpu_memory_utilization: 0.5
|
| 499 |
+
enforce_eager: true
|
| 500 |
+
cudagraph_capture_sizes: null
|
| 501 |
+
free_cache_engine: true
|
| 502 |
+
data_parallel_size: 1
|
| 503 |
+
expert_parallel_size: 1
|
| 504 |
+
tensor_model_parallel_size: 2
|
| 505 |
+
max_num_batched_tokens: 8192
|
| 506 |
+
max_model_len: null
|
| 507 |
+
max_num_seqs: 1024
|
| 508 |
+
load_format: auto
|
| 509 |
+
engine_kwargs: {}
|
| 510 |
+
limit_images: null
|
| 511 |
+
enable_chunked_prefill: true
|
| 512 |
+
enable_prefix_caching: true
|
| 513 |
+
disable_log_stats: true
|
| 514 |
+
skip_tokenizer_init: true
|
| 515 |
+
prompt_length: 512
|
| 516 |
+
response_length: 512
|
| 517 |
+
algorithm:
|
| 518 |
+
rollout_correction:
|
| 519 |
+
rollout_is: null
|
| 520 |
+
rollout_is_threshold: 2.0
|
| 521 |
+
rollout_rs: null
|
| 522 |
+
rollout_rs_threshold: null
|
| 523 |
+
rollout_rs_threshold_lower: null
|
| 524 |
+
rollout_token_veto_threshold: null
|
| 525 |
+
bypass_mode: false
|
| 526 |
+
use_policy_gradient: false
|
| 527 |
+
rollout_is_batch_normalize: false
|
| 528 |
+
_target_: verl.trainer.config.AlgoConfig
|
| 529 |
+
gamma: 1.0
|
| 530 |
+
lam: 1.0
|
| 531 |
+
adv_estimator: grpo
|
| 532 |
+
norm_adv_by_std_in_grpo: true
|
| 533 |
+
use_kl_in_reward: false
|
| 534 |
+
kl_penalty: kl
|
| 535 |
+
kl_ctrl:
|
| 536 |
+
_target_: verl.trainer.config.KLControlConfig
|
| 537 |
+
type: fixed
|
| 538 |
+
kl_coef: 0.001
|
| 539 |
+
horizon: 10000
|
| 540 |
+
target_kl: 0.1
|
| 541 |
+
use_pf_ppo: false
|
| 542 |
+
pf_ppo:
|
| 543 |
+
reweight_method: pow
|
| 544 |
+
weight_pow: 2.0
|
| 545 |
+
custom_reward_function:
|
| 546 |
+
path: null
|
| 547 |
+
name: compute_score
|
| 548 |
+
trainer:
|
| 549 |
+
balance_batch: true
|
| 550 |
+
total_epochs: 15
|
| 551 |
+
total_training_steps: null
|
| 552 |
+
project_name: verl_grpo_gsm8k
|
| 553 |
+
experiment_name: qwen3_4b_gsm8k_grpo
|
| 554 |
+
logger:
|
| 555 |
+
- console
|
| 556 |
+
- wandb
|
| 557 |
+
log_val_generations: 0
|
| 558 |
+
rollout_data_dir: null
|
| 559 |
+
validation_data_dir: null
|
| 560 |
+
nnodes: 1
|
| 561 |
+
n_gpus_per_node: 8
|
| 562 |
+
save_freq: 20
|
| 563 |
+
esi_redundant_time: 0
|
| 564 |
+
resume_mode: disable
|
| 565 |
+
resume_from_path: null
|
| 566 |
+
val_before_train: true
|
| 567 |
+
val_only: false
|
| 568 |
+
test_freq: 5
|
| 569 |
+
critic_warmup: 0
|
| 570 |
+
default_hdfs_dir: null
|
| 571 |
+
del_local_ckpt_after_load: false
|
| 572 |
+
default_local_dir: checkpoints/${trainer.project_name}/${trainer.experiment_name}
|
| 573 |
+
max_actor_ckpt_to_keep: null
|
| 574 |
+
max_critic_ckpt_to_keep: null
|
| 575 |
+
ray_wait_register_center_timeout: 300
|
| 576 |
+
device: cuda
|
| 577 |
+
use_legacy_worker_impl: auto
|
| 578 |
+
global_profiler:
|
| 579 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 580 |
+
tool: null
|
| 581 |
+
steps: null
|
| 582 |
+
profile_continuous_steps: false
|
| 583 |
+
save_path: outputs/profile
|
| 584 |
+
global_tool_config:
|
| 585 |
+
nsys:
|
| 586 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 587 |
+
discrete: false
|
| 588 |
+
controller_nsight_options:
|
| 589 |
+
trace: cuda,nvtx,cublas,ucx
|
| 590 |
+
cuda-memory-usage: 'true'
|
| 591 |
+
cuda-graph-trace: graph
|
| 592 |
+
worker_nsight_options:
|
| 593 |
+
trace: cuda,nvtx,cublas,ucx
|
| 594 |
+
cuda-memory-usage: 'true'
|
| 595 |
+
cuda-graph-trace: graph
|
| 596 |
+
capture-range: cudaProfilerApi
|
| 597 |
+
capture-range-end: null
|
| 598 |
+
kill: none
|
| 599 |
+
torch_memory:
|
| 600 |
+
trace_alloc_max_entries: 100000
|
| 601 |
+
stack_depth: 32
|
| 602 |
+
context: all
|
| 603 |
+
stacks: all
|
| 604 |
+
kw_args: {}
|
| 605 |
+
transfer_queue:
|
| 606 |
+
enable: false
|
| 607 |
+
ray_kwargs:
|
| 608 |
+
ray_init:
|
| 609 |
+
num_cpus: null
|
| 610 |
+
timeline_json_file: null
|
examples/grpo_trainer/outputs/2026-01-26/16-49-41/.hydra/config.yaml
ADDED
|
@@ -0,0 +1,610 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
actor_rollout_ref:
|
| 2 |
+
actor:
|
| 3 |
+
optim:
|
| 4 |
+
_target_: verl.workers.config.FSDPOptimizerConfig
|
| 5 |
+
optimizer: AdamW
|
| 6 |
+
optimizer_impl: torch.optim
|
| 7 |
+
lr: 1.0e-06
|
| 8 |
+
lr_warmup_steps_ratio: 0.0
|
| 9 |
+
total_training_steps: -1
|
| 10 |
+
weight_decay: 0.01
|
| 11 |
+
lr_warmup_steps: -1
|
| 12 |
+
betas:
|
| 13 |
+
- 0.9
|
| 14 |
+
- 0.999
|
| 15 |
+
clip_grad: 1.0
|
| 16 |
+
min_lr_ratio: 0.0
|
| 17 |
+
num_cycles: 0.5
|
| 18 |
+
lr_scheduler_type: constant
|
| 19 |
+
warmup_style: null
|
| 20 |
+
override_optimizer_config: null
|
| 21 |
+
fsdp_config:
|
| 22 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 23 |
+
wrap_policy:
|
| 24 |
+
min_num_params: 0
|
| 25 |
+
param_offload: true
|
| 26 |
+
optimizer_offload: false
|
| 27 |
+
offload_policy: false
|
| 28 |
+
reshard_after_forward: true
|
| 29 |
+
fsdp_size: -1
|
| 30 |
+
forward_prefetch: false
|
| 31 |
+
model_dtype: fp32
|
| 32 |
+
use_orig_params: false
|
| 33 |
+
seed: 42
|
| 34 |
+
full_determinism: false
|
| 35 |
+
ulysses_sequence_parallel_size: 1
|
| 36 |
+
entropy_from_logits_with_chunking: false
|
| 37 |
+
use_torch_compile: true
|
| 38 |
+
entropy_checkpointing: false
|
| 39 |
+
forward_only: false
|
| 40 |
+
strategy: fsdp
|
| 41 |
+
dtype: bfloat16
|
| 42 |
+
_target_: verl.workers.config.FSDPActorConfig
|
| 43 |
+
rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
|
| 44 |
+
strategy: fsdp
|
| 45 |
+
ppo_mini_batch_size: 256
|
| 46 |
+
ppo_micro_batch_size: null
|
| 47 |
+
ppo_micro_batch_size_per_gpu: 32
|
| 48 |
+
use_dynamic_bsz: false
|
| 49 |
+
ppo_max_token_len_per_gpu: 16384
|
| 50 |
+
clip_ratio: 0.2
|
| 51 |
+
clip_ratio_low: 0.2
|
| 52 |
+
clip_ratio_high: 0.2
|
| 53 |
+
freeze_vision_tower: false
|
| 54 |
+
policy_loss:
|
| 55 |
+
_target_: verl.workers.config.PolicyLossConfig
|
| 56 |
+
loss_mode: vanilla
|
| 57 |
+
clip_cov_ratio: 0.0002
|
| 58 |
+
clip_cov_lb: 1.0
|
| 59 |
+
clip_cov_ub: 5.0
|
| 60 |
+
kl_cov_ratio: 0.0002
|
| 61 |
+
ppo_kl_coef: 0.1
|
| 62 |
+
clip_ratio_c: 3.0
|
| 63 |
+
loss_agg_mode: token-mean
|
| 64 |
+
loss_scale_factor: null
|
| 65 |
+
entropy_coeff: 0
|
| 66 |
+
calculate_entropy: false
|
| 67 |
+
use_kl_loss: true
|
| 68 |
+
use_torch_compile: true
|
| 69 |
+
kl_loss_coef: 0.001
|
| 70 |
+
kl_loss_type: low_var_kl
|
| 71 |
+
ppo_epochs: 1
|
| 72 |
+
shuffle: false
|
| 73 |
+
checkpoint:
|
| 74 |
+
_target_: verl.trainer.config.CheckpointConfig
|
| 75 |
+
save_contents:
|
| 76 |
+
- model
|
| 77 |
+
- optimizer
|
| 78 |
+
- extra
|
| 79 |
+
load_contents: ${.save_contents}
|
| 80 |
+
async_save: false
|
| 81 |
+
use_fused_kernels: ${oc.select:actor_rollout_ref.model.use_fused_kernels,false}
|
| 82 |
+
profiler:
|
| 83 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 84 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 85 |
+
enable: false
|
| 86 |
+
all_ranks: false
|
| 87 |
+
ranks: []
|
| 88 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 89 |
+
tool_config:
|
| 90 |
+
nsys:
|
| 91 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 92 |
+
discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
|
| 93 |
+
npu:
|
| 94 |
+
_target_: verl.utils.profiler.config.NPUToolConfig
|
| 95 |
+
contents: []
|
| 96 |
+
level: level1
|
| 97 |
+
analysis: true
|
| 98 |
+
discrete: false
|
| 99 |
+
torch:
|
| 100 |
+
_target_: verl.utils.profiler.config.TorchProfilerToolConfig
|
| 101 |
+
step_start: 0
|
| 102 |
+
step_end: null
|
| 103 |
+
torch_memory:
|
| 104 |
+
_target_: verl.utils.profiler.config.TorchMemoryToolConfig
|
| 105 |
+
trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
|
| 106 |
+
stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
|
| 107 |
+
router_replay:
|
| 108 |
+
_target_: verl.workers.config.RouterReplayConfig
|
| 109 |
+
mode: disabled
|
| 110 |
+
record_file: null
|
| 111 |
+
replay_file: null
|
| 112 |
+
grad_clip: 1.0
|
| 113 |
+
ulysses_sequence_parallel_size: 1
|
| 114 |
+
entropy_from_logits_with_chunking: false
|
| 115 |
+
entropy_checkpointing: false
|
| 116 |
+
use_remove_padding: ${oc.select:actor_rollout_ref.model.use_remove_padding,false}
|
| 117 |
+
ref:
|
| 118 |
+
rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
|
| 119 |
+
strategy: ${actor_rollout_ref.actor.strategy}
|
| 120 |
+
use_torch_compile: ${oc.select:actor_rollout_ref.actor.use_torch_compile,true}
|
| 121 |
+
log_prob_micro_batch_size: null
|
| 122 |
+
log_prob_micro_batch_size_per_gpu: 32
|
| 123 |
+
log_prob_use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
|
| 124 |
+
log_prob_max_token_len_per_gpu: ${oc.select:actor_rollout_ref.actor.ppo_max_token_len_per_gpu,16384}
|
| 125 |
+
profiler:
|
| 126 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 127 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 128 |
+
enable: false
|
| 129 |
+
all_ranks: false
|
| 130 |
+
ranks: []
|
| 131 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 132 |
+
tool_config:
|
| 133 |
+
nsys:
|
| 134 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 135 |
+
discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
|
| 136 |
+
npu:
|
| 137 |
+
_target_: verl.utils.profiler.config.NPUToolConfig
|
| 138 |
+
contents: []
|
| 139 |
+
level: level1
|
| 140 |
+
analysis: true
|
| 141 |
+
discrete: false
|
| 142 |
+
torch:
|
| 143 |
+
_target_: verl.utils.profiler.config.TorchProfilerToolConfig
|
| 144 |
+
step_start: 0
|
| 145 |
+
step_end: null
|
| 146 |
+
torch_memory:
|
| 147 |
+
_target_: verl.utils.profiler.config.TorchMemoryToolConfig
|
| 148 |
+
trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
|
| 149 |
+
stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
|
| 150 |
+
router_replay:
|
| 151 |
+
_target_: verl.workers.config.RouterReplayConfig
|
| 152 |
+
mode: disabled
|
| 153 |
+
record_file: null
|
| 154 |
+
replay_file: null
|
| 155 |
+
fsdp_config:
|
| 156 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 157 |
+
wrap_policy:
|
| 158 |
+
min_num_params: 0
|
| 159 |
+
param_offload: false
|
| 160 |
+
optimizer_offload: false
|
| 161 |
+
offload_policy: false
|
| 162 |
+
reshard_after_forward: true
|
| 163 |
+
fsdp_size: -1
|
| 164 |
+
forward_prefetch: false
|
| 165 |
+
model_dtype: fp32
|
| 166 |
+
use_orig_params: false
|
| 167 |
+
seed: 42
|
| 168 |
+
full_determinism: false
|
| 169 |
+
ulysses_sequence_parallel_size: 1
|
| 170 |
+
entropy_from_logits_with_chunking: false
|
| 171 |
+
use_torch_compile: true
|
| 172 |
+
entropy_checkpointing: false
|
| 173 |
+
forward_only: true
|
| 174 |
+
strategy: fsdp
|
| 175 |
+
dtype: bfloat16
|
| 176 |
+
_target_: verl.workers.config.FSDPActorConfig
|
| 177 |
+
ulysses_sequence_parallel_size: ${oc.select:actor_rollout_ref.actor.ulysses_sequence_parallel_size,1}
|
| 178 |
+
entropy_from_logits_with_chunking: false
|
| 179 |
+
entropy_checkpointing: false
|
| 180 |
+
rollout:
|
| 181 |
+
_target_: verl.workers.config.RolloutConfig
|
| 182 |
+
name: vllm
|
| 183 |
+
mode: async
|
| 184 |
+
temperature: 1.0
|
| 185 |
+
top_k: -1
|
| 186 |
+
top_p: 1
|
| 187 |
+
prompt_length: ${oc.select:data.max_prompt_length,512}
|
| 188 |
+
response_length: ${oc.select:data.max_response_length,512}
|
| 189 |
+
dtype: bfloat16
|
| 190 |
+
gpu_memory_utilization: 0.6
|
| 191 |
+
ignore_eos: false
|
| 192 |
+
enforce_eager: false
|
| 193 |
+
cudagraph_capture_sizes: null
|
| 194 |
+
free_cache_engine: true
|
| 195 |
+
tensor_model_parallel_size: 2
|
| 196 |
+
data_parallel_size: 1
|
| 197 |
+
expert_parallel_size: 1
|
| 198 |
+
pipeline_model_parallel_size: 1
|
| 199 |
+
max_num_batched_tokens: 8192
|
| 200 |
+
max_model_len: null
|
| 201 |
+
max_num_seqs: 1024
|
| 202 |
+
enable_chunked_prefill: true
|
| 203 |
+
enable_prefix_caching: true
|
| 204 |
+
load_format: safetensors
|
| 205 |
+
log_prob_micro_batch_size: null
|
| 206 |
+
log_prob_micro_batch_size_per_gpu: 32
|
| 207 |
+
log_prob_use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
|
| 208 |
+
log_prob_max_token_len_per_gpu: ${oc.select:actor_rollout_ref.actor.ppo_max_token_len_per_gpu,16384}
|
| 209 |
+
disable_log_stats: true
|
| 210 |
+
do_sample: true
|
| 211 |
+
'n': 5
|
| 212 |
+
over_sample_rate: 0
|
| 213 |
+
multi_stage_wake_up: false
|
| 214 |
+
engine_kwargs:
|
| 215 |
+
vllm: {}
|
| 216 |
+
sglang: {}
|
| 217 |
+
val_kwargs:
|
| 218 |
+
_target_: verl.workers.config.SamplingConfig
|
| 219 |
+
top_k: -1
|
| 220 |
+
top_p: 1.0
|
| 221 |
+
temperature: 0
|
| 222 |
+
'n': 1
|
| 223 |
+
do_sample: false
|
| 224 |
+
multi_turn:
|
| 225 |
+
_target_: verl.workers.config.MultiTurnConfig
|
| 226 |
+
enable: false
|
| 227 |
+
max_assistant_turns: null
|
| 228 |
+
tool_config_path: null
|
| 229 |
+
max_user_turns: null
|
| 230 |
+
max_parallel_calls: 1
|
| 231 |
+
max_tool_response_length: 256
|
| 232 |
+
tool_response_truncate_side: middle
|
| 233 |
+
interaction_config_path: null
|
| 234 |
+
use_inference_chat_template: false
|
| 235 |
+
tokenization_sanity_check_mode: strict
|
| 236 |
+
format: hermes
|
| 237 |
+
num_repeat_rollouts: null
|
| 238 |
+
calculate_log_probs: false
|
| 239 |
+
agent:
|
| 240 |
+
_target_: verl.workers.config.AgentLoopConfig
|
| 241 |
+
num_workers: 8
|
| 242 |
+
default_agent_loop: single_turn_agent
|
| 243 |
+
agent_loop_config_path: null
|
| 244 |
+
custom_async_server:
|
| 245 |
+
_target_: verl.workers.config.CustomAsyncServerConfig
|
| 246 |
+
path: null
|
| 247 |
+
name: null
|
| 248 |
+
update_weights_bucket_megabytes: 512
|
| 249 |
+
trace:
|
| 250 |
+
_target_: verl.workers.config.TraceConfig
|
| 251 |
+
backend: null
|
| 252 |
+
token2text: false
|
| 253 |
+
max_samples_per_step_per_worker: null
|
| 254 |
+
skip_rollout: false
|
| 255 |
+
skip_dump_dir: /tmp/rollout_dump
|
| 256 |
+
skip_tokenizer_init: true
|
| 257 |
+
enable_rollout_routing_replay: false
|
| 258 |
+
profiler:
|
| 259 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 260 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 261 |
+
enable: ${oc.select:actor_rollout_ref.actor.profiler.enable,false}
|
| 262 |
+
all_ranks: ${oc.select:actor_rollout_ref.actor.profiler.all_ranks,false}
|
| 263 |
+
ranks: ${oc.select:actor_rollout_ref.actor.profiler.ranks,[]}
|
| 264 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 265 |
+
tool_config: ${oc.select:actor_rollout_ref.actor.profiler.tool_config,null}
|
| 266 |
+
prometheus:
|
| 267 |
+
_target_: verl.workers.config.PrometheusConfig
|
| 268 |
+
enable: false
|
| 269 |
+
port: 9090
|
| 270 |
+
file: /tmp/ray/session_latest/metrics/prometheus/prometheus.yml
|
| 271 |
+
served_model_name: ${oc.select:actor_rollout_ref.model.path,null}
|
| 272 |
+
layered_summon: true
|
| 273 |
+
model:
|
| 274 |
+
_target_: verl.workers.config.HFModelConfig
|
| 275 |
+
path: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 276 |
+
hf_config_path: null
|
| 277 |
+
tokenizer_path: null
|
| 278 |
+
use_shm: false
|
| 279 |
+
trust_remote_code: false
|
| 280 |
+
custom_chat_template: null
|
| 281 |
+
external_lib: null
|
| 282 |
+
override_config: {}
|
| 283 |
+
enable_gradient_checkpointing: true
|
| 284 |
+
enable_activation_offload: false
|
| 285 |
+
use_remove_padding: true
|
| 286 |
+
lora_rank: 0
|
| 287 |
+
lora_alpha: 16
|
| 288 |
+
target_modules: all-linear
|
| 289 |
+
exclude_modules: null
|
| 290 |
+
lora_adapter_path: null
|
| 291 |
+
use_liger: false
|
| 292 |
+
use_fused_kernels: false
|
| 293 |
+
fused_kernel_options:
|
| 294 |
+
impl_backend: torch
|
| 295 |
+
hybrid_engine: true
|
| 296 |
+
nccl_timeout: 600
|
| 297 |
+
data:
|
| 298 |
+
tokenizer: null
|
| 299 |
+
use_shm: false
|
| 300 |
+
train_files: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/train.parquet
|
| 301 |
+
val_files: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/test.parquet
|
| 302 |
+
train_max_samples: -1
|
| 303 |
+
val_max_samples: -1
|
| 304 |
+
prompt_key: prompt
|
| 305 |
+
reward_fn_key: data_source
|
| 306 |
+
max_prompt_length: 512
|
| 307 |
+
max_response_length: 64
|
| 308 |
+
train_batch_size: 1024
|
| 309 |
+
val_batch_size: null
|
| 310 |
+
tool_config_path: ${oc.select:actor_rollout_ref.rollout.multi_turn.tool_config_path,
|
| 311 |
+
null}
|
| 312 |
+
return_raw_input_ids: false
|
| 313 |
+
return_raw_chat: true
|
| 314 |
+
return_full_prompt: false
|
| 315 |
+
shuffle: false
|
| 316 |
+
seed: null
|
| 317 |
+
dataloader_num_workers: 8
|
| 318 |
+
image_patch_size: 14
|
| 319 |
+
validation_shuffle: false
|
| 320 |
+
filter_overlong_prompts: true
|
| 321 |
+
filter_overlong_prompts_workers: 1
|
| 322 |
+
truncation: error
|
| 323 |
+
image_key: images
|
| 324 |
+
video_key: videos
|
| 325 |
+
trust_remote_code: false
|
| 326 |
+
custom_cls:
|
| 327 |
+
path: null
|
| 328 |
+
name: null
|
| 329 |
+
return_multi_modal_inputs: true
|
| 330 |
+
sampler:
|
| 331 |
+
class_path: null
|
| 332 |
+
class_name: null
|
| 333 |
+
datagen:
|
| 334 |
+
path: null
|
| 335 |
+
name: null
|
| 336 |
+
apply_chat_template_kwargs: {}
|
| 337 |
+
reward_manager:
|
| 338 |
+
_target_: verl.trainer.config.config.RewardManagerConfig
|
| 339 |
+
source: register
|
| 340 |
+
name: ${oc.select:reward_model.reward_manager,naive}
|
| 341 |
+
module:
|
| 342 |
+
_target_: verl.trainer.config.config.ModuleConfig
|
| 343 |
+
path: null
|
| 344 |
+
name: custom_reward_manager
|
| 345 |
+
critic:
|
| 346 |
+
optim:
|
| 347 |
+
_target_: verl.workers.config.FSDPOptimizerConfig
|
| 348 |
+
optimizer: AdamW
|
| 349 |
+
optimizer_impl: torch.optim
|
| 350 |
+
lr: 1.0e-05
|
| 351 |
+
lr_warmup_steps_ratio: 0.0
|
| 352 |
+
total_training_steps: -1
|
| 353 |
+
weight_decay: 0.01
|
| 354 |
+
lr_warmup_steps: -1
|
| 355 |
+
betas:
|
| 356 |
+
- 0.9
|
| 357 |
+
- 0.999
|
| 358 |
+
clip_grad: 1.0
|
| 359 |
+
min_lr_ratio: 0.0
|
| 360 |
+
num_cycles: 0.5
|
| 361 |
+
lr_scheduler_type: constant
|
| 362 |
+
warmup_style: null
|
| 363 |
+
override_optimizer_config: null
|
| 364 |
+
model:
|
| 365 |
+
fsdp_config:
|
| 366 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 367 |
+
wrap_policy:
|
| 368 |
+
min_num_params: 0
|
| 369 |
+
param_offload: false
|
| 370 |
+
optimizer_offload: false
|
| 371 |
+
offload_policy: false
|
| 372 |
+
reshard_after_forward: true
|
| 373 |
+
fsdp_size: -1
|
| 374 |
+
forward_prefetch: false
|
| 375 |
+
model_dtype: fp32
|
| 376 |
+
use_orig_params: false
|
| 377 |
+
seed: 42
|
| 378 |
+
full_determinism: false
|
| 379 |
+
ulysses_sequence_parallel_size: 1
|
| 380 |
+
entropy_from_logits_with_chunking: false
|
| 381 |
+
use_torch_compile: true
|
| 382 |
+
entropy_checkpointing: false
|
| 383 |
+
forward_only: false
|
| 384 |
+
strategy: fsdp
|
| 385 |
+
dtype: bfloat16
|
| 386 |
+
path: ~/models/deepseek-llm-7b-chat
|
| 387 |
+
tokenizer_path: ${oc.select:actor_rollout_ref.model.path,"~/models/deepseek-llm-7b-chat"}
|
| 388 |
+
override_config: {}
|
| 389 |
+
external_lib: ${oc.select:actor_rollout_ref.model.external_lib,null}
|
| 390 |
+
trust_remote_code: ${oc.select:actor_rollout_ref.model.trust_remote_code,false}
|
| 391 |
+
_target_: verl.workers.config.FSDPCriticModelCfg
|
| 392 |
+
use_shm: false
|
| 393 |
+
enable_gradient_checkpointing: true
|
| 394 |
+
enable_activation_offload: false
|
| 395 |
+
use_remove_padding: false
|
| 396 |
+
lora_rank: 0
|
| 397 |
+
lora_alpha: 16
|
| 398 |
+
target_modules: all-linear
|
| 399 |
+
_target_: verl.workers.config.FSDPCriticConfig
|
| 400 |
+
rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
|
| 401 |
+
strategy: fsdp
|
| 402 |
+
enable: null
|
| 403 |
+
ppo_mini_batch_size: ${oc.select:actor_rollout_ref.actor.ppo_mini_batch_size,256}
|
| 404 |
+
ppo_micro_batch_size: null
|
| 405 |
+
ppo_micro_batch_size_per_gpu: ${oc.select:.ppo_micro_batch_size,null}
|
| 406 |
+
use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
|
| 407 |
+
ppo_max_token_len_per_gpu: 32768
|
| 408 |
+
forward_max_token_len_per_gpu: ${.ppo_max_token_len_per_gpu}
|
| 409 |
+
ppo_epochs: ${oc.select:actor_rollout_ref.actor.ppo_epochs,1}
|
| 410 |
+
shuffle: ${oc.select:actor_rollout_ref.actor.shuffle,false}
|
| 411 |
+
cliprange_value: 0.5
|
| 412 |
+
loss_agg_mode: ${oc.select:actor_rollout_ref.actor.loss_agg_mode,token-mean}
|
| 413 |
+
checkpoint:
|
| 414 |
+
_target_: verl.trainer.config.CheckpointConfig
|
| 415 |
+
save_contents:
|
| 416 |
+
- model
|
| 417 |
+
- optimizer
|
| 418 |
+
- extra
|
| 419 |
+
load_contents: ${.save_contents}
|
| 420 |
+
async_save: false
|
| 421 |
+
profiler:
|
| 422 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 423 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 424 |
+
enable: false
|
| 425 |
+
all_ranks: false
|
| 426 |
+
ranks: []
|
| 427 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 428 |
+
tool_config:
|
| 429 |
+
nsys:
|
| 430 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 431 |
+
discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
|
| 432 |
+
npu:
|
| 433 |
+
_target_: verl.utils.profiler.config.NPUToolConfig
|
| 434 |
+
contents: []
|
| 435 |
+
level: level1
|
| 436 |
+
analysis: true
|
| 437 |
+
discrete: false
|
| 438 |
+
torch:
|
| 439 |
+
_target_: verl.utils.profiler.config.TorchProfilerToolConfig
|
| 440 |
+
step_start: 0
|
| 441 |
+
step_end: null
|
| 442 |
+
torch_memory:
|
| 443 |
+
_target_: verl.utils.profiler.config.TorchMemoryToolConfig
|
| 444 |
+
trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
|
| 445 |
+
stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
|
| 446 |
+
forward_micro_batch_size: ${oc.select:.ppo_micro_batch_size,null}
|
| 447 |
+
forward_micro_batch_size_per_gpu: ${oc.select:.ppo_micro_batch_size_per_gpu,null}
|
| 448 |
+
ulysses_sequence_parallel_size: 1
|
| 449 |
+
grad_clip: 1.0
|
| 450 |
+
reward_model:
|
| 451 |
+
enable: true
|
| 452 |
+
enable_resource_pool: false
|
| 453 |
+
n_gpus_per_node: 0
|
| 454 |
+
nnodes: 0
|
| 455 |
+
strategy: fsdp
|
| 456 |
+
model:
|
| 457 |
+
input_tokenizer: ${actor_rollout_ref.model.path}
|
| 458 |
+
path: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/reward_model_converted
|
| 459 |
+
external_lib: ${actor_rollout_ref.model.external_lib}
|
| 460 |
+
trust_remote_code: false
|
| 461 |
+
override_config: {}
|
| 462 |
+
use_shm: false
|
| 463 |
+
use_remove_padding: false
|
| 464 |
+
use_fused_kernels: ${actor_rollout_ref.model.use_fused_kernels}
|
| 465 |
+
fsdp_config:
|
| 466 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 467 |
+
wrap_policy:
|
| 468 |
+
min_num_params: 0
|
| 469 |
+
param_offload: false
|
| 470 |
+
reshard_after_forward: true
|
| 471 |
+
fsdp_size: -1
|
| 472 |
+
forward_prefetch: false
|
| 473 |
+
micro_batch_size: null
|
| 474 |
+
micro_batch_size_per_gpu: 32
|
| 475 |
+
max_length: null
|
| 476 |
+
use_dynamic_bsz: ${critic.use_dynamic_bsz}
|
| 477 |
+
forward_max_token_len_per_gpu: ${critic.forward_max_token_len_per_gpu}
|
| 478 |
+
reward_manager: naive
|
| 479 |
+
launch_reward_fn_async: false
|
| 480 |
+
sandbox_fusion:
|
| 481 |
+
url: null
|
| 482 |
+
max_concurrent: 64
|
| 483 |
+
memory_limit_mb: 1024
|
| 484 |
+
profiler:
|
| 485 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 486 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 487 |
+
enable: false
|
| 488 |
+
all_ranks: false
|
| 489 |
+
ranks: []
|
| 490 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 491 |
+
tool_config: ${oc.select:actor_rollout_ref.actor.profiler.tool_config,null}
|
| 492 |
+
ulysses_sequence_parallel_size: 1
|
| 493 |
+
use_reward_loop: true
|
| 494 |
+
rollout:
|
| 495 |
+
_target_: verl.workers.config.RolloutConfig
|
| 496 |
+
name: ???
|
| 497 |
+
dtype: bfloat16
|
| 498 |
+
gpu_memory_utilization: 0.5
|
| 499 |
+
enforce_eager: true
|
| 500 |
+
cudagraph_capture_sizes: null
|
| 501 |
+
free_cache_engine: true
|
| 502 |
+
data_parallel_size: 1
|
| 503 |
+
expert_parallel_size: 1
|
| 504 |
+
tensor_model_parallel_size: 2
|
| 505 |
+
max_num_batched_tokens: 8192
|
| 506 |
+
max_model_len: null
|
| 507 |
+
max_num_seqs: 1024
|
| 508 |
+
load_format: auto
|
| 509 |
+
engine_kwargs: {}
|
| 510 |
+
limit_images: null
|
| 511 |
+
enable_chunked_prefill: true
|
| 512 |
+
enable_prefix_caching: true
|
| 513 |
+
disable_log_stats: true
|
| 514 |
+
skip_tokenizer_init: true
|
| 515 |
+
prompt_length: 512
|
| 516 |
+
response_length: 512
|
| 517 |
+
algorithm:
|
| 518 |
+
rollout_correction:
|
| 519 |
+
rollout_is: null
|
| 520 |
+
rollout_is_threshold: 2.0
|
| 521 |
+
rollout_rs: null
|
| 522 |
+
rollout_rs_threshold: null
|
| 523 |
+
rollout_rs_threshold_lower: null
|
| 524 |
+
rollout_token_veto_threshold: null
|
| 525 |
+
bypass_mode: false
|
| 526 |
+
use_policy_gradient: false
|
| 527 |
+
rollout_is_batch_normalize: false
|
| 528 |
+
_target_: verl.trainer.config.AlgoConfig
|
| 529 |
+
gamma: 1.0
|
| 530 |
+
lam: 1.0
|
| 531 |
+
adv_estimator: grpo
|
| 532 |
+
norm_adv_by_std_in_grpo: true
|
| 533 |
+
use_kl_in_reward: false
|
| 534 |
+
kl_penalty: kl
|
| 535 |
+
kl_ctrl:
|
| 536 |
+
_target_: verl.trainer.config.KLControlConfig
|
| 537 |
+
type: fixed
|
| 538 |
+
kl_coef: 0.001
|
| 539 |
+
horizon: 10000
|
| 540 |
+
target_kl: 0.1
|
| 541 |
+
use_pf_ppo: false
|
| 542 |
+
pf_ppo:
|
| 543 |
+
reweight_method: pow
|
| 544 |
+
weight_pow: 2.0
|
| 545 |
+
custom_reward_function:
|
| 546 |
+
path: null
|
| 547 |
+
name: compute_score
|
| 548 |
+
trainer:
|
| 549 |
+
balance_batch: true
|
| 550 |
+
total_epochs: 15
|
| 551 |
+
total_training_steps: null
|
| 552 |
+
project_name: verl_grpo_gsm8k
|
| 553 |
+
experiment_name: qwen3_4b_gsm8k_grpo
|
| 554 |
+
logger:
|
| 555 |
+
- console
|
| 556 |
+
- wandb
|
| 557 |
+
log_val_generations: 0
|
| 558 |
+
rollout_data_dir: null
|
| 559 |
+
validation_data_dir: null
|
| 560 |
+
nnodes: 1
|
| 561 |
+
n_gpus_per_node: 8
|
| 562 |
+
save_freq: 20
|
| 563 |
+
esi_redundant_time: 0
|
| 564 |
+
resume_mode: disable
|
| 565 |
+
resume_from_path: null
|
| 566 |
+
val_before_train: true
|
| 567 |
+
val_only: false
|
| 568 |
+
test_freq: 5
|
| 569 |
+
critic_warmup: 0
|
| 570 |
+
default_hdfs_dir: null
|
| 571 |
+
del_local_ckpt_after_load: false
|
| 572 |
+
default_local_dir: checkpoints/${trainer.project_name}/${trainer.experiment_name}
|
| 573 |
+
max_actor_ckpt_to_keep: null
|
| 574 |
+
max_critic_ckpt_to_keep: null
|
| 575 |
+
ray_wait_register_center_timeout: 300
|
| 576 |
+
device: cuda
|
| 577 |
+
use_legacy_worker_impl: auto
|
| 578 |
+
global_profiler:
|
| 579 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 580 |
+
tool: null
|
| 581 |
+
steps: null
|
| 582 |
+
profile_continuous_steps: false
|
| 583 |
+
save_path: outputs/profile
|
| 584 |
+
global_tool_config:
|
| 585 |
+
nsys:
|
| 586 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 587 |
+
discrete: false
|
| 588 |
+
controller_nsight_options:
|
| 589 |
+
trace: cuda,nvtx,cublas,ucx
|
| 590 |
+
cuda-memory-usage: 'true'
|
| 591 |
+
cuda-graph-trace: graph
|
| 592 |
+
worker_nsight_options:
|
| 593 |
+
trace: cuda,nvtx,cublas,ucx
|
| 594 |
+
cuda-memory-usage: 'true'
|
| 595 |
+
cuda-graph-trace: graph
|
| 596 |
+
capture-range: cudaProfilerApi
|
| 597 |
+
capture-range-end: null
|
| 598 |
+
kill: none
|
| 599 |
+
torch_memory:
|
| 600 |
+
trace_alloc_max_entries: 100000
|
| 601 |
+
stack_depth: 32
|
| 602 |
+
context: all
|
| 603 |
+
stacks: all
|
| 604 |
+
kw_args: {}
|
| 605 |
+
transfer_queue:
|
| 606 |
+
enable: false
|
| 607 |
+
ray_kwargs:
|
| 608 |
+
ray_init:
|
| 609 |
+
num_cpus: null
|
| 610 |
+
timeline_json_file: null
|
examples/grpo_trainer/outputs/2026-01-26/16-49-41/.hydra/overrides.yaml
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
- algorithm.adv_estimator=grpo
|
| 2 |
+
- data.train_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/train.parquet
|
| 3 |
+
- data.val_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/test.parquet
|
| 4 |
+
- data.train_batch_size=1024
|
| 5 |
+
- data.max_prompt_length=512
|
| 6 |
+
- data.max_response_length=64
|
| 7 |
+
- data.filter_overlong_prompts=True
|
| 8 |
+
- data.truncation=error
|
| 9 |
+
- data.shuffle=False
|
| 10 |
+
- actor_rollout_ref.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 11 |
+
- actor_rollout_ref.actor.optim.lr=1e-6
|
| 12 |
+
- actor_rollout_ref.model.use_remove_padding=True
|
| 13 |
+
- actor_rollout_ref.actor.ppo_mini_batch_size=256
|
| 14 |
+
- actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=32
|
| 15 |
+
- actor_rollout_ref.actor.use_kl_loss=True
|
| 16 |
+
- actor_rollout_ref.actor.kl_loss_coef=0.001
|
| 17 |
+
- actor_rollout_ref.actor.kl_loss_type=low_var_kl
|
| 18 |
+
- actor_rollout_ref.actor.entropy_coeff=0
|
| 19 |
+
- actor_rollout_ref.model.enable_gradient_checkpointing=True
|
| 20 |
+
- actor_rollout_ref.actor.fsdp_config.param_offload=True
|
| 21 |
+
- actor_rollout_ref.actor.fsdp_config.optimizer_offload=False
|
| 22 |
+
- actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32
|
| 23 |
+
- actor_rollout_ref.rollout.tensor_model_parallel_size=2
|
| 24 |
+
- actor_rollout_ref.rollout.name=vllm
|
| 25 |
+
- actor_rollout_ref.rollout.gpu_memory_utilization=0.6
|
| 26 |
+
- actor_rollout_ref.rollout.n=5
|
| 27 |
+
- actor_rollout_ref.rollout.load_format=safetensors
|
| 28 |
+
- actor_rollout_ref.rollout.layered_summon=True
|
| 29 |
+
- actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32
|
| 30 |
+
- actor_rollout_ref.ref.fsdp_config.param_offload=False
|
| 31 |
+
- algorithm.use_kl_in_reward=False
|
| 32 |
+
- reward_model.enable=True
|
| 33 |
+
- reward_model.enable=True
|
| 34 |
+
- reward_model.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/reward_model_converted
|
| 35 |
+
- reward_model.micro_batch_size_per_gpu=32
|
| 36 |
+
- trainer.critic_warmup=0
|
| 37 |
+
- trainer.logger=["console","wandb"]
|
| 38 |
+
- trainer.project_name=verl_grpo_gsm8k
|
| 39 |
+
- trainer.experiment_name=qwen3_4b_gsm8k_grpo
|
| 40 |
+
- trainer.n_gpus_per_node=8
|
| 41 |
+
- trainer.nnodes=1
|
| 42 |
+
- trainer.save_freq=20
|
| 43 |
+
- trainer.test_freq=5
|
| 44 |
+
- trainer.total_epochs=15
|
| 45 |
+
- trainer.resume_mode=disable
|
examples/grpo_trainer/outputs/2026-01-26/17-05-09/.hydra/config.yaml
ADDED
|
@@ -0,0 +1,610 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
actor_rollout_ref:
|
| 2 |
+
actor:
|
| 3 |
+
optim:
|
| 4 |
+
_target_: verl.workers.config.FSDPOptimizerConfig
|
| 5 |
+
optimizer: AdamW
|
| 6 |
+
optimizer_impl: torch.optim
|
| 7 |
+
lr: 1.0e-06
|
| 8 |
+
lr_warmup_steps_ratio: 0.0
|
| 9 |
+
total_training_steps: -1
|
| 10 |
+
weight_decay: 0.01
|
| 11 |
+
lr_warmup_steps: -1
|
| 12 |
+
betas:
|
| 13 |
+
- 0.9
|
| 14 |
+
- 0.999
|
| 15 |
+
clip_grad: 1.0
|
| 16 |
+
min_lr_ratio: 0.0
|
| 17 |
+
num_cycles: 0.5
|
| 18 |
+
lr_scheduler_type: constant
|
| 19 |
+
warmup_style: null
|
| 20 |
+
override_optimizer_config: null
|
| 21 |
+
fsdp_config:
|
| 22 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 23 |
+
wrap_policy:
|
| 24 |
+
min_num_params: 0
|
| 25 |
+
param_offload: true
|
| 26 |
+
optimizer_offload: false
|
| 27 |
+
offload_policy: false
|
| 28 |
+
reshard_after_forward: true
|
| 29 |
+
fsdp_size: -1
|
| 30 |
+
forward_prefetch: false
|
| 31 |
+
model_dtype: fp32
|
| 32 |
+
use_orig_params: false
|
| 33 |
+
seed: 42
|
| 34 |
+
full_determinism: false
|
| 35 |
+
ulysses_sequence_parallel_size: 1
|
| 36 |
+
entropy_from_logits_with_chunking: false
|
| 37 |
+
use_torch_compile: true
|
| 38 |
+
entropy_checkpointing: false
|
| 39 |
+
forward_only: false
|
| 40 |
+
strategy: fsdp
|
| 41 |
+
dtype: bfloat16
|
| 42 |
+
_target_: verl.workers.config.FSDPActorConfig
|
| 43 |
+
rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
|
| 44 |
+
strategy: fsdp
|
| 45 |
+
ppo_mini_batch_size: 256
|
| 46 |
+
ppo_micro_batch_size: null
|
| 47 |
+
ppo_micro_batch_size_per_gpu: 32
|
| 48 |
+
use_dynamic_bsz: false
|
| 49 |
+
ppo_max_token_len_per_gpu: 16384
|
| 50 |
+
clip_ratio: 0.2
|
| 51 |
+
clip_ratio_low: 0.2
|
| 52 |
+
clip_ratio_high: 0.2
|
| 53 |
+
freeze_vision_tower: false
|
| 54 |
+
policy_loss:
|
| 55 |
+
_target_: verl.workers.config.PolicyLossConfig
|
| 56 |
+
loss_mode: vanilla
|
| 57 |
+
clip_cov_ratio: 0.0002
|
| 58 |
+
clip_cov_lb: 1.0
|
| 59 |
+
clip_cov_ub: 5.0
|
| 60 |
+
kl_cov_ratio: 0.0002
|
| 61 |
+
ppo_kl_coef: 0.1
|
| 62 |
+
clip_ratio_c: 3.0
|
| 63 |
+
loss_agg_mode: token-mean
|
| 64 |
+
loss_scale_factor: null
|
| 65 |
+
entropy_coeff: 0
|
| 66 |
+
calculate_entropy: false
|
| 67 |
+
use_kl_loss: true
|
| 68 |
+
use_torch_compile: true
|
| 69 |
+
kl_loss_coef: 0.001
|
| 70 |
+
kl_loss_type: low_var_kl
|
| 71 |
+
ppo_epochs: 1
|
| 72 |
+
shuffle: false
|
| 73 |
+
checkpoint:
|
| 74 |
+
_target_: verl.trainer.config.CheckpointConfig
|
| 75 |
+
save_contents:
|
| 76 |
+
- model
|
| 77 |
+
- optimizer
|
| 78 |
+
- extra
|
| 79 |
+
load_contents: ${.save_contents}
|
| 80 |
+
async_save: false
|
| 81 |
+
use_fused_kernels: ${oc.select:actor_rollout_ref.model.use_fused_kernels,false}
|
| 82 |
+
profiler:
|
| 83 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 84 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 85 |
+
enable: false
|
| 86 |
+
all_ranks: false
|
| 87 |
+
ranks: []
|
| 88 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 89 |
+
tool_config:
|
| 90 |
+
nsys:
|
| 91 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 92 |
+
discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
|
| 93 |
+
npu:
|
| 94 |
+
_target_: verl.utils.profiler.config.NPUToolConfig
|
| 95 |
+
contents: []
|
| 96 |
+
level: level1
|
| 97 |
+
analysis: true
|
| 98 |
+
discrete: false
|
| 99 |
+
torch:
|
| 100 |
+
_target_: verl.utils.profiler.config.TorchProfilerToolConfig
|
| 101 |
+
step_start: 0
|
| 102 |
+
step_end: null
|
| 103 |
+
torch_memory:
|
| 104 |
+
_target_: verl.utils.profiler.config.TorchMemoryToolConfig
|
| 105 |
+
trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
|
| 106 |
+
stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
|
| 107 |
+
router_replay:
|
| 108 |
+
_target_: verl.workers.config.RouterReplayConfig
|
| 109 |
+
mode: disabled
|
| 110 |
+
record_file: null
|
| 111 |
+
replay_file: null
|
| 112 |
+
grad_clip: 1.0
|
| 113 |
+
ulysses_sequence_parallel_size: 1
|
| 114 |
+
entropy_from_logits_with_chunking: false
|
| 115 |
+
entropy_checkpointing: false
|
| 116 |
+
use_remove_padding: ${oc.select:actor_rollout_ref.model.use_remove_padding,false}
|
| 117 |
+
ref:
|
| 118 |
+
rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
|
| 119 |
+
strategy: ${actor_rollout_ref.actor.strategy}
|
| 120 |
+
use_torch_compile: ${oc.select:actor_rollout_ref.actor.use_torch_compile,true}
|
| 121 |
+
log_prob_micro_batch_size: null
|
| 122 |
+
log_prob_micro_batch_size_per_gpu: 32
|
| 123 |
+
log_prob_use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
|
| 124 |
+
log_prob_max_token_len_per_gpu: ${oc.select:actor_rollout_ref.actor.ppo_max_token_len_per_gpu,16384}
|
| 125 |
+
profiler:
|
| 126 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 127 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 128 |
+
enable: false
|
| 129 |
+
all_ranks: false
|
| 130 |
+
ranks: []
|
| 131 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 132 |
+
tool_config:
|
| 133 |
+
nsys:
|
| 134 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 135 |
+
discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
|
| 136 |
+
npu:
|
| 137 |
+
_target_: verl.utils.profiler.config.NPUToolConfig
|
| 138 |
+
contents: []
|
| 139 |
+
level: level1
|
| 140 |
+
analysis: true
|
| 141 |
+
discrete: false
|
| 142 |
+
torch:
|
| 143 |
+
_target_: verl.utils.profiler.config.TorchProfilerToolConfig
|
| 144 |
+
step_start: 0
|
| 145 |
+
step_end: null
|
| 146 |
+
torch_memory:
|
| 147 |
+
_target_: verl.utils.profiler.config.TorchMemoryToolConfig
|
| 148 |
+
trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
|
| 149 |
+
stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
|
| 150 |
+
router_replay:
|
| 151 |
+
_target_: verl.workers.config.RouterReplayConfig
|
| 152 |
+
mode: disabled
|
| 153 |
+
record_file: null
|
| 154 |
+
replay_file: null
|
| 155 |
+
fsdp_config:
|
| 156 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 157 |
+
wrap_policy:
|
| 158 |
+
min_num_params: 0
|
| 159 |
+
param_offload: false
|
| 160 |
+
optimizer_offload: false
|
| 161 |
+
offload_policy: false
|
| 162 |
+
reshard_after_forward: true
|
| 163 |
+
fsdp_size: -1
|
| 164 |
+
forward_prefetch: false
|
| 165 |
+
model_dtype: fp32
|
| 166 |
+
use_orig_params: false
|
| 167 |
+
seed: 42
|
| 168 |
+
full_determinism: false
|
| 169 |
+
ulysses_sequence_parallel_size: 1
|
| 170 |
+
entropy_from_logits_with_chunking: false
|
| 171 |
+
use_torch_compile: true
|
| 172 |
+
entropy_checkpointing: false
|
| 173 |
+
forward_only: true
|
| 174 |
+
strategy: fsdp
|
| 175 |
+
dtype: bfloat16
|
| 176 |
+
_target_: verl.workers.config.FSDPActorConfig
|
| 177 |
+
ulysses_sequence_parallel_size: ${oc.select:actor_rollout_ref.actor.ulysses_sequence_parallel_size,1}
|
| 178 |
+
entropy_from_logits_with_chunking: false
|
| 179 |
+
entropy_checkpointing: false
|
| 180 |
+
rollout:
|
| 181 |
+
_target_: verl.workers.config.RolloutConfig
|
| 182 |
+
name: vllm
|
| 183 |
+
mode: async
|
| 184 |
+
temperature: 1.0
|
| 185 |
+
top_k: -1
|
| 186 |
+
top_p: 1
|
| 187 |
+
prompt_length: ${oc.select:data.max_prompt_length,512}
|
| 188 |
+
response_length: ${oc.select:data.max_response_length,512}
|
| 189 |
+
dtype: bfloat16
|
| 190 |
+
gpu_memory_utilization: 0.6
|
| 191 |
+
ignore_eos: false
|
| 192 |
+
enforce_eager: false
|
| 193 |
+
cudagraph_capture_sizes: null
|
| 194 |
+
free_cache_engine: true
|
| 195 |
+
tensor_model_parallel_size: 2
|
| 196 |
+
data_parallel_size: 1
|
| 197 |
+
expert_parallel_size: 1
|
| 198 |
+
pipeline_model_parallel_size: 1
|
| 199 |
+
max_num_batched_tokens: 8192
|
| 200 |
+
max_model_len: null
|
| 201 |
+
max_num_seqs: 1024
|
| 202 |
+
enable_chunked_prefill: true
|
| 203 |
+
enable_prefix_caching: true
|
| 204 |
+
load_format: safetensors
|
| 205 |
+
log_prob_micro_batch_size: null
|
| 206 |
+
log_prob_micro_batch_size_per_gpu: 32
|
| 207 |
+
log_prob_use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
|
| 208 |
+
log_prob_max_token_len_per_gpu: ${oc.select:actor_rollout_ref.actor.ppo_max_token_len_per_gpu,16384}
|
| 209 |
+
disable_log_stats: true
|
| 210 |
+
do_sample: true
|
| 211 |
+
'n': 5
|
| 212 |
+
over_sample_rate: 0
|
| 213 |
+
multi_stage_wake_up: false
|
| 214 |
+
engine_kwargs:
|
| 215 |
+
vllm: {}
|
| 216 |
+
sglang: {}
|
| 217 |
+
val_kwargs:
|
| 218 |
+
_target_: verl.workers.config.SamplingConfig
|
| 219 |
+
top_k: -1
|
| 220 |
+
top_p: 1.0
|
| 221 |
+
temperature: 0
|
| 222 |
+
'n': 1
|
| 223 |
+
do_sample: false
|
| 224 |
+
multi_turn:
|
| 225 |
+
_target_: verl.workers.config.MultiTurnConfig
|
| 226 |
+
enable: false
|
| 227 |
+
max_assistant_turns: null
|
| 228 |
+
tool_config_path: null
|
| 229 |
+
max_user_turns: null
|
| 230 |
+
max_parallel_calls: 1
|
| 231 |
+
max_tool_response_length: 256
|
| 232 |
+
tool_response_truncate_side: middle
|
| 233 |
+
interaction_config_path: null
|
| 234 |
+
use_inference_chat_template: false
|
| 235 |
+
tokenization_sanity_check_mode: strict
|
| 236 |
+
format: hermes
|
| 237 |
+
num_repeat_rollouts: null
|
| 238 |
+
calculate_log_probs: false
|
| 239 |
+
agent:
|
| 240 |
+
_target_: verl.workers.config.AgentLoopConfig
|
| 241 |
+
num_workers: 8
|
| 242 |
+
default_agent_loop: single_turn_agent
|
| 243 |
+
agent_loop_config_path: null
|
| 244 |
+
custom_async_server:
|
| 245 |
+
_target_: verl.workers.config.CustomAsyncServerConfig
|
| 246 |
+
path: null
|
| 247 |
+
name: null
|
| 248 |
+
update_weights_bucket_megabytes: 512
|
| 249 |
+
trace:
|
| 250 |
+
_target_: verl.workers.config.TraceConfig
|
| 251 |
+
backend: null
|
| 252 |
+
token2text: false
|
| 253 |
+
max_samples_per_step_per_worker: null
|
| 254 |
+
skip_rollout: false
|
| 255 |
+
skip_dump_dir: /tmp/rollout_dump
|
| 256 |
+
skip_tokenizer_init: true
|
| 257 |
+
enable_rollout_routing_replay: false
|
| 258 |
+
profiler:
|
| 259 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 260 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 261 |
+
enable: ${oc.select:actor_rollout_ref.actor.profiler.enable,false}
|
| 262 |
+
all_ranks: ${oc.select:actor_rollout_ref.actor.profiler.all_ranks,false}
|
| 263 |
+
ranks: ${oc.select:actor_rollout_ref.actor.profiler.ranks,[]}
|
| 264 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 265 |
+
tool_config: ${oc.select:actor_rollout_ref.actor.profiler.tool_config,null}
|
| 266 |
+
prometheus:
|
| 267 |
+
_target_: verl.workers.config.PrometheusConfig
|
| 268 |
+
enable: false
|
| 269 |
+
port: 9090
|
| 270 |
+
file: /tmp/ray/session_latest/metrics/prometheus/prometheus.yml
|
| 271 |
+
served_model_name: ${oc.select:actor_rollout_ref.model.path,null}
|
| 272 |
+
layered_summon: true
|
| 273 |
+
model:
|
| 274 |
+
_target_: verl.workers.config.HFModelConfig
|
| 275 |
+
path: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 276 |
+
hf_config_path: null
|
| 277 |
+
tokenizer_path: null
|
| 278 |
+
use_shm: false
|
| 279 |
+
trust_remote_code: false
|
| 280 |
+
custom_chat_template: null
|
| 281 |
+
external_lib: null
|
| 282 |
+
override_config: {}
|
| 283 |
+
enable_gradient_checkpointing: true
|
| 284 |
+
enable_activation_offload: false
|
| 285 |
+
use_remove_padding: true
|
| 286 |
+
lora_rank: 0
|
| 287 |
+
lora_alpha: 16
|
| 288 |
+
target_modules: all-linear
|
| 289 |
+
exclude_modules: null
|
| 290 |
+
lora_adapter_path: null
|
| 291 |
+
use_liger: false
|
| 292 |
+
use_fused_kernels: false
|
| 293 |
+
fused_kernel_options:
|
| 294 |
+
impl_backend: torch
|
| 295 |
+
hybrid_engine: true
|
| 296 |
+
nccl_timeout: 600
|
| 297 |
+
data:
|
| 298 |
+
tokenizer: null
|
| 299 |
+
use_shm: false
|
| 300 |
+
train_files: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/train.parquet
|
| 301 |
+
val_files: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/test.parquet
|
| 302 |
+
train_max_samples: -1
|
| 303 |
+
val_max_samples: -1
|
| 304 |
+
prompt_key: prompt
|
| 305 |
+
reward_fn_key: data_source
|
| 306 |
+
max_prompt_length: 512
|
| 307 |
+
max_response_length: 128
|
| 308 |
+
train_batch_size: 1024
|
| 309 |
+
val_batch_size: null
|
| 310 |
+
tool_config_path: ${oc.select:actor_rollout_ref.rollout.multi_turn.tool_config_path,
|
| 311 |
+
null}
|
| 312 |
+
return_raw_input_ids: false
|
| 313 |
+
return_raw_chat: true
|
| 314 |
+
return_full_prompt: false
|
| 315 |
+
shuffle: false
|
| 316 |
+
seed: null
|
| 317 |
+
dataloader_num_workers: 8
|
| 318 |
+
image_patch_size: 14
|
| 319 |
+
validation_shuffle: false
|
| 320 |
+
filter_overlong_prompts: true
|
| 321 |
+
filter_overlong_prompts_workers: 1
|
| 322 |
+
truncation: error
|
| 323 |
+
image_key: images
|
| 324 |
+
video_key: videos
|
| 325 |
+
trust_remote_code: false
|
| 326 |
+
custom_cls:
|
| 327 |
+
path: null
|
| 328 |
+
name: null
|
| 329 |
+
return_multi_modal_inputs: true
|
| 330 |
+
sampler:
|
| 331 |
+
class_path: null
|
| 332 |
+
class_name: null
|
| 333 |
+
datagen:
|
| 334 |
+
path: null
|
| 335 |
+
name: null
|
| 336 |
+
apply_chat_template_kwargs: {}
|
| 337 |
+
reward_manager:
|
| 338 |
+
_target_: verl.trainer.config.config.RewardManagerConfig
|
| 339 |
+
source: register
|
| 340 |
+
name: ${oc.select:reward_model.reward_manager,naive}
|
| 341 |
+
module:
|
| 342 |
+
_target_: verl.trainer.config.config.ModuleConfig
|
| 343 |
+
path: null
|
| 344 |
+
name: custom_reward_manager
|
| 345 |
+
critic:
|
| 346 |
+
optim:
|
| 347 |
+
_target_: verl.workers.config.FSDPOptimizerConfig
|
| 348 |
+
optimizer: AdamW
|
| 349 |
+
optimizer_impl: torch.optim
|
| 350 |
+
lr: 1.0e-05
|
| 351 |
+
lr_warmup_steps_ratio: 0.0
|
| 352 |
+
total_training_steps: -1
|
| 353 |
+
weight_decay: 0.01
|
| 354 |
+
lr_warmup_steps: -1
|
| 355 |
+
betas:
|
| 356 |
+
- 0.9
|
| 357 |
+
- 0.999
|
| 358 |
+
clip_grad: 1.0
|
| 359 |
+
min_lr_ratio: 0.0
|
| 360 |
+
num_cycles: 0.5
|
| 361 |
+
lr_scheduler_type: constant
|
| 362 |
+
warmup_style: null
|
| 363 |
+
override_optimizer_config: null
|
| 364 |
+
model:
|
| 365 |
+
fsdp_config:
|
| 366 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 367 |
+
wrap_policy:
|
| 368 |
+
min_num_params: 0
|
| 369 |
+
param_offload: false
|
| 370 |
+
optimizer_offload: false
|
| 371 |
+
offload_policy: false
|
| 372 |
+
reshard_after_forward: true
|
| 373 |
+
fsdp_size: -1
|
| 374 |
+
forward_prefetch: false
|
| 375 |
+
model_dtype: fp32
|
| 376 |
+
use_orig_params: false
|
| 377 |
+
seed: 42
|
| 378 |
+
full_determinism: false
|
| 379 |
+
ulysses_sequence_parallel_size: 1
|
| 380 |
+
entropy_from_logits_with_chunking: false
|
| 381 |
+
use_torch_compile: true
|
| 382 |
+
entropy_checkpointing: false
|
| 383 |
+
forward_only: false
|
| 384 |
+
strategy: fsdp
|
| 385 |
+
dtype: bfloat16
|
| 386 |
+
path: ~/models/deepseek-llm-7b-chat
|
| 387 |
+
tokenizer_path: ${oc.select:actor_rollout_ref.model.path,"~/models/deepseek-llm-7b-chat"}
|
| 388 |
+
override_config: {}
|
| 389 |
+
external_lib: ${oc.select:actor_rollout_ref.model.external_lib,null}
|
| 390 |
+
trust_remote_code: ${oc.select:actor_rollout_ref.model.trust_remote_code,false}
|
| 391 |
+
_target_: verl.workers.config.FSDPCriticModelCfg
|
| 392 |
+
use_shm: false
|
| 393 |
+
enable_gradient_checkpointing: true
|
| 394 |
+
enable_activation_offload: false
|
| 395 |
+
use_remove_padding: false
|
| 396 |
+
lora_rank: 0
|
| 397 |
+
lora_alpha: 16
|
| 398 |
+
target_modules: all-linear
|
| 399 |
+
_target_: verl.workers.config.FSDPCriticConfig
|
| 400 |
+
rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
|
| 401 |
+
strategy: fsdp
|
| 402 |
+
enable: null
|
| 403 |
+
ppo_mini_batch_size: ${oc.select:actor_rollout_ref.actor.ppo_mini_batch_size,256}
|
| 404 |
+
ppo_micro_batch_size: null
|
| 405 |
+
ppo_micro_batch_size_per_gpu: ${oc.select:.ppo_micro_batch_size,null}
|
| 406 |
+
use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
|
| 407 |
+
ppo_max_token_len_per_gpu: 32768
|
| 408 |
+
forward_max_token_len_per_gpu: ${.ppo_max_token_len_per_gpu}
|
| 409 |
+
ppo_epochs: ${oc.select:actor_rollout_ref.actor.ppo_epochs,1}
|
| 410 |
+
shuffle: ${oc.select:actor_rollout_ref.actor.shuffle,false}
|
| 411 |
+
cliprange_value: 0.5
|
| 412 |
+
loss_agg_mode: ${oc.select:actor_rollout_ref.actor.loss_agg_mode,token-mean}
|
| 413 |
+
checkpoint:
|
| 414 |
+
_target_: verl.trainer.config.CheckpointConfig
|
| 415 |
+
save_contents:
|
| 416 |
+
- model
|
| 417 |
+
- optimizer
|
| 418 |
+
- extra
|
| 419 |
+
load_contents: ${.save_contents}
|
| 420 |
+
async_save: false
|
| 421 |
+
profiler:
|
| 422 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 423 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 424 |
+
enable: false
|
| 425 |
+
all_ranks: false
|
| 426 |
+
ranks: []
|
| 427 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 428 |
+
tool_config:
|
| 429 |
+
nsys:
|
| 430 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 431 |
+
discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
|
| 432 |
+
npu:
|
| 433 |
+
_target_: verl.utils.profiler.config.NPUToolConfig
|
| 434 |
+
contents: []
|
| 435 |
+
level: level1
|
| 436 |
+
analysis: true
|
| 437 |
+
discrete: false
|
| 438 |
+
torch:
|
| 439 |
+
_target_: verl.utils.profiler.config.TorchProfilerToolConfig
|
| 440 |
+
step_start: 0
|
| 441 |
+
step_end: null
|
| 442 |
+
torch_memory:
|
| 443 |
+
_target_: verl.utils.profiler.config.TorchMemoryToolConfig
|
| 444 |
+
trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
|
| 445 |
+
stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
|
| 446 |
+
forward_micro_batch_size: ${oc.select:.ppo_micro_batch_size,null}
|
| 447 |
+
forward_micro_batch_size_per_gpu: ${oc.select:.ppo_micro_batch_size_per_gpu,null}
|
| 448 |
+
ulysses_sequence_parallel_size: 1
|
| 449 |
+
grad_clip: 1.0
|
| 450 |
+
reward_model:
|
| 451 |
+
enable: true
|
| 452 |
+
enable_resource_pool: false
|
| 453 |
+
n_gpus_per_node: 0
|
| 454 |
+
nnodes: 0
|
| 455 |
+
strategy: fsdp
|
| 456 |
+
model:
|
| 457 |
+
input_tokenizer: ${actor_rollout_ref.model.path}
|
| 458 |
+
path: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/reward_model_converted
|
| 459 |
+
external_lib: ${actor_rollout_ref.model.external_lib}
|
| 460 |
+
trust_remote_code: false
|
| 461 |
+
override_config: {}
|
| 462 |
+
use_shm: false
|
| 463 |
+
use_remove_padding: false
|
| 464 |
+
use_fused_kernels: ${actor_rollout_ref.model.use_fused_kernels}
|
| 465 |
+
fsdp_config:
|
| 466 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 467 |
+
wrap_policy:
|
| 468 |
+
min_num_params: 0
|
| 469 |
+
param_offload: false
|
| 470 |
+
reshard_after_forward: true
|
| 471 |
+
fsdp_size: -1
|
| 472 |
+
forward_prefetch: false
|
| 473 |
+
micro_batch_size: null
|
| 474 |
+
micro_batch_size_per_gpu: 32
|
| 475 |
+
max_length: null
|
| 476 |
+
use_dynamic_bsz: ${critic.use_dynamic_bsz}
|
| 477 |
+
forward_max_token_len_per_gpu: ${critic.forward_max_token_len_per_gpu}
|
| 478 |
+
reward_manager: naive
|
| 479 |
+
launch_reward_fn_async: false
|
| 480 |
+
sandbox_fusion:
|
| 481 |
+
url: null
|
| 482 |
+
max_concurrent: 64
|
| 483 |
+
memory_limit_mb: 1024
|
| 484 |
+
profiler:
|
| 485 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 486 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 487 |
+
enable: false
|
| 488 |
+
all_ranks: false
|
| 489 |
+
ranks: []
|
| 490 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 491 |
+
tool_config: ${oc.select:actor_rollout_ref.actor.profiler.tool_config,null}
|
| 492 |
+
ulysses_sequence_parallel_size: 1
|
| 493 |
+
use_reward_loop: true
|
| 494 |
+
rollout:
|
| 495 |
+
_target_: verl.workers.config.RolloutConfig
|
| 496 |
+
name: ???
|
| 497 |
+
dtype: bfloat16
|
| 498 |
+
gpu_memory_utilization: 0.5
|
| 499 |
+
enforce_eager: true
|
| 500 |
+
cudagraph_capture_sizes: null
|
| 501 |
+
free_cache_engine: true
|
| 502 |
+
data_parallel_size: 1
|
| 503 |
+
expert_parallel_size: 1
|
| 504 |
+
tensor_model_parallel_size: 2
|
| 505 |
+
max_num_batched_tokens: 8192
|
| 506 |
+
max_model_len: null
|
| 507 |
+
max_num_seqs: 1024
|
| 508 |
+
load_format: auto
|
| 509 |
+
engine_kwargs: {}
|
| 510 |
+
limit_images: null
|
| 511 |
+
enable_chunked_prefill: true
|
| 512 |
+
enable_prefix_caching: true
|
| 513 |
+
disable_log_stats: true
|
| 514 |
+
skip_tokenizer_init: true
|
| 515 |
+
prompt_length: 512
|
| 516 |
+
response_length: 512
|
| 517 |
+
algorithm:
|
| 518 |
+
rollout_correction:
|
| 519 |
+
rollout_is: null
|
| 520 |
+
rollout_is_threshold: 2.0
|
| 521 |
+
rollout_rs: null
|
| 522 |
+
rollout_rs_threshold: null
|
| 523 |
+
rollout_rs_threshold_lower: null
|
| 524 |
+
rollout_token_veto_threshold: null
|
| 525 |
+
bypass_mode: false
|
| 526 |
+
use_policy_gradient: false
|
| 527 |
+
rollout_is_batch_normalize: false
|
| 528 |
+
_target_: verl.trainer.config.AlgoConfig
|
| 529 |
+
gamma: 1.0
|
| 530 |
+
lam: 1.0
|
| 531 |
+
adv_estimator: grpo
|
| 532 |
+
norm_adv_by_std_in_grpo: true
|
| 533 |
+
use_kl_in_reward: false
|
| 534 |
+
kl_penalty: kl
|
| 535 |
+
kl_ctrl:
|
| 536 |
+
_target_: verl.trainer.config.KLControlConfig
|
| 537 |
+
type: fixed
|
| 538 |
+
kl_coef: 0.001
|
| 539 |
+
horizon: 10000
|
| 540 |
+
target_kl: 0.1
|
| 541 |
+
use_pf_ppo: false
|
| 542 |
+
pf_ppo:
|
| 543 |
+
reweight_method: pow
|
| 544 |
+
weight_pow: 2.0
|
| 545 |
+
custom_reward_function:
|
| 546 |
+
path: null
|
| 547 |
+
name: compute_score
|
| 548 |
+
trainer:
|
| 549 |
+
balance_batch: true
|
| 550 |
+
total_epochs: 15
|
| 551 |
+
total_training_steps: null
|
| 552 |
+
project_name: verl_grpo_gsm8k
|
| 553 |
+
experiment_name: qwen3_4b_gsm8k_grpo
|
| 554 |
+
logger:
|
| 555 |
+
- console
|
| 556 |
+
- wandb
|
| 557 |
+
log_val_generations: 0
|
| 558 |
+
rollout_data_dir: null
|
| 559 |
+
validation_data_dir: null
|
| 560 |
+
nnodes: 1
|
| 561 |
+
n_gpus_per_node: 8
|
| 562 |
+
save_freq: 20
|
| 563 |
+
esi_redundant_time: 0
|
| 564 |
+
resume_mode: disable
|
| 565 |
+
resume_from_path: null
|
| 566 |
+
val_before_train: true
|
| 567 |
+
val_only: false
|
| 568 |
+
test_freq: 5
|
| 569 |
+
critic_warmup: 0
|
| 570 |
+
default_hdfs_dir: null
|
| 571 |
+
del_local_ckpt_after_load: false
|
| 572 |
+
default_local_dir: checkpoints/${trainer.project_name}/${trainer.experiment_name}
|
| 573 |
+
max_actor_ckpt_to_keep: null
|
| 574 |
+
max_critic_ckpt_to_keep: null
|
| 575 |
+
ray_wait_register_center_timeout: 300
|
| 576 |
+
device: cuda
|
| 577 |
+
use_legacy_worker_impl: auto
|
| 578 |
+
global_profiler:
|
| 579 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 580 |
+
tool: null
|
| 581 |
+
steps: null
|
| 582 |
+
profile_continuous_steps: false
|
| 583 |
+
save_path: outputs/profile
|
| 584 |
+
global_tool_config:
|
| 585 |
+
nsys:
|
| 586 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 587 |
+
discrete: false
|
| 588 |
+
controller_nsight_options:
|
| 589 |
+
trace: cuda,nvtx,cublas,ucx
|
| 590 |
+
cuda-memory-usage: 'true'
|
| 591 |
+
cuda-graph-trace: graph
|
| 592 |
+
worker_nsight_options:
|
| 593 |
+
trace: cuda,nvtx,cublas,ucx
|
| 594 |
+
cuda-memory-usage: 'true'
|
| 595 |
+
cuda-graph-trace: graph
|
| 596 |
+
capture-range: cudaProfilerApi
|
| 597 |
+
capture-range-end: null
|
| 598 |
+
kill: none
|
| 599 |
+
torch_memory:
|
| 600 |
+
trace_alloc_max_entries: 100000
|
| 601 |
+
stack_depth: 32
|
| 602 |
+
context: all
|
| 603 |
+
stacks: all
|
| 604 |
+
kw_args: {}
|
| 605 |
+
transfer_queue:
|
| 606 |
+
enable: false
|
| 607 |
+
ray_kwargs:
|
| 608 |
+
ray_init:
|
| 609 |
+
num_cpus: null
|
| 610 |
+
timeline_json_file: null
|
examples/grpo_trainer/outputs/2026-01-26/17-05-09/.hydra/overrides.yaml
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
- algorithm.adv_estimator=grpo
|
| 2 |
+
- data.train_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/train.parquet
|
| 3 |
+
- data.val_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/test.parquet
|
| 4 |
+
- data.train_batch_size=1024
|
| 5 |
+
- data.max_prompt_length=512
|
| 6 |
+
- data.max_response_length=128
|
| 7 |
+
- data.filter_overlong_prompts=True
|
| 8 |
+
- data.truncation=error
|
| 9 |
+
- data.shuffle=False
|
| 10 |
+
- actor_rollout_ref.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 11 |
+
- actor_rollout_ref.actor.optim.lr=1e-6
|
| 12 |
+
- actor_rollout_ref.model.use_remove_padding=True
|
| 13 |
+
- actor_rollout_ref.actor.ppo_mini_batch_size=256
|
| 14 |
+
- actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=32
|
| 15 |
+
- actor_rollout_ref.actor.use_kl_loss=True
|
| 16 |
+
- actor_rollout_ref.actor.kl_loss_coef=0.001
|
| 17 |
+
- actor_rollout_ref.actor.kl_loss_type=low_var_kl
|
| 18 |
+
- actor_rollout_ref.actor.entropy_coeff=0
|
| 19 |
+
- actor_rollout_ref.model.enable_gradient_checkpointing=True
|
| 20 |
+
- actor_rollout_ref.actor.fsdp_config.param_offload=True
|
| 21 |
+
- actor_rollout_ref.actor.fsdp_config.optimizer_offload=False
|
| 22 |
+
- actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32
|
| 23 |
+
- actor_rollout_ref.rollout.tensor_model_parallel_size=2
|
| 24 |
+
- actor_rollout_ref.rollout.name=vllm
|
| 25 |
+
- actor_rollout_ref.rollout.gpu_memory_utilization=0.6
|
| 26 |
+
- actor_rollout_ref.rollout.n=5
|
| 27 |
+
- actor_rollout_ref.rollout.load_format=safetensors
|
| 28 |
+
- actor_rollout_ref.rollout.layered_summon=True
|
| 29 |
+
- actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32
|
| 30 |
+
- actor_rollout_ref.ref.fsdp_config.param_offload=False
|
| 31 |
+
- algorithm.use_kl_in_reward=False
|
| 32 |
+
- reward_model.enable=True
|
| 33 |
+
- reward_model.enable=True
|
| 34 |
+
- reward_model.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/reward_model_converted
|
| 35 |
+
- reward_model.micro_batch_size_per_gpu=32
|
| 36 |
+
- trainer.critic_warmup=0
|
| 37 |
+
- trainer.logger=["console","wandb"]
|
| 38 |
+
- trainer.project_name=verl_grpo_gsm8k
|
| 39 |
+
- trainer.experiment_name=qwen3_4b_gsm8k_grpo
|
| 40 |
+
- trainer.n_gpus_per_node=8
|
| 41 |
+
- trainer.nnodes=1
|
| 42 |
+
- trainer.save_freq=20
|
| 43 |
+
- trainer.test_freq=5
|
| 44 |
+
- trainer.total_epochs=15
|
| 45 |
+
- trainer.resume_mode=disable
|
examples/grpo_trainer/outputs/2026-01-26/17-07-54/.hydra/config.yaml
ADDED
|
@@ -0,0 +1,610 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
actor_rollout_ref:
|
| 2 |
+
actor:
|
| 3 |
+
optim:
|
| 4 |
+
_target_: verl.workers.config.FSDPOptimizerConfig
|
| 5 |
+
optimizer: AdamW
|
| 6 |
+
optimizer_impl: torch.optim
|
| 7 |
+
lr: 1.0e-06
|
| 8 |
+
lr_warmup_steps_ratio: 0.0
|
| 9 |
+
total_training_steps: -1
|
| 10 |
+
weight_decay: 0.01
|
| 11 |
+
lr_warmup_steps: -1
|
| 12 |
+
betas:
|
| 13 |
+
- 0.9
|
| 14 |
+
- 0.999
|
| 15 |
+
clip_grad: 1.0
|
| 16 |
+
min_lr_ratio: 0.0
|
| 17 |
+
num_cycles: 0.5
|
| 18 |
+
lr_scheduler_type: constant
|
| 19 |
+
warmup_style: null
|
| 20 |
+
override_optimizer_config: null
|
| 21 |
+
fsdp_config:
|
| 22 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 23 |
+
wrap_policy:
|
| 24 |
+
min_num_params: 0
|
| 25 |
+
param_offload: true
|
| 26 |
+
optimizer_offload: false
|
| 27 |
+
offload_policy: false
|
| 28 |
+
reshard_after_forward: true
|
| 29 |
+
fsdp_size: -1
|
| 30 |
+
forward_prefetch: false
|
| 31 |
+
model_dtype: fp32
|
| 32 |
+
use_orig_params: false
|
| 33 |
+
seed: 42
|
| 34 |
+
full_determinism: false
|
| 35 |
+
ulysses_sequence_parallel_size: 1
|
| 36 |
+
entropy_from_logits_with_chunking: false
|
| 37 |
+
use_torch_compile: true
|
| 38 |
+
entropy_checkpointing: false
|
| 39 |
+
forward_only: false
|
| 40 |
+
strategy: fsdp
|
| 41 |
+
dtype: bfloat16
|
| 42 |
+
_target_: verl.workers.config.FSDPActorConfig
|
| 43 |
+
rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
|
| 44 |
+
strategy: fsdp
|
| 45 |
+
ppo_mini_batch_size: 256
|
| 46 |
+
ppo_micro_batch_size: null
|
| 47 |
+
ppo_micro_batch_size_per_gpu: 32
|
| 48 |
+
use_dynamic_bsz: false
|
| 49 |
+
ppo_max_token_len_per_gpu: 16384
|
| 50 |
+
clip_ratio: 0.2
|
| 51 |
+
clip_ratio_low: 0.2
|
| 52 |
+
clip_ratio_high: 0.2
|
| 53 |
+
freeze_vision_tower: false
|
| 54 |
+
policy_loss:
|
| 55 |
+
_target_: verl.workers.config.PolicyLossConfig
|
| 56 |
+
loss_mode: vanilla
|
| 57 |
+
clip_cov_ratio: 0.0002
|
| 58 |
+
clip_cov_lb: 1.0
|
| 59 |
+
clip_cov_ub: 5.0
|
| 60 |
+
kl_cov_ratio: 0.0002
|
| 61 |
+
ppo_kl_coef: 0.1
|
| 62 |
+
clip_ratio_c: 3.0
|
| 63 |
+
loss_agg_mode: token-mean
|
| 64 |
+
loss_scale_factor: null
|
| 65 |
+
entropy_coeff: 0
|
| 66 |
+
calculate_entropy: false
|
| 67 |
+
use_kl_loss: true
|
| 68 |
+
use_torch_compile: true
|
| 69 |
+
kl_loss_coef: 0.001
|
| 70 |
+
kl_loss_type: low_var_kl
|
| 71 |
+
ppo_epochs: 1
|
| 72 |
+
shuffle: false
|
| 73 |
+
checkpoint:
|
| 74 |
+
_target_: verl.trainer.config.CheckpointConfig
|
| 75 |
+
save_contents:
|
| 76 |
+
- model
|
| 77 |
+
- optimizer
|
| 78 |
+
- extra
|
| 79 |
+
load_contents: ${.save_contents}
|
| 80 |
+
async_save: false
|
| 81 |
+
use_fused_kernels: ${oc.select:actor_rollout_ref.model.use_fused_kernels,false}
|
| 82 |
+
profiler:
|
| 83 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 84 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 85 |
+
enable: false
|
| 86 |
+
all_ranks: false
|
| 87 |
+
ranks: []
|
| 88 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 89 |
+
tool_config:
|
| 90 |
+
nsys:
|
| 91 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 92 |
+
discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
|
| 93 |
+
npu:
|
| 94 |
+
_target_: verl.utils.profiler.config.NPUToolConfig
|
| 95 |
+
contents: []
|
| 96 |
+
level: level1
|
| 97 |
+
analysis: true
|
| 98 |
+
discrete: false
|
| 99 |
+
torch:
|
| 100 |
+
_target_: verl.utils.profiler.config.TorchProfilerToolConfig
|
| 101 |
+
step_start: 0
|
| 102 |
+
step_end: null
|
| 103 |
+
torch_memory:
|
| 104 |
+
_target_: verl.utils.profiler.config.TorchMemoryToolConfig
|
| 105 |
+
trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
|
| 106 |
+
stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
|
| 107 |
+
router_replay:
|
| 108 |
+
_target_: verl.workers.config.RouterReplayConfig
|
| 109 |
+
mode: disabled
|
| 110 |
+
record_file: null
|
| 111 |
+
replay_file: null
|
| 112 |
+
grad_clip: 1.0
|
| 113 |
+
ulysses_sequence_parallel_size: 1
|
| 114 |
+
entropy_from_logits_with_chunking: false
|
| 115 |
+
entropy_checkpointing: false
|
| 116 |
+
use_remove_padding: ${oc.select:actor_rollout_ref.model.use_remove_padding,false}
|
| 117 |
+
ref:
|
| 118 |
+
rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
|
| 119 |
+
strategy: ${actor_rollout_ref.actor.strategy}
|
| 120 |
+
use_torch_compile: ${oc.select:actor_rollout_ref.actor.use_torch_compile,true}
|
| 121 |
+
log_prob_micro_batch_size: null
|
| 122 |
+
log_prob_micro_batch_size_per_gpu: 32
|
| 123 |
+
log_prob_use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
|
| 124 |
+
log_prob_max_token_len_per_gpu: ${oc.select:actor_rollout_ref.actor.ppo_max_token_len_per_gpu,16384}
|
| 125 |
+
profiler:
|
| 126 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 127 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 128 |
+
enable: false
|
| 129 |
+
all_ranks: false
|
| 130 |
+
ranks: []
|
| 131 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 132 |
+
tool_config:
|
| 133 |
+
nsys:
|
| 134 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 135 |
+
discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
|
| 136 |
+
npu:
|
| 137 |
+
_target_: verl.utils.profiler.config.NPUToolConfig
|
| 138 |
+
contents: []
|
| 139 |
+
level: level1
|
| 140 |
+
analysis: true
|
| 141 |
+
discrete: false
|
| 142 |
+
torch:
|
| 143 |
+
_target_: verl.utils.profiler.config.TorchProfilerToolConfig
|
| 144 |
+
step_start: 0
|
| 145 |
+
step_end: null
|
| 146 |
+
torch_memory:
|
| 147 |
+
_target_: verl.utils.profiler.config.TorchMemoryToolConfig
|
| 148 |
+
trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
|
| 149 |
+
stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
|
| 150 |
+
router_replay:
|
| 151 |
+
_target_: verl.workers.config.RouterReplayConfig
|
| 152 |
+
mode: disabled
|
| 153 |
+
record_file: null
|
| 154 |
+
replay_file: null
|
| 155 |
+
fsdp_config:
|
| 156 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 157 |
+
wrap_policy:
|
| 158 |
+
min_num_params: 0
|
| 159 |
+
param_offload: false
|
| 160 |
+
optimizer_offload: false
|
| 161 |
+
offload_policy: false
|
| 162 |
+
reshard_after_forward: true
|
| 163 |
+
fsdp_size: -1
|
| 164 |
+
forward_prefetch: false
|
| 165 |
+
model_dtype: fp32
|
| 166 |
+
use_orig_params: false
|
| 167 |
+
seed: 42
|
| 168 |
+
full_determinism: false
|
| 169 |
+
ulysses_sequence_parallel_size: 1
|
| 170 |
+
entropy_from_logits_with_chunking: false
|
| 171 |
+
use_torch_compile: true
|
| 172 |
+
entropy_checkpointing: false
|
| 173 |
+
forward_only: true
|
| 174 |
+
strategy: fsdp
|
| 175 |
+
dtype: bfloat16
|
| 176 |
+
_target_: verl.workers.config.FSDPActorConfig
|
| 177 |
+
ulysses_sequence_parallel_size: ${oc.select:actor_rollout_ref.actor.ulysses_sequence_parallel_size,1}
|
| 178 |
+
entropy_from_logits_with_chunking: false
|
| 179 |
+
entropy_checkpointing: false
|
| 180 |
+
rollout:
|
| 181 |
+
_target_: verl.workers.config.RolloutConfig
|
| 182 |
+
name: vllm
|
| 183 |
+
mode: async
|
| 184 |
+
temperature: 1.0
|
| 185 |
+
top_k: -1
|
| 186 |
+
top_p: 1
|
| 187 |
+
prompt_length: ${oc.select:data.max_prompt_length,512}
|
| 188 |
+
response_length: ${oc.select:data.max_response_length,512}
|
| 189 |
+
dtype: bfloat16
|
| 190 |
+
gpu_memory_utilization: 0.6
|
| 191 |
+
ignore_eos: false
|
| 192 |
+
enforce_eager: false
|
| 193 |
+
cudagraph_capture_sizes: null
|
| 194 |
+
free_cache_engine: true
|
| 195 |
+
tensor_model_parallel_size: 2
|
| 196 |
+
data_parallel_size: 1
|
| 197 |
+
expert_parallel_size: 1
|
| 198 |
+
pipeline_model_parallel_size: 1
|
| 199 |
+
max_num_batched_tokens: 8192
|
| 200 |
+
max_model_len: null
|
| 201 |
+
max_num_seqs: 1024
|
| 202 |
+
enable_chunked_prefill: true
|
| 203 |
+
enable_prefix_caching: true
|
| 204 |
+
load_format: safetensors
|
| 205 |
+
log_prob_micro_batch_size: null
|
| 206 |
+
log_prob_micro_batch_size_per_gpu: 32
|
| 207 |
+
log_prob_use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
|
| 208 |
+
log_prob_max_token_len_per_gpu: ${oc.select:actor_rollout_ref.actor.ppo_max_token_len_per_gpu,16384}
|
| 209 |
+
disable_log_stats: true
|
| 210 |
+
do_sample: true
|
| 211 |
+
'n': 5
|
| 212 |
+
over_sample_rate: 0
|
| 213 |
+
multi_stage_wake_up: false
|
| 214 |
+
engine_kwargs:
|
| 215 |
+
vllm: {}
|
| 216 |
+
sglang: {}
|
| 217 |
+
val_kwargs:
|
| 218 |
+
_target_: verl.workers.config.SamplingConfig
|
| 219 |
+
top_k: -1
|
| 220 |
+
top_p: 1.0
|
| 221 |
+
temperature: 0
|
| 222 |
+
'n': 1
|
| 223 |
+
do_sample: false
|
| 224 |
+
multi_turn:
|
| 225 |
+
_target_: verl.workers.config.MultiTurnConfig
|
| 226 |
+
enable: false
|
| 227 |
+
max_assistant_turns: null
|
| 228 |
+
tool_config_path: null
|
| 229 |
+
max_user_turns: null
|
| 230 |
+
max_parallel_calls: 1
|
| 231 |
+
max_tool_response_length: 256
|
| 232 |
+
tool_response_truncate_side: middle
|
| 233 |
+
interaction_config_path: null
|
| 234 |
+
use_inference_chat_template: false
|
| 235 |
+
tokenization_sanity_check_mode: strict
|
| 236 |
+
format: hermes
|
| 237 |
+
num_repeat_rollouts: null
|
| 238 |
+
calculate_log_probs: false
|
| 239 |
+
agent:
|
| 240 |
+
_target_: verl.workers.config.AgentLoopConfig
|
| 241 |
+
num_workers: 8
|
| 242 |
+
default_agent_loop: single_turn_agent
|
| 243 |
+
agent_loop_config_path: null
|
| 244 |
+
custom_async_server:
|
| 245 |
+
_target_: verl.workers.config.CustomAsyncServerConfig
|
| 246 |
+
path: null
|
| 247 |
+
name: null
|
| 248 |
+
update_weights_bucket_megabytes: 512
|
| 249 |
+
trace:
|
| 250 |
+
_target_: verl.workers.config.TraceConfig
|
| 251 |
+
backend: null
|
| 252 |
+
token2text: false
|
| 253 |
+
max_samples_per_step_per_worker: null
|
| 254 |
+
skip_rollout: false
|
| 255 |
+
skip_dump_dir: /tmp/rollout_dump
|
| 256 |
+
skip_tokenizer_init: true
|
| 257 |
+
enable_rollout_routing_replay: false
|
| 258 |
+
profiler:
|
| 259 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 260 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 261 |
+
enable: ${oc.select:actor_rollout_ref.actor.profiler.enable,false}
|
| 262 |
+
all_ranks: ${oc.select:actor_rollout_ref.actor.profiler.all_ranks,false}
|
| 263 |
+
ranks: ${oc.select:actor_rollout_ref.actor.profiler.ranks,[]}
|
| 264 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 265 |
+
tool_config: ${oc.select:actor_rollout_ref.actor.profiler.tool_config,null}
|
| 266 |
+
prometheus:
|
| 267 |
+
_target_: verl.workers.config.PrometheusConfig
|
| 268 |
+
enable: false
|
| 269 |
+
port: 9090
|
| 270 |
+
file: /tmp/ray/session_latest/metrics/prometheus/prometheus.yml
|
| 271 |
+
served_model_name: ${oc.select:actor_rollout_ref.model.path,null}
|
| 272 |
+
layered_summon: true
|
| 273 |
+
model:
|
| 274 |
+
_target_: verl.workers.config.HFModelConfig
|
| 275 |
+
path: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 276 |
+
hf_config_path: null
|
| 277 |
+
tokenizer_path: null
|
| 278 |
+
use_shm: false
|
| 279 |
+
trust_remote_code: false
|
| 280 |
+
custom_chat_template: null
|
| 281 |
+
external_lib: null
|
| 282 |
+
override_config: {}
|
| 283 |
+
enable_gradient_checkpointing: true
|
| 284 |
+
enable_activation_offload: false
|
| 285 |
+
use_remove_padding: true
|
| 286 |
+
lora_rank: 0
|
| 287 |
+
lora_alpha: 16
|
| 288 |
+
target_modules: all-linear
|
| 289 |
+
exclude_modules: null
|
| 290 |
+
lora_adapter_path: null
|
| 291 |
+
use_liger: false
|
| 292 |
+
use_fused_kernels: false
|
| 293 |
+
fused_kernel_options:
|
| 294 |
+
impl_backend: torch
|
| 295 |
+
hybrid_engine: true
|
| 296 |
+
nccl_timeout: 600
|
| 297 |
+
data:
|
| 298 |
+
tokenizer: null
|
| 299 |
+
use_shm: false
|
| 300 |
+
train_files: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/train.parquet
|
| 301 |
+
val_files: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/test.parquet
|
| 302 |
+
train_max_samples: -1
|
| 303 |
+
val_max_samples: -1
|
| 304 |
+
prompt_key: prompt
|
| 305 |
+
reward_fn_key: data_source
|
| 306 |
+
max_prompt_length: 512
|
| 307 |
+
max_response_length: 128
|
| 308 |
+
train_batch_size: 1024
|
| 309 |
+
val_batch_size: null
|
| 310 |
+
tool_config_path: ${oc.select:actor_rollout_ref.rollout.multi_turn.tool_config_path,
|
| 311 |
+
null}
|
| 312 |
+
return_raw_input_ids: false
|
| 313 |
+
return_raw_chat: true
|
| 314 |
+
return_full_prompt: false
|
| 315 |
+
shuffle: false
|
| 316 |
+
seed: null
|
| 317 |
+
dataloader_num_workers: 8
|
| 318 |
+
image_patch_size: 14
|
| 319 |
+
validation_shuffle: false
|
| 320 |
+
filter_overlong_prompts: true
|
| 321 |
+
filter_overlong_prompts_workers: 1
|
| 322 |
+
truncation: error
|
| 323 |
+
image_key: images
|
| 324 |
+
video_key: videos
|
| 325 |
+
trust_remote_code: false
|
| 326 |
+
custom_cls:
|
| 327 |
+
path: null
|
| 328 |
+
name: null
|
| 329 |
+
return_multi_modal_inputs: true
|
| 330 |
+
sampler:
|
| 331 |
+
class_path: null
|
| 332 |
+
class_name: null
|
| 333 |
+
datagen:
|
| 334 |
+
path: null
|
| 335 |
+
name: null
|
| 336 |
+
apply_chat_template_kwargs: {}
|
| 337 |
+
reward_manager:
|
| 338 |
+
_target_: verl.trainer.config.config.RewardManagerConfig
|
| 339 |
+
source: register
|
| 340 |
+
name: ${oc.select:reward_model.reward_manager,naive}
|
| 341 |
+
module:
|
| 342 |
+
_target_: verl.trainer.config.config.ModuleConfig
|
| 343 |
+
path: null
|
| 344 |
+
name: custom_reward_manager
|
| 345 |
+
critic:
|
| 346 |
+
optim:
|
| 347 |
+
_target_: verl.workers.config.FSDPOptimizerConfig
|
| 348 |
+
optimizer: AdamW
|
| 349 |
+
optimizer_impl: torch.optim
|
| 350 |
+
lr: 1.0e-05
|
| 351 |
+
lr_warmup_steps_ratio: 0.0
|
| 352 |
+
total_training_steps: -1
|
| 353 |
+
weight_decay: 0.01
|
| 354 |
+
lr_warmup_steps: -1
|
| 355 |
+
betas:
|
| 356 |
+
- 0.9
|
| 357 |
+
- 0.999
|
| 358 |
+
clip_grad: 1.0
|
| 359 |
+
min_lr_ratio: 0.0
|
| 360 |
+
num_cycles: 0.5
|
| 361 |
+
lr_scheduler_type: constant
|
| 362 |
+
warmup_style: null
|
| 363 |
+
override_optimizer_config: null
|
| 364 |
+
model:
|
| 365 |
+
fsdp_config:
|
| 366 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 367 |
+
wrap_policy:
|
| 368 |
+
min_num_params: 0
|
| 369 |
+
param_offload: false
|
| 370 |
+
optimizer_offload: false
|
| 371 |
+
offload_policy: false
|
| 372 |
+
reshard_after_forward: true
|
| 373 |
+
fsdp_size: -1
|
| 374 |
+
forward_prefetch: false
|
| 375 |
+
model_dtype: fp32
|
| 376 |
+
use_orig_params: false
|
| 377 |
+
seed: 42
|
| 378 |
+
full_determinism: false
|
| 379 |
+
ulysses_sequence_parallel_size: 1
|
| 380 |
+
entropy_from_logits_with_chunking: false
|
| 381 |
+
use_torch_compile: true
|
| 382 |
+
entropy_checkpointing: false
|
| 383 |
+
forward_only: false
|
| 384 |
+
strategy: fsdp
|
| 385 |
+
dtype: bfloat16
|
| 386 |
+
path: ~/models/deepseek-llm-7b-chat
|
| 387 |
+
tokenizer_path: ${oc.select:actor_rollout_ref.model.path,"~/models/deepseek-llm-7b-chat"}
|
| 388 |
+
override_config: {}
|
| 389 |
+
external_lib: ${oc.select:actor_rollout_ref.model.external_lib,null}
|
| 390 |
+
trust_remote_code: ${oc.select:actor_rollout_ref.model.trust_remote_code,false}
|
| 391 |
+
_target_: verl.workers.config.FSDPCriticModelCfg
|
| 392 |
+
use_shm: false
|
| 393 |
+
enable_gradient_checkpointing: true
|
| 394 |
+
enable_activation_offload: false
|
| 395 |
+
use_remove_padding: false
|
| 396 |
+
lora_rank: 0
|
| 397 |
+
lora_alpha: 16
|
| 398 |
+
target_modules: all-linear
|
| 399 |
+
_target_: verl.workers.config.FSDPCriticConfig
|
| 400 |
+
rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
|
| 401 |
+
strategy: fsdp
|
| 402 |
+
enable: null
|
| 403 |
+
ppo_mini_batch_size: ${oc.select:actor_rollout_ref.actor.ppo_mini_batch_size,256}
|
| 404 |
+
ppo_micro_batch_size: null
|
| 405 |
+
ppo_micro_batch_size_per_gpu: ${oc.select:.ppo_micro_batch_size,null}
|
| 406 |
+
use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
|
| 407 |
+
ppo_max_token_len_per_gpu: 32768
|
| 408 |
+
forward_max_token_len_per_gpu: ${.ppo_max_token_len_per_gpu}
|
| 409 |
+
ppo_epochs: ${oc.select:actor_rollout_ref.actor.ppo_epochs,1}
|
| 410 |
+
shuffle: ${oc.select:actor_rollout_ref.actor.shuffle,false}
|
| 411 |
+
cliprange_value: 0.5
|
| 412 |
+
loss_agg_mode: ${oc.select:actor_rollout_ref.actor.loss_agg_mode,token-mean}
|
| 413 |
+
checkpoint:
|
| 414 |
+
_target_: verl.trainer.config.CheckpointConfig
|
| 415 |
+
save_contents:
|
| 416 |
+
- model
|
| 417 |
+
- optimizer
|
| 418 |
+
- extra
|
| 419 |
+
load_contents: ${.save_contents}
|
| 420 |
+
async_save: false
|
| 421 |
+
profiler:
|
| 422 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 423 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 424 |
+
enable: false
|
| 425 |
+
all_ranks: false
|
| 426 |
+
ranks: []
|
| 427 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 428 |
+
tool_config:
|
| 429 |
+
nsys:
|
| 430 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 431 |
+
discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
|
| 432 |
+
npu:
|
| 433 |
+
_target_: verl.utils.profiler.config.NPUToolConfig
|
| 434 |
+
contents: []
|
| 435 |
+
level: level1
|
| 436 |
+
analysis: true
|
| 437 |
+
discrete: false
|
| 438 |
+
torch:
|
| 439 |
+
_target_: verl.utils.profiler.config.TorchProfilerToolConfig
|
| 440 |
+
step_start: 0
|
| 441 |
+
step_end: null
|
| 442 |
+
torch_memory:
|
| 443 |
+
_target_: verl.utils.profiler.config.TorchMemoryToolConfig
|
| 444 |
+
trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
|
| 445 |
+
stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
|
| 446 |
+
forward_micro_batch_size: ${oc.select:.ppo_micro_batch_size,null}
|
| 447 |
+
forward_micro_batch_size_per_gpu: ${oc.select:.ppo_micro_batch_size_per_gpu,null}
|
| 448 |
+
ulysses_sequence_parallel_size: 1
|
| 449 |
+
grad_clip: 1.0
|
| 450 |
+
reward_model:
|
| 451 |
+
enable: true
|
| 452 |
+
enable_resource_pool: false
|
| 453 |
+
n_gpus_per_node: 0
|
| 454 |
+
nnodes: 0
|
| 455 |
+
strategy: fsdp
|
| 456 |
+
model:
|
| 457 |
+
input_tokenizer: ${actor_rollout_ref.model.path}
|
| 458 |
+
path: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/reward_model_converted
|
| 459 |
+
external_lib: ${actor_rollout_ref.model.external_lib}
|
| 460 |
+
trust_remote_code: false
|
| 461 |
+
override_config: {}
|
| 462 |
+
use_shm: false
|
| 463 |
+
use_remove_padding: false
|
| 464 |
+
use_fused_kernels: ${actor_rollout_ref.model.use_fused_kernels}
|
| 465 |
+
fsdp_config:
|
| 466 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 467 |
+
wrap_policy:
|
| 468 |
+
min_num_params: 0
|
| 469 |
+
param_offload: false
|
| 470 |
+
reshard_after_forward: true
|
| 471 |
+
fsdp_size: -1
|
| 472 |
+
forward_prefetch: false
|
| 473 |
+
micro_batch_size: null
|
| 474 |
+
micro_batch_size_per_gpu: 32
|
| 475 |
+
max_length: null
|
| 476 |
+
use_dynamic_bsz: ${critic.use_dynamic_bsz}
|
| 477 |
+
forward_max_token_len_per_gpu: ${critic.forward_max_token_len_per_gpu}
|
| 478 |
+
reward_manager: naive
|
| 479 |
+
launch_reward_fn_async: false
|
| 480 |
+
sandbox_fusion:
|
| 481 |
+
url: null
|
| 482 |
+
max_concurrent: 64
|
| 483 |
+
memory_limit_mb: 1024
|
| 484 |
+
profiler:
|
| 485 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 486 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 487 |
+
enable: false
|
| 488 |
+
all_ranks: false
|
| 489 |
+
ranks: []
|
| 490 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 491 |
+
tool_config: ${oc.select:actor_rollout_ref.actor.profiler.tool_config,null}
|
| 492 |
+
ulysses_sequence_parallel_size: 1
|
| 493 |
+
use_reward_loop: true
|
| 494 |
+
rollout:
|
| 495 |
+
_target_: verl.workers.config.RolloutConfig
|
| 496 |
+
name: ???
|
| 497 |
+
dtype: bfloat16
|
| 498 |
+
gpu_memory_utilization: 0.5
|
| 499 |
+
enforce_eager: true
|
| 500 |
+
cudagraph_capture_sizes: null
|
| 501 |
+
free_cache_engine: true
|
| 502 |
+
data_parallel_size: 1
|
| 503 |
+
expert_parallel_size: 1
|
| 504 |
+
tensor_model_parallel_size: 2
|
| 505 |
+
max_num_batched_tokens: 8192
|
| 506 |
+
max_model_len: null
|
| 507 |
+
max_num_seqs: 1024
|
| 508 |
+
load_format: auto
|
| 509 |
+
engine_kwargs: {}
|
| 510 |
+
limit_images: null
|
| 511 |
+
enable_chunked_prefill: true
|
| 512 |
+
enable_prefix_caching: true
|
| 513 |
+
disable_log_stats: true
|
| 514 |
+
skip_tokenizer_init: true
|
| 515 |
+
prompt_length: 512
|
| 516 |
+
response_length: 512
|
| 517 |
+
algorithm:
|
| 518 |
+
rollout_correction:
|
| 519 |
+
rollout_is: null
|
| 520 |
+
rollout_is_threshold: 2.0
|
| 521 |
+
rollout_rs: null
|
| 522 |
+
rollout_rs_threshold: null
|
| 523 |
+
rollout_rs_threshold_lower: null
|
| 524 |
+
rollout_token_veto_threshold: null
|
| 525 |
+
bypass_mode: false
|
| 526 |
+
use_policy_gradient: false
|
| 527 |
+
rollout_is_batch_normalize: false
|
| 528 |
+
_target_: verl.trainer.config.AlgoConfig
|
| 529 |
+
gamma: 1.0
|
| 530 |
+
lam: 1.0
|
| 531 |
+
adv_estimator: grpo
|
| 532 |
+
norm_adv_by_std_in_grpo: true
|
| 533 |
+
use_kl_in_reward: false
|
| 534 |
+
kl_penalty: kl
|
| 535 |
+
kl_ctrl:
|
| 536 |
+
_target_: verl.trainer.config.KLControlConfig
|
| 537 |
+
type: fixed
|
| 538 |
+
kl_coef: 0.001
|
| 539 |
+
horizon: 10000
|
| 540 |
+
target_kl: 0.1
|
| 541 |
+
use_pf_ppo: false
|
| 542 |
+
pf_ppo:
|
| 543 |
+
reweight_method: pow
|
| 544 |
+
weight_pow: 2.0
|
| 545 |
+
custom_reward_function:
|
| 546 |
+
path: null
|
| 547 |
+
name: compute_score
|
| 548 |
+
trainer:
|
| 549 |
+
balance_batch: true
|
| 550 |
+
total_epochs: 15
|
| 551 |
+
total_training_steps: null
|
| 552 |
+
project_name: verl_grpo_gsm8k
|
| 553 |
+
experiment_name: qwen3_4b_gsm8k_grpo
|
| 554 |
+
logger:
|
| 555 |
+
- console
|
| 556 |
+
- wandb
|
| 557 |
+
log_val_generations: 0
|
| 558 |
+
rollout_data_dir: null
|
| 559 |
+
validation_data_dir: null
|
| 560 |
+
nnodes: 1
|
| 561 |
+
n_gpus_per_node: 8
|
| 562 |
+
save_freq: 20
|
| 563 |
+
esi_redundant_time: 0
|
| 564 |
+
resume_mode: disable
|
| 565 |
+
resume_from_path: null
|
| 566 |
+
val_before_train: true
|
| 567 |
+
val_only: false
|
| 568 |
+
test_freq: 5
|
| 569 |
+
critic_warmup: 0
|
| 570 |
+
default_hdfs_dir: null
|
| 571 |
+
del_local_ckpt_after_load: false
|
| 572 |
+
default_local_dir: checkpoints/${trainer.project_name}/${trainer.experiment_name}
|
| 573 |
+
max_actor_ckpt_to_keep: null
|
| 574 |
+
max_critic_ckpt_to_keep: null
|
| 575 |
+
ray_wait_register_center_timeout: 300
|
| 576 |
+
device: cuda
|
| 577 |
+
use_legacy_worker_impl: auto
|
| 578 |
+
global_profiler:
|
| 579 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 580 |
+
tool: null
|
| 581 |
+
steps: null
|
| 582 |
+
profile_continuous_steps: false
|
| 583 |
+
save_path: outputs/profile
|
| 584 |
+
global_tool_config:
|
| 585 |
+
nsys:
|
| 586 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 587 |
+
discrete: false
|
| 588 |
+
controller_nsight_options:
|
| 589 |
+
trace: cuda,nvtx,cublas,ucx
|
| 590 |
+
cuda-memory-usage: 'true'
|
| 591 |
+
cuda-graph-trace: graph
|
| 592 |
+
worker_nsight_options:
|
| 593 |
+
trace: cuda,nvtx,cublas,ucx
|
| 594 |
+
cuda-memory-usage: 'true'
|
| 595 |
+
cuda-graph-trace: graph
|
| 596 |
+
capture-range: cudaProfilerApi
|
| 597 |
+
capture-range-end: null
|
| 598 |
+
kill: none
|
| 599 |
+
torch_memory:
|
| 600 |
+
trace_alloc_max_entries: 100000
|
| 601 |
+
stack_depth: 32
|
| 602 |
+
context: all
|
| 603 |
+
stacks: all
|
| 604 |
+
kw_args: {}
|
| 605 |
+
transfer_queue:
|
| 606 |
+
enable: false
|
| 607 |
+
ray_kwargs:
|
| 608 |
+
ray_init:
|
| 609 |
+
num_cpus: null
|
| 610 |
+
timeline_json_file: null
|
examples/grpo_trainer/outputs/2026-01-26/17-07-54/.hydra/overrides.yaml
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
- algorithm.adv_estimator=grpo
|
| 2 |
+
- data.train_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/train.parquet
|
| 3 |
+
- data.val_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/test.parquet
|
| 4 |
+
- data.train_batch_size=1024
|
| 5 |
+
- data.max_prompt_length=512
|
| 6 |
+
- data.max_response_length=128
|
| 7 |
+
- data.filter_overlong_prompts=True
|
| 8 |
+
- data.truncation=error
|
| 9 |
+
- data.shuffle=False
|
| 10 |
+
- actor_rollout_ref.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 11 |
+
- actor_rollout_ref.actor.optim.lr=1e-6
|
| 12 |
+
- actor_rollout_ref.model.use_remove_padding=True
|
| 13 |
+
- actor_rollout_ref.actor.ppo_mini_batch_size=256
|
| 14 |
+
- actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=32
|
| 15 |
+
- actor_rollout_ref.actor.use_kl_loss=True
|
| 16 |
+
- actor_rollout_ref.actor.kl_loss_coef=0.001
|
| 17 |
+
- actor_rollout_ref.actor.kl_loss_type=low_var_kl
|
| 18 |
+
- actor_rollout_ref.actor.entropy_coeff=0
|
| 19 |
+
- actor_rollout_ref.model.enable_gradient_checkpointing=True
|
| 20 |
+
- actor_rollout_ref.actor.fsdp_config.param_offload=True
|
| 21 |
+
- actor_rollout_ref.actor.fsdp_config.optimizer_offload=False
|
| 22 |
+
- actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32
|
| 23 |
+
- actor_rollout_ref.rollout.tensor_model_parallel_size=2
|
| 24 |
+
- actor_rollout_ref.rollout.name=vllm
|
| 25 |
+
- actor_rollout_ref.rollout.gpu_memory_utilization=0.6
|
| 26 |
+
- actor_rollout_ref.rollout.n=5
|
| 27 |
+
- actor_rollout_ref.rollout.load_format=safetensors
|
| 28 |
+
- actor_rollout_ref.rollout.layered_summon=True
|
| 29 |
+
- actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32
|
| 30 |
+
- actor_rollout_ref.ref.fsdp_config.param_offload=False
|
| 31 |
+
- algorithm.use_kl_in_reward=False
|
| 32 |
+
- reward_model.enable=True
|
| 33 |
+
- reward_model.enable=True
|
| 34 |
+
- reward_model.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/reward_model_converted
|
| 35 |
+
- reward_model.micro_batch_size_per_gpu=32
|
| 36 |
+
- trainer.critic_warmup=0
|
| 37 |
+
- trainer.logger=["console","wandb"]
|
| 38 |
+
- trainer.project_name=verl_grpo_gsm8k
|
| 39 |
+
- trainer.experiment_name=qwen3_4b_gsm8k_grpo
|
| 40 |
+
- trainer.n_gpus_per_node=8
|
| 41 |
+
- trainer.nnodes=1
|
| 42 |
+
- trainer.save_freq=20
|
| 43 |
+
- trainer.test_freq=5
|
| 44 |
+
- trainer.total_epochs=15
|
| 45 |
+
- trainer.resume_mode=disable
|
examples/grpo_trainer/outputs/2026-01-26/17-28-29/.hydra/config.yaml
ADDED
|
@@ -0,0 +1,610 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
actor_rollout_ref:
|
| 2 |
+
actor:
|
| 3 |
+
optim:
|
| 4 |
+
_target_: verl.workers.config.FSDPOptimizerConfig
|
| 5 |
+
optimizer: AdamW
|
| 6 |
+
optimizer_impl: torch.optim
|
| 7 |
+
lr: 1.0e-06
|
| 8 |
+
lr_warmup_steps_ratio: 0.0
|
| 9 |
+
total_training_steps: -1
|
| 10 |
+
weight_decay: 0.01
|
| 11 |
+
lr_warmup_steps: -1
|
| 12 |
+
betas:
|
| 13 |
+
- 0.9
|
| 14 |
+
- 0.999
|
| 15 |
+
clip_grad: 1.0
|
| 16 |
+
min_lr_ratio: 0.0
|
| 17 |
+
num_cycles: 0.5
|
| 18 |
+
lr_scheduler_type: constant
|
| 19 |
+
warmup_style: null
|
| 20 |
+
override_optimizer_config: null
|
| 21 |
+
fsdp_config:
|
| 22 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 23 |
+
wrap_policy:
|
| 24 |
+
min_num_params: 0
|
| 25 |
+
param_offload: true
|
| 26 |
+
optimizer_offload: false
|
| 27 |
+
offload_policy: false
|
| 28 |
+
reshard_after_forward: true
|
| 29 |
+
fsdp_size: -1
|
| 30 |
+
forward_prefetch: false
|
| 31 |
+
model_dtype: fp32
|
| 32 |
+
use_orig_params: false
|
| 33 |
+
seed: 42
|
| 34 |
+
full_determinism: false
|
| 35 |
+
ulysses_sequence_parallel_size: 1
|
| 36 |
+
entropy_from_logits_with_chunking: false
|
| 37 |
+
use_torch_compile: true
|
| 38 |
+
entropy_checkpointing: false
|
| 39 |
+
forward_only: false
|
| 40 |
+
strategy: fsdp
|
| 41 |
+
dtype: bfloat16
|
| 42 |
+
_target_: verl.workers.config.FSDPActorConfig
|
| 43 |
+
rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
|
| 44 |
+
strategy: fsdp
|
| 45 |
+
ppo_mini_batch_size: 256
|
| 46 |
+
ppo_micro_batch_size: null
|
| 47 |
+
ppo_micro_batch_size_per_gpu: 32
|
| 48 |
+
use_dynamic_bsz: false
|
| 49 |
+
ppo_max_token_len_per_gpu: 16384
|
| 50 |
+
clip_ratio: 0.2
|
| 51 |
+
clip_ratio_low: 0.2
|
| 52 |
+
clip_ratio_high: 0.2
|
| 53 |
+
freeze_vision_tower: false
|
| 54 |
+
policy_loss:
|
| 55 |
+
_target_: verl.workers.config.PolicyLossConfig
|
| 56 |
+
loss_mode: vanilla
|
| 57 |
+
clip_cov_ratio: 0.0002
|
| 58 |
+
clip_cov_lb: 1.0
|
| 59 |
+
clip_cov_ub: 5.0
|
| 60 |
+
kl_cov_ratio: 0.0002
|
| 61 |
+
ppo_kl_coef: 0.1
|
| 62 |
+
clip_ratio_c: 3.0
|
| 63 |
+
loss_agg_mode: token-mean
|
| 64 |
+
loss_scale_factor: null
|
| 65 |
+
entropy_coeff: 0
|
| 66 |
+
calculate_entropy: false
|
| 67 |
+
use_kl_loss: true
|
| 68 |
+
use_torch_compile: true
|
| 69 |
+
kl_loss_coef: 0.001
|
| 70 |
+
kl_loss_type: low_var_kl
|
| 71 |
+
ppo_epochs: 1
|
| 72 |
+
shuffle: false
|
| 73 |
+
checkpoint:
|
| 74 |
+
_target_: verl.trainer.config.CheckpointConfig
|
| 75 |
+
save_contents:
|
| 76 |
+
- model
|
| 77 |
+
- optimizer
|
| 78 |
+
- extra
|
| 79 |
+
load_contents: ${.save_contents}
|
| 80 |
+
async_save: false
|
| 81 |
+
use_fused_kernels: ${oc.select:actor_rollout_ref.model.use_fused_kernels,false}
|
| 82 |
+
profiler:
|
| 83 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 84 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 85 |
+
enable: false
|
| 86 |
+
all_ranks: false
|
| 87 |
+
ranks: []
|
| 88 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 89 |
+
tool_config:
|
| 90 |
+
nsys:
|
| 91 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 92 |
+
discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
|
| 93 |
+
npu:
|
| 94 |
+
_target_: verl.utils.profiler.config.NPUToolConfig
|
| 95 |
+
contents: []
|
| 96 |
+
level: level1
|
| 97 |
+
analysis: true
|
| 98 |
+
discrete: false
|
| 99 |
+
torch:
|
| 100 |
+
_target_: verl.utils.profiler.config.TorchProfilerToolConfig
|
| 101 |
+
step_start: 0
|
| 102 |
+
step_end: null
|
| 103 |
+
torch_memory:
|
| 104 |
+
_target_: verl.utils.profiler.config.TorchMemoryToolConfig
|
| 105 |
+
trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
|
| 106 |
+
stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
|
| 107 |
+
router_replay:
|
| 108 |
+
_target_: verl.workers.config.RouterReplayConfig
|
| 109 |
+
mode: disabled
|
| 110 |
+
record_file: null
|
| 111 |
+
replay_file: null
|
| 112 |
+
grad_clip: 1.0
|
| 113 |
+
ulysses_sequence_parallel_size: 1
|
| 114 |
+
entropy_from_logits_with_chunking: false
|
| 115 |
+
entropy_checkpointing: false
|
| 116 |
+
use_remove_padding: ${oc.select:actor_rollout_ref.model.use_remove_padding,false}
|
| 117 |
+
ref:
|
| 118 |
+
rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
|
| 119 |
+
strategy: ${actor_rollout_ref.actor.strategy}
|
| 120 |
+
use_torch_compile: ${oc.select:actor_rollout_ref.actor.use_torch_compile,true}
|
| 121 |
+
log_prob_micro_batch_size: null
|
| 122 |
+
log_prob_micro_batch_size_per_gpu: 32
|
| 123 |
+
log_prob_use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
|
| 124 |
+
log_prob_max_token_len_per_gpu: ${oc.select:actor_rollout_ref.actor.ppo_max_token_len_per_gpu,16384}
|
| 125 |
+
profiler:
|
| 126 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 127 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 128 |
+
enable: false
|
| 129 |
+
all_ranks: false
|
| 130 |
+
ranks: []
|
| 131 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 132 |
+
tool_config:
|
| 133 |
+
nsys:
|
| 134 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 135 |
+
discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
|
| 136 |
+
npu:
|
| 137 |
+
_target_: verl.utils.profiler.config.NPUToolConfig
|
| 138 |
+
contents: []
|
| 139 |
+
level: level1
|
| 140 |
+
analysis: true
|
| 141 |
+
discrete: false
|
| 142 |
+
torch:
|
| 143 |
+
_target_: verl.utils.profiler.config.TorchProfilerToolConfig
|
| 144 |
+
step_start: 0
|
| 145 |
+
step_end: null
|
| 146 |
+
torch_memory:
|
| 147 |
+
_target_: verl.utils.profiler.config.TorchMemoryToolConfig
|
| 148 |
+
trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
|
| 149 |
+
stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
|
| 150 |
+
router_replay:
|
| 151 |
+
_target_: verl.workers.config.RouterReplayConfig
|
| 152 |
+
mode: disabled
|
| 153 |
+
record_file: null
|
| 154 |
+
replay_file: null
|
| 155 |
+
fsdp_config:
|
| 156 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 157 |
+
wrap_policy:
|
| 158 |
+
min_num_params: 0
|
| 159 |
+
param_offload: false
|
| 160 |
+
optimizer_offload: false
|
| 161 |
+
offload_policy: false
|
| 162 |
+
reshard_after_forward: true
|
| 163 |
+
fsdp_size: -1
|
| 164 |
+
forward_prefetch: false
|
| 165 |
+
model_dtype: fp32
|
| 166 |
+
use_orig_params: false
|
| 167 |
+
seed: 42
|
| 168 |
+
full_determinism: false
|
| 169 |
+
ulysses_sequence_parallel_size: 1
|
| 170 |
+
entropy_from_logits_with_chunking: false
|
| 171 |
+
use_torch_compile: true
|
| 172 |
+
entropy_checkpointing: false
|
| 173 |
+
forward_only: true
|
| 174 |
+
strategy: fsdp
|
| 175 |
+
dtype: bfloat16
|
| 176 |
+
_target_: verl.workers.config.FSDPActorConfig
|
| 177 |
+
ulysses_sequence_parallel_size: ${oc.select:actor_rollout_ref.actor.ulysses_sequence_parallel_size,1}
|
| 178 |
+
entropy_from_logits_with_chunking: false
|
| 179 |
+
entropy_checkpointing: false
|
| 180 |
+
rollout:
|
| 181 |
+
_target_: verl.workers.config.RolloutConfig
|
| 182 |
+
name: vllm
|
| 183 |
+
mode: async
|
| 184 |
+
temperature: 1.0
|
| 185 |
+
top_k: -1
|
| 186 |
+
top_p: 1
|
| 187 |
+
prompt_length: ${oc.select:data.max_prompt_length,512}
|
| 188 |
+
response_length: ${oc.select:data.max_response_length,512}
|
| 189 |
+
dtype: bfloat16
|
| 190 |
+
gpu_memory_utilization: 0.6
|
| 191 |
+
ignore_eos: false
|
| 192 |
+
enforce_eager: false
|
| 193 |
+
cudagraph_capture_sizes: null
|
| 194 |
+
free_cache_engine: true
|
| 195 |
+
tensor_model_parallel_size: 2
|
| 196 |
+
data_parallel_size: 1
|
| 197 |
+
expert_parallel_size: 1
|
| 198 |
+
pipeline_model_parallel_size: 1
|
| 199 |
+
max_num_batched_tokens: 8192
|
| 200 |
+
max_model_len: null
|
| 201 |
+
max_num_seqs: 1024
|
| 202 |
+
enable_chunked_prefill: true
|
| 203 |
+
enable_prefix_caching: true
|
| 204 |
+
load_format: safetensors
|
| 205 |
+
log_prob_micro_batch_size: null
|
| 206 |
+
log_prob_micro_batch_size_per_gpu: 32
|
| 207 |
+
log_prob_use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
|
| 208 |
+
log_prob_max_token_len_per_gpu: ${oc.select:actor_rollout_ref.actor.ppo_max_token_len_per_gpu,16384}
|
| 209 |
+
disable_log_stats: true
|
| 210 |
+
do_sample: true
|
| 211 |
+
'n': 5
|
| 212 |
+
over_sample_rate: 0
|
| 213 |
+
multi_stage_wake_up: false
|
| 214 |
+
engine_kwargs:
|
| 215 |
+
vllm: {}
|
| 216 |
+
sglang: {}
|
| 217 |
+
val_kwargs:
|
| 218 |
+
_target_: verl.workers.config.SamplingConfig
|
| 219 |
+
top_k: -1
|
| 220 |
+
top_p: 1.0
|
| 221 |
+
temperature: 0
|
| 222 |
+
'n': 1
|
| 223 |
+
do_sample: false
|
| 224 |
+
multi_turn:
|
| 225 |
+
_target_: verl.workers.config.MultiTurnConfig
|
| 226 |
+
enable: false
|
| 227 |
+
max_assistant_turns: null
|
| 228 |
+
tool_config_path: null
|
| 229 |
+
max_user_turns: null
|
| 230 |
+
max_parallel_calls: 1
|
| 231 |
+
max_tool_response_length: 256
|
| 232 |
+
tool_response_truncate_side: middle
|
| 233 |
+
interaction_config_path: null
|
| 234 |
+
use_inference_chat_template: false
|
| 235 |
+
tokenization_sanity_check_mode: strict
|
| 236 |
+
format: hermes
|
| 237 |
+
num_repeat_rollouts: null
|
| 238 |
+
calculate_log_probs: false
|
| 239 |
+
agent:
|
| 240 |
+
_target_: verl.workers.config.AgentLoopConfig
|
| 241 |
+
num_workers: 8
|
| 242 |
+
default_agent_loop: single_turn_agent
|
| 243 |
+
agent_loop_config_path: null
|
| 244 |
+
custom_async_server:
|
| 245 |
+
_target_: verl.workers.config.CustomAsyncServerConfig
|
| 246 |
+
path: null
|
| 247 |
+
name: null
|
| 248 |
+
update_weights_bucket_megabytes: 512
|
| 249 |
+
trace:
|
| 250 |
+
_target_: verl.workers.config.TraceConfig
|
| 251 |
+
backend: null
|
| 252 |
+
token2text: false
|
| 253 |
+
max_samples_per_step_per_worker: null
|
| 254 |
+
skip_rollout: false
|
| 255 |
+
skip_dump_dir: /tmp/rollout_dump
|
| 256 |
+
skip_tokenizer_init: true
|
| 257 |
+
enable_rollout_routing_replay: false
|
| 258 |
+
profiler:
|
| 259 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 260 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 261 |
+
enable: ${oc.select:actor_rollout_ref.actor.profiler.enable,false}
|
| 262 |
+
all_ranks: ${oc.select:actor_rollout_ref.actor.profiler.all_ranks,false}
|
| 263 |
+
ranks: ${oc.select:actor_rollout_ref.actor.profiler.ranks,[]}
|
| 264 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 265 |
+
tool_config: ${oc.select:actor_rollout_ref.actor.profiler.tool_config,null}
|
| 266 |
+
prometheus:
|
| 267 |
+
_target_: verl.workers.config.PrometheusConfig
|
| 268 |
+
enable: false
|
| 269 |
+
port: 9090
|
| 270 |
+
file: /tmp/ray/session_latest/metrics/prometheus/prometheus.yml
|
| 271 |
+
served_model_name: ${oc.select:actor_rollout_ref.model.path,null}
|
| 272 |
+
layered_summon: true
|
| 273 |
+
model:
|
| 274 |
+
_target_: verl.workers.config.HFModelConfig
|
| 275 |
+
path: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 276 |
+
hf_config_path: null
|
| 277 |
+
tokenizer_path: null
|
| 278 |
+
use_shm: false
|
| 279 |
+
trust_remote_code: false
|
| 280 |
+
custom_chat_template: null
|
| 281 |
+
external_lib: null
|
| 282 |
+
override_config: {}
|
| 283 |
+
enable_gradient_checkpointing: true
|
| 284 |
+
enable_activation_offload: false
|
| 285 |
+
use_remove_padding: true
|
| 286 |
+
lora_rank: 0
|
| 287 |
+
lora_alpha: 16
|
| 288 |
+
target_modules: all-linear
|
| 289 |
+
exclude_modules: null
|
| 290 |
+
lora_adapter_path: null
|
| 291 |
+
use_liger: false
|
| 292 |
+
use_fused_kernels: false
|
| 293 |
+
fused_kernel_options:
|
| 294 |
+
impl_backend: torch
|
| 295 |
+
hybrid_engine: true
|
| 296 |
+
nccl_timeout: 600
|
| 297 |
+
data:
|
| 298 |
+
tokenizer: null
|
| 299 |
+
use_shm: false
|
| 300 |
+
train_files: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/train.parquet
|
| 301 |
+
val_files: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/test.parquet
|
| 302 |
+
train_max_samples: -1
|
| 303 |
+
val_max_samples: -1
|
| 304 |
+
prompt_key: prompt
|
| 305 |
+
reward_fn_key: data_source
|
| 306 |
+
max_prompt_length: 512
|
| 307 |
+
max_response_length: 128
|
| 308 |
+
train_batch_size: 1024
|
| 309 |
+
val_batch_size: null
|
| 310 |
+
tool_config_path: ${oc.select:actor_rollout_ref.rollout.multi_turn.tool_config_path,
|
| 311 |
+
null}
|
| 312 |
+
return_raw_input_ids: false
|
| 313 |
+
return_raw_chat: true
|
| 314 |
+
return_full_prompt: false
|
| 315 |
+
shuffle: false
|
| 316 |
+
seed: null
|
| 317 |
+
dataloader_num_workers: 8
|
| 318 |
+
image_patch_size: 14
|
| 319 |
+
validation_shuffle: false
|
| 320 |
+
filter_overlong_prompts: true
|
| 321 |
+
filter_overlong_prompts_workers: 1
|
| 322 |
+
truncation: error
|
| 323 |
+
image_key: images
|
| 324 |
+
video_key: videos
|
| 325 |
+
trust_remote_code: false
|
| 326 |
+
custom_cls:
|
| 327 |
+
path: null
|
| 328 |
+
name: null
|
| 329 |
+
return_multi_modal_inputs: true
|
| 330 |
+
sampler:
|
| 331 |
+
class_path: null
|
| 332 |
+
class_name: null
|
| 333 |
+
datagen:
|
| 334 |
+
path: null
|
| 335 |
+
name: null
|
| 336 |
+
apply_chat_template_kwargs: {}
|
| 337 |
+
reward_manager:
|
| 338 |
+
_target_: verl.trainer.config.config.RewardManagerConfig
|
| 339 |
+
source: register
|
| 340 |
+
name: ${oc.select:reward_model.reward_manager,naive}
|
| 341 |
+
module:
|
| 342 |
+
_target_: verl.trainer.config.config.ModuleConfig
|
| 343 |
+
path: null
|
| 344 |
+
name: custom_reward_manager
|
| 345 |
+
critic:
|
| 346 |
+
optim:
|
| 347 |
+
_target_: verl.workers.config.FSDPOptimizerConfig
|
| 348 |
+
optimizer: AdamW
|
| 349 |
+
optimizer_impl: torch.optim
|
| 350 |
+
lr: 1.0e-05
|
| 351 |
+
lr_warmup_steps_ratio: 0.0
|
| 352 |
+
total_training_steps: -1
|
| 353 |
+
weight_decay: 0.01
|
| 354 |
+
lr_warmup_steps: -1
|
| 355 |
+
betas:
|
| 356 |
+
- 0.9
|
| 357 |
+
- 0.999
|
| 358 |
+
clip_grad: 1.0
|
| 359 |
+
min_lr_ratio: 0.0
|
| 360 |
+
num_cycles: 0.5
|
| 361 |
+
lr_scheduler_type: constant
|
| 362 |
+
warmup_style: null
|
| 363 |
+
override_optimizer_config: null
|
| 364 |
+
model:
|
| 365 |
+
fsdp_config:
|
| 366 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 367 |
+
wrap_policy:
|
| 368 |
+
min_num_params: 0
|
| 369 |
+
param_offload: false
|
| 370 |
+
optimizer_offload: false
|
| 371 |
+
offload_policy: false
|
| 372 |
+
reshard_after_forward: true
|
| 373 |
+
fsdp_size: -1
|
| 374 |
+
forward_prefetch: false
|
| 375 |
+
model_dtype: fp32
|
| 376 |
+
use_orig_params: false
|
| 377 |
+
seed: 42
|
| 378 |
+
full_determinism: false
|
| 379 |
+
ulysses_sequence_parallel_size: 1
|
| 380 |
+
entropy_from_logits_with_chunking: false
|
| 381 |
+
use_torch_compile: true
|
| 382 |
+
entropy_checkpointing: false
|
| 383 |
+
forward_only: false
|
| 384 |
+
strategy: fsdp
|
| 385 |
+
dtype: bfloat16
|
| 386 |
+
path: ~/models/deepseek-llm-7b-chat
|
| 387 |
+
tokenizer_path: ${oc.select:actor_rollout_ref.model.path,"~/models/deepseek-llm-7b-chat"}
|
| 388 |
+
override_config: {}
|
| 389 |
+
external_lib: ${oc.select:actor_rollout_ref.model.external_lib,null}
|
| 390 |
+
trust_remote_code: ${oc.select:actor_rollout_ref.model.trust_remote_code,false}
|
| 391 |
+
_target_: verl.workers.config.FSDPCriticModelCfg
|
| 392 |
+
use_shm: false
|
| 393 |
+
enable_gradient_checkpointing: true
|
| 394 |
+
enable_activation_offload: false
|
| 395 |
+
use_remove_padding: false
|
| 396 |
+
lora_rank: 0
|
| 397 |
+
lora_alpha: 16
|
| 398 |
+
target_modules: all-linear
|
| 399 |
+
_target_: verl.workers.config.FSDPCriticConfig
|
| 400 |
+
rollout_n: ${oc.select:actor_rollout_ref.rollout.n,1}
|
| 401 |
+
strategy: fsdp
|
| 402 |
+
enable: null
|
| 403 |
+
ppo_mini_batch_size: ${oc.select:actor_rollout_ref.actor.ppo_mini_batch_size,256}
|
| 404 |
+
ppo_micro_batch_size: null
|
| 405 |
+
ppo_micro_batch_size_per_gpu: ${oc.select:.ppo_micro_batch_size,null}
|
| 406 |
+
use_dynamic_bsz: ${oc.select:actor_rollout_ref.actor.use_dynamic_bsz,false}
|
| 407 |
+
ppo_max_token_len_per_gpu: 32768
|
| 408 |
+
forward_max_token_len_per_gpu: ${.ppo_max_token_len_per_gpu}
|
| 409 |
+
ppo_epochs: ${oc.select:actor_rollout_ref.actor.ppo_epochs,1}
|
| 410 |
+
shuffle: ${oc.select:actor_rollout_ref.actor.shuffle,false}
|
| 411 |
+
cliprange_value: 0.5
|
| 412 |
+
loss_agg_mode: ${oc.select:actor_rollout_ref.actor.loss_agg_mode,token-mean}
|
| 413 |
+
checkpoint:
|
| 414 |
+
_target_: verl.trainer.config.CheckpointConfig
|
| 415 |
+
save_contents:
|
| 416 |
+
- model
|
| 417 |
+
- optimizer
|
| 418 |
+
- extra
|
| 419 |
+
load_contents: ${.save_contents}
|
| 420 |
+
async_save: false
|
| 421 |
+
profiler:
|
| 422 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 423 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 424 |
+
enable: false
|
| 425 |
+
all_ranks: false
|
| 426 |
+
ranks: []
|
| 427 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 428 |
+
tool_config:
|
| 429 |
+
nsys:
|
| 430 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 431 |
+
discrete: ${oc.select:global_profiler.global_tool_config.nsys.discrete}
|
| 432 |
+
npu:
|
| 433 |
+
_target_: verl.utils.profiler.config.NPUToolConfig
|
| 434 |
+
contents: []
|
| 435 |
+
level: level1
|
| 436 |
+
analysis: true
|
| 437 |
+
discrete: false
|
| 438 |
+
torch:
|
| 439 |
+
_target_: verl.utils.profiler.config.TorchProfilerToolConfig
|
| 440 |
+
step_start: 0
|
| 441 |
+
step_end: null
|
| 442 |
+
torch_memory:
|
| 443 |
+
_target_: verl.utils.profiler.config.TorchMemoryToolConfig
|
| 444 |
+
trace_alloc_max_entries: ${oc.select:global_profiler.global_tool_config.torch_memory.trace_alloc_max_entries,100000}
|
| 445 |
+
stack_depth: ${oc.select:global_profiler.global_tool_config.torch_memory.stack_depth,32}
|
| 446 |
+
forward_micro_batch_size: ${oc.select:.ppo_micro_batch_size,null}
|
| 447 |
+
forward_micro_batch_size_per_gpu: ${oc.select:.ppo_micro_batch_size_per_gpu,null}
|
| 448 |
+
ulysses_sequence_parallel_size: 1
|
| 449 |
+
grad_clip: 1.0
|
| 450 |
+
reward_model:
|
| 451 |
+
enable: true
|
| 452 |
+
enable_resource_pool: false
|
| 453 |
+
n_gpus_per_node: 0
|
| 454 |
+
nnodes: 0
|
| 455 |
+
strategy: fsdp
|
| 456 |
+
model:
|
| 457 |
+
input_tokenizer: ${actor_rollout_ref.model.path}
|
| 458 |
+
path: /mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/reward_model_converted
|
| 459 |
+
external_lib: ${actor_rollout_ref.model.external_lib}
|
| 460 |
+
trust_remote_code: false
|
| 461 |
+
override_config: {}
|
| 462 |
+
use_shm: false
|
| 463 |
+
use_remove_padding: false
|
| 464 |
+
use_fused_kernels: ${actor_rollout_ref.model.use_fused_kernels}
|
| 465 |
+
fsdp_config:
|
| 466 |
+
_target_: verl.workers.config.FSDPEngineConfig
|
| 467 |
+
wrap_policy:
|
| 468 |
+
min_num_params: 0
|
| 469 |
+
param_offload: false
|
| 470 |
+
reshard_after_forward: true
|
| 471 |
+
fsdp_size: -1
|
| 472 |
+
forward_prefetch: false
|
| 473 |
+
micro_batch_size: null
|
| 474 |
+
micro_batch_size_per_gpu: 32
|
| 475 |
+
max_length: null
|
| 476 |
+
use_dynamic_bsz: ${critic.use_dynamic_bsz}
|
| 477 |
+
forward_max_token_len_per_gpu: ${critic.forward_max_token_len_per_gpu}
|
| 478 |
+
reward_manager: naive
|
| 479 |
+
launch_reward_fn_async: false
|
| 480 |
+
sandbox_fusion:
|
| 481 |
+
url: null
|
| 482 |
+
max_concurrent: 64
|
| 483 |
+
memory_limit_mb: 1024
|
| 484 |
+
profiler:
|
| 485 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 486 |
+
tool: ${oc.select:global_profiler.tool,null}
|
| 487 |
+
enable: false
|
| 488 |
+
all_ranks: false
|
| 489 |
+
ranks: []
|
| 490 |
+
save_path: ${oc.select:global_profiler.save_path,null}
|
| 491 |
+
tool_config: ${oc.select:actor_rollout_ref.actor.profiler.tool_config,null}
|
| 492 |
+
ulysses_sequence_parallel_size: 1
|
| 493 |
+
use_reward_loop: true
|
| 494 |
+
rollout:
|
| 495 |
+
_target_: verl.workers.config.RolloutConfig
|
| 496 |
+
name: ???
|
| 497 |
+
dtype: bfloat16
|
| 498 |
+
gpu_memory_utilization: 0.5
|
| 499 |
+
enforce_eager: true
|
| 500 |
+
cudagraph_capture_sizes: null
|
| 501 |
+
free_cache_engine: true
|
| 502 |
+
data_parallel_size: 1
|
| 503 |
+
expert_parallel_size: 1
|
| 504 |
+
tensor_model_parallel_size: 2
|
| 505 |
+
max_num_batched_tokens: 8192
|
| 506 |
+
max_model_len: null
|
| 507 |
+
max_num_seqs: 1024
|
| 508 |
+
load_format: auto
|
| 509 |
+
engine_kwargs: {}
|
| 510 |
+
limit_images: null
|
| 511 |
+
enable_chunked_prefill: true
|
| 512 |
+
enable_prefix_caching: true
|
| 513 |
+
disable_log_stats: true
|
| 514 |
+
skip_tokenizer_init: true
|
| 515 |
+
prompt_length: 512
|
| 516 |
+
response_length: 512
|
| 517 |
+
algorithm:
|
| 518 |
+
rollout_correction:
|
| 519 |
+
rollout_is: null
|
| 520 |
+
rollout_is_threshold: 2.0
|
| 521 |
+
rollout_rs: null
|
| 522 |
+
rollout_rs_threshold: null
|
| 523 |
+
rollout_rs_threshold_lower: null
|
| 524 |
+
rollout_token_veto_threshold: null
|
| 525 |
+
bypass_mode: false
|
| 526 |
+
use_policy_gradient: false
|
| 527 |
+
rollout_is_batch_normalize: false
|
| 528 |
+
_target_: verl.trainer.config.AlgoConfig
|
| 529 |
+
gamma: 1.0
|
| 530 |
+
lam: 1.0
|
| 531 |
+
adv_estimator: grpo
|
| 532 |
+
norm_adv_by_std_in_grpo: true
|
| 533 |
+
use_kl_in_reward: false
|
| 534 |
+
kl_penalty: kl
|
| 535 |
+
kl_ctrl:
|
| 536 |
+
_target_: verl.trainer.config.KLControlConfig
|
| 537 |
+
type: fixed
|
| 538 |
+
kl_coef: 0.001
|
| 539 |
+
horizon: 10000
|
| 540 |
+
target_kl: 0.1
|
| 541 |
+
use_pf_ppo: false
|
| 542 |
+
pf_ppo:
|
| 543 |
+
reweight_method: pow
|
| 544 |
+
weight_pow: 2.0
|
| 545 |
+
custom_reward_function:
|
| 546 |
+
path: null
|
| 547 |
+
name: compute_score
|
| 548 |
+
trainer:
|
| 549 |
+
balance_batch: true
|
| 550 |
+
total_epochs: 15
|
| 551 |
+
total_training_steps: null
|
| 552 |
+
project_name: verl_grpo_gsm8k
|
| 553 |
+
experiment_name: qwen3_4b_gsm8k_grpo
|
| 554 |
+
logger:
|
| 555 |
+
- console
|
| 556 |
+
- wandb
|
| 557 |
+
log_val_generations: 0
|
| 558 |
+
rollout_data_dir: null
|
| 559 |
+
validation_data_dir: null
|
| 560 |
+
nnodes: 1
|
| 561 |
+
n_gpus_per_node: 8
|
| 562 |
+
save_freq: 20
|
| 563 |
+
esi_redundant_time: 0
|
| 564 |
+
resume_mode: disable
|
| 565 |
+
resume_from_path: null
|
| 566 |
+
val_before_train: true
|
| 567 |
+
val_only: false
|
| 568 |
+
test_freq: 5
|
| 569 |
+
critic_warmup: 0
|
| 570 |
+
default_hdfs_dir: null
|
| 571 |
+
del_local_ckpt_after_load: false
|
| 572 |
+
default_local_dir: checkpoints/${trainer.project_name}/${trainer.experiment_name}
|
| 573 |
+
max_actor_ckpt_to_keep: null
|
| 574 |
+
max_critic_ckpt_to_keep: null
|
| 575 |
+
ray_wait_register_center_timeout: 300
|
| 576 |
+
device: cuda
|
| 577 |
+
use_legacy_worker_impl: auto
|
| 578 |
+
global_profiler:
|
| 579 |
+
_target_: verl.utils.profiler.ProfilerConfig
|
| 580 |
+
tool: null
|
| 581 |
+
steps: null
|
| 582 |
+
profile_continuous_steps: false
|
| 583 |
+
save_path: outputs/profile
|
| 584 |
+
global_tool_config:
|
| 585 |
+
nsys:
|
| 586 |
+
_target_: verl.utils.profiler.config.NsightToolConfig
|
| 587 |
+
discrete: false
|
| 588 |
+
controller_nsight_options:
|
| 589 |
+
trace: cuda,nvtx,cublas,ucx
|
| 590 |
+
cuda-memory-usage: 'true'
|
| 591 |
+
cuda-graph-trace: graph
|
| 592 |
+
worker_nsight_options:
|
| 593 |
+
trace: cuda,nvtx,cublas,ucx
|
| 594 |
+
cuda-memory-usage: 'true'
|
| 595 |
+
cuda-graph-trace: graph
|
| 596 |
+
capture-range: cudaProfilerApi
|
| 597 |
+
capture-range-end: null
|
| 598 |
+
kill: none
|
| 599 |
+
torch_memory:
|
| 600 |
+
trace_alloc_max_entries: 100000
|
| 601 |
+
stack_depth: 32
|
| 602 |
+
context: all
|
| 603 |
+
stacks: all
|
| 604 |
+
kw_args: {}
|
| 605 |
+
transfer_queue:
|
| 606 |
+
enable: false
|
| 607 |
+
ray_kwargs:
|
| 608 |
+
ray_init:
|
| 609 |
+
num_cpus: null
|
| 610 |
+
timeline_json_file: null
|
examples/grpo_trainer/outputs/2026-01-26/17-28-29/.hydra/overrides.yaml
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
- algorithm.adv_estimator=grpo
|
| 2 |
+
- data.train_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/train.parquet
|
| 3 |
+
- data.val_files=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/data/gsm8k/test.parquet
|
| 4 |
+
- data.train_batch_size=1024
|
| 5 |
+
- data.max_prompt_length=512
|
| 6 |
+
- data.max_response_length=128
|
| 7 |
+
- data.filter_overlong_prompts=True
|
| 8 |
+
- data.truncation=error
|
| 9 |
+
- data.shuffle=False
|
| 10 |
+
- actor_rollout_ref.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/models/Qwen3-4B-Instruct-2507
|
| 11 |
+
- actor_rollout_ref.actor.optim.lr=1e-6
|
| 12 |
+
- actor_rollout_ref.model.use_remove_padding=True
|
| 13 |
+
- actor_rollout_ref.actor.ppo_mini_batch_size=256
|
| 14 |
+
- actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=32
|
| 15 |
+
- actor_rollout_ref.actor.use_kl_loss=True
|
| 16 |
+
- actor_rollout_ref.actor.kl_loss_coef=0.001
|
| 17 |
+
- actor_rollout_ref.actor.kl_loss_type=low_var_kl
|
| 18 |
+
- actor_rollout_ref.actor.entropy_coeff=0
|
| 19 |
+
- actor_rollout_ref.model.enable_gradient_checkpointing=True
|
| 20 |
+
- actor_rollout_ref.actor.fsdp_config.param_offload=True
|
| 21 |
+
- actor_rollout_ref.actor.fsdp_config.optimizer_offload=False
|
| 22 |
+
- actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=32
|
| 23 |
+
- actor_rollout_ref.rollout.tensor_model_parallel_size=2
|
| 24 |
+
- actor_rollout_ref.rollout.name=vllm
|
| 25 |
+
- actor_rollout_ref.rollout.gpu_memory_utilization=0.6
|
| 26 |
+
- actor_rollout_ref.rollout.n=5
|
| 27 |
+
- actor_rollout_ref.rollout.load_format=safetensors
|
| 28 |
+
- actor_rollout_ref.rollout.layered_summon=True
|
| 29 |
+
- actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=32
|
| 30 |
+
- actor_rollout_ref.ref.fsdp_config.param_offload=False
|
| 31 |
+
- algorithm.use_kl_in_reward=False
|
| 32 |
+
- reward_model.enable=True
|
| 33 |
+
- reward_model.enable=True
|
| 34 |
+
- reward_model.model.path=/mnt/tidal-alsh01/dataset/redtrans/zhangruiqi/paper_grpo/Math-Shepherd/reward_model_converted
|
| 35 |
+
- reward_model.micro_batch_size_per_gpu=32
|
| 36 |
+
- trainer.critic_warmup=0
|
| 37 |
+
- trainer.logger=["console","wandb"]
|
| 38 |
+
- trainer.project_name=verl_grpo_gsm8k
|
| 39 |
+
- trainer.experiment_name=qwen3_4b_gsm8k_grpo
|
| 40 |
+
- trainer.n_gpus_per_node=8
|
| 41 |
+
- trainer.nnodes=1
|
| 42 |
+
- trainer.save_freq=20
|
| 43 |
+
- trainer.test_freq=5
|
| 44 |
+
- trainer.total_epochs=15
|
| 45 |
+
- trainer.resume_mode=disable
|