Spaces:
Sleeping

Sleeping
Upload 107 files
Browse filesThis view is limited to 50 files because it contains too many changes. See raw diff
- markdown_files/1._Development_Tools.md +22 -0
- markdown_files/2._Deployment_Tools.md +18 -0
- markdown_files/3._Large_Language_Models.md +68 -0
- markdown_files/4._Data_Sourcing.md +39 -0
- markdown_files/5._Data_Preparation.md +34 -0
- markdown_files/6._Data_Analysis.md +31 -0
- markdown_files/7._Data_Visualization.md +18 -0
- markdown_files/AI_Code_Editors__GitHub_Copilot.md +31 -0
- markdown_files/AI_Terminal_Tools__llm.md +76 -0
- markdown_files/Actor_Network_Visualization.md +26 -0
- markdown_files/Authentication__Google_Auth.md +93 -0
- markdown_files/BBC_Weather_API_with_Python.md +74 -0
- markdown_files/Base_64_Encoding.md +77 -0
- markdown_files/Browser__DevTools.md +69 -0
- markdown_files/CI_CD__GitHub_Actions.md +79 -0
- markdown_files/CORS.md +88 -0
- markdown_files/CSS_Selectors.md +39 -0
- markdown_files/Cleaning_Data_with_OpenRefine.md +31 -0
- markdown_files/Containers__Docker,_Podman.md +94 -0
- markdown_files/Convert_HTML_to_Markdown.md +183 -0
- markdown_files/Convert_PDFs_to_Markdown.md +139 -0
- markdown_files/Correlation_with_Excel.md +33 -0
- markdown_files/Crawling_with_the_CLI.md +137 -0
- markdown_files/Data_Aggregation_in_Excel.md +32 -0
- markdown_files/Data_Analysis_with_DuckDB.md +37 -0
- markdown_files/Data_Analysis_with_Python.md +37 -0
- markdown_files/Data_Analysis_with_SQL.md +39 -0
- markdown_files/Data_Cleansing_in_Excel.md +30 -0
- markdown_files/Data_Preparation_in_the_Editor.md +30 -0
- markdown_files/Data_Preparation_in_the_Shell.md +36 -0
- markdown_files/Data_Storytelling.md +18 -0
- markdown_files/Data_Transformation_in_Excel.md +30 -0
- markdown_files/Data_Transformation_with_dbt.md +64 -0
- markdown_files/Data_Visualization_with_Seaborn.md +20 -0
- markdown_files/Database__SQLite.md +148 -0
- markdown_files/DevContainers__GitHub_Codespaces.md +57 -0
- markdown_files/Editor__VS_Code.md +31 -0
- markdown_files/Embeddings.md +106 -0
- markdown_files/Extracting_Audio_and_Transcripts.md +298 -0
- markdown_files/Forecasting_with_Excel.md +25 -0
- markdown_files/Function_Calling.md +184 -0
- markdown_files/Geospatial_Analysis_with_Excel.md +33 -0
- markdown_files/Geospatial_Analysis_with_Python.md +34 -0
- markdown_files/Geospatial_Analysis_with_QGIS.md +32 -0
- markdown_files/Hybrid_RAG_with_TypeSense.md +154 -0
- markdown_files/Images__Compression.md +83 -0
- markdown_files/Interactive_Notebooks__Marimo.md +58 -0
- markdown_files/JSON.md +8 -0
- markdown_files/JavaScript_tools__npx.md +47 -0
- markdown_files/LLM_Agents.md +123 -0
markdown_files/1._Development_Tools.md
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "1. Development Tools"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/development-tools?id=development-tools"
|
| 4 |
+
downloaded_at: "2025-06-08T23:21:33.929318"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Development Tools](#/development-tools?id=development-tools)
|
| 8 |
+
=============================================================
|
| 9 |
+
|
| 10 |
+
**NOTE**: The tools in this module are **PRE-REQUISITES** for the course. You would have used most of these before. If most of this is new to you, please take this course later.
|
| 11 |
+
|
| 12 |
+
Some tools are fundamental to data science because they are industry standards and widely used by data science professionals. Mastering these tools will align you with current best practices and making you more adaptable in a fast-evolving industry.
|
| 13 |
+
|
| 14 |
+
The tools we cover here are not just popular, they’re the core technology behind most of today’s data science and software development.
|
| 15 |
+
|
| 16 |
+
[Previous
|
| 17 |
+
|
| 18 |
+
Tools in Data Science](#/README)
|
| 19 |
+
|
| 20 |
+
[Next
|
| 21 |
+
|
| 22 |
+
Editor: VS Code](#/vscode)
|
markdown_files/2._Deployment_Tools.md
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "2. Deployment Tools"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/deployment-tools?id=deployment-tools"
|
| 4 |
+
downloaded_at: "2025-06-08T23:26:43.558808"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Deployment Tools](#/deployment-tools?id=deployment-tools)
|
| 8 |
+
==========================================================
|
| 9 |
+
|
| 10 |
+
Any application you build is likely to be deployed somewhere. This section covers the most popular tools involved in deploying an application.
|
| 11 |
+
|
| 12 |
+
[Previous
|
| 13 |
+
|
| 14 |
+
Version Control: Git, GitHub](#/git)
|
| 15 |
+
|
| 16 |
+
[Next
|
| 17 |
+
|
| 18 |
+
Markdown](#/markdown)
|
markdown_files/3._Large_Language_Models.md
ADDED
|
@@ -0,0 +1,68 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "3. Large Language Models"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/large-language-models?id=large-language-models"
|
| 4 |
+
downloaded_at: "2025-06-08T23:23:17.306109"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Large Language Models](#/large-language-models?id=large-language-models)
|
| 8 |
+
=========================================================================
|
| 9 |
+
|
| 10 |
+
This module covers the practical usage of large language models (LLMs).
|
| 11 |
+
|
| 12 |
+
**LLMs incur a cost.** For the May 2025 batch, use [aipipe.org](https://aipipe.org/) as a proxy.
|
| 13 |
+
Emails with `@ds.study.iitm.ac.in` get a **$1 per calendar month** allowance. (Don’t exceed that.)
|
| 14 |
+
|
| 15 |
+
Read the [AI Pipe documentation](https://github.com/sanand0/aipipe) to learn how to use it. But in short:
|
| 16 |
+
|
| 17 |
+
1. Replace `OPENAI_BASE_URL`, i.e. `https://api.openai.com/v1` with `https://aipipe.org/openrouter/v1...` or `https://aipipe.org/openai/v1...`
|
| 18 |
+
2. Replace `OPENAI_API_KEY` with the [`AIPIPE_TOKEN`](https://aipipe.org/login)
|
| 19 |
+
3. Replace model names, e.g. `gpt-4.1-nano`, with `openai/gpt-4.1-nano`
|
| 20 |
+
|
| 21 |
+
For example, let’s use [Gemini 2.0 Flash Lite](https://cloud.google.com/vertex-ai/generative-ai/docs/models/gemini/2-0-flash-lite) via [OpenRouter](https://openrouter.ai/google/gemini-2.0-flash-lite-001) for chat completions and [Text Embedding 3 Small](https://platform.openai.com/docs/models/text-embedding-3-small) via [OpenAI](https://platform.openai.com/docs/) for embeddings:
|
| 22 |
+
|
| 23 |
+
```
|
| 24 |
+
curl https://aipipe.org/openrouter/v1/chat/completions \
|
| 25 |
+
-H "Content-Type: application/json" \
|
| 26 |
+
-H "Authorization: Bearer $AIPIPE_TOKEN" \
|
| 27 |
+
-d '{
|
| 28 |
+
"model": "google/gemini-2.0-flash-lite-001",
|
| 29 |
+
"messages": [{ "role": "user", "content": "What is 2 + 2?"} }]
|
| 30 |
+
}'
|
| 31 |
+
|
| 32 |
+
curl https://aipipe.org/openai/v1/embeddings \
|
| 33 |
+
-H "Content-Type: application/json" \
|
| 34 |
+
-H "Authorization: Bearer $AIPIPE_TOKEN" \
|
| 35 |
+
-d '{ "model": "text-embedding-3-small", "input": "What is 2 + 2?" }'Copy to clipboardErrorCopied
|
| 36 |
+
```
|
| 37 |
+
|
| 38 |
+
Or using [`llm`](https://llm.datasette.io/):
|
| 39 |
+
|
| 40 |
+
```
|
| 41 |
+
llm keys set openai --value $AIPIPE_TOKEN
|
| 42 |
+
|
| 43 |
+
export OPENAI_BASE_URL=https://aipipe.org/openrouter/v1
|
| 44 |
+
llm 'What is 2 + 2?' -m openrouter/google/gemini-2.0-flash-lite-001
|
| 45 |
+
|
| 46 |
+
export OPENAI_BASE_URL=https://aipipe.org/openai/v1
|
| 47 |
+
llm embed -c 'What is 2 + 2' -m 3-smallCopy to clipboardErrorCopied
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
**For a 50% discount** (but slower speed), use [Flex processing](https://platform.openai.com/docs/guides/flex-processing) by adding `service_tier: "flex"` to your JSON request.
|
| 51 |
+
|
| 52 |
+
[AI Proxy - Jan 2025](#/large-language-models?id=ai-proxy-jan-2025)
|
| 53 |
+
-------------------------------------------------------------------
|
| 54 |
+
|
| 55 |
+
For the Jan 2025 batch, we had created API keys for everyone with an `iitm.ac.in` email to use `gpt-4o-mini` and `text-embedding-3-small`. Your usage is limited to **$1 per calendar month** for this course. Don’t exceed that.
|
| 56 |
+
|
| 57 |
+
**Use [AI Proxy](https://github.com/sanand0/aiproxy)** instead of OpenAI. Specifically:
|
| 58 |
+
|
| 59 |
+
1. Replace your API to `https://api.openai.com/...` with `https://aiproxy.sanand.workers.dev/openai/...`
|
| 60 |
+
2. Replace the `OPENAI_API_KEY` with the `AIPROXY_TOKEN` that someone will give you.
|
| 61 |
+
|
| 62 |
+
[Previous
|
| 63 |
+
|
| 64 |
+
Local LLMs: Ollama](#/ollama)
|
| 65 |
+
|
| 66 |
+
[Next
|
| 67 |
+
|
| 68 |
+
Prompt engineering](#/prompt-engineering)
|
markdown_files/4._Data_Sourcing.md
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "4. Data Sourcing"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/data-sourcing?id=data-sourcing"
|
| 4 |
+
downloaded_at: "2025-06-08T23:24:22.670487"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Data Sourcing](#/data-sourcing?id=data-sourcing)
|
| 8 |
+
=================================================
|
| 9 |
+
|
| 10 |
+
Before you do any kind of data science, you obviously have to get the data to be able to analyze it, visualize it, narrate it, and deploy it.
|
| 11 |
+
And what we are going to cover in this module is how you get the data.
|
| 12 |
+
|
| 13 |
+
There are three ways you can get the data.
|
| 14 |
+
|
| 15 |
+
1. The first is you can **download** the data. Either somebody gives you the data and says download it from here, or you are asked to download it from the internet because it’s a public data source. But that’s the first way—you download the data.
|
| 16 |
+
2. The second way is you can **query it** from somewhere. It may be on a database. It may be available through an API. It may be available through a library. But these are ways in which you can selectively query parts of the data and stitch it together.
|
| 17 |
+
3. The third way is you have to **scrape it**. It’s not directly available in a convenient form that you can query or download. But it is, in fact, on a web page. It’s available on a PDF file. It’s available in a Word document. It’s available on an Excel file. It’s kind of structured, but you will have to figure out that structure and extract it from there.
|
| 18 |
+
|
| 19 |
+
In this module, we will be looking at the tools that will help you either download from a data source or query from an API or from a database or from a library. And finally, how you can scrape from different sources.
|
| 20 |
+
|
| 21 |
+
[](https://youtu.be/1LyblMkJzOo)
|
| 22 |
+
|
| 23 |
+
Here are links used in the video:
|
| 24 |
+
|
| 25 |
+
* [The Movies Dataset](https://www.kaggle.com/rounakbanik/the-movies-dataset)
|
| 26 |
+
* [IMDb Datasets](https://imdb.com/interfaces/)
|
| 27 |
+
* [Download the IMDb Datasets](https://datasets.imdbws.com/)
|
| 28 |
+
* [Explore the Internet Movie Database](https://gramener.com/imdb/)
|
| 29 |
+
* [What does the world search for?](https://gramener.com/search/)
|
| 30 |
+
* [HowStat - Cricket statistics](https://howstat.com/cricket/home.asp)
|
| 31 |
+
* [Cricket Strike Rates](https://gramener.com/cricket/)
|
| 32 |
+
|
| 33 |
+
[Previous
|
| 34 |
+
|
| 35 |
+
Project 1](#/project-tds-virtual-ta)
|
| 36 |
+
|
| 37 |
+
[Next
|
| 38 |
+
|
| 39 |
+
Scraping with Excel](#/scraping-with-excel)
|
markdown_files/5._Data_Preparation.md
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "5. Data Preparation"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/data-preparation?id=data-preparation"
|
| 4 |
+
downloaded_at: "2025-06-08T23:22:16.649843"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Data Preparation](#/data-preparation?id=data-preparation)
|
| 8 |
+
==========================================================
|
| 9 |
+
|
| 10 |
+
Data preparation is crucial because raw data is rarely perfect.
|
| 11 |
+
|
| 12 |
+
It often contains errors, inconsistencies, or missing values. For example, marks data may have ‘NA’ or ‘absent’ for non-attendees, which you need to handle.
|
| 13 |
+
|
| 14 |
+
This section teaches you how to clean up data, convert it to different formats, aggregate it if required, and get a feel for the data before you analyze.
|
| 15 |
+
|
| 16 |
+
Here are links used in the video:
|
| 17 |
+
|
| 18 |
+
* [Presentation used in the video](https://docs.google.com/presentation/d/1Gb0QnPUN1YOwM_O5EqDdXUdL-5Azp1Tf/view)
|
| 19 |
+
* [Scraping assembly elections - Notebook](https://colab.research.google.com/drive/1SP8yVxzmofQO48-yXF3rujqWk2iM0KSl)
|
| 20 |
+
* [Assembly election results (CSV)](https://github.com/datameet/india-election-data/blob/master/assembly-elections/assembly.csv)
|
| 21 |
+
* [`pdftotext` software](https://www.xpdfreader.com/pdftotext-man.html)
|
| 22 |
+
* [OpenRefine software](https://openrefine.org)
|
| 23 |
+
* [The most persistent party](https://gramener.com/election/parliament#story.ddp)
|
| 24 |
+
* [TN assembly election cartogram](https://gramener.com/election/cartogram?ST_NAME=Tamil%20Nadu)
|
| 25 |
+
|
| 26 |
+
[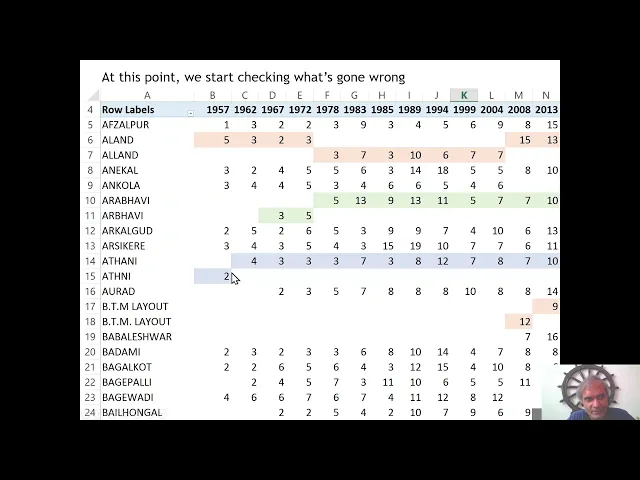](https://youtu.be/dF3zchJJKqk)
|
| 27 |
+
|
| 28 |
+
[Previous
|
| 29 |
+
|
| 30 |
+
Scraping: Live Sessions](#/scraping-live-sessions)
|
| 31 |
+
|
| 32 |
+
[Next
|
| 33 |
+
|
| 34 |
+
Data Cleansing in Excel](#/data-cleansing-in-excel)
|
markdown_files/6._Data_Analysis.md
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "6. Data Analysis"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/data-analysis?id=data-analysis"
|
| 4 |
+
downloaded_at: "2025-06-08T23:26:37.046522"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Data analysis](#/data-analysis?id=data-analysis)
|
| 8 |
+
=================================================
|
| 9 |
+
|
| 10 |
+
[Data Analysis: Introduction Podcast](https://drive.google.com/file/d/1isjtxFa43CLIFlLpo8mwwQfBog9VlXYl/view) by [NotebookLM](https://notebooklm.google.com/)
|
| 11 |
+
|
| 12 |
+
Once you’ve prepared the data, your next task is to analyze it to get insights that are not immediately obvious.
|
| 13 |
+
|
| 14 |
+
In this module, you’ll learn:
|
| 15 |
+
|
| 16 |
+
* **Statistical analysis**: Calculate correlations, regressions, forecasts, and outliers using **spreadsheets**
|
| 17 |
+
* **Data summarization**: Aggregate and pivot data using **Python** and **databases**.
|
| 18 |
+
* **Geo-data Collection & Processing**: Gather and process geospatial data using tools like Python (GeoPandas) and QGIS.
|
| 19 |
+
* **Geo-visualization**: Create and visualize geospatial data on maps using Excel, QGIS, and Python libraries such as Folium.
|
| 20 |
+
* **Network & Proximity Analysis**: Analyze geospatial relationships and perform network analysis to understand data distribution and clustering.
|
| 21 |
+
* **Storytelling & Decision Making**: Develop narratives and make informed decisions based on geospatial data insights.
|
| 22 |
+
|
| 23 |
+
[](https://youtu.be/CRSljunxjnk)
|
| 24 |
+
|
| 25 |
+
[Previous
|
| 26 |
+
|
| 27 |
+
Extracting Audio and Transcripts](#/extracting-audio-and-transcripts)
|
| 28 |
+
|
| 29 |
+
[Next
|
| 30 |
+
|
| 31 |
+
Correlation with Excel](#/correlation-with-excel)
|
markdown_files/7._Data_Visualization.md
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "7. Data Visualization"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/data-visualization?id=data-visualization"
|
| 4 |
+
downloaded_at: "2025-06-08T23:27:12.693601"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Data visualization](#/data-visualization?id=data-visualization)
|
| 8 |
+
================================================================
|
| 9 |
+
|
| 10 |
+
[](https://youtu.be/XkxRDql00UU)
|
| 11 |
+
|
| 12 |
+
[Previous
|
| 13 |
+
|
| 14 |
+
Network Analysis in Python](#/network-analysis-in-python)
|
| 15 |
+
|
| 16 |
+
[Next
|
| 17 |
+
|
| 18 |
+
Visualizing Forecasts with Excel](#/visualizing-forecasts-with-excel)
|
markdown_files/AI_Code_Editors__GitHub_Copilot.md
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "AI Code Editors: GitHub Copilot"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/github-copilot?id=ai-editor-github-copilot"
|
| 4 |
+
downloaded_at: "2025-06-08T23:26:20.399680"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[AI Editor: GitHub Copilot](#/github-copilot?id=ai-editor-github-copilot)
|
| 8 |
+
-------------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
AI Code Editors like [GitHub Copilot](https://github.com/features/copilot), [Cursor](https://www.cursor.com/), [Windsurf](http://windsurf.com/), [Roo Code](https://roocode.com/), [Cline](https://cline.bot/), [Continue.dev](https://www.continue.dev/), etc. use LLMs to help you write code faster.
|
| 11 |
+
|
| 12 |
+
Most are built on top of [VS Code](#/vscode). These are now a standard tool in every developer’s toolkit.
|
| 13 |
+
|
| 14 |
+
[GitHub Copilot](https://github.com/features/copilot) is [free](https://github.com/features/copilot/plans) (as of May 2025) for 2,000 completions and 50 chats.
|
| 15 |
+
|
| 16 |
+
[](https://youtu.be/n0NlxUyA7FI)
|
| 17 |
+
|
| 18 |
+
You should learn about:
|
| 19 |
+
|
| 20 |
+
* [Code Suggestions](https://docs.github.com/en/enterprise-cloud@latest/copilot/using-github-copilot/using-github-copilot-code-suggestions-in-your-editor), which is a basic feature.
|
| 21 |
+
* [Using Chat](https://docs.github.com/en/copilot/github-copilot-chat/using-github-copilot-chat-in-your-ide), which lets you code in natural language.
|
| 22 |
+
* [Changing the chat model](https://docs.github.com/en/copilot/using-github-copilot/ai-models/changing-the-ai-model-for-copilot-chat). The free version includes Claude 3.5 Sonnet, a good coding model.
|
| 23 |
+
* [Prompts](https://docs.github.com/en/copilot/copilot-chat-cookbook) to understand how people use AI code editors.
|
| 24 |
+
|
| 25 |
+
[Previous
|
| 26 |
+
|
| 27 |
+
Editor: VS Code](#/vscode)
|
| 28 |
+
|
| 29 |
+
[Next
|
| 30 |
+
|
| 31 |
+
Python tools: uv](#/uv)
|
markdown_files/AI_Terminal_Tools__llm.md
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "AI Terminal Tools: llm"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/llm?id=llm-cli-llm"
|
| 4 |
+
downloaded_at: "2025-06-08T23:25:09.715323"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[LLM CLI: llm](#/llm?id=llm-cli-llm)
|
| 8 |
+
------------------------------------
|
| 9 |
+
|
| 10 |
+
[`llm`](https://pypi.org/project/llm) is a command-line utility for interacting with large language models—simplifying prompts, managing models and plugins, logging every conversation, and extracting structured data for pipelines.
|
| 11 |
+
|
| 12 |
+
[](https://youtu.be/QUXQNi6jQ30?t=100)
|
| 13 |
+
|
| 14 |
+
### [Basic Usage](#/llm?id=basic-usage)
|
| 15 |
+
|
| 16 |
+
[Install llm](https://github.com/simonw/llm#installation). Then set up your [`OPENAI_API_KEY`](https://platform.openai.com/api-keys) environment variable. See [Getting started](https://github.com/simonw/llm?tab=readme-ov-file#getting-started).
|
| 17 |
+
|
| 18 |
+
**TDS Students**: See [Large Language Models](#/large-language-models) for instructions on how to get and use `OPENAI_API_KEY`.
|
| 19 |
+
|
| 20 |
+
```
|
| 21 |
+
# Run a simple prompt
|
| 22 |
+
llm 'five great names for a pet pelican'
|
| 23 |
+
|
| 24 |
+
# Continue a conversation
|
| 25 |
+
llm -c 'now do walruses'
|
| 26 |
+
|
| 27 |
+
# Start a memory-aware chat session
|
| 28 |
+
llm chat
|
| 29 |
+
|
| 30 |
+
# Specify a model
|
| 31 |
+
llm -m gpt-4.1-nano 'Summarize tomorrow’s meeting agenda'
|
| 32 |
+
|
| 33 |
+
# Extract JSON output
|
| 34 |
+
llm 'List the top 5 Python viz libraries with descriptions' \
|
| 35 |
+
--schema-multi 'name,description'Copy to clipboardErrorCopied
|
| 36 |
+
```
|
| 37 |
+
|
| 38 |
+
Or use llm without installation using [`uvx`](#/uv):
|
| 39 |
+
|
| 40 |
+
```
|
| 41 |
+
# Run llm via uvx without any prior installation
|
| 42 |
+
uvx llm 'Translate "Hello, world" into Japanese'
|
| 43 |
+
|
| 44 |
+
# Specify a model
|
| 45 |
+
uvx llm -m gpt-4.1-nano 'Draft a 200-word blog post on data ethics'
|
| 46 |
+
|
| 47 |
+
# Use structured JSON output
|
| 48 |
+
uvx llm 'List the top 5 programming languages in 2025 with their release years' \
|
| 49 |
+
--schema-multi 'rank,language,release_year'Copy to clipboardErrorCopied
|
| 50 |
+
```
|
| 51 |
+
|
| 52 |
+
### [Key Features](#/llm?id=key-features)
|
| 53 |
+
|
| 54 |
+
* **Interactive prompts**: `llm '…'` — Fast shell access to any LLM.
|
| 55 |
+
* **Conversational flow**: `-c '…'` — Continue context across prompts.
|
| 56 |
+
* **Model switching**: `-m MODEL` — Use OpenAI, Anthropic, local models, and more.
|
| 57 |
+
* **Structured output**: `llm json` — Produce JSON for automation.
|
| 58 |
+
* **Logging & history**: `llm logs path` — Persist every prompt/response in SQLite.
|
| 59 |
+
* **Web UI**: `datasette "$(llm logs path)"` — Browse your entire history with Datasette.
|
| 60 |
+
* **Persistent chat**: `llm chat` — Keep the model in memory across multiple interactions.
|
| 61 |
+
* **Plugin ecosystem**: `llm install PLUGIN` — Add support for new models, data sources, or workflows. ([Language models on the command-line - Simon Willison’s Weblog](https://simonwillison.net/2024/Jun/17/cli-language-models/?utm_source=chatgpt.com))
|
| 62 |
+
|
| 63 |
+
### [Practical Uses](#/llm?id=practical-uses)
|
| 64 |
+
|
| 65 |
+
* **Automated coding**. Generate code scaffolding, review helpers, or utilities on demand. For example, after running`llm install llm-cmd`, run `llm cmd 'Undo the last git commit'`. Inspired by [Simon’s post on using LLMs for rapid tool building](https://simonwillison.net/2025/Mar/11/using-llms-for-code/).
|
| 66 |
+
* **Transcript processing**. Summarize YouTube or podcast transcripts using Gemini. See [Putting Gemini 2.5 Pro through its paces](https://www.macstories.net/mac/llm-youtube-transcripts-with-claude-and-gemini-in-shortcuts/).
|
| 67 |
+
* **Commit messages**. Turn diffs into descriptive commit messages, e.g. `git diff | llm 'Write a concise git commit message explaining these changes'`. \
|
| 68 |
+
* **Data extraction**. Convert free-text into structured JSON for automation. [Structured data extraction from unstructured content using LLM schemas](https://simonwillison.net/2025/Feb/28/llm-schemas/).
|
| 69 |
+
|
| 70 |
+
[Previous
|
| 71 |
+
|
| 72 |
+
Terminal: Bash](#/bash)
|
| 73 |
+
|
| 74 |
+
[Next
|
| 75 |
+
|
| 76 |
+
Spreadsheet: Excel, Google Sheets](#/spreadsheets)
|
markdown_files/Actor_Network_Visualization.md
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Actor Network Visualization"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/actor-network-visualization?id=actor-network-visualization"
|
| 4 |
+
downloaded_at: "2025-06-08T23:23:12.679629"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Actor Network Visualization](#/actor-network-visualization?id=actor-network-visualization)
|
| 8 |
+
-------------------------------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
Find the shortest path between Govinda & Angelina Jolie using IMDb data using Python: [networkx](https://pypi.org/project/networkx/) or [scikit-network](https://pypi.org/project/scikit-network).
|
| 11 |
+
|
| 12 |
+
[](https://youtu.be/lcwMsPxPIjc)
|
| 13 |
+
|
| 14 |
+
* [Notebook: How this video was created](https://github.com/sanand0/jolie-no-1/blob/master/jolie-no-1.ipynb)
|
| 15 |
+
* [The data used to visualize the network](https://github.com/sanand0/jolie-no-1/blob/master/imdb-actor-pairing.ipynb)
|
| 16 |
+
* [The shortest path between actors](https://github.com/sanand0/jolie-no-1/blob/master/shortest-path.ipynb)
|
| 17 |
+
* [IMDB data](https://developer.imdb.com/non-commercial-datasets/)
|
| 18 |
+
* [Codebase](https://github.com/sanand0/jolie-no-1)
|
| 19 |
+
|
| 20 |
+
[Previous
|
| 21 |
+
|
| 22 |
+
Data Visualization with ChatGPT](#/data-visualization-with-chatgpt)
|
| 23 |
+
|
| 24 |
+
[Next
|
| 25 |
+
|
| 26 |
+
RAWgraphs](#/rawgraphs)
|
markdown_files/Authentication__Google_Auth.md
ADDED
|
@@ -0,0 +1,93 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Authentication: Google Auth"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/google-auth?id=google-authentication-with-fastapi"
|
| 4 |
+
downloaded_at: "2025-06-08T23:25:42.202598"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Google Authentication with FastAPI](#/google-auth?id=google-authentication-with-fastapi)
|
| 8 |
+
-----------------------------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
Secure your API endpoints using Google ID tokens to restrict access to specific email addresses.
|
| 11 |
+
|
| 12 |
+
[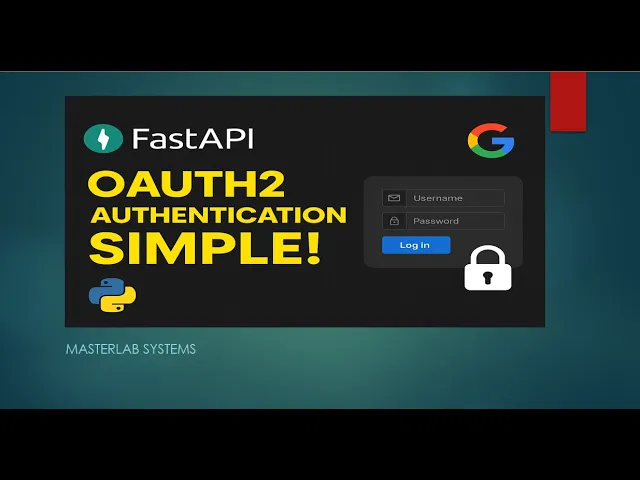](https://youtu.be/4ExQYRCwbzw)
|
| 13 |
+
|
| 14 |
+
Google Auth is the most commonly implemented single sign-on mechanism because:
|
| 15 |
+
|
| 16 |
+
* It’s popular and user-friendly. Users can log in with their existing Google accounts.
|
| 17 |
+
* It’s secure: Google supports OAuth2 and OpenID Connect to handle authentication.
|
| 18 |
+
|
| 19 |
+
Here’s how you build a FastAPI app that identifies the user.
|
| 20 |
+
|
| 21 |
+
1. Go to the [Google Cloud Console – Credentials](https://console.developers.google.com/apis/credentials) and click **Create Credentials > OAuth client ID**.
|
| 22 |
+
2. Choose **Web application**, set your authorized redirect URIs (e.g., `http://localhost:8000/`).
|
| 23 |
+
3. Copy the **Client ID** and **Client Secret** into a `.env` file:
|
| 24 |
+
|
| 25 |
+
```
|
| 26 |
+
GOOGLE_CLIENT_ID=your-client-id.apps.googleusercontent.com
|
| 27 |
+
GOOGLE_CLIENT_SECRET=your-client-secretCopy to clipboardErrorCopied
|
| 28 |
+
```
|
| 29 |
+
4. Create your FastAPI `app.py`:
|
| 30 |
+
|
| 31 |
+
```
|
| 32 |
+
# /// script
|
| 33 |
+
# dependencies = ["python-dotenv", "fastapi", "uvicorn", "itsdangerous", "httpx", "authlib"]
|
| 34 |
+
# ///
|
| 35 |
+
|
| 36 |
+
import os
|
| 37 |
+
from dotenv import load_dotenv
|
| 38 |
+
from fastapi import FastAPI, Request
|
| 39 |
+
from fastapi.responses import RedirectResponse
|
| 40 |
+
from starlette.middleware.sessions import SessionMiddleware
|
| 41 |
+
from authlib.integrations.starlette_client import OAuth
|
| 42 |
+
|
| 43 |
+
load_dotenv()
|
| 44 |
+
app = FastAPI()
|
| 45 |
+
app.add_middleware(SessionMiddleware, secret_key="create-a-random-secret-key")
|
| 46 |
+
|
| 47 |
+
oauth = OAuth()
|
| 48 |
+
oauth.register(
|
| 49 |
+
name="google",
|
| 50 |
+
client_id=os.getenv("GOOGLE_CLIENT_ID"),
|
| 51 |
+
client_secret=os.getenv("GOOGLE_CLIENT_SECRET"),
|
| 52 |
+
server_metadata_url="https://accounts.google.com/.well-known/openid-configuration",
|
| 53 |
+
client_kwargs={"scope": "openid email profile"},
|
| 54 |
+
)
|
| 55 |
+
|
| 56 |
+
@app.get("/")
|
| 57 |
+
async def application(request: Request):
|
| 58 |
+
user = request.session.get("user")
|
| 59 |
+
# 3. For authenticated users: say hello
|
| 60 |
+
if user:
|
| 61 |
+
return f"Hello {user['email']}"
|
| 62 |
+
# 2. For users who have just logged in, save their details in the session
|
| 63 |
+
if "code" in request.query_params:
|
| 64 |
+
token = await oauth.google.authorize_access_token(request)
|
| 65 |
+
request.session["user"] = token["userinfo"]
|
| 66 |
+
return RedirectResponse("/")
|
| 67 |
+
# 1. For users who are logging in for the first time, redirect to Google login
|
| 68 |
+
return await oauth.google.authorize_redirect(request, request.url)
|
| 69 |
+
|
| 70 |
+
if __name__ == "__main__":
|
| 71 |
+
import uvicorn
|
| 72 |
+
uvicorn.run(app, port=8000)Copy to clipboardErrorCopied
|
| 73 |
+
```
|
| 74 |
+
|
| 75 |
+
Now, run `uv run app.py`.
|
| 76 |
+
|
| 77 |
+
1. When you visit <http://localhost:8000/> you’ll be redirected to a Google login page.
|
| 78 |
+
2. When you log in, you’ll be redirected back to <http://localhost:8000/>
|
| 79 |
+
3. Now you’ll see the email ID you logged in with.
|
| 80 |
+
|
| 81 |
+
Instead of displaying the email, you can show different content based on the user. For example:
|
| 82 |
+
|
| 83 |
+
* Allow access to specfic users and not others
|
| 84 |
+
* Fetch the user’s personalized information
|
| 85 |
+
* Display different content based on the user
|
| 86 |
+
|
| 87 |
+
[Previous
|
| 88 |
+
|
| 89 |
+
Web Framework: FastAPI](#/fastapi)
|
| 90 |
+
|
| 91 |
+
[Next
|
| 92 |
+
|
| 93 |
+
Local LLMs: Ollama](#/ollama)
|
markdown_files/BBC_Weather_API_with_Python.md
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "BBC Weather API with Python"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/bbc-weather-api-with-python?id=bbc-weather-location-id-with-python"
|
| 4 |
+
downloaded_at: "2025-06-08T23:24:13.538036"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[BBC Weather location ID with Python](#/bbc-weather-api-with-python?id=bbc-weather-location-id-with-python)
|
| 8 |
+
-----------------------------------------------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
[](https://youtu.be/IafLrvnamAw)
|
| 11 |
+
|
| 12 |
+
You’ll learn how to get the location ID of any city from the BBC Weather API – as a precursor to scraping weather data – covering:
|
| 13 |
+
|
| 14 |
+
* **Understanding API Calls**: Learn how backend API calls work when searching for a city on the BBC weather website.
|
| 15 |
+
* **Inspecting Web Interactions**: Use the browser’s inspect element feature to track API calls and understand the network activity.
|
| 16 |
+
* **Extracting Location IDs**: Identify and extract the location ID from the API response using Python.
|
| 17 |
+
* **Using Python Libraries**: Import and use requests, json, and urlencode libraries to make API calls and process responses.
|
| 18 |
+
* **Constructing API URLs**: Create structured API URLs dynamically with constant prefixes and query parameters using urlencode.
|
| 19 |
+
* **Building Functions**: Develop a Python function that accepts a city name, constructs the API call, and returns the location ID.
|
| 20 |
+
|
| 21 |
+
To open the browser Developer Tools on Chrome, Edge, or Firefox, you can:
|
| 22 |
+
|
| 23 |
+
* Right-click on the page and select “Inspect” to open the developer tools
|
| 24 |
+
* OR: Press `F12`
|
| 25 |
+
* OR: Press `Ctrl+Shift+I` on Windows
|
| 26 |
+
* OR: Press `Cmd+Opt+I` on Mac
|
| 27 |
+
|
| 28 |
+
Here are links and references:
|
| 29 |
+
|
| 30 |
+
* [BBC Location ID scraping - Notebook](https://colab.research.google.com/drive/1-iV-tbtRicKR_HXWeu4Hi5aXJCV3QdQp)
|
| 31 |
+
* [BBC Weather - Palo Alto (location ID: 5380748)](https://www.bbc.com/weather/5380748)
|
| 32 |
+
* [BBC Locator Service - Los Angeles](https://locator-service.api.bbci.co.uk/locations?api_key=AGbFAKx58hyjQScCXIYrxuEwJh2W2cmv&stack=aws&locale=en&filter=international&place-types=settlement%2Cairport%2Cdistrict&order=importance&s=los%20angeles&a=true&format=json)
|
| 33 |
+
* Learn about the [`requests` package](https://docs.python-requests.org/en/latest/user/quickstart/). Watch [Python Requests Tutorial: Request Web Pages, Download Images, POST Data, Read JSON, and More](https://youtu.be/tb8gHvYlCFs)
|
| 34 |
+
|
| 35 |
+
[BBC Weather data with Python](#/bbc-weather-api-with-python?id=bbc-weather-data-with-python)
|
| 36 |
+
---------------------------------------------------------------------------------------------
|
| 37 |
+
|
| 38 |
+
[](https://youtu.be/Uc4DgQJDRoI)
|
| 39 |
+
|
| 40 |
+
You’ll learn how to scrape the live weather data of a city from the BBC Weather API, covering:
|
| 41 |
+
|
| 42 |
+
* **Introduction to Web Scraping**: Understand the basics of web scraping and its legality.
|
| 43 |
+
* **Libraries Overview**: Learn the importance of [`requests`](https://docs.python-requests.org/en/latest/user/quickstart/) and [`BeautifulSoup`](https://beautiful-soup-4.readthedocs.io/).
|
| 44 |
+
* **Fetching HTML**: Use [`requests`](https://docs.python-requests.org/en/latest/user/quickstart/) to fetch HTML content from a web page.
|
| 45 |
+
* **Parsing HTML**: Utilize [`BeautifulSoup`](https://beautiful-soup-4.readthedocs.io/) to parse and navigate the HTML content.
|
| 46 |
+
* **Identifying Data**: Inspect HTML elements to locate specific data (e.g., high and low temperatures).
|
| 47 |
+
* **Extracting Data**: Extract relevant data using [`BeautifulSoup`](https://beautiful-soup-4.readthedocs.io/)‘s `find_all()` function.
|
| 48 |
+
* **Data Cleanup**: Clean extracted data to remove unwanted elements.
|
| 49 |
+
* **Post-Processing**: Use regular expressions to split large strings into meaningful parts.
|
| 50 |
+
* **Data Structuring**: Combine extracted data into a structured pandas DataFrame.
|
| 51 |
+
* **Handling Special Characters**: Replace unwanted characters for better data manipulation.
|
| 52 |
+
* **Saving Data**: Save the cleaned data into CSV and Excel formats.
|
| 53 |
+
|
| 54 |
+
Here are links and references:
|
| 55 |
+
|
| 56 |
+
* [BBC Weather scraping - Notebook](https://colab.research.google.com/drive/1-gkMzE-TKe3U_yh1v0NPn4TM687H2Hcf)
|
| 57 |
+
* [BBC Locator Service - Mumbai](https://locator-service.api.bbci.co.uk/locations?api_key=AGbFAKx58hyjQScCXIYrxuEwJh2W2cmv&stack=aws&locale=en&filter=international&place-types=settlement%2Cairport%2Cdistrict&order=importance&s=mumbai&a=true&format=json)
|
| 58 |
+
* [BBC Weather - Mumbai (location ID: 1275339)](https://www.bbc.com/weather/1275339)
|
| 59 |
+
* [BBC Weather API - Mumbai (location ID: 1275339)](https://weather-broker-cdn.api.bbci.co.uk/en/forecast/aggregated/1275339)
|
| 60 |
+
* Learn about the [`json` package](https://docs.python.org/3/library/json.html). Watch [Python Tutorial: Working with JSON Data using the json Module](https://youtu.be/9N6a-VLBa2I)
|
| 61 |
+
* Learn about the [`BeautifulSoup` package](https://beautiful-soup-4.readthedocs.io/). Watch [Python Tutorial: Web Scraping with BeautifulSoup and Requests](https://youtu.be/ng2o98k983k)
|
| 62 |
+
* Learn about the [`pandas` package](https://pandas.pydata.org/pandas-docs/stable/user_guide/10min.html). Watch
|
| 63 |
+
+ [Python Pandas Tutorial (Part 1): Getting Started with Data Analysis - Installation and Loading Data](https://youtu.be/ZyhVh-qRZPA)
|
| 64 |
+
+ [Python Pandas Tutorial (Part 2): DataFrame and Series Basics - Selecting Rows and Columns](https://youtu.be/zmdjNSmRXF4)
|
| 65 |
+
* Learn about the [`re` package](https://docs.python.org/3/library/re.html). Watch [Python Tutorial: re Module - How to Write and Match Regular Expressions (Regex)](https://youtu.be/K8L6KVGG-7o)
|
| 66 |
+
* Learn about the [`datetime` package](https://docs.python.org/3/library/datetime.html). Watch [Python Tutorial: Datetime Module - How to work with Dates, Times, Timedeltas, and Timezones](https://youtu.be/eirjjyP2qcQ)
|
| 67 |
+
|
| 68 |
+
[Previous
|
| 69 |
+
|
| 70 |
+
Crawling with the CLI](#/crawling-cli)
|
| 71 |
+
|
| 72 |
+
[Next
|
| 73 |
+
|
| 74 |
+
Scraping IMDb with JavaScript](#/scraping-imdb-with-javascript)
|
markdown_files/Base_64_Encoding.md
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Base 64 Encoding"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/base64-encoding?id=base-64-encoding"
|
| 4 |
+
downloaded_at: "2025-06-08T23:27:25.543180"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Base 64 Encoding](#/base64-encoding?id=base-64-encoding)
|
| 8 |
+
=========================================================
|
| 9 |
+
|
| 10 |
+
Base64 is a method to convert binary data into ASCII text. It’s essential when you need to transmit binary data through text-only channels or embed binary content in text formats.
|
| 11 |
+
|
| 12 |
+
Watch this quick explanation of how Base64 works (3 min):
|
| 13 |
+
|
| 14 |
+
[](https://youtu.be/8qkxeZmKmOY)
|
| 15 |
+
|
| 16 |
+
Here’s how it works:
|
| 17 |
+
|
| 18 |
+
* It takes 3 bytes (24 bits) and converts them into 4 ASCII characters
|
| 19 |
+
* … using 64 characters: A-Z, a-z, 0-9, + and / (padding with `=` to make the length a multiple of 4)
|
| 20 |
+
* There’s a URL-safe variant of Base64 that replaces + and / with - and \_ to avoid issues in URLs
|
| 21 |
+
* Base64 adds ~33% overhead (since every 3 bytes becomes 4 characters)
|
| 22 |
+
|
| 23 |
+
Common Python operations with Base64:
|
| 24 |
+
|
| 25 |
+
```
|
| 26 |
+
import base64
|
| 27 |
+
|
| 28 |
+
# Basic encoding/decoding
|
| 29 |
+
text = "Hello, World!"
|
| 30 |
+
# Convert text to base64
|
| 31 |
+
encoded = base64.b64encode(text.encode()).decode() # SGVsbG8sIFdvcmxkIQ==
|
| 32 |
+
# Convert base64 back to text
|
| 33 |
+
decoded = base64.b64decode(encoded).decode() # Hello, World!
|
| 34 |
+
# Convert to URL-safe base64
|
| 35 |
+
url_safe = base64.urlsafe_b64encode(text.encode()).decode() # SGVsbG8sIFdvcmxkIQ==
|
| 36 |
+
|
| 37 |
+
# Working with binary files (e.g., images)
|
| 38 |
+
with open('image.png', 'rb') as f:
|
| 39 |
+
binary_data = f.read()
|
| 40 |
+
image_b64 = base64.b64encode(binary_data).decode()
|
| 41 |
+
|
| 42 |
+
# Data URI example (embed images in HTML/CSS)
|
| 43 |
+
data_uri = f"data:image/png;base64,{image_b64}"Copy to clipboardErrorCopied
|
| 44 |
+
```
|
| 45 |
+
|
| 46 |
+
Data URIs allow embedding binary data directly in HTML/CSS. This reduces the number of HTTP requests and also works offline. But it increases the file size.
|
| 47 |
+
|
| 48 |
+
For example, here’s an SVG image embedded as a data URI:
|
| 49 |
+
|
| 50 |
+
```
|
| 51 |
+
<img
|
| 52 |
+
src="data:image/svg+xml;base64,PHN2ZyB4bWxucz0iaHR0cDovL3d3dy53My5vcmcvMjAwMC9zdmciIHZpZXdCb3g9IjAgMCAzMiAzMiI+PGNpcmNsZSBjeD0iMTYiIGN5PSIxNiIgcj0iMTUiIGZpbGw9IiMyNTYzZWIiLz48cGF0aCBmaWxsPSIjZmZmIiBkPSJtMTYgNyAyIDcgNyAyLTcgMi0yIDctMi03LTctMiA3LTJaIi8+PC9zdmc+"
|
| 53 |
+
/>Copy to clipboardErrorCopied
|
| 54 |
+
```
|
| 55 |
+
|
| 56 |
+
Base64 is used in many places:
|
| 57 |
+
|
| 58 |
+
* JSON: Encoding binary data in JSON payloads
|
| 59 |
+
* Email: MIME attachments encoding
|
| 60 |
+
* Auth: HTTP Basic Authentication headers
|
| 61 |
+
* JWT: Encoding tokens in web authentication
|
| 62 |
+
* SSL/TLS: PEM certificate format
|
| 63 |
+
* SAML: Encoding assertions in SSO
|
| 64 |
+
* Git: Encoding binary files in patches
|
| 65 |
+
|
| 66 |
+
Tools for working with Base64:
|
| 67 |
+
|
| 68 |
+
* [Base64 Decoder/Encoder](https://www.base64decode.org/) for online encoding/decoding
|
| 69 |
+
* [data: URI Generator](https://dopiaza.org/tools/datauri/index.php) converts files to Data URIs
|
| 70 |
+
|
| 71 |
+
[Previous
|
| 72 |
+
|
| 73 |
+
LLM Text Extraction](#/llm-text-extraction)
|
| 74 |
+
|
| 75 |
+
[Next
|
| 76 |
+
|
| 77 |
+
Vision Models](#/vision-models)
|
markdown_files/Browser__DevTools.md
ADDED
|
@@ -0,0 +1,69 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Browser: DevTools"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/devtools?id=browser-devtools"
|
| 4 |
+
downloaded_at: "2025-06-08T23:21:14.785028"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Browser: DevTools](#/devtools?id=browser-devtools)
|
| 8 |
+
---------------------------------------------------
|
| 9 |
+
|
| 10 |
+
[Chrome DevTools](https://developer.chrome.com/docs/devtools/overview/) is the de facto standard for web development and data analysis in the browser.
|
| 11 |
+
You’ll use this a lot when debugging and inspecting web pages.
|
| 12 |
+
|
| 13 |
+
Here are the key features you’ll use most:
|
| 14 |
+
|
| 15 |
+
1. **Elements Panel**
|
| 16 |
+
|
| 17 |
+
* Inspect and modify HTML/CSS in real-time
|
| 18 |
+
* Copy CSS selectors for web scraping
|
| 19 |
+
* Debug layout issues with the Box Model
|
| 20 |
+
|
| 21 |
+
```
|
| 22 |
+
// Copy selector in Console
|
| 23 |
+
copy($0); // Copies selector of selected elementCopy to clipboardErrorCopied
|
| 24 |
+
```
|
| 25 |
+
2. **Console Panel**
|
| 26 |
+
|
| 27 |
+
* JavaScript REPL environment
|
| 28 |
+
* Log and debug data
|
| 29 |
+
* Common console methods:
|
| 30 |
+
|
| 31 |
+
```
|
| 32 |
+
console.table(data); // Display data in table format
|
| 33 |
+
console.group("Name"); // Group related logs
|
| 34 |
+
console.time("Label"); // Measure execution timeCopy to clipboardErrorCopied
|
| 35 |
+
```
|
| 36 |
+
3. **Network Panel**
|
| 37 |
+
|
| 38 |
+
* Monitor API requests and responses
|
| 39 |
+
* Simulate slow connections
|
| 40 |
+
* Right-click on a request and select “Copy as fetch” to get the request.
|
| 41 |
+
4. **Essential Keyboard Shortcuts**
|
| 42 |
+
|
| 43 |
+
* `Ctrl+Shift+I` (Windows) / `Cmd+Opt+I` (Mac): Open DevTools
|
| 44 |
+
* `Ctrl+Shift+C`: Select element to inspect
|
| 45 |
+
* `Ctrl+L`: Clear console
|
| 46 |
+
* `$0`: Reference currently selected element
|
| 47 |
+
* `$$('selector')`: Query selector all (returns array)
|
| 48 |
+
|
| 49 |
+
Videos from Chrome Developers (37 min total):
|
| 50 |
+
|
| 51 |
+
* [Fun & powerful: Intro to Chrome DevTools](https://youtu.be/t1c5tNPpXjs) (5 min)
|
| 52 |
+
* [Different ways to open Chrome DevTools](https://youtu.be/X65TAP8a530) (5 min)
|
| 53 |
+
* [Faster DevTools navigation with shortcuts and settings](https://youtu.be/xHusjrb_34A) (3 min)
|
| 54 |
+
* [How to log messages in the Console](https://youtu.be/76U0gtuV9AY) (6 min)
|
| 55 |
+
* [How to speed up your workflow with Console shortcuts](https://youtu.be/hdRDTj6ObiE) (6 min)
|
| 56 |
+
* [HTML vs DOM? Let’s debug them](https://youtu.be/J-02VNxE7lE) (5 min)
|
| 57 |
+
* [Caching demystified: Inspect, clear, and disable caches](https://youtu.be/mSMb-aH6sUw) (7 min)
|
| 58 |
+
* [Console message logging](https://youtu.be/76U0gtuV9AY) (6 min)
|
| 59 |
+
* [Console workflow shortcuts](https://youtu.be/hdRDTj6ObiE) (6 min)
|
| 60 |
+
* [HTML vs DOM debugging](https://youtu.be/J-02VNxE7lE) (5 min)
|
| 61 |
+
* [Cache inspection and management](https://youtu.be/mSMb-aH6sUw) (7 min)
|
| 62 |
+
|
| 63 |
+
[Previous
|
| 64 |
+
|
| 65 |
+
Unicode](#/unicode)
|
| 66 |
+
|
| 67 |
+
[Next
|
| 68 |
+
|
| 69 |
+
CSS Selectors](#/css-selectors)
|
markdown_files/CI_CD__GitHub_Actions.md
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "CI/CD: GitHub Actions"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/github-actions?id=cicd-github-actions"
|
| 4 |
+
downloaded_at: "2025-06-08T23:24:27.252899"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[CI/CD: GitHub Actions](#/github-actions?id=cicd-github-actions)
|
| 8 |
+
----------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
[GitHub Actions](https://github.com/features/actions) is a powerful automation platform built into GitHub. It helps automate your development workflow - running tests, deploying applications, updating datasets, retraining models, etc.
|
| 11 |
+
|
| 12 |
+
* Understand the basics of [YAML configuration files](https://docs.github.com/en/actions/writing-workflows/quickstart)
|
| 13 |
+
* Explore the [pre-built actions from the marketplace](https://github.com/marketplace?type=actions)
|
| 14 |
+
* How to [handle secrets securely](https://docs.github.com/en/actions/security-for-github-actions/security-guides/using-secrets-in-github-actions)
|
| 15 |
+
* [Triggering a workflow](https://docs.github.com/en/actions/writing-workflows/choosing-when-your-workflow-runs/triggering-a-workflow)
|
| 16 |
+
* Staying within the [free tier limits](https://docs.github.com/en/billing/managing-billing-for-your-products/managing-billing-for-github-actions/about-billing-for-github-actions)
|
| 17 |
+
* [Caching dependencies to speed up workflows](https://docs.github.com/en/actions/writing-workflows/choosing-what-your-workflow-does/caching-dependencies-to-speed-up-workflows)
|
| 18 |
+
|
| 19 |
+
Here is a sample `.github/workflows/iss-location.yml` that runs daily, appends the International Space Station location data into `iss-location.json`, and commits it to the repository.
|
| 20 |
+
|
| 21 |
+
```
|
| 22 |
+
name: Log ISS Location Data Daily
|
| 23 |
+
|
| 24 |
+
on:
|
| 25 |
+
schedule:
|
| 26 |
+
# Runs at 12:00 UTC (noon) every day
|
| 27 |
+
- cron: "0 12 * * *"
|
| 28 |
+
workflow_dispatch: # Allows manual triggering
|
| 29 |
+
|
| 30 |
+
jobs:
|
| 31 |
+
collect-iss-data:
|
| 32 |
+
runs-on: ubuntu-latest
|
| 33 |
+
permissions:
|
| 34 |
+
contents: write
|
| 35 |
+
|
| 36 |
+
steps:
|
| 37 |
+
- name: Checkout repository
|
| 38 |
+
uses: actions/checkout@v4
|
| 39 |
+
|
| 40 |
+
- name: Install uv
|
| 41 |
+
uses: astral-sh/setup-uv@v5
|
| 42 |
+
|
| 43 |
+
- name: Fetch ISS location data
|
| 44 |
+
run: | # python
|
| 45 |
+
uv run --with requests python << 'EOF'
|
| 46 |
+
import requests
|
| 47 |
+
|
| 48 |
+
data = requests.get('http://api.open-notify.org/iss-now.json').text
|
| 49 |
+
with open('iss-location.jsonl', 'a') as f:
|
| 50 |
+
f.write(data + '\n')
|
| 51 |
+
'EOF'
|
| 52 |
+
|
| 53 |
+
- name: Commit and push changes
|
| 54 |
+
run: | # shell
|
| 55 |
+
git config --local user.email "github-actions[bot]@users.noreply.github.com"
|
| 56 |
+
git config --local user.name "github-actions[bot]"
|
| 57 |
+
git add iss-location.jsonl
|
| 58 |
+
git commit -m "Update ISS position data [skip ci]" || exit 0
|
| 59 |
+
git pushCopy to clipboardErrorCopied
|
| 60 |
+
```
|
| 61 |
+
|
| 62 |
+
Tools:
|
| 63 |
+
|
| 64 |
+
* [GitHub CLI](https://cli.github.com/): Manage workflows from terminal
|
| 65 |
+
* [Super-Linter](https://github.com/github/super-linter): Validate code style
|
| 66 |
+
* [Release Drafter](https://github.com/release-drafter/release-drafter): Automate releases
|
| 67 |
+
* [act](https://github.com/nektos/act): Run actions locally
|
| 68 |
+
|
| 69 |
+
[](https://youtu.be/mFFXuXjVgkU)
|
| 70 |
+
|
| 71 |
+
* [How to handle secrets in GitHub Actions](https://youtu.be/1tD7km5jK70)
|
| 72 |
+
|
| 73 |
+
[Previous
|
| 74 |
+
|
| 75 |
+
Serverless hosting: Vercel](#/vercel)
|
| 76 |
+
|
| 77 |
+
[Next
|
| 78 |
+
|
| 79 |
+
Containers: Docker, Podman](#/docker)
|
markdown_files/CORS.md
ADDED
|
@@ -0,0 +1,88 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "CORS"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/cors?id=cors-cross-origin-resource-sharing"
|
| 4 |
+
downloaded_at: "2025-06-08T23:26:45.742238"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[CORS: Cross-Origin Resource Sharing](#/cors?id=cors-cross-origin-resource-sharing)
|
| 8 |
+
-----------------------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
CORS (Cross-Origin Resource Sharing) is a security mechanism that controls how web browsers handle requests between different origins (domains, protocols, or ports). Data scientists need CORS for APIs serving data or analysis to a browser on a different domain.
|
| 11 |
+
|
| 12 |
+
Watch this practical explanation of CORS (3 min):
|
| 13 |
+
|
| 14 |
+
[](https://youtu.be/4KHiSt0oLJ0)
|
| 15 |
+
|
| 16 |
+
Key CORS concepts:
|
| 17 |
+
|
| 18 |
+
* **Same-Origin Policy**: Browsers block requests between different origins by default
|
| 19 |
+
* **CORS Headers**: Server responses must include specific headers to allow cross-origin requests
|
| 20 |
+
* **Preflight Requests**: Browsers send OPTIONS requests to check if the actual request is allowed
|
| 21 |
+
* **Credentials**: Special handling required for requests with cookies or authentication
|
| 22 |
+
|
| 23 |
+
If you’re exposing your API with a GET request publicly, the only thing you need to do is set the HTTP header `Access-Control-Allow-Origin: *`.
|
| 24 |
+
|
| 25 |
+
Here are other common CORS headers:
|
| 26 |
+
|
| 27 |
+
```
|
| 28 |
+
Access-Control-Allow-Origin: https://example.com
|
| 29 |
+
Access-Control-Allow-Methods: GET, POST, PUT, DELETE
|
| 30 |
+
Access-Control-Allow-Headers: Content-Type, Authorization
|
| 31 |
+
Access-Control-Allow-Credentials: trueCopy to clipboardErrorCopied
|
| 32 |
+
```
|
| 33 |
+
|
| 34 |
+
To implement CORS in FastAPI, use the [`CORSMiddleware` middleware](https://fastapi.tiangolo.com/tutorial/cors/):
|
| 35 |
+
|
| 36 |
+
```
|
| 37 |
+
from fastapi import FastAPI
|
| 38 |
+
from fastapi.middleware.cors import CORSMiddleware
|
| 39 |
+
|
| 40 |
+
app = FastAPI()
|
| 41 |
+
|
| 42 |
+
app.add_middleware(CORSMiddleware, allow_origins=["*"]) # Allow GET requests from all origins
|
| 43 |
+
# Or, provide more granular control:
|
| 44 |
+
app.add_middleware(
|
| 45 |
+
CORSMiddleware,
|
| 46 |
+
allow_origins=["https://example.com"], # Allow a specific domain
|
| 47 |
+
allow_credentials=True, # Allow cookies
|
| 48 |
+
allow_methods=["GET", "POST", "PUT", "DELETE"], # Allow specific methods
|
| 49 |
+
allow_headers=["*"], # Allow all headers
|
| 50 |
+
)Copy to clipboardErrorCopied
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
Testing CORS with JavaScript:
|
| 54 |
+
|
| 55 |
+
```
|
| 56 |
+
// Simple request
|
| 57 |
+
const response = await fetch("https://api.example.com/data", {
|
| 58 |
+
method: "GET",
|
| 59 |
+
headers: { "Content-Type": "application/json" },
|
| 60 |
+
});
|
| 61 |
+
|
| 62 |
+
// Request with credentials
|
| 63 |
+
const response = await fetch("https://api.example.com/data", {
|
| 64 |
+
credentials: "include",
|
| 65 |
+
headers: { "Content-Type": "application/json" },
|
| 66 |
+
});Copy to clipboardErrorCopied
|
| 67 |
+
```
|
| 68 |
+
|
| 69 |
+
Useful CORS debugging tools:
|
| 70 |
+
|
| 71 |
+
* [CORS Checker](https://cors-test.codehappy.dev/): Test CORS configurations
|
| 72 |
+
* Browser DevTools Network tab: Inspect CORS headers and preflight requests
|
| 73 |
+
* [cors-anywhere](https://github.com/Rob--W/cors-anywhere): CORS proxy for development
|
| 74 |
+
|
| 75 |
+
Common CORS errors and solutions:
|
| 76 |
+
|
| 77 |
+
* `No 'Access-Control-Allow-Origin' header`: Configure server to send proper CORS headers
|
| 78 |
+
* `Request header field not allowed`: Add required headers to `Access-Control-Allow-Headers`
|
| 79 |
+
* `Credentials flag`: Set both `credentials: 'include'` and `Access-Control-Allow-Credentials: true`
|
| 80 |
+
* `Wild card error`: Cannot use `*` with credentials; specify exact origins
|
| 81 |
+
|
| 82 |
+
[Previous
|
| 83 |
+
|
| 84 |
+
Tunneling: ngrok](#/ngrok)
|
| 85 |
+
|
| 86 |
+
[Next
|
| 87 |
+
|
| 88 |
+
REST APIs](#/rest-apis)
|
markdown_files/CSS_Selectors.md
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "CSS Selectors"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/css-selectors?id=css-selectors"
|
| 4 |
+
downloaded_at: "2025-06-08T23:24:42.527184"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[CSS Selectors](#/css-selectors?id=css-selectors)
|
| 8 |
+
-------------------------------------------------
|
| 9 |
+
|
| 10 |
+
CSS selectors are patterns used to select and style HTML elements on a web page. They are fundamental to web development and data scraping, allowing you to precisely target elements for styling or extraction.
|
| 11 |
+
|
| 12 |
+
For data scientists, understanding CSS selectors is crucial when:
|
| 13 |
+
|
| 14 |
+
* Web scraping with tools like Beautiful Soup or Scrapy
|
| 15 |
+
* Selecting elements for browser automation with Selenium
|
| 16 |
+
* Styling data visualizations and web applications
|
| 17 |
+
* Debugging website issues using browser DevTools
|
| 18 |
+
|
| 19 |
+
Watch this comprehensive introduction to CSS selectors (20 min):
|
| 20 |
+
|
| 21 |
+
[](https://youtu.be/l1mER1bV0N0)
|
| 22 |
+
|
| 23 |
+
The Mozilla Developer Network (MDN) provides detailed documentation on the three main types of selectors:
|
| 24 |
+
|
| 25 |
+
* [Basic CSS selectors](https://developer.mozilla.org/en-US/docs/Learn_web_development/Core/Styling_basics/Basic_selectors): Learn about element (`div`), class (`.container`), ID (`#header`), and universal (`*`) selectors
|
| 26 |
+
* [Attribute selectors](https://developer.mozilla.org/en-US/docs/Learn_web_development/Core/Styling_basics/Attribute_selectors): Target elements based on their attributes or attribute values (`[type="text"]`)
|
| 27 |
+
* [Combinators](https://developer.mozilla.org/en-US/docs/Learn_web_development/Core/Styling_basics/Combinators): Use relationships between elements (`div > p`, `div + p`, `div ~ p`)
|
| 28 |
+
|
| 29 |
+
Practice your CSS selector skills with this interactive tool:
|
| 30 |
+
|
| 31 |
+
* [CSS Diner](https://flukeout.github.io/): A fun game that teaches CSS selectors through increasingly challenging levels
|
| 32 |
+
|
| 33 |
+
[Previous
|
| 34 |
+
|
| 35 |
+
Browser: DevTools](#/devtools)
|
| 36 |
+
|
| 37 |
+
[Next
|
| 38 |
+
|
| 39 |
+
JSON](#/json)
|
markdown_files/Cleaning_Data_with_OpenRefine.md
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Cleaning Data with OpenRefine"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/cleaning-data-with-openrefine?id=cleaning-data-with-openrefine"
|
| 4 |
+
downloaded_at: "2025-06-08T23:26:48.911609"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Cleaning Data with OpenRefine](#/cleaning-data-with-openrefine?id=cleaning-data-with-openrefine)
|
| 8 |
+
-------------------------------------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
[](https://youtu.be/zxEtfHseE84)
|
| 11 |
+
|
| 12 |
+
This session covers the use of OpenRefine for data cleaning, focusing on resolving entity discrepancies:
|
| 13 |
+
|
| 14 |
+
* **Data Upload and Project Creation**: Import data into OpenRefine and create a new project for analysis.
|
| 15 |
+
* **Faceting Data**: Use text facets to group similar entries and identify frequency of address crumbs.
|
| 16 |
+
* **Clustering Methodology**: Apply clustering algorithms to merge similar entries with minor differences, such as punctuation.
|
| 17 |
+
* **Manual and Automated Clustering**: Learn to merge clusters manually or in one go, trusting the system’s clustering accuracy.
|
| 18 |
+
* **Entity Resolution**: Clean and save the data by resolving multiple versions of the same entity using Open Refine.
|
| 19 |
+
|
| 20 |
+
Here are links used in the video:
|
| 21 |
+
|
| 22 |
+
* [OpenRefine software](https://openrefine.org)
|
| 23 |
+
* [Dataset for OpenRefine](https://drive.google.com/file/d/1ccu0Xxk8UJUa2Dz4lihmvzhLjvPy42Ai/view)
|
| 24 |
+
|
| 25 |
+
[Previous
|
| 26 |
+
|
| 27 |
+
Data Preparation in the Editor](#/data-preparation-in-the-editor)
|
| 28 |
+
|
| 29 |
+
[Next
|
| 30 |
+
|
| 31 |
+
Profiling Data with Python](#/profiling-data-with-python)
|
markdown_files/Containers__Docker,_Podman.md
ADDED
|
@@ -0,0 +1,94 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Containers: Docker, Podman"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/docker?id=containers-docker-podman"
|
| 4 |
+
downloaded_at: "2025-06-08T23:26:01.579602"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Containers: Docker, Podman](#/docker?id=containers-docker-podman)
|
| 8 |
+
------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
[Docker](https://www.docker.com/) and [Podman](https://podman.io/) are containerization tools that package your application and its dependencies into a standardized unit for software development and deployment.
|
| 11 |
+
|
| 12 |
+
Docker is the industry standard. Podman is compatible with Docker and has better security (and a slightly more open license). In this course, we recommend Podman but Docker works in the same way.
|
| 13 |
+
|
| 14 |
+
Initialize the container engine:
|
| 15 |
+
|
| 16 |
+
```
|
| 17 |
+
podman machine init
|
| 18 |
+
podman machine startCopy to clipboardErrorCopied
|
| 19 |
+
```
|
| 20 |
+
|
| 21 |
+
Common Operations. (You can use `docker` instead of `podman` in the same way.)
|
| 22 |
+
|
| 23 |
+
```
|
| 24 |
+
# Pull an image
|
| 25 |
+
podman pull python:3.11-slim
|
| 26 |
+
|
| 27 |
+
# Run a container
|
| 28 |
+
podman run -it python:3.11-slim
|
| 29 |
+
|
| 30 |
+
# List containers
|
| 31 |
+
podman ps -a
|
| 32 |
+
|
| 33 |
+
# Stop container
|
| 34 |
+
podman stop container_id
|
| 35 |
+
|
| 36 |
+
# Scan image for vulnerabilities
|
| 37 |
+
podman scan myapp:latest
|
| 38 |
+
|
| 39 |
+
# Remove container
|
| 40 |
+
podman rm container_id
|
| 41 |
+
|
| 42 |
+
# Remove all stopped containers
|
| 43 |
+
podman container pruneCopy to clipboardErrorCopied
|
| 44 |
+
```
|
| 45 |
+
|
| 46 |
+
You can create a `Dockerfile` to build a container image. Here’s a sample `Dockerfile` that converts a Python script into a container image.
|
| 47 |
+
|
| 48 |
+
```
|
| 49 |
+
FROM python:3.11-slim
|
| 50 |
+
# Set working directory
|
| 51 |
+
WORKDIR /app
|
| 52 |
+
# Typically, you would use `COPY . .` to copy files from the host machine,
|
| 53 |
+
# but here we're just using a simple script.
|
| 54 |
+
RUN echo 'print("Hello, world!")' > app.py
|
| 55 |
+
# Run the script
|
| 56 |
+
CMD ["python", "app.py"]Copy to clipboardErrorCopied
|
| 57 |
+
```
|
| 58 |
+
|
| 59 |
+
To build, run, and deploy the container, run these commands:
|
| 60 |
+
|
| 61 |
+
```
|
| 62 |
+
# Create an account on https://hub.docker.com/ and then login
|
| 63 |
+
podman login docker.io
|
| 64 |
+
|
| 65 |
+
# Build and run the container
|
| 66 |
+
podman build -t py-hello .
|
| 67 |
+
podman run -it py-hello
|
| 68 |
+
|
| 69 |
+
# Push the container to Docker Hub. Replace $DOCKER_HUB_USERNAME with your Docker Hub username.
|
| 70 |
+
podman push py-hello:latest docker.io/$DOCKER_HUB_USERNAME/py-hello
|
| 71 |
+
|
| 72 |
+
# Push adding a specific tag, e.g. dev
|
| 73 |
+
TAG=dev podman push py-hello docker.io/$DOCKER_HUB_USERNAME/py-hello:$TAGCopy to clipboardErrorCopied
|
| 74 |
+
```
|
| 75 |
+
|
| 76 |
+
Tools:
|
| 77 |
+
|
| 78 |
+
* [Dive](https://github.com/wagoodman/dive): Explore image layers
|
| 79 |
+
* [Skopeo](https://github.com/containers/skopeo): Work with container images
|
| 80 |
+
* [Trivy](https://github.com/aquasecurity/trivy): Security scanner
|
| 81 |
+
|
| 82 |
+
[](https://youtu.be/YXfA5O5Mr18)
|
| 83 |
+
|
| 84 |
+
[](https://youtu.be/gAkwW2tuIqE)
|
| 85 |
+
|
| 86 |
+
* Optional: For Windows, see [WSL 2 with Docker getting started](https://youtu.be/5RQbdMn04Oc)
|
| 87 |
+
|
| 88 |
+
[Previous
|
| 89 |
+
|
| 90 |
+
CI/CD: GitHub Actions](#/github-actions)
|
| 91 |
+
|
| 92 |
+
[Next
|
| 93 |
+
|
| 94 |
+
DevContainers: GitHub Codespaces](#/github-codespaces)
|
markdown_files/Convert_HTML_to_Markdown.md
ADDED
|
@@ -0,0 +1,183 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Convert HTML to Markdown"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/convert-html-to-markdown?id=markdown-crawler"
|
| 4 |
+
downloaded_at: "2025-06-08T23:25:38.805247"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Converting HTML to Markdown](#/convert-html-to-markdown?id=converting-html-to-markdown)
|
| 8 |
+
----------------------------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
When working with web content, converting HTML files to plain text or Markdown is a common requirement for content extraction, analysis, and preservation. For example:
|
| 11 |
+
|
| 12 |
+
* **Content analysis**: Extract clean text from HTML for natural language processing
|
| 13 |
+
* **Data mining**: Strip formatting to focus on the actual content
|
| 14 |
+
* **Offline reading**: Convert web pages to readable formats for e-readers or offline consumption
|
| 15 |
+
* **Content migration**: Move content between different CMS platforms
|
| 16 |
+
* **SEO analysis**: Extract headings, content structure, and text for optimization
|
| 17 |
+
* **Archive creation**: Store web content in more compact, preservation-friendly formats
|
| 18 |
+
* **Accessibility**: Convert content to formats that work better with screen readers
|
| 19 |
+
|
| 20 |
+
This tutorial covers both converting existing HTML files and combining web crawling with HTML-to-text conversion in a single workflow – all using the command line.
|
| 21 |
+
|
| 22 |
+
### [defuddle-cli](#/convert-html-to-markdown?id=defuddle-cli)
|
| 23 |
+
|
| 24 |
+
[defuddle-cli](https://github.com/defuddle/defuddle) specializes in HTML - Markdown conversion. It’s a bit slow and not very customizable but produces clean Markdown that preserves structure, links, and basic formatting. Best for content where preserving the document structure is important.
|
| 25 |
+
|
| 26 |
+
```
|
| 27 |
+
find . -name '*.html' -exec npx --package defuddle-cli -y defuddle parse {} --md -o {}.md \;Copy to clipboardErrorCopied
|
| 28 |
+
```
|
| 29 |
+
|
| 30 |
+
* `find . -name '*.html'`: Finds all HTML files in the current directory and subdirectories
|
| 31 |
+
* `-exec ... \;`: Executes the following command for each file found
|
| 32 |
+
* `npx --package defuddle-cli -y`: Installs and runs defuddle-cli without prompting
|
| 33 |
+
* `defuddle parse {} --md`: Parses the HTML file (represented by `{}`) and converts to markdown
|
| 34 |
+
* `-o {}.md`: Outputs to a file with the original name plus .md extension
|
| 35 |
+
|
| 36 |
+
### [Pandoc](#/convert-html-to-markdown?id=pandoc)
|
| 37 |
+
|
| 38 |
+
[Pandoc](https://pandoc.org/) is a bit slow and highly customizable, preserving almost all formatting elements, leading to verbose markdown. Best for academic or documentation conversion where precision matters.
|
| 39 |
+
|
| 40 |
+
Pandoc can convert from many other formats (such as Word, PDF, LaTeX, etc.) to Markdown and vice versa, making it one of most popular and versatele document convertors.
|
| 41 |
+
|
| 42 |
+
[](https://youtu.be/HPSK7q13-40)
|
| 43 |
+
|
| 44 |
+
```
|
| 45 |
+
find . -name '*.html' -exec pandoc -f html -t markdown_strict -o {}.md {} \;Copy to clipboardErrorCopied
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
* `find . -name '*.html'`: Finds all HTML files in the current directory and subdirectories
|
| 49 |
+
* `-exec ... \;`: Executes the following command for each file found
|
| 50 |
+
* `pandoc`: The Swiss Army knife of document conversion
|
| 51 |
+
* `-f html -t markdown_strict`: Convert from HTML format to strict markdown
|
| 52 |
+
* `-o {}.md {}`: Output to a markdown file, with the input file as the last argument
|
| 53 |
+
|
| 54 |
+
### [Lynx](#/convert-html-to-markdown?id=lynx)
|
| 55 |
+
|
| 56 |
+
[Lynx](https://lynx.invisible-island.net/) is fast and generates text (not Markdown) with minimal formatting. Lynx renders the HTML as it would appear in a text browser, preserving basic structure but losing complex formatting. Best for quick content extraction or when processing large numbers of files.
|
| 57 |
+
|
| 58 |
+
```
|
| 59 |
+
find . -type f -name '*.html' -exec sh -c 'for f; do lynx -dump -nolist "$f" > "${f%.html}.txt"; done' _ {} +Copy to clipboardErrorCopied
|
| 60 |
+
```
|
| 61 |
+
|
| 62 |
+
* `find . -type f -name '*.html'`: Finds all HTML files in the current directory and subdirectories
|
| 63 |
+
* `-exec sh -c '...' _ {} +`: Executes a shell command with batched files for efficiency
|
| 64 |
+
* `for f; do ... done`: Loops through each file in the batch
|
| 65 |
+
* `lynx -dump -nolist "$f"`: Uses the lynx text browser to render HTML as plain text
|
| 66 |
+
+ `-dump`: Output the rendered page to stdout
|
| 67 |
+
+ `-nolist`: Don’t include the list of links at the end
|
| 68 |
+
* `> "${f%.html}.txt"`: Save output to a .txt file with the same base name
|
| 69 |
+
|
| 70 |
+
### [w3m](#/convert-html-to-markdown?id=w3m)
|
| 71 |
+
|
| 72 |
+
[w3m](https://w3m.sourceforge.net/) is very slow processing with minimal formatting. w3m tends to be more thorough in its rendering than lynx but takes considerably longer. It supports basic JavaScript processing, making it better at handling modern websites with dynamic content. Best for cases where you need slightly better rendering than lynx, particularly for complex layouts and tables, and when some JavaScript processing is beneficial.
|
| 73 |
+
|
| 74 |
+
```
|
| 75 |
+
find . -type f -name '*.html' \
|
| 76 |
+
-exec sh -c 'for f; do \
|
| 77 |
+
w3m -dump -T text/html -cols 80 -no-graph "$f" > "${f%.html}.md"; \
|
| 78 |
+
done' _ {} +Copy to clipboardErrorCopied
|
| 79 |
+
```
|
| 80 |
+
|
| 81 |
+
* `find . -type f -name '*.html'`: Finds all HTML files in the current directory and subdirectories
|
| 82 |
+
* `-exec sh -c '...' _ {} +`: Executes a shell command with batched files for efficiency
|
| 83 |
+
* `for f; do ... done`: Loops through each file in the batch
|
| 84 |
+
* `w3m -dump -T text/html -cols 80 -no-graph "$f"`: Uses the w3m text browser to render HTML
|
| 85 |
+
+ `-dump`: Output the rendered page to stdout
|
| 86 |
+
+ `-T text/html`: Specify input format as HTML
|
| 87 |
+
+ `-cols 80`: Set output width to 80 columns
|
| 88 |
+
+ `-no-graph`: Don’t show graphic characters for tables and frames
|
| 89 |
+
* `> "${f%.html}.md"`: Save output to a .md file with the same base name
|
| 90 |
+
|
| 91 |
+
### [Comparison](#/convert-html-to-markdown?id=comparison)
|
| 92 |
+
|
| 93 |
+
| Approach | Speed | Format Quality | Preservation | Best For |
|
| 94 |
+
| --- | --- | --- | --- | --- |
|
| 95 |
+
| defuddle-cli | Slow | High | Good structure and links | Content migration, publishing |
|
| 96 |
+
| pandoc | Slow | Very High | Almost everything | Academic papers, documentation |
|
| 97 |
+
| lynx | Fast | Low | Basic structure only | Quick extraction, large batches |
|
| 98 |
+
| w3m | Very Slow | Medium-Low | Basic structure with better tables | Improved readability over lynx |
|
| 99 |
+
|
| 100 |
+
### [Optimize Batch Processing](#/convert-html-to-markdown?id=optimize-batch-processing)
|
| 101 |
+
|
| 102 |
+
1. **Process in parallel**: Use GNU Parallel for multi-core processing:
|
| 103 |
+
|
| 104 |
+
```
|
| 105 |
+
find . -name "*.html" | parallel "pandoc -f html -t markdown_strict -o {}.md {}"Copy to clipboardErrorCopied
|
| 106 |
+
```
|
| 107 |
+
2. **Filter files before processing**:
|
| 108 |
+
|
| 109 |
+
```
|
| 110 |
+
find . -name "*.html" -type f -size -1M -exec pandoc -f html -t markdown {} -o {}.md \;Copy to clipboardErrorCopied
|
| 111 |
+
```
|
| 112 |
+
3. **Customize output format** with additional parameters:
|
| 113 |
+
|
| 114 |
+
```
|
| 115 |
+
# For pandoc, preserve line breaks but simplify other formatting
|
| 116 |
+
find . -name "*.html" -exec pandoc -f html -t markdown --wrap=preserve --atx-headers {} -o {}.md \;Copy to clipboardErrorCopied
|
| 117 |
+
```
|
| 118 |
+
4. **Handle errors gracefully**:
|
| 119 |
+
|
| 120 |
+
```
|
| 121 |
+
find . -name "*.html" -exec sh -c 'for f; do pandoc -f html -t markdown "$f" -o "${f%.html}.md" 2>/dev/null || echo "Failed: $f" >> conversion_errors.log; done' _ {} +Copy to clipboardErrorCopied
|
| 122 |
+
```
|
| 123 |
+
|
| 124 |
+
### [Choosing the Right Tool](#/convert-html-to-markdown?id=choosing-the-right-tool)
|
| 125 |
+
|
| 126 |
+
* **Need speed with minimal formatting?** Use the lynx approach
|
| 127 |
+
* **Need precise, complete conversion?** Use pandoc
|
| 128 |
+
* **Need a balance of structure and cleanliness?** Try defuddle-cli
|
| 129 |
+
* **Working with complex tables?** w3m might render them better
|
| 130 |
+
|
| 131 |
+
Remember that the best approach depends on your specific use case, volume of files, and how you intend to use the converted text.
|
| 132 |
+
|
| 133 |
+
### [Combined Crawling and Conversion](#/convert-html-to-markdown?id=combined-crawling-and-conversion)
|
| 134 |
+
|
| 135 |
+
Sometimes you need to both crawl a website and convert its content to markdown or text in a single workflow, like [Crawl4AI](#/convert-html-to-markdown?id=crawl4ai) or [markdown-crawler](#/convert-html-to-markdown?id=markdown-crawler).
|
| 136 |
+
|
| 137 |
+
1. **For research/data collection**: Use a specialized crawler (like Crawl4AI) with post-processing conversion
|
| 138 |
+
2. **For simple website archiving**: Markdown-crawler provides a convenient all-in-one solution
|
| 139 |
+
3. **For high-quality conversion**: Use wget/wget2 for crawling followed by pandoc for conversion
|
| 140 |
+
4. **For maximum speed**: Combine wget with lynx in a pipeline
|
| 141 |
+
|
| 142 |
+
### [Crawl4AI](#/convert-html-to-markdown?id=crawl4ai)
|
| 143 |
+
|
| 144 |
+
[Crawl4AI](https://github.com/crawl4ai/crawl4ai) is designed for single-page extraction with high-quality content processing. Crawl4AI is optimized for AI training data extraction, focusing on clean, structured content rather than complete site preservation. It excels at removing boilerplate content and preserving the main article text.
|
| 145 |
+
|
| 146 |
+
```
|
| 147 |
+
uv venv
|
| 148 |
+
source .venv/bin/activate.fish
|
| 149 |
+
uv pip install crawl4ai
|
| 150 |
+
crawl4ai-setupCopy to clipboardErrorCopied
|
| 151 |
+
```
|
| 152 |
+
|
| 153 |
+
* `uv venv`: Creates a Python virtual environment using uv (a faster alternative to virtualenv)
|
| 154 |
+
* `source .venv/bin/activate.fish`: Activates the virtual environment (fish shell syntax)
|
| 155 |
+
* `uv pip install crawl4ai`: Installs the crawl4ai package
|
| 156 |
+
* `crawl4ai-setup`: Initializes crawl4ai’s required dependencies
|
| 157 |
+
|
| 158 |
+
### [markdown-crawler](#/convert-html-to-markdown?id=markdown-crawler)
|
| 159 |
+
|
| 160 |
+
[markdown-crawler](https://pypi.org/project/markdown-crawler/) combines web crawling with markdown conversion in one tool. It’s efficient for bulk processing but tends to produce lower-quality markdown conversion compared to specialized converters like pandoc or defuddle. Best for projects where quantity and integration are more important than perfect formatting.
|
| 161 |
+
|
| 162 |
+
```
|
| 163 |
+
uv venv
|
| 164 |
+
source .venv/bin/activate.fish
|
| 165 |
+
uv pip install markdown-crawler
|
| 166 |
+
markdown-crawler -t 5 -d 3 -b ./markdown https://study.iitm.ac.in/ds/Copy to clipboardErrorCopied
|
| 167 |
+
```
|
| 168 |
+
|
| 169 |
+
* `uv venv` and activation: Same as above
|
| 170 |
+
* `uv pip install markdown-crawler`: Installs the markdown-crawler package
|
| 171 |
+
* `markdown-crawler`: Runs the crawler with these options:
|
| 172 |
+
+ `-t 5`: Sets 5 threads for parallel crawling
|
| 173 |
+
+ `-d 3`: Limits crawl depth to 3 levels
|
| 174 |
+
+ `-b ./markdown`: Sets the base output directory
|
| 175 |
+
+ Final argument is the starting URL
|
| 176 |
+
|
| 177 |
+
[Previous
|
| 178 |
+
|
| 179 |
+
Convert PDFs to Markdown](#/convert-pdfs-to-markdown)
|
| 180 |
+
|
| 181 |
+
[Next
|
| 182 |
+
|
| 183 |
+
LLM Website Scraping](#/llm-website-scraping)
|
markdown_files/Convert_PDFs_to_Markdown.md
ADDED
|
@@ -0,0 +1,139 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Convert PDFs to Markdown"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/convert-pdfs-to-markdown?id=tips-for-optimal-pdf-conversion"
|
| 4 |
+
downloaded_at: "2025-06-08T23:25:59.398450"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Converting PDFs to Markdown](#/convert-pdfs-to-markdown?id=converting-pdfs-to-markdown)
|
| 8 |
+
----------------------------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
PDF documents are ubiquitous in academic, business, and technical contexts, but extracting and repurposing their content can be challenging. This tutorial explores various command-line tools for converting PDFs to Markdown format, with a focus on preserving structure and formatting suitable for different use cases, including preparation for Large Language Models (LLMs).
|
| 11 |
+
|
| 12 |
+
Use Cases:
|
| 13 |
+
|
| 14 |
+
* **LLM training and fine-tuning**: Create clean text data from PDFs for AI model training
|
| 15 |
+
* **Knowledge base creation**: Transform PDFs into searchable, editable markdown documents
|
| 16 |
+
* **Content repurposing**: Convert academic papers and reports for web publication
|
| 17 |
+
* **Data extraction**: Pull structured content from PDF documents for analysis
|
| 18 |
+
* **Accessibility**: Convert PDFs to more accessible formats for screen readers
|
| 19 |
+
* **Citation and reference management**: Extract bibliographic information from academic papers
|
| 20 |
+
* **Documentation conversion**: Transform technical PDFs into maintainable documentation
|
| 21 |
+
|
| 22 |
+
### [PyMuPDF4LLM](#/convert-pdfs-to-markdown?id=pymupdf4llm)
|
| 23 |
+
|
| 24 |
+
[PyMuPDF4LLM](https://pymupdf.readthedocs.io/en/latest/pymupdf4llm/) is a specialized component of the PyMuPDF library that generates Markdown specifically formatted for Large Language Models. It produces high-quality markdown with good preservation of document structure. It’s specifically optimized for producing text that works well with LLMs, removing irrelevant formatting while preserving semantic structure. Requires PyTorch, which adds dependencies but enables more advanced processing capabilities.
|
| 25 |
+
|
| 26 |
+
PyMuPDF4LLM uses [MuPDF](https://mupdf.com/) as its PDF parsing engine. [PyMuPDF](https://pymupdf.readthedocs.io/) is emerging as a strong default for PDF text extraction due to its accuracy and performance in handling complex PDF structures.
|
| 27 |
+
|
| 28 |
+
```
|
| 29 |
+
PYTHONUTF8=1 uv run --with pymupdf4llm python -c 'import pymupdf4llm; h = open("pymupdf4llm.md", "w"); h.write(pymupdf4llm.to_markdown("$FILE.pdf"))'Copy to clipboardErrorCopied
|
| 30 |
+
```
|
| 31 |
+
|
| 32 |
+
* `PYTHONUTF8=1`: Forces Python to use UTF-8 encoding regardless of system locale
|
| 33 |
+
* `uv run --with pymupdf4llm`: Uses uv package manager to run Python with the pymupdf4llm package
|
| 34 |
+
* `python -c '...'`: Executes Python code directly from the command line
|
| 35 |
+
* `import pymupdf4llm`: Imports the PDF-to-Markdown module
|
| 36 |
+
* `h = open("pymupdf4llm.md", "w")`: Creates a file to write the markdown output
|
| 37 |
+
* `h.write(pymupdf4llm.to_markdown("$FILE.pdf"))`: Converts the PDF to markdown and writes to file
|
| 38 |
+
|
| 39 |
+
[Markitdown](#/convert-pdfs-to-markdown?id=markitdown)
|
| 40 |
+
------------------------------------------------------
|
| 41 |
+
|
| 42 |
+
[](https://youtu.be/v65Oyddfxeg)
|
| 43 |
+
|
| 44 |
+
[Markitdown](https://github.com/microsoft/markitdown) is Microsoft’s tool for converting various document formats to Markdown, including PDFs, DOCX, XLSX, PPTX, and ZIP files. It’s a versatile multi-format converter that handles PDFs via PDFMiner, DOCX via Mammoth, XLSX via Pandas, and PPTX via Python-PPTX. Good for batch processing of mixed document types. The quality of PDF conversion is generally good but may struggle with complex layouts or heavily formatted documents.
|
| 45 |
+
|
| 46 |
+
```
|
| 47 |
+
PYTHONUTF8=1 uvx markitdown $FILE.pdf > markitdown.mdCopy to clipboardErrorCopied
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
* `PYTHONUTF8=1`: Forces Python to use UTF-8 encoding
|
| 51 |
+
* `uvx markitdown`: Runs the markitdown tool via the uv package manager
|
| 52 |
+
* `$FILE.pdf`: The input PDF file
|
| 53 |
+
* `> markitdown.md`: Redirects output to a markdown file
|
| 54 |
+
|
| 55 |
+
### [Unstructured](#/convert-pdfs-to-markdown?id=unstructured)
|
| 56 |
+
|
| 57 |
+
[Unstructured](https://unstructured.io/) is rapidly becoming the de facto library for parsing over 40 different file types. It is excellent for extracting text and tables from diverse document formats. Particularly useful for generating clean content to pass to LLMs. Strong community support and actively maintained.
|
| 58 |
+
|
| 59 |
+
[GROBID](#/convert-pdfs-to-markdown?id=grobid)
|
| 60 |
+
----------------------------------------------
|
| 61 |
+
|
| 62 |
+
If you specifically need to parse references from text-native PDFs or reliably OCR’ed ones, [GROBID](https://github.com/kermitt2/grobid) remains the de facto choice. It excels at extracting structured bibliographic information with high accuracy.
|
| 63 |
+
|
| 64 |
+
```
|
| 65 |
+
# Start GROBID service
|
| 66 |
+
docker run -t --rm -p 8070:8070 lfoppiano/grobid:0.7.2
|
| 67 |
+
|
| 68 |
+
# Process PDF with curl
|
| 69 |
+
curl -X POST -F "input=@paper.pdf" localhost:8070/api/processFulltextDocument > references.tei.xmlCopy to clipboardErrorCopied
|
| 70 |
+
```
|
| 71 |
+
|
| 72 |
+
### [Mistral OCR API](#/convert-pdfs-to-markdown?id=mistral-ocr-api)
|
| 73 |
+
|
| 74 |
+
[Mistral OCR](https://mistral.ai/products/ocr/) offers an end-to-end cloud API that preserves both text and layout, making it easier to isolate specific sections like References. It shows the most promise currently, though it requires post-processing.
|
| 75 |
+
|
| 76 |
+
[Azure Document Intelligence API](#/convert-pdfs-to-markdown?id=azure-document-intelligence-api)
|
| 77 |
+
------------------------------------------------------------------------------------------------
|
| 78 |
+
|
| 79 |
+
For enterprise users already in the Microsoft ecosystem, [Azure Document Intelligence](https://azure.microsoft.com/en-us/products/ai-services/document-intelligence) provides excellent raw OCR with enterprise SLAs. May require custom model training or post-processing to match GROBID’s reference extraction capabilities.
|
| 80 |
+
|
| 81 |
+
### [Other libraries](#/convert-pdfs-to-markdown?id=other-libraries)
|
| 82 |
+
|
| 83 |
+
[Docling](https://github.com/DS4SD/docling) is IBM’s document understanding library that supports PDF conversion. It can be challenging to install, particularly on Windows and some Linux distributions. Offers advanced document understanding capabilities beyond simple text extraction.
|
| 84 |
+
|
| 85 |
+
[MegaParse](https://github.com/QuivrHQ/MegaParse) takes a comprehensive approach using LibreOffice, Pandoc, Tesseract OCR, and other tools. It has Robust handling of different document types but requires an OpenAI API key for some features. Good for complex documents but has significant dependencies.
|
| 86 |
+
|
| 87 |
+
[Comparison of PDF-to-Markdown Tools](#/convert-pdfs-to-markdown?id=comparison-of-pdf-to-markdown-tools)
|
| 88 |
+
--------------------------------------------------------------------------------------------------------
|
| 89 |
+
|
| 90 |
+
| Tool | Strengths | Weaknesses | Best For |
|
| 91 |
+
| --- | --- | --- | --- |
|
| 92 |
+
| PyMuPDF4LLM | Structure preservation, LLM optimization | Requires PyTorch | AI training data, semantic structure |
|
| 93 |
+
| Markitdown | Multi-format support, simple usage | Less precise layout handling | Batch processing, mixed documents |
|
| 94 |
+
| Unstructured | Wide format support, active development | Can be resource-intensive | Production pipelines, integration |
|
| 95 |
+
| GROBID | Reference extraction excellence | Narrower use case | Academic papers, citations |
|
| 96 |
+
| Docling | Advanced document understanding | Installation difficulties | Research applications |
|
| 97 |
+
| MegaParse | Comprehensive approach | Requires OpenAI API | Complex documents, OCR needs |
|
| 98 |
+
|
| 99 |
+
How to pick:
|
| 100 |
+
|
| 101 |
+
* **Need LLM-ready content?** PyMuPDF4LLM is specifically designed for this
|
| 102 |
+
* **Working with multiple document formats?** Markitdown handles diverse inputs
|
| 103 |
+
* **Extracting academic references?** GROBID remains the standard
|
| 104 |
+
* **Building a production pipeline?** Unstructured offers the best integration options
|
| 105 |
+
* **Handling complex layouts?** Consider commercial OCR like Mistral or Azure Document Intelligence
|
| 106 |
+
|
| 107 |
+
The optimal approach depends on your specific requirements regarding accuracy, structure preservation, and the intended use of the extracted content.
|
| 108 |
+
|
| 109 |
+
[Tips for Optimal PDF Conversion](#/convert-pdfs-to-markdown?id=tips-for-optimal-pdf-conversion)
|
| 110 |
+
------------------------------------------------------------------------------------------------
|
| 111 |
+
|
| 112 |
+
1. **Pre-process PDFs** when possible:
|
| 113 |
+
|
| 114 |
+
```
|
| 115 |
+
# Optimize a PDF for text extraction first
|
| 116 |
+
ocrmypdf --optimize 3 --skip-text input.pdf optimized.pdfCopy to clipboardErrorCopied
|
| 117 |
+
```
|
| 118 |
+
2. **Try multiple tools** on the same document to compare results:
|
| 119 |
+
3. **Handle scanned PDFs** appropriately:
|
| 120 |
+
|
| 121 |
+
```
|
| 122 |
+
# For scanned documents, run OCR first
|
| 123 |
+
ocrmypdf --force-ocr input.pdf ocr_ready.pdf
|
| 124 |
+
PYTHONUTF8=1 uvx markitdown ocr_ready.pdf > markitdown.mdCopy to clipboardErrorCopied
|
| 125 |
+
```
|
| 126 |
+
4. **Consider post-processing** for better results:
|
| 127 |
+
|
| 128 |
+
```
|
| 129 |
+
# Simple post-processing example
|
| 130 |
+
sed -i 's/\([A-Z]\)\./\1\.\n/g' output.md # Add line breaks after sentencesCopy to clipboardErrorCopied
|
| 131 |
+
```
|
| 132 |
+
|
| 133 |
+
[Previous
|
| 134 |
+
|
| 135 |
+
Scraping PDFs with Tabula](#/scraping-pdfs-with-tabula)
|
| 136 |
+
|
| 137 |
+
[Next
|
| 138 |
+
|
| 139 |
+
Convert HTML to Markdown](#/convert-html-to-markdown)
|
markdown_files/Correlation_with_Excel.md
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Correlation with Excel"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/correlation-with-excel?id=correlation-with-excel"
|
| 4 |
+
downloaded_at: "2025-06-08T23:24:31.921246"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Correlation with Excel](#/correlation-with-excel?id=correlation-with-excel)
|
| 8 |
+
----------------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
[](https://youtu.be/lXHCyhO7DmY)
|
| 11 |
+
|
| 12 |
+
You’ll learn to calculate and interpret correlations using Excel, covering:
|
| 13 |
+
|
| 14 |
+
* **Enabling the Data Analysis Tool Pack**: Steps to enable the Excel data analysis tool pack.
|
| 15 |
+
* **Correlation Analysis**: Understanding statistical association between variables.
|
| 16 |
+
* **Creating a Correlation Matrix**: Steps to generate and interpret a correlation matrix.
|
| 17 |
+
* **Scatterplots and Trendlines**: Plotting data and adding trend lines to visualize correlations.
|
| 18 |
+
* **Analyzing Results**: Comparing correlation coefficients and understanding their implications.
|
| 19 |
+
* **Insights and Further Analysis**: Interpreting scatterplots and planning further analysis for deeper insights.
|
| 20 |
+
|
| 21 |
+
Here are the links used in the video:
|
| 22 |
+
|
| 23 |
+
* [Understand correlation](https://www.khanacademy.org/math/ap-statistics/bivariate-data-ap/correlation-coefficient-r/v/correlation-coefficient-intuition-examples)
|
| 24 |
+
* [COVID-19 vaccinations data explorer - Website](https://ourworldindata.org/covid-vaccinations?country=OWID_WRL)
|
| 25 |
+
* [COVID-19 vaccinations - Correlations Excel file](https://docs.google.com/spreadsheets/d/1_vQF2i5ubKmHQMBqoTwsu6AlevWsQtTD/view#gid=790744269)
|
| 26 |
+
|
| 27 |
+
[Previous
|
| 28 |
+
|
| 29 |
+
6. Data Analysis](#/data-analysis)
|
| 30 |
+
|
| 31 |
+
[Next
|
| 32 |
+
|
| 33 |
+
Regression with Excel](#/regression-with-excel)
|
markdown_files/Crawling_with_the_CLI.md
ADDED
|
@@ -0,0 +1,137 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Crawling with the CLI"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/crawling-cli?id=wpull"
|
| 4 |
+
downloaded_at: "2025-06-08T23:26:52.185904"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Crawling with the CLI](#/crawling-cli?id=crawling-with-the-cli)
|
| 8 |
+
----------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
Since websites are a common source of data, we often download entire websites (crawling) and then process them offline.
|
| 11 |
+
|
| 12 |
+
Web crawling is essential in many data-driven scenarios:
|
| 13 |
+
|
| 14 |
+
* **Data mining and analysis**: Gathering structured data from multiple pages for market research, competitive analysis, or academic research
|
| 15 |
+
* **Content archiving**: Creating offline copies of websites for preservation or backup purposes
|
| 16 |
+
* **SEO analysis**: Analyzing site structure, metadata, and content to improve search rankings
|
| 17 |
+
* **Legal compliance**: Capturing website content for regulatory or compliance documentation
|
| 18 |
+
* **Website migration**: Creating a complete copy before moving to a new platform or design
|
| 19 |
+
* **Offline access**: Downloading educational resources, documentation, or reference materials for use without internet connection
|
| 20 |
+
|
| 21 |
+
The most commonly used tool for fetching websites is [`wget`](https://www.gnu.org/software/wget/). It is pre-installed in many UNIX distributions and easy to install.
|
| 22 |
+
|
| 23 |
+
[](https://youtu.be/pLfH5TZBGXo)
|
| 24 |
+
|
| 25 |
+
To crawl the [IIT Madras Data Science Program website](https://study.iitm.ac.in/ds/) for example, you could run:
|
| 26 |
+
|
| 27 |
+
```
|
| 28 |
+
wget \
|
| 29 |
+
--recursive \
|
| 30 |
+
--level=3 \
|
| 31 |
+
--no-parent \
|
| 32 |
+
--convert-links \
|
| 33 |
+
--adjust-extension \
|
| 34 |
+
--compression=auto \
|
| 35 |
+
--accept html,htm \
|
| 36 |
+
--directory-prefix=./ds \
|
| 37 |
+
https://study.iitm.ac.in/ds/Copy to clipboardErrorCopied
|
| 38 |
+
```
|
| 39 |
+
|
| 40 |
+
Here’s what each option does:
|
| 41 |
+
|
| 42 |
+
* `--recursive`: Enables recursive downloading (following links)
|
| 43 |
+
* `--level=3`: Limits recursion depth to 3 levels from the initial URL
|
| 44 |
+
* `--no-parent`: Restricts crawling to only URLs below the initial directory
|
| 45 |
+
* `--convert-links`: Converts all links in downloaded documents to work locally
|
| 46 |
+
* `--adjust-extension`: Adds proper extensions to files (.html, .jpg, etc.) based on MIME types
|
| 47 |
+
* `--compression=auto`: Automatically handles compressed content (gzip, deflate)
|
| 48 |
+
* `--accept html,htm`: Only downloads files with these extensions
|
| 49 |
+
* `--directory-prefix=./ds`: Saves all downloaded files to the specified directory
|
| 50 |
+
|
| 51 |
+
[wget2](https://gitlab.com/gnuwget/wget2) is a better version of `wget` and supports HTTP2, parallel connections, and only updates modified sites. The syntax is (mostly) the same.
|
| 52 |
+
|
| 53 |
+
```
|
| 54 |
+
wget2 \
|
| 55 |
+
--recursive \
|
| 56 |
+
--level=3 \
|
| 57 |
+
--no-parent \
|
| 58 |
+
--convert-links \
|
| 59 |
+
--adjust-extension \
|
| 60 |
+
--compression=auto \
|
| 61 |
+
--accept html,htm \
|
| 62 |
+
--directory-prefix=./ds \
|
| 63 |
+
https://study.iitm.ac.in/ds/Copy to clipboardErrorCopied
|
| 64 |
+
```
|
| 65 |
+
|
| 66 |
+
There are popular free and open-source alternatives to Wget:
|
| 67 |
+
|
| 68 |
+
### [Wpull](#/crawling-cli?id=wpull)
|
| 69 |
+
|
| 70 |
+
[Wpull](https://github.com/ArchiveTeam/wpull) is a wget‐compatible Python crawler that supports on-disk resumption, WARC output, and PhantomJS integration.
|
| 71 |
+
|
| 72 |
+
```
|
| 73 |
+
uvx wpull \
|
| 74 |
+
--recursive \
|
| 75 |
+
--level=3 \
|
| 76 |
+
--no-parent \
|
| 77 |
+
--convert-links \
|
| 78 |
+
--adjust-extension \
|
| 79 |
+
--compression=auto \
|
| 80 |
+
--accept html,htm \
|
| 81 |
+
--directory-prefix=./ds \
|
| 82 |
+
https://study.iitm.ac.in/ds/Copy to clipboardErrorCopied
|
| 83 |
+
```
|
| 84 |
+
|
| 85 |
+
### [HTTrack](#/crawling-cli?id=httrack)
|
| 86 |
+
|
| 87 |
+
[HTTrack](https://www.httrack.com/html/fcguide.html) is dedicated website‐mirroring tool with rich filtering and link‐conversion options.
|
| 88 |
+
|
| 89 |
+
```
|
| 90 |
+
httrack "https://study.iitm.ac.in/ds/" \
|
| 91 |
+
-O "./ds" \
|
| 92 |
+
"+*.study.iitm.ac.in/ds/*" \
|
| 93 |
+
-r3Copy to clipboardErrorCopied
|
| 94 |
+
```
|
| 95 |
+
|
| 96 |
+
### [Robots.txt](#/crawling-cli?id=robotstxt)
|
| 97 |
+
|
| 98 |
+
`robots.txt` is a standard file found in a website’s root directory that specifies which parts of the site should not be accessed by web crawlers. It’s part of the Robots Exclusion Protocol, an ethical standard for web crawling.
|
| 99 |
+
|
| 100 |
+
**Why it’s important**:
|
| 101 |
+
|
| 102 |
+
* **Server load protection**: Prevents excessive traffic that could overload servers
|
| 103 |
+
* **Privacy protection**: Keeps sensitive or private content from being indexed
|
| 104 |
+
* **Legal compliance**: Respects website owners’ rights to control access to their content
|
| 105 |
+
* **Ethical web citizenship**: Shows respect for website administrators’ wishes
|
| 106 |
+
|
| 107 |
+
**How to override robots.txt restrictions**:
|
| 108 |
+
|
| 109 |
+
* **wget, wget2**: Use `-e robots=off`
|
| 110 |
+
* **httrack**: Use `-s0`
|
| 111 |
+
* **wpull**: Use `--no-robots`
|
| 112 |
+
|
| 113 |
+
**When to override robots.txt (use with discretion)**:
|
| 114 |
+
|
| 115 |
+
Only bypass `robots.txt` when:
|
| 116 |
+
|
| 117 |
+
* You have explicit permission from the website owner
|
| 118 |
+
* You’re crawling your own website
|
| 119 |
+
* The content is publicly accessible and your crawling won’t cause server issues
|
| 120 |
+
* You’re conducting authorized security testing
|
| 121 |
+
|
| 122 |
+
Remember that bypassing `robots.txt` without legitimate reason may:
|
| 123 |
+
|
| 124 |
+
* Violate terms of service
|
| 125 |
+
* Lead to IP banning
|
| 126 |
+
* Result in legal consequences in some jurisdictions
|
| 127 |
+
* Cause reputation damage to your organization
|
| 128 |
+
|
| 129 |
+
Always use the minimum necessary crawling speed and scope, and consider contacting website administrators for permission when in doubt.
|
| 130 |
+
|
| 131 |
+
[Previous
|
| 132 |
+
|
| 133 |
+
Scraping with Google Sheets](#/scraping-with-google-sheets)
|
| 134 |
+
|
| 135 |
+
[Next
|
| 136 |
+
|
| 137 |
+
BBC Weather API with Python](#/bbc-weather-api-with-python)
|
markdown_files/Data_Aggregation_in_Excel.md
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Data Aggregation in Excel"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/data-aggregation-in-excel?id=data-aggregation-in-excel"
|
| 4 |
+
downloaded_at: "2025-06-08T23:26:38.121838"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Data Aggregation in Excel](#/data-aggregation-in-excel?id=data-aggregation-in-excel)
|
| 8 |
+
-------------------------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
[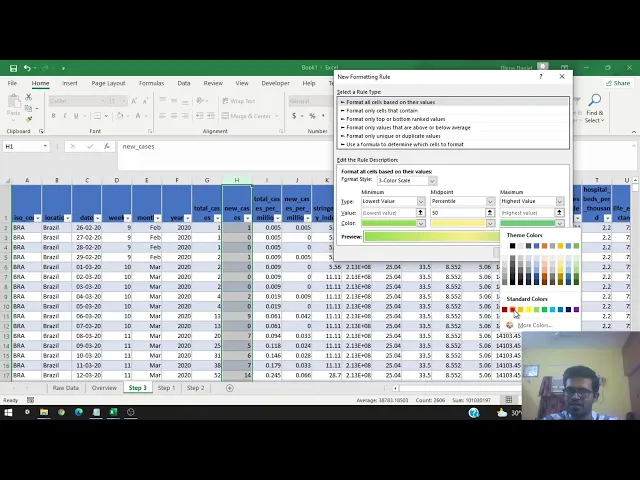](https://youtu.be/NkpT0dDU8Y4)
|
| 11 |
+
|
| 12 |
+
You’ll learn data aggregation and visualization techniques in Excel, covering:
|
| 13 |
+
|
| 14 |
+
* **Data Cleanup**: Remove empty columns and rows with missing values.
|
| 15 |
+
* **Creating Excel Tables**: Convert raw data into tables for easier manipulation and formula application.
|
| 16 |
+
* **Date Manipulation**: Extract week, month, and year from date columns using Excel functions (WEEKNUM, TEXT).
|
| 17 |
+
* **Color Scales**: Apply color scales to visualize clusters and trends in data over time.
|
| 18 |
+
* **Pivot Tables**: Create pivot tables to aggregate data by location and date, summarizing values weekly and monthly.
|
| 19 |
+
* **Sparklines**: Use sparklines to visualize trends within pivot tables, making data patterns more apparent.
|
| 20 |
+
* **Data Bars**: Implement data bars for graphical illustrations of numerical columns, showing trends and waves.
|
| 21 |
+
|
| 22 |
+
Here are links used in the video:
|
| 23 |
+
|
| 24 |
+
* [COVID-19 data Excel file - raw data](https://docs.google.com/spreadsheets/d/14HLgSmME95q--6lcBv9pUstqHL183wTd/view)
|
| 25 |
+
|
| 26 |
+
[Previous
|
| 27 |
+
|
| 28 |
+
Splitting Text in Excel](#/splitting-text-in-excel)
|
| 29 |
+
|
| 30 |
+
[Next
|
| 31 |
+
|
| 32 |
+
Data Preparation in the Shell](#/data-preparation-in-the-shell)
|
markdown_files/Data_Analysis_with_DuckDB.md
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Data Analysis with DuckDB"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/data-analysis-with-duckdb?id=data-analysis-with-duckdb"
|
| 4 |
+
downloaded_at: "2025-06-08T23:26:27.065997"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Data Analysis with DuckDB](#/data-analysis-with-duckdb?id=data-analysis-with-duckdb)
|
| 8 |
+
-------------------------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
[](https://youtu.be/4U0GqYrET5s)
|
| 11 |
+
|
| 12 |
+
You’ll learn how to perform data analysis using DuckDB and Pandas, covering:
|
| 13 |
+
|
| 14 |
+
* **Parquet for Data Storage**: Understand why Parquet is a faster, more compact, and better-typed storage format compared to CSV, JSON, and SQLite.
|
| 15 |
+
* **DuckDB Setup**: Learn how to install and set up DuckDB, along with integrating it into a Jupyter notebook environment.
|
| 16 |
+
* **File Format Comparisons**: Compare file formats by speed and size, observing the performance difference between saving and loading data in CSV, JSON, SQLite, and Parquet.
|
| 17 |
+
* **Faster Queries with DuckDB**: Learn how DuckDB uses parallel processing, columnar storage, and on-disk operations to outperform Pandas in speed and memory efficiency.
|
| 18 |
+
* **SQL Query Execution in DuckDB**: Run SQL queries directly on Parquet files and Pandas DataFrames to compute metrics such as the number of unique flight routes delayed by certain time intervals.
|
| 19 |
+
* **Memory Efficiency**: Understand how DuckDB performs analytics without loading entire datasets into memory, making it highly efficient for large-scale data analysis.
|
| 20 |
+
* **Mixing DuckDB and Pandas**: Learn to interleave DuckDB and Pandas operations, leveraging the strengths of both tools to perform complex queries like correlations and aggregations.
|
| 21 |
+
* **Ranking and Filtering Data**: Use SQL and Pandas to rank arrival delays by distance and extract key insights, such as the earliest flight arrival for each route.
|
| 22 |
+
* **Joining Data**: Create a cost analysis by joining datasets and calculating total costs of flight delays, demonstrating DuckDB’s speed in joining and aggregating large datasets.
|
| 23 |
+
|
| 24 |
+
Here are the links used in the video:
|
| 25 |
+
|
| 26 |
+
* [Data analysis with DuckDB - Notebook](https://drive.google.com/file/d/1Y9XSs-LeSz-ZmnQj4OGP-Q4yDkPJrmsZ/view)
|
| 27 |
+
* [Parquet file format](https://parquet.apache.org/) - a fast columnar storage format that’s becoming a de facto standard for big data
|
| 28 |
+
* [DuckDB](https://duckdb.org/) - a fast in-memory database that’s very good with large-scale analysis
|
| 29 |
+
* [Plotly Datasets](https://github.com/plotly/datasets/) - a collection of sample datasets for analysis. This includes the [Kaggle Flights Dataset](https://www.kaggle.com/datasets/usdot/flight-delays) that the notebook downloads as [2015\_flights.parquet](https://github.com/plotly/datasets/raw/master/2015_flights.parquet)
|
| 30 |
+
|
| 31 |
+
[Previous
|
| 32 |
+
|
| 33 |
+
Data Analysis with Datasette](#/data-analysis-with-datasette)
|
| 34 |
+
|
| 35 |
+
[Next
|
| 36 |
+
|
| 37 |
+
Data Analysis with ChatGPT](#/data-analysis-with-chatgpt)
|
markdown_files/Data_Analysis_with_Python.md
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Data Analysis with Python"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/data-analysis-with-python?id=data-analysis-with-python"
|
| 4 |
+
downloaded_at: "2025-06-08T23:24:24.926726"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Data Analysis with Python](#/data-analysis-with-python?id=data-analysis-with-python)
|
| 8 |
+
-------------------------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
[](https://youtu.be/ZPfZH14FK90)
|
| 11 |
+
|
| 12 |
+
You’ll learn practical data analysis techniques in Python using Pandas, covering:
|
| 13 |
+
|
| 14 |
+
* **Reading Parquet Files**: Utilize Pandas to read Parquet file formats for efficient data handling.
|
| 15 |
+
* **Dataframe Inspection**: Methods to preview and understand the structure of a dataset.
|
| 16 |
+
* **Pivot Tables**: Creating and interpreting pivot tables to summarize data.
|
| 17 |
+
* **Percentage Calculations**: Normalize pivot table values to percentages for better insights.
|
| 18 |
+
* **Correlation Analysis**: Calculate and interpret correlation between variables, including significance testing.
|
| 19 |
+
* **Statistical Significance**: Use statistical tests to determine the significance of observed correlations.
|
| 20 |
+
* **Datetime Handling**: Extract and manipulate date and time information from datetime columns.
|
| 21 |
+
* **Data Visualization**: Generate and customize heat maps to visualize data patterns effectively.
|
| 22 |
+
* **Leveraging AI**: Use ChatGPT to generate and refine analytical code, enhancing productivity and accuracy.
|
| 23 |
+
|
| 24 |
+
Here are the links used in the video:
|
| 25 |
+
|
| 26 |
+
* [Data analysis with Python - Notebook](https://colab.research.google.com/drive/1wEUEeF_e2SSmS9uf2-3fZJQ2kEFRnxah)
|
| 27 |
+
* [Card transactions dataset (Parquet)](https://drive.google.com/file/u/3/d/1XGvuFjoTwlybkw0cc9u34horMF9vMhrB/view)
|
| 28 |
+
* [10 minutes to Pandas](https://pandas.pydata.org/pandas-docs/stable/user_guide/10min.html)
|
| 29 |
+
* [Python Pandas tutorials](https://www.youtube.com/playlist?list=PL-osiE80TeTsWmV9i9c58mdDCSskIFdDS)
|
| 30 |
+
|
| 31 |
+
[Previous
|
| 32 |
+
|
| 33 |
+
Outlier Detection with Excel](#/outlier-detection-with-excel)
|
| 34 |
+
|
| 35 |
+
[Next
|
| 36 |
+
|
| 37 |
+
Data Analysis with SQL](#/data-analysis-with-sql)
|
markdown_files/Data_Analysis_with_SQL.md
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Data Analysis with SQL"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/data-analysis-with-sql?id=data-analysis-with-sql"
|
| 4 |
+
downloaded_at: "2025-06-08T23:22:33.461136"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Data Analysis with SQL](#/data-analysis-with-sql?id=data-analysis-with-sql)
|
| 8 |
+
----------------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
[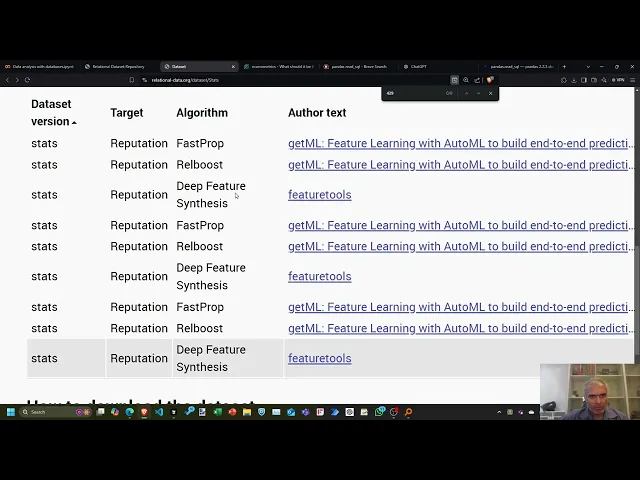](https://youtu.be/Xn3QkYrThbI)
|
| 11 |
+
|
| 12 |
+
You’ll learn how to perform data analysis using SQL (via Python), covering:
|
| 13 |
+
|
| 14 |
+
* **Database Connection**: How to connect to a MySQL database using SQLAlchemy and Pandas.
|
| 15 |
+
* **SQL Queries**: Execute SQL queries directly from a Python environment to retrieve and analyze data.
|
| 16 |
+
* **Counting Rows**: Use SQL to count the number of rows in a table.
|
| 17 |
+
* **User Activity Analysis**: Query and identify top users by post count.
|
| 18 |
+
* **Post Concentration**: Determine if a small percentage of users contribute the majority of posts using SQL aggregation.
|
| 19 |
+
* **Correlation Calculation**: Calculate the Pearson correlation coefficient between user attributes such as age and reputation.
|
| 20 |
+
* **Regression Analysis**: Compute the regression slope to understand the relationship between views and reputation.
|
| 21 |
+
* **Handling Large Data**: Perform calculations on large datasets by fetching aggregated values from the database rather than entire datasets.
|
| 22 |
+
* **Statistical Analysis in SQL**: Use SQL as a tool for statistical analysis, demonstrating its power beyond simple data retrieval.
|
| 23 |
+
* **Leveraging AI**: Use ChatGPT to generate SQL queries and Python code, enhancing productivity and accuracy.
|
| 24 |
+
|
| 25 |
+
Here are the links used in the video:
|
| 26 |
+
|
| 27 |
+
* [Data analysis with databases - Notebook](https://colab.research.google.com/drive/1j_5AsWdf0SwVHVgfbEAcg7vYguKUN41o)
|
| 28 |
+
* [SQLZoo](https://www.sqlzoo.net/wiki/SQL_Tutorial) has simple interactive tutorials to learn SQL
|
| 29 |
+
* [Stats database](https://relational-data.org/dataset/Stats) that has an anonymized dump of [stats.stackexchange.com](https://stats.stackexchange.com/)
|
| 30 |
+
* [Pandas `read_sql`](https://pandas.pydata.org/docs/reference/api/pandas.read_sql.html)
|
| 31 |
+
* [SQLAlchemy docs](https://docs.sqlalchemy.org/)
|
| 32 |
+
|
| 33 |
+
[Previous
|
| 34 |
+
|
| 35 |
+
Data Analysis with Python](#/data-analysis-with-python)
|
| 36 |
+
|
| 37 |
+
[Next
|
| 38 |
+
|
| 39 |
+
Data Analysis with Datasette](#/data-analysis-with-datasette)
|
markdown_files/Data_Cleansing_in_Excel.md
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Data Cleansing in Excel"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/data-cleansing-in-excel?id=data-cleansing-in-excel"
|
| 4 |
+
downloaded_at: "2025-06-08T23:27:03.007571"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Data Cleansing in Excel](#/data-cleansing-in-excel?id=data-cleansing-in-excel)
|
| 8 |
+
-------------------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
[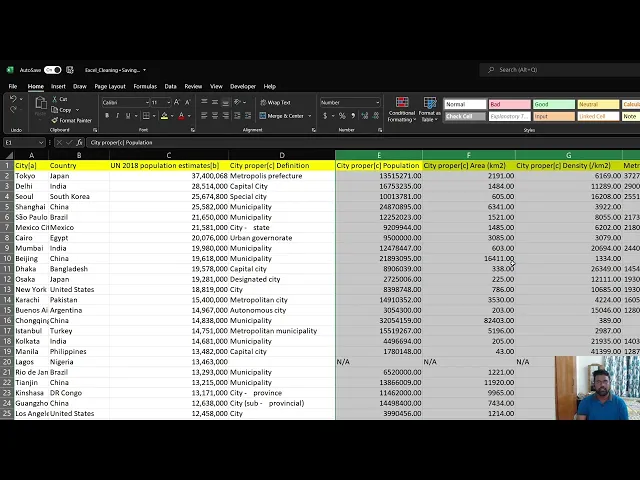](https://youtu.be/7du7xkqeu4s)
|
| 11 |
+
|
| 12 |
+
You’ll learn basic but essential data cleaning techniques in Excel, covering:
|
| 13 |
+
|
| 14 |
+
* **Find and Replace**: Use Ctrl+H to replace or remove specific terms (e.g., removing “[more]” from country names).
|
| 15 |
+
* **Changing Data Formats**: Convert columns from general to numerical format.
|
| 16 |
+
* **Removing Extra Spaces**: Use the TRIM function to clean up unnecessary spaces in text.
|
| 17 |
+
* **Identifying and Removing Blank Cells**: Highlight and delete entire rows with blank cells using the “Go To Special” function.
|
| 18 |
+
* **Removing Duplicates**: Use the “Remove Duplicates” feature to eliminate duplicate entries, demonstrated with country names.
|
| 19 |
+
|
| 20 |
+
Here are links used in the video:
|
| 21 |
+
|
| 22 |
+
* [List of Largest Cities Excel file](https://docs.google.com/spreadsheets/d/1jl8tHGoxmIba4J78aJVfT9jtZv7lfCbV/view)
|
| 23 |
+
|
| 24 |
+
[Previous
|
| 25 |
+
|
| 26 |
+
5. Data Preparation](#/data-preparation)
|
| 27 |
+
|
| 28 |
+
[Next
|
| 29 |
+
|
| 30 |
+
Data Transformation in Excel](#/data-transformation-in-excel)
|
markdown_files/Data_Preparation_in_the_Editor.md
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Data Preparation in the Editor"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/data-preparation-in-the-editor?id=data-preparation-in-the-editor"
|
| 4 |
+
downloaded_at: "2025-06-08T23:22:43.469063"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Data Preparation in the Editor](#/data-preparation-in-the-editor?id=data-preparation-in-the-editor)
|
| 8 |
+
----------------------------------------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
[](https://youtu.be/99lYu43L9uM)
|
| 11 |
+
|
| 12 |
+
You’ll learn how to use a text editor [Visual Studio Code](https://code.visualstudio.com/) to process and clean data, covering:
|
| 13 |
+
|
| 14 |
+
* **Format** JSON files
|
| 15 |
+
* **Find all** and multiple cursors to extract specific fields
|
| 16 |
+
* **Sort** lines
|
| 17 |
+
* **Delete duplicate** lines
|
| 18 |
+
* **Replace** text with multiple cursors
|
| 19 |
+
|
| 20 |
+
Here are the links used in the video:
|
| 21 |
+
|
| 22 |
+
* [City-wise product sales JSON](https://drive.google.com/file/d/1VEnKChf4i04iKsQfw0MwoJlfkOBGQ65B/view?usp=drive_link)
|
| 23 |
+
|
| 24 |
+
[Previous
|
| 25 |
+
|
| 26 |
+
Data Preparation in the Shell](#/data-preparation-in-the-shell)
|
| 27 |
+
|
| 28 |
+
[Next
|
| 29 |
+
|
| 30 |
+
Cleaning Data with OpenRefine](#/cleaning-data-with-openrefine)
|
markdown_files/Data_Preparation_in_the_Shell.md
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Data Preparation in the Shell"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/data-preparation-in-the-shell?id=data-preparation-in-the-shell"
|
| 4 |
+
downloaded_at: "2025-06-08T23:26:41.381829"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Data Preparation in the Shell](#/data-preparation-in-the-shell?id=data-preparation-in-the-shell)
|
| 8 |
+
-------------------------------------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
[](https://youtu.be/XEdy4WK70vU)
|
| 11 |
+
|
| 12 |
+
You’ll learn how to use UNIX tools to process and clean data, covering:
|
| 13 |
+
|
| 14 |
+
* `curl` (or `wget`) to fetch data from websites.
|
| 15 |
+
* `gzip` (or `xz`) to compress and decompress files.
|
| 16 |
+
* `wc` to count lines, words, and characters in text.
|
| 17 |
+
* `head` and `tail` to get the start and end of files.
|
| 18 |
+
* `cut` to extract specific columns from text.
|
| 19 |
+
* `uniq` to de-duplicate lines.
|
| 20 |
+
* `sort` to sort lines.
|
| 21 |
+
* `grep` to filter lines containing specific text.
|
| 22 |
+
* `sed` to search and replace text.
|
| 23 |
+
* `awk` for more complex text processing.
|
| 24 |
+
|
| 25 |
+
Here are the links used in the video:
|
| 26 |
+
|
| 27 |
+
* [Data preparation in the shell - Notebook](https://colab.research.google.com/drive/1KSFkQDK0v__XWaAaHKeQuIAwYV0dkTe8)
|
| 28 |
+
* [Data Science at the Command Line](https://jeroenjanssens.com/dsatcl/)
|
| 29 |
+
|
| 30 |
+
[Previous
|
| 31 |
+
|
| 32 |
+
Data Aggregation in Excel](#/data-aggregation-in-excel)
|
| 33 |
+
|
| 34 |
+
[Next
|
| 35 |
+
|
| 36 |
+
Data Preparation in the Editor](#/data-preparation-in-the-editor)
|
markdown_files/Data_Storytelling.md
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Data Storytelling"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/data-storytelling?id=data-storytelling"
|
| 4 |
+
downloaded_at: "2025-06-08T23:21:12.671499"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Data Storytelling](#/data-storytelling?id=data-storytelling)
|
| 8 |
+
=============================================================
|
| 9 |
+
|
| 10 |
+
[](https://youtu.be/aF93i6zVVQg)
|
| 11 |
+
|
| 12 |
+
[Previous
|
| 13 |
+
|
| 14 |
+
RAWgraphs](#/rawgraphs)
|
| 15 |
+
|
| 16 |
+
[Next
|
| 17 |
+
|
| 18 |
+
Narratives with LLMs](#/narratives-with-llms)
|
markdown_files/Data_Transformation_in_Excel.md
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Data Transformation in Excel"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/data-transformation-in-excel?id=data-transformation-in-excel"
|
| 4 |
+
downloaded_at: "2025-06-08T23:26:40.285938"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Data Transformation in Excel](#/data-transformation-in-excel?id=data-transformation-in-excel)
|
| 8 |
+
----------------------------------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
[](https://youtu.be/gR2IY5Naja0)
|
| 11 |
+
|
| 12 |
+
You’ll learn data transformation techniques in Excel, covering:
|
| 13 |
+
|
| 14 |
+
* **Calculating Ratios**: Compute metro area to city area and metro population to city population ratios.
|
| 15 |
+
* **Using Pivot Tables**: Create pivot tables to aggregate data and identify outliers.
|
| 16 |
+
* **Filtering Data**: Apply filters in pivot tables to analyze specific subsets of data.
|
| 17 |
+
* **Counting Data Occurrences**: Use pivot tables to count the frequency of specific entries.
|
| 18 |
+
* **Creating Charts**: Generate charts from pivot table data to visualize distributions and outliers.
|
| 19 |
+
|
| 20 |
+
Here are links used in the video:
|
| 21 |
+
|
| 22 |
+
* [List of Largest Cities Excel file](https://docs.google.com/spreadsheets/d/1jl8tHGoxmIba4J78aJVfT9jtZv7lfCbV/view)
|
| 23 |
+
|
| 24 |
+
[Previous
|
| 25 |
+
|
| 26 |
+
Data Cleansing in Excel](#/data-cleansing-in-excel)
|
| 27 |
+
|
| 28 |
+
[Next
|
| 29 |
+
|
| 30 |
+
Splitting Text in Excel](#/splitting-text-in-excel)
|
markdown_files/Data_Transformation_with_dbt.md
ADDED
|
@@ -0,0 +1,64 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Data Transformation with dbt"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/dbt?id=data-transformation-with-dbt"
|
| 4 |
+
downloaded_at: "2025-06-08T23:26:28.166999"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Data Transformation with dbt](#/dbt?id=data-transformation-with-dbt)
|
| 8 |
+
---------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
[](https://youtu.be/5rNquRnNb4E)
|
| 11 |
+
|
| 12 |
+
You’ll learn how to transform data using dbt (data build tool), covering:
|
| 13 |
+
|
| 14 |
+
* **dbt Fundamentals**: Understand what dbt is and how it brings software engineering practices to data transformation
|
| 15 |
+
* **Project Setup**: Learn how to initialize a dbt project, configure your warehouse connection, and structure your models
|
| 16 |
+
* **Models and Materialization**: Create your first dbt models and understand different materialization strategies (view, table, incremental)
|
| 17 |
+
* **Testing and Documentation**: Implement data quality tests and auto-generate documentation for your data models
|
| 18 |
+
* **Jinja Templating**: Use Jinja for dynamic SQL generation, making your transformations more maintainable and reusable
|
| 19 |
+
* **References and Dependencies**: Learn how to reference other models and manage model dependencies
|
| 20 |
+
* **Sources and Seeds**: Configure source data connections and manage static reference data
|
| 21 |
+
* **Macros and Packages**: Create reusable macros and leverage community packages to extend functionality
|
| 22 |
+
* **Incremental Models**: Optimize performance by only processing new or changed data
|
| 23 |
+
* **Deployment and Orchestration**: Set up dbt Cloud or integrate with Airflow for production deployment
|
| 24 |
+
|
| 25 |
+
Here’s a minimal dbt model example, `models/staging/stg_customers.sql`:
|
| 26 |
+
|
| 27 |
+
```
|
| 28 |
+
with source as (
|
| 29 |
+
select * from {{ source('raw', 'customers') }}
|
| 30 |
+
),
|
| 31 |
+
|
| 32 |
+
renamed as (
|
| 33 |
+
select
|
| 34 |
+
id as customer_id,
|
| 35 |
+
first_name,
|
| 36 |
+
last_name,
|
| 37 |
+
email,
|
| 38 |
+
created_at
|
| 39 |
+
from source
|
| 40 |
+
)
|
| 41 |
+
|
| 42 |
+
select * from renamedCopy to clipboardErrorCopied
|
| 43 |
+
```
|
| 44 |
+
|
| 45 |
+
Tools and Resources:
|
| 46 |
+
|
| 47 |
+
* [dbt Core](https://github.com/dbt-labs/dbt-core) - The open-source transformation tool
|
| 48 |
+
* [dbt Cloud](https://www.getdbt.com/product/dbt-cloud) - Hosted platform for running dbt
|
| 49 |
+
* [dbt Packages](https://hub.getdbt.com/) - Reusable modules from the community
|
| 50 |
+
* [dbt Documentation](https://docs.getdbt.com/) - Comprehensive guides and references
|
| 51 |
+
* [Jaffle Shop](https://github.com/dbt-labs/jaffle_shop) - Example dbt project for learning
|
| 52 |
+
* [dbt Slack Community](https://www.getdbt.com/community/) - Active community for support and discussions
|
| 53 |
+
|
| 54 |
+
Watch this dbt Fundamentals Course (90 min):
|
| 55 |
+
|
| 56 |
+
[](https://youtu.be/5rNquRnNb4E)
|
| 57 |
+
|
| 58 |
+
[Previous
|
| 59 |
+
|
| 60 |
+
Parsing JSON](#/parsing-json)
|
| 61 |
+
|
| 62 |
+
[Next
|
| 63 |
+
|
| 64 |
+
Transforming Images](#/transforming-images)
|
markdown_files/Data_Visualization_with_Seaborn.md
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Data Visualization with Seaborn"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/data-visualization-with-seaborn?id=data-visualization-with-seaborn"
|
| 4 |
+
downloaded_at: "2025-06-08T23:24:55.808928"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Data Visualization with Seaborn](#/data-visualization-with-seaborn?id=data-visualization-with-seaborn)
|
| 8 |
+
-------------------------------------------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
[Seaborn](https://seaborn.pydata.org/) is a data visualization library for Python. It’s based on Matplotlib but a bit easier to use, and a bit prettier.
|
| 11 |
+
|
| 12 |
+
[](https://youtu.be/6GUZXDef2U0)
|
| 13 |
+
|
| 14 |
+
[Previous
|
| 15 |
+
|
| 16 |
+
Visualizing Charts with Excel](#/visualizing-charts-with-excel)
|
| 17 |
+
|
| 18 |
+
[Next
|
| 19 |
+
|
| 20 |
+
Data Visualization with ChatGPT](#/data-visualization-with-chatgpt)
|
markdown_files/Database__SQLite.md
ADDED
|
@@ -0,0 +1,148 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Database: SQLite"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/sqlite?id=database-sqlite"
|
| 4 |
+
downloaded_at: "2025-06-08T23:26:00.500923"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Database: SQLite](#/sqlite?id=database-sqlite)
|
| 8 |
+
-----------------------------------------------
|
| 9 |
+
|
| 10 |
+
Relational databases are used to store data in a structured way. You’ll often access databases created by others for analysis.
|
| 11 |
+
|
| 12 |
+
PostgreSQL, MySQL, MS SQL, Oracle, etc. are popular databases. But the most installed database is [SQLite](https://www.sqlite.org/index.html). It’s embedded into many devices and apps (e.g. your phone, browser, etc.). It’s lightweight but very scalable and powerful.
|
| 13 |
+
|
| 14 |
+
Watch these introductory videos to understand SQLite and how it’s used in Python (34 min):
|
| 15 |
+
|
| 16 |
+
[](https://youtu.be/8Xyn8R9eKB8)
|
| 17 |
+
|
| 18 |
+
[](https://youtu.be/Ohj-CqALrwk)
|
| 19 |
+
|
| 20 |
+
There are many non-relational databases (NoSQL) like [ElasticSearch](https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html), [MongoDB](https://www.mongodb.com/docs/manual/), [Redis](https://redis.io/docs/latest/), etc. that you should know about and we may cover later.
|
| 21 |
+
|
| 22 |
+
Core Concepts:
|
| 23 |
+
|
| 24 |
+
```
|
| 25 |
+
-- Create a table
|
| 26 |
+
CREATE TABLE users (
|
| 27 |
+
id INTEGER PRIMARY KEY,
|
| 28 |
+
name TEXT NOT NULL,
|
| 29 |
+
email TEXT UNIQUE,
|
| 30 |
+
created_at DATETIME DEFAULT CURRENT_TIMESTAMP
|
| 31 |
+
);
|
| 32 |
+
|
| 33 |
+
-- Insert data
|
| 34 |
+
INSERT INTO users (name, email) VALUES
|
| 35 |
+
('Alice', 'alice@example.com'),
|
| 36 |
+
('Bob', 'bob@example.com');
|
| 37 |
+
|
| 38 |
+
-- Query data
|
| 39 |
+
SELECT name, COUNT(*) as count
|
| 40 |
+
FROM users
|
| 41 |
+
GROUP BY name
|
| 42 |
+
HAVING count > 1;
|
| 43 |
+
|
| 44 |
+
-- Join tables
|
| 45 |
+
SELECT u.name, o.product
|
| 46 |
+
FROM users u
|
| 47 |
+
LEFT JOIN orders o ON u.id = o.user_id
|
| 48 |
+
WHERE o.status = 'pending';Copy to clipboardErrorCopied
|
| 49 |
+
```
|
| 50 |
+
|
| 51 |
+
Python Integration:
|
| 52 |
+
|
| 53 |
+
```
|
| 54 |
+
import sqlite3
|
| 55 |
+
from pathlib import Path
|
| 56 |
+
import pandas as pd
|
| 57 |
+
|
| 58 |
+
async def query_database(db_path: Path, query: str) -> pd.DataFrame:
|
| 59 |
+
"""Execute SQL query and return results as DataFrame.
|
| 60 |
+
|
| 61 |
+
Args:
|
| 62 |
+
db_path: Path to SQLite database
|
| 63 |
+
query: SQL query to execute
|
| 64 |
+
|
| 65 |
+
Returns:
|
| 66 |
+
DataFrame with query results
|
| 67 |
+
"""
|
| 68 |
+
try:
|
| 69 |
+
conn = sqlite3.connect(db_path)
|
| 70 |
+
return pd.read_sql_query(query, conn)
|
| 71 |
+
finally:
|
| 72 |
+
conn.close()
|
| 73 |
+
|
| 74 |
+
# Example usage
|
| 75 |
+
db = Path('data.db')
|
| 76 |
+
df = await query_database(db, '''
|
| 77 |
+
SELECT date, COUNT(*) as count
|
| 78 |
+
FROM events
|
| 79 |
+
GROUP BY date
|
| 80 |
+
''')Copy to clipboardErrorCopied
|
| 81 |
+
```
|
| 82 |
+
|
| 83 |
+
Common Operations:
|
| 84 |
+
|
| 85 |
+
1. **Database Management**
|
| 86 |
+
|
| 87 |
+
```
|
| 88 |
+
-- Backup database
|
| 89 |
+
.backup 'backup.db'
|
| 90 |
+
|
| 91 |
+
-- Import CSV
|
| 92 |
+
.mode csv
|
| 93 |
+
.import data.csv table_name
|
| 94 |
+
|
| 95 |
+
-- Export results
|
| 96 |
+
.headers on
|
| 97 |
+
.mode csv
|
| 98 |
+
.output results.csv
|
| 99 |
+
SELECT * FROM table;Copy to clipboardErrorCopied
|
| 100 |
+
```
|
| 101 |
+
2. **Performance Optimization**
|
| 102 |
+
|
| 103 |
+
```
|
| 104 |
+
-- Create index
|
| 105 |
+
CREATE INDEX idx_user_email ON users(email);
|
| 106 |
+
|
| 107 |
+
-- Analyze query
|
| 108 |
+
EXPLAIN QUERY PLAN
|
| 109 |
+
SELECT * FROM users WHERE email LIKE '%@example.com';
|
| 110 |
+
|
| 111 |
+
-- Show indexes
|
| 112 |
+
SELECT * FROM sqlite_master WHERE type='index';Copy to clipboardErrorCopied
|
| 113 |
+
```
|
| 114 |
+
3. **Data Analysis**
|
| 115 |
+
|
| 116 |
+
```
|
| 117 |
+
-- Time series aggregation
|
| 118 |
+
SELECT
|
| 119 |
+
date(timestamp),
|
| 120 |
+
COUNT(*) as events,
|
| 121 |
+
AVG(duration) as avg_duration
|
| 122 |
+
FROM events
|
| 123 |
+
GROUP BY date(timestamp);
|
| 124 |
+
|
| 125 |
+
-- Window functions
|
| 126 |
+
SELECT *,
|
| 127 |
+
AVG(amount) OVER (
|
| 128 |
+
PARTITION BY user_id
|
| 129 |
+
ORDER BY date
|
| 130 |
+
ROWS BETWEEN 3 PRECEDING AND CURRENT ROW
|
| 131 |
+
) as moving_avg
|
| 132 |
+
FROM transactions;Copy to clipboardErrorCopied
|
| 133 |
+
```
|
| 134 |
+
|
| 135 |
+
Tools to work with SQLite:
|
| 136 |
+
|
| 137 |
+
* [SQLiteStudio](https://sqlitestudio.pl/): Lightweight GUI
|
| 138 |
+
* [DBeaver](https://dbeaver.io/): Full-featured GUI
|
| 139 |
+
* [sqlite-utils](https://sqlite-utils.datasette.io/): CLI tool
|
| 140 |
+
* [Datasette](https://datasette.io/): Web interface
|
| 141 |
+
|
| 142 |
+
[Previous
|
| 143 |
+
|
| 144 |
+
Spreadsheet: Excel, Google Sheets](#/spreadsheets)
|
| 145 |
+
|
| 146 |
+
[Next
|
| 147 |
+
|
| 148 |
+
Version Control: Git, GitHub](#/git)
|
markdown_files/DevContainers__GitHub_Codespaces.md
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "DevContainers: GitHub Codespaces"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/github-codespaces?id=features-to-explore"
|
| 4 |
+
downloaded_at: "2025-06-08T23:27:28.688679"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[IDE: GitHub Codespaces](#/github-codespaces?id=ide-github-codespaces)
|
| 8 |
+
----------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
[GitHub Codespaces](https://github.com/features/codespaces) is a cloud-hosted development environment built right into GitHub that gets you coding faster with pre-configured containers, adjustable compute power, and seamless integration with workflows like Actions and Copilot.
|
| 11 |
+
|
| 12 |
+
**Why Codespaces helps**
|
| 13 |
+
|
| 14 |
+
* **Reproducible onboarding**: Say goodbye to “works on my machine” woes—everyone uses the same setup for assignments or demos.
|
| 15 |
+
* **Anywhere access**: Jump back into your project from a laptop, tablet, or phone without having to reinstall anything.
|
| 16 |
+
* **Rapid experimentation & debugging**: Spin up short-lived environments on any branch, commit, or PR to isolate bugs or test features, or keep longer-lived codespaces for big projects.
|
| 17 |
+
|
| 18 |
+
[](https://www.youtube.com/watch?v=-tQ2nxjqP6o)
|
| 19 |
+
|
| 20 |
+
### [Quick Setup](#/github-codespaces?id=quick-setup)
|
| 21 |
+
|
| 22 |
+
1. [**From the GitHub UI**](https://github.com/codespaces)
|
| 23 |
+
|
| 24 |
+
* Go to your repo and click **Code → Codespaces → New codespace**.
|
| 25 |
+
* Pick the branch and machine specs (2–32 cores, 8–64 GB RAM), then click **Create codespace**.
|
| 26 |
+
2. [**In Visual Studio Code**](https://code.visualstudio.com/docs/remote/codespaces)
|
| 27 |
+
|
| 28 |
+
* Press `Ctrl+Shift+P` (or `Cmd+Shift+P` on Mac), choose **Codespaces: Create New Codespace**, and follow the prompts.
|
| 29 |
+
3. [**Via GitHub CLI**](https://docs.github.com/en/codespaces/developing-in-a-codespace/using-github-codespaces-with-github-cli)
|
| 30 |
+
|
| 31 |
+
```
|
| 32 |
+
gh auth login
|
| 33 |
+
gh codespace create --repo OWNER/REPO
|
| 34 |
+
gh codespace list # List all codespaces
|
| 35 |
+
gh codespace code # opens in your local VS Code
|
| 36 |
+
gh codespace ssh # SSH into the codepsaceCopy to clipboardErrorCopied
|
| 37 |
+
```
|
| 38 |
+
|
| 39 |
+
### [Features To Explore](#/github-codespaces?id=features-to-explore)
|
| 40 |
+
|
| 41 |
+
* **Dev Containers**: Set up your environment the same way every time using a `devcontainer.json` or your own Dockerfile. [Introduction to dev containers](https://docs.github.com/en/codespaces/setting-up-your-project-for-codespaces/adding-a-dev-container-configuration/introduction-to-dev-containers)
|
| 42 |
+
* **Prebuilds**: Build bigger or more complex repos in advance so codespaces start up in a flash. [About prebuilds](https://docs.github.com/en/codespaces/prebuilding-your-codespaces/about-github-codespaces-prebuilds)
|
| 43 |
+
* **Port Forwarding**: Let Codespaces spot and forward the ports your web apps use automatically. [Forward ports in Codespaces](https://docs.github.com/en/codespaces/developing-in-a-codespace/forwarding-ports-in-your-codespace)
|
| 44 |
+
* **Secrets & Variables**: Keep your environment variables safe in the Codespaces settings for your repo. [Manage Codespaces secrets](https://docs.github.com/en/enterprise-cloud@latest/codespaces/managing-codespaces-for-your-organization/managing-development-environment-secrets-for-your-repository-or-organization)
|
| 45 |
+
* **Dotfiles Integration**: Bring in your dotfiles repo to customize shell settings, aliases, and tools in every codespace. [Personalizing your codespaces](https://docs.github.com/en/codespaces/setting-your-user-preferences/personalizing-github-codespaces-for-your-account)
|
| 46 |
+
* **Machine Types & Cost Control**: Pick from VMs with 2 to 32 cores and track your usage in the billing dashboard. [Managing Codespaces costs](https://docs.github.com/en/billing/managing-billing-for-github-codespaces/about-billing-for-github-codespaces)
|
| 47 |
+
* **VS Code & CLI Integration**: Flip between browser VS Code and your desktop editor, and script everything with the CLI. [VS Code Remote: Codespaces](https://code.visualstudio.com/docs/remote/codespaces)
|
| 48 |
+
* **GitHub Actions**: Power up prebuilds and your CI/CD right inside codespaces using Actions workflows. [Prebuilding your codespaces](https://docs.github.com/en/codespaces/prebuilding-your-codespaces)
|
| 49 |
+
* **Copilot in Codespaces**: Let Copilot help you write code with in-editor AI suggestions. [Copilot in Codespaces](https://docs.github.com/en/codespaces/reference/using-github-copilot-in-github-codespaces)
|
| 50 |
+
|
| 51 |
+
[Previous
|
| 52 |
+
|
| 53 |
+
Containers: Docker, Podman](#/docker)
|
| 54 |
+
|
| 55 |
+
[Next
|
| 56 |
+
|
| 57 |
+
Tunneling: ngrok](#/ngrok)
|
markdown_files/Editor__VS_Code.md
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Editor: VS Code"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/vscode?id=editor-vs-code"
|
| 4 |
+
downloaded_at: "2025-06-08T23:26:42.473263"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Editor: VS Code](#/vscode?id=editor-vs-code)
|
| 8 |
+
---------------------------------------------
|
| 9 |
+
|
| 10 |
+
Your editor is the most important tool in your arsenal. That’s where you’ll spend most of your time. Make sure you’re comfortable with it.
|
| 11 |
+
|
| 12 |
+
[**Visual Studio Code**](https://code.visualstudio.com/) is, *by far*, the most popular code editor today. According to the [2024 StackOverflow Survey](https://survey.stackoverflow.co/2024/technology/#1-integrated-development-environment) almost 75% of developers use it. We recommend you learn it well. Even if you use another editor, you’ll be working with others who use it, and it’s a good idea to have some exposure.
|
| 13 |
+
|
| 14 |
+
Watch these introductory videos (35 min) from the [Visual Studio Docs](https://code.visualstudio.com/docs) to get started:
|
| 15 |
+
|
| 16 |
+
* [Getting Started](https://code.visualstudio.com/docs/introvideos/basics): Set up and learn the basics of Visual Studio Code. (7 min)
|
| 17 |
+
* [Code Editing](https://code.visualstudio.com/docs/introvideos/codeediting): Learn how to edit and run code in VS Code. (3 min)
|
| 18 |
+
* [Productivity Tips](https://code.visualstudio.com/docs/introvideos/productivity): Become a VS Code power user with these productivity tips. (4 min)
|
| 19 |
+
* [Personalize](https://code.visualstudio.com/docs/introvideos/configure): Personalize VS Code to make it yours with themes. (2 min)
|
| 20 |
+
* [Extensions](https://code.visualstudio.com/docs/introvideos/extend): Add features, themes, and more to VS Code with extensions! (4 min)
|
| 21 |
+
* [Debugging](https://code.visualstudio.com/docs/introvideos/debugging): Get started with debugging in VS Code. (6 min)
|
| 22 |
+
* [Version Control](https://code.visualstudio.com/docs/introvideos/versioncontrol): Learn how to use Git version control in VS Code. (3 min)
|
| 23 |
+
* [Customize](https://code.visualstudio.com/docs/introvideos/customize): Learn how to customize your settings and keyboard shortcuts in VS Code. (6 min)
|
| 24 |
+
|
| 25 |
+
[Previous
|
| 26 |
+
|
| 27 |
+
1. Development Tools](#/development-tools)
|
| 28 |
+
|
| 29 |
+
[Next
|
| 30 |
+
|
| 31 |
+
AI Code Editors: GitHub Copilot](#/github-copilot)
|
markdown_files/Embeddings.md
ADDED
|
@@ -0,0 +1,106 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Embeddings"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/embeddings?id=openai-embeddings"
|
| 4 |
+
downloaded_at: "2025-06-08T23:27:24.487774"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Embeddings: OpenAI and Local Models](#/embeddings?id=embeddings-openai-and-local-models)
|
| 8 |
+
-----------------------------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
Embedding models convert text into a list of numbers. These are like a map of text in numerical form. Each number represents a feature, and similar texts will have numbers close to each other. So, if the numbers are similar, the text they represent mean something similar.
|
| 11 |
+
|
| 12 |
+
This is useful because text similarity is important in many common problems:
|
| 13 |
+
|
| 14 |
+
1. **Search**. Find similar documents to a query.
|
| 15 |
+
2. **Classification**. Classify text into categories.
|
| 16 |
+
3. **Clustering**. Group similar items into clusters.
|
| 17 |
+
4. **Anomaly Detection**. Find an unusual piece of text.
|
| 18 |
+
|
| 19 |
+
You can run embedding models locally or using an API. Local models are better for privacy and cost. APIs are better for scale and quality.
|
| 20 |
+
|
| 21 |
+
| Feature | Local Models | API |
|
| 22 |
+
| --- | --- | --- |
|
| 23 |
+
| **Privacy** | High | Dependent on provider |
|
| 24 |
+
| **Cost** | High setup, low after that | Pay-as-you-go |
|
| 25 |
+
| **Scale** | Limited by local resources | Easily scales with demand |
|
| 26 |
+
| **Quality** | Varies by model | Typically high |
|
| 27 |
+
|
| 28 |
+
The [Massive Text Embedding Benchmark (MTEB)](https://huggingface.co/spaces/mteb/leaderboard) provides comprehensive comparisons of embedding models. These models are compared on several parameters, but here are some key ones to look at:
|
| 29 |
+
|
| 30 |
+
1. **Rank**. Higher ranked models have higher quality.
|
| 31 |
+
2. **Memory Usage**. Lower is better (for similar ranks). It costs less and is faster to run.
|
| 32 |
+
3. **Embedding Dimensions**. Lower is better. This is the number of numbers in the array. Smaller dimensions are cheaper to store.
|
| 33 |
+
4. **Max Tokens**. Higher is better. This is the number of input tokens (words) the model can take in a *single* input.
|
| 34 |
+
5. Look for higher scores in the columns for Classification, Clustering, Summarization, etc. based on your needs.
|
| 35 |
+
|
| 36 |
+
### [Local Embeddings](#/embeddings?id=local-embeddings)
|
| 37 |
+
|
| 38 |
+
[](https://youtu.be/OATCgQtNX2o)
|
| 39 |
+
|
| 40 |
+
Here’s a minimal example using a local embedding model:
|
| 41 |
+
|
| 42 |
+
```
|
| 43 |
+
# /// script
|
| 44 |
+
# requires-python = "==3.12"
|
| 45 |
+
# dependencies = [
|
| 46 |
+
# "sentence-transformers",
|
| 47 |
+
# "httpx",
|
| 48 |
+
# "numpy",
|
| 49 |
+
# ]
|
| 50 |
+
# ///
|
| 51 |
+
|
| 52 |
+
from sentence_transformers import SentenceTransformer
|
| 53 |
+
import numpy as np
|
| 54 |
+
|
| 55 |
+
model = SentenceTransformer('BAAI/bge-base-en-v1.5') # A small, high quality model
|
| 56 |
+
|
| 57 |
+
async def embed(text: str) -> list[float]:
|
| 58 |
+
"""Get embedding vector for text using local model."""
|
| 59 |
+
return model.encode(text).tolist()
|
| 60 |
+
|
| 61 |
+
async def get_similarity(text1: str, text2: str) -> float:
|
| 62 |
+
"""Calculate cosine similarity between two texts."""
|
| 63 |
+
emb1 = np.array(await embed(text1))
|
| 64 |
+
emb2 = np.array(await embed(text2))
|
| 65 |
+
return float(np.dot(emb1, emb2) / (np.linalg.norm(emb1) * np.linalg.norm(emb2)))
|
| 66 |
+
|
| 67 |
+
async def main():
|
| 68 |
+
print(await get_similarity("Apple", "Orange"))
|
| 69 |
+
print(await get_similarity("Apple", "Lightning"))
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
if __name__ == "__main__":
|
| 73 |
+
import asyncio
|
| 74 |
+
asyncio.run(main())Copy to clipboardErrorCopied
|
| 75 |
+
```
|
| 76 |
+
|
| 77 |
+
Note the `get_similarity` function. It uses a [Cosine Similarity](https://en.wikipedia.org/wiki/Cosine_similarity) to calculate the similarity between two embeddings.
|
| 78 |
+
|
| 79 |
+
### [OpenAI Embeddings](#/embeddings?id=openai-embeddings)
|
| 80 |
+
|
| 81 |
+
For comparison, here’s how to use OpenAI’s API with direct HTTP calls. Replace the `embed` function in the earlier script:
|
| 82 |
+
|
| 83 |
+
```
|
| 84 |
+
import os
|
| 85 |
+
import httpx
|
| 86 |
+
|
| 87 |
+
async def embed(text: str) -> list[float]:
|
| 88 |
+
"""Get embedding vector for text using OpenAI's API."""
|
| 89 |
+
async with httpx.AsyncClient() as client:
|
| 90 |
+
response = await client.post(
|
| 91 |
+
"https://api.openai.com/v1/embeddings",
|
| 92 |
+
headers={"Authorization": f"Bearer {os.environ['OPENAI_API_KEY']}"},
|
| 93 |
+
json={"model": "text-embedding-3-small", "input": text}
|
| 94 |
+
)
|
| 95 |
+
return response.json()["data"][0]["embedding"]Copy to clipboardErrorCopied
|
| 96 |
+
```
|
| 97 |
+
|
| 98 |
+
**NOTE**: You need to set the [`OPENAI_API_KEY`](https://platform.openai.com/api-keys) environment variable for this to work.
|
| 99 |
+
|
| 100 |
+
[Previous
|
| 101 |
+
|
| 102 |
+
Vision Models](#/vision-models)
|
| 103 |
+
|
| 104 |
+
[Next
|
| 105 |
+
|
| 106 |
+
Multimodal Embeddings](#/multimodal-embeddings)
|
markdown_files/Extracting_Audio_and_Transcripts.md
ADDED
|
@@ -0,0 +1,298 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Extracting Audio and Transcripts"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/extracting-audio-and-transcripts?id=media-tools-yt-dlp"
|
| 4 |
+
downloaded_at: "2025-06-08T23:25:44.497461"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Extracting Audio and Transcripts](#/extracting-audio-and-transcripts?id=extracting-audio-and-transcripts)
|
| 8 |
+
----------------------------------------------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
[Media Processing: FFmpeg](#/extracting-audio-and-transcripts?id=media-processing-ffmpeg)
|
| 11 |
+
-----------------------------------------------------------------------------------------
|
| 12 |
+
|
| 13 |
+
[FFmpeg](https://ffmpeg.org/) is the standard command-line tool for processing video and audio files. It’s essential for data scientists working with media files for:
|
| 14 |
+
|
| 15 |
+
* Extracting audio/video for machine learning
|
| 16 |
+
* Converting formats for web deployment
|
| 17 |
+
* Creating visualizations and presentations
|
| 18 |
+
* Processing large media datasets
|
| 19 |
+
|
| 20 |
+
Basic Operations:
|
| 21 |
+
|
| 22 |
+
```
|
| 23 |
+
# Basic conversion
|
| 24 |
+
ffmpeg -i input.mp4 output.avi
|
| 25 |
+
|
| 26 |
+
# Extract audio
|
| 27 |
+
ffmpeg -i input.mp4 -vn output.mp3
|
| 28 |
+
|
| 29 |
+
# Convert format without re-encoding
|
| 30 |
+
ffmpeg -i input.mkv -c copy output.mp4
|
| 31 |
+
|
| 32 |
+
# High quality encoding (crf: 0-51, lower is better)
|
| 33 |
+
ffmpeg -i input.mp4 -preset slower -crf 18 output.mp4Copy to clipboardErrorCopied
|
| 34 |
+
```
|
| 35 |
+
|
| 36 |
+
Common Data Science Tasks:
|
| 37 |
+
|
| 38 |
+
```
|
| 39 |
+
# Extract frames for computer vision
|
| 40 |
+
ffmpeg -i input.mp4 -vf "fps=1" frames_%04d.png # 1 frame per second
|
| 41 |
+
ffmpeg -i input.mp4 -vf "select='eq(n,0)'" -vframes 1 first_frame.jpg
|
| 42 |
+
|
| 43 |
+
# Create video from image sequence
|
| 44 |
+
ffmpeg -r 1/5 -i img%03d.png -c:v libx264 -vf fps=25 output.mp4
|
| 45 |
+
|
| 46 |
+
# Extract audio for speech recognition
|
| 47 |
+
ffmpeg -i input.mp4 -ar 16000 -ac 1 audio.wav # 16kHz mono
|
| 48 |
+
|
| 49 |
+
# Trim video/audio for training data
|
| 50 |
+
ffmpeg -ss 00:01:00 -i input.mp4 -t 00:00:30 -c copy clip.mp4Copy to clipboardErrorCopied
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
Processing Multiple Files:
|
| 54 |
+
|
| 55 |
+
```
|
| 56 |
+
# Concatenate videos (first create files.txt with list of files)
|
| 57 |
+
echo "file 'input1.mp4'
|
| 58 |
+
file 'input2.mp4'" > files.txt
|
| 59 |
+
ffmpeg -f concat -i files.txt -c copy output.mp4
|
| 60 |
+
|
| 61 |
+
# Batch process with shell loop
|
| 62 |
+
for f in *.mp4; do
|
| 63 |
+
ffmpeg -i "$f" -vn "audio/${f%.mp4}.wav"
|
| 64 |
+
doneCopy to clipboardErrorCopied
|
| 65 |
+
```
|
| 66 |
+
|
| 67 |
+
Data Analysis Features:
|
| 68 |
+
|
| 69 |
+
```
|
| 70 |
+
# Get media file information
|
| 71 |
+
ffprobe -v quiet -print_format json -show_format -show_streams input.mp4
|
| 72 |
+
|
| 73 |
+
# Display frame metadata
|
| 74 |
+
ffprobe -v quiet -print_format json -show_frames input.mp4
|
| 75 |
+
|
| 76 |
+
# Generate video thumbnails
|
| 77 |
+
ffmpeg -i input.mp4 -vf "thumbnail" -frames:v 1 thumb.jpgCopy to clipboardErrorCopied
|
| 78 |
+
```
|
| 79 |
+
|
| 80 |
+
Watch this introduction to FFmpeg (12 min):
|
| 81 |
+
|
| 82 |
+
[](https://youtu.be/MPV7JXTWPWI)
|
| 83 |
+
|
| 84 |
+
Tools:
|
| 85 |
+
|
| 86 |
+
* [ffmpeg.lav.io](https://ffmpeg.lav.io/): Interactive command builder
|
| 87 |
+
* [FFmpeg Explorer](https://ffmpeg.guide/): Visual FFmpeg command generator
|
| 88 |
+
* [FFmpeg Buddy](https://evanhahn.github.io/ffmpeg-buddy/): Simple command generator
|
| 89 |
+
|
| 90 |
+
Tips:
|
| 91 |
+
|
| 92 |
+
1. Use `-c copy` when possible to avoid re-encoding
|
| 93 |
+
2. Monitor progress with `-progress pipe:1`
|
| 94 |
+
3. Use `-hide_banner` to reduce output verbosity
|
| 95 |
+
4. Test commands with small clips first
|
| 96 |
+
5. Use hardware acceleration when available (-hwaccel auto)
|
| 97 |
+
|
| 98 |
+
Error Handling:
|
| 99 |
+
|
| 100 |
+
```
|
| 101 |
+
# Validate file before processing
|
| 102 |
+
ffprobe input.mp4 2>&1 | grep "Invalid"
|
| 103 |
+
|
| 104 |
+
# Continue on errors in batch processing
|
| 105 |
+
ffmpeg -i input.mp4 output.mp4 -xerror
|
| 106 |
+
|
| 107 |
+
# Get detailed error information
|
| 108 |
+
ffmpeg -v error -i input.mp4 2>&1 | grep -A2 "Error"Copy to clipboardErrorCopied
|
| 109 |
+
```
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
[Media tools: yt-dlp](#/extracting-audio-and-transcripts?id=media-tools-yt-dlp)
|
| 114 |
+
-------------------------------------------------------------------------------
|
| 115 |
+
|
| 116 |
+
[yt-dlp](https://github.com/yt-dlp/yt-dlp) is a feature-rich command-line tool for downloading audio/video from thousands of sites. It’s particularly useful for extracting audio and transcripts from videos.
|
| 117 |
+
|
| 118 |
+
Install using your package manager:
|
| 119 |
+
|
| 120 |
+
```
|
| 121 |
+
# macOS
|
| 122 |
+
brew install yt-dlp
|
| 123 |
+
|
| 124 |
+
# Linux
|
| 125 |
+
curl -L https://github.com/yt-dlp/yt-dlp/releases/latest/download/yt-dlp -o ~/.local/bin/yt-dlp
|
| 126 |
+
chmod a+rx ~/.local/bin/yt-dlp
|
| 127 |
+
|
| 128 |
+
# Windows
|
| 129 |
+
winget install yt-dlpCopy to clipboardErrorCopied
|
| 130 |
+
```
|
| 131 |
+
|
| 132 |
+
Common operations for extracting audio and transcripts:
|
| 133 |
+
|
| 134 |
+
```
|
| 135 |
+
# Download audio only at lowest quality suitable for speech
|
| 136 |
+
yt-dlp -f "ba[abr<50]/worstaudio" \
|
| 137 |
+
--extract-audio \
|
| 138 |
+
--audio-format mp3 \
|
| 139 |
+
--audio-quality 32k \
|
| 140 |
+
"https://www.youtube.com/watch?v=VIDEO_ID"
|
| 141 |
+
|
| 142 |
+
# Download auto-generated subtitles
|
| 143 |
+
yt-dlp --write-auto-sub \
|
| 144 |
+
--skip-download \
|
| 145 |
+
--sub-format "srt" \
|
| 146 |
+
"https://www.youtube.com/watch?v=VIDEO_ID"
|
| 147 |
+
|
| 148 |
+
# Download both audio and subtitles with custom output template
|
| 149 |
+
yt-dlp -f "ba[abr<50]/worstaudio" \
|
| 150 |
+
--extract-audio \
|
| 151 |
+
--audio-format mp3 \
|
| 152 |
+
--audio-quality 32k \
|
| 153 |
+
--write-auto-sub \
|
| 154 |
+
--sub-format "srt" \
|
| 155 |
+
-o "%(title)s.%(ext)s" \
|
| 156 |
+
"https://www.youtube.com/watch?v=VIDEO_ID"
|
| 157 |
+
|
| 158 |
+
# Download entire playlist's audio
|
| 159 |
+
yt-dlp -f "ba[abr<50]/worstaudio" \
|
| 160 |
+
--extract-audio \
|
| 161 |
+
--audio-format mp3 \
|
| 162 |
+
--audio-quality 32k \
|
| 163 |
+
-o "%(playlist_index)s-%(title)s.%(ext)s" \
|
| 164 |
+
"https://www.youtube.com/playlist?list=PLAYLIST_ID"Copy to clipboardErrorCopied
|
| 165 |
+
```
|
| 166 |
+
|
| 167 |
+
For Python integration:
|
| 168 |
+
|
| 169 |
+
```
|
| 170 |
+
# /// script
|
| 171 |
+
# requires-python = ">=3.9"
|
| 172 |
+
# dependencies = ["yt-dlp"]
|
| 173 |
+
# ///
|
| 174 |
+
|
| 175 |
+
import yt_dlp
|
| 176 |
+
|
| 177 |
+
def download_audio(url: str) -> None:
|
| 178 |
+
"""Download audio at speech-optimized quality."""
|
| 179 |
+
ydl_opts = {
|
| 180 |
+
'format': 'ba[abr<50]/worstaudio',
|
| 181 |
+
'postprocessors': [{
|
| 182 |
+
'key': 'FFmpegExtractAudio',
|
| 183 |
+
'preferredcodec': 'mp3',
|
| 184 |
+
'preferredquality': '32'
|
| 185 |
+
}]
|
| 186 |
+
}
|
| 187 |
+
|
| 188 |
+
with yt_dlp.YoutubeDL(ydl_opts) as ydl:
|
| 189 |
+
ydl.download([url])
|
| 190 |
+
|
| 191 |
+
# Example usage
|
| 192 |
+
download_audio('https://www.youtube.com/watch?v=VIDEO_ID')Copy to clipboardErrorCopied
|
| 193 |
+
```
|
| 194 |
+
|
| 195 |
+
Tools:
|
| 196 |
+
|
| 197 |
+
* [ffmpeg](https://ffmpeg.org/): Required for audio extraction and conversion
|
| 198 |
+
* [whisper](https://github.com/openai/whisper): Can be used with yt-dlp for speech-to-text
|
| 199 |
+
* [gallery-dl](https://github.com/mikf/gallery-dl): Alternative for image-focused sites
|
| 200 |
+
|
| 201 |
+
Note: Always respect copyright and terms of service when downloading content.
|
| 202 |
+
|
| 203 |
+
[Whisper transcription](#/extracting-audio-and-transcripts?id=whisper-transcription)
|
| 204 |
+
------------------------------------------------------------------------------------
|
| 205 |
+
|
| 206 |
+
[Faster Whisper](https://github.com/SYSTRAN/faster-whisper) is a highly optimized implementation of OpenAI’s [Whisper model](https://github.com/openai/whisper), offering up to 4x faster transcription while using less memory.
|
| 207 |
+
|
| 208 |
+
You can install it via:
|
| 209 |
+
|
| 210 |
+
* `pip install faster-whisper`
|
| 211 |
+
* [Download Windows Standalone](https://github.com/Purfview/whisper-standalone-win/releases)
|
| 212 |
+
|
| 213 |
+
Here’s a basic usage example:
|
| 214 |
+
|
| 215 |
+
```
|
| 216 |
+
faster-whisper-xxl "video.mp4" --model medium --language enCopy to clipboardErrorCopied
|
| 217 |
+
```
|
| 218 |
+
|
| 219 |
+
Here’s my recommendation for transcribing videos. This saves the output in JSON as well as SRT format in the source directory.
|
| 220 |
+
|
| 221 |
+
```
|
| 222 |
+
faster-whisper-xxl --print_progress --output_dir source --batch_recursive \
|
| 223 |
+
--check_files --standard --output_format json srt \
|
| 224 |
+
--model medium --language en $FILECopy to clipboardErrorCopied
|
| 225 |
+
```
|
| 226 |
+
|
| 227 |
+
* `--model`: The OpenAI Whisper model to use. You can choose from:
|
| 228 |
+
+ `tiny`: Fastest but least accurate
|
| 229 |
+
+ `base`: Good for simple audio
|
| 230 |
+
+ `small`: Balanced speed/accuracy
|
| 231 |
+
+ `medium`: Recommended default
|
| 232 |
+
+ `large-v3`: Most accurate but slowest
|
| 233 |
+
* `--output_format`: The output format to use. You can pick multiple formats from:
|
| 234 |
+
+ `json`: Has the most detailed information including timing, text, quality, etc.
|
| 235 |
+
+ `srt`: A popular subtitle format. You can use this in YouTube, for example.
|
| 236 |
+
+ `vtt`: A modern subtitle format.
|
| 237 |
+
+ `txt`: Just the text transcript
|
| 238 |
+
* `--output_dir`: The directory to save the output files. `source` indicates the source directory, i.e. where the input `$FILE` is
|
| 239 |
+
* `--language`: The language of the input file. If you don’t specify it, it analyzes the first 30 seconds to auto-detect. You can speed it up by specifying it.
|
| 240 |
+
|
| 241 |
+
Run `faster-whisper-xxl --help` for more options.
|
| 242 |
+
|
| 243 |
+
[Gemini transcription](#/extracting-audio-and-transcripts?id=gemini-transcription)
|
| 244 |
+
----------------------------------------------------------------------------------
|
| 245 |
+
|
| 246 |
+
The [Gemini](https://gemini.google.com/) models from Google are notable in two ways:
|
| 247 |
+
|
| 248 |
+
1. They have a *huge* input context window. Gemini 2.0 Flash can accept 1M tokens, for example.
|
| 249 |
+
2. They can handle audio input.
|
| 250 |
+
|
| 251 |
+
This allows us to use Gemini to transcribe audio files.
|
| 252 |
+
|
| 253 |
+
LLMs are not good at transcribing audio *faithfully*. They tend to correct errors and meander from what was said. But they are intelligent. That enables a few powerful workflows. Here are some examples:
|
| 254 |
+
|
| 255 |
+
1. **Transcribe into other languages**. Gemini will handle the transcription and translation in a single step.
|
| 256 |
+
2. **Summarize audio transcripts**. For example, convert a podcast into a tutorial, or a meeting recording into actions.
|
| 257 |
+
3. **Legal Proceeding Analysis**. Extract case citations, dates, and other details from a legal debate.
|
| 258 |
+
4. **Medical Consultation Summary**. Extract treatments, medications, details of next visit, etc. from a medical consultation.
|
| 259 |
+
|
| 260 |
+
Here’s how to use Gemini to transcribe audio files.
|
| 261 |
+
|
| 262 |
+
1. Get a [Gemini API key](https://aistudio.google.com/app/apikey) from Google AI Studio.
|
| 263 |
+
2. Set the `GEMINI_API_KEY` environment variable to the API key.
|
| 264 |
+
3. Set the `MP3_FILE` environment variable to the path of the MP3 file you want to transcribe.
|
| 265 |
+
4. Run this code:
|
| 266 |
+
|
| 267 |
+
```
|
| 268 |
+
curl -X POST https://generativelanguage.googleapis.com/v1beta/models/gemini-1.5-flash-002:streamGenerateContent?alt=sse \
|
| 269 |
+
-H "X-Goog-API-Key: $GEMINI_API_KEY" \
|
| 270 |
+
-H "Content-Type: application/json" \
|
| 271 |
+
-d "$(cat << EOF
|
| 272 |
+
{
|
| 273 |
+
"contents": [
|
| 274 |
+
{
|
| 275 |
+
"role": "user",
|
| 276 |
+
"parts": [
|
| 277 |
+
{
|
| 278 |
+
"inline_data": {
|
| 279 |
+
"mime_type": "audio/mp3",
|
| 280 |
+
"data": "$(base64 --wrap=0 $MP3_FILE)"
|
| 281 |
+
}
|
| 282 |
+
},
|
| 283 |
+
{"text": "Transcribe this"}
|
| 284 |
+
]
|
| 285 |
+
}
|
| 286 |
+
]
|
| 287 |
+
}
|
| 288 |
+
EOF
|
| 289 |
+
)"Copy to clipboardErrorCopied
|
| 290 |
+
```
|
| 291 |
+
|
| 292 |
+
[Previous
|
| 293 |
+
|
| 294 |
+
Transforming Images](#/transforming-images)
|
| 295 |
+
|
| 296 |
+
[Next
|
| 297 |
+
|
| 298 |
+
6. Data Analysis](#/data-analysis)
|
markdown_files/Forecasting_with_Excel.md
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Forecasting with Excel"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/forecasting-with-excel?id=forecasting-with-excel"
|
| 4 |
+
downloaded_at: "2025-06-08T23:26:21.478299"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Forecasting with Excel](#/forecasting-with-excel?id=forecasting-with-excel)
|
| 8 |
+
----------------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
[](https://youtu.be/QrTimmxwZw4)
|
| 11 |
+
|
| 12 |
+
Here are links used in the video:
|
| 13 |
+
|
| 14 |
+
* [FORECAST reference](https://support.microsoft.com/en-us/office/forecast-and-forecast-linear-functions-50ca49c9-7b40-4892-94e4-7ad38bbeda99)
|
| 15 |
+
* [FORECAST.ETS reference](https://support.microsoft.com/en-us/office/forecast-ets-function-15389b8b-677e-4fbd-bd95-21d464333f41)
|
| 16 |
+
* [Height-weight dataset](https://docs.google.com/spreadsheets/d/1iMFVPh8q9KgnfLwBeBMmX1GaFabP02FK/view) from [Kaggle](https://www.kaggle.com/datasets/burnoutminer/heights-and-weights-dataset)
|
| 17 |
+
* [Traffic dataset](https://docs.google.com/spreadsheets/d/1w2R0fHdLG5ZGW-papaK7wzWq_-WDArKC/view) from [Kaggle](https://www.kaggle.com/datasets/fedesoriano/traffic-prediction-dataset)
|
| 18 |
+
|
| 19 |
+
[Previous
|
| 20 |
+
|
| 21 |
+
Regression with Excel](#/regression-with-excel)
|
| 22 |
+
|
| 23 |
+
[Next
|
| 24 |
+
|
| 25 |
+
Outlier Detection with Excel](#/outlier-detection-with-excel)
|
markdown_files/Function_Calling.md
ADDED
|
@@ -0,0 +1,184 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Function Calling"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/function-calling?id=function-calling-with-openai"
|
| 4 |
+
downloaded_at: "2025-06-08T23:26:04.973121"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Function Calling with OpenAI](#/function-calling?id=function-calling-with-openai)
|
| 8 |
+
----------------------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
[Function Calling](https://platform.openai.com/docs/guides/function-calling) allows Large Language Models to convert natural language into structured function calls. This is perfect for building chatbots and AI assistants that need to interact with your backend systems.
|
| 11 |
+
|
| 12 |
+
OpenAI supports [Function Calling](https://platform.openai.com/docs/guides/function-calling) – a way for LLMs to suggest what functions to call and how.
|
| 13 |
+
|
| 14 |
+
[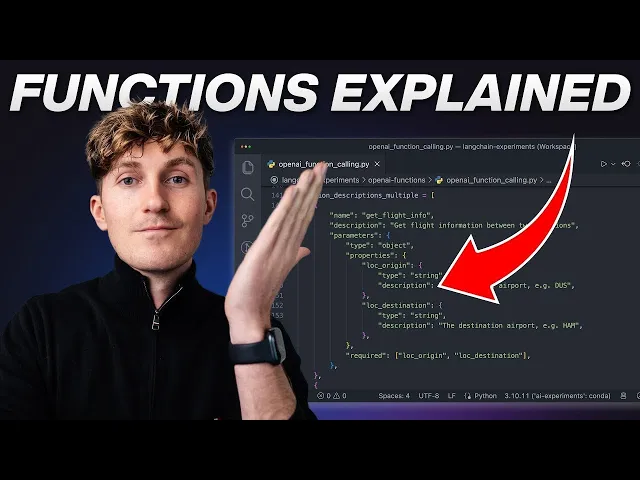](https://youtu.be/aqdWSYWC_LI)
|
| 15 |
+
|
| 16 |
+
Here’s a minimal example using Python and OpenAI’s function calling that identifies the weather in a given location.
|
| 17 |
+
|
| 18 |
+
```
|
| 19 |
+
# /// script
|
| 20 |
+
# requires-python = ">=3.11"
|
| 21 |
+
# dependencies = [
|
| 22 |
+
# "httpx",
|
| 23 |
+
# ]
|
| 24 |
+
# ///
|
| 25 |
+
|
| 26 |
+
import httpx
|
| 27 |
+
import os
|
| 28 |
+
from typing import Dict, Any
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def query_gpt(user_input: str, tools: list[Dict[str, Any]]) -> Dict[str, Any]:
|
| 32 |
+
response = httpx.post(
|
| 33 |
+
"https://api.openai.com/v1/chat/completions",
|
| 34 |
+
headers={
|
| 35 |
+
"Authorization": f"Bearer {os.getenv('OPENAI_API_KEY')}",
|
| 36 |
+
"Content-Type": "application/json",
|
| 37 |
+
},
|
| 38 |
+
json={
|
| 39 |
+
"model": "gpt-4o-mini",
|
| 40 |
+
"messages": [{"role": "user", "content": user_input}],
|
| 41 |
+
"tools": tools,
|
| 42 |
+
"tool_choice": "auto",
|
| 43 |
+
},
|
| 44 |
+
)
|
| 45 |
+
return response.json()["choices"][0]["message"]
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
WEATHER_TOOL = {
|
| 49 |
+
"type": "function",
|
| 50 |
+
"function": {
|
| 51 |
+
"name": "get_weather",
|
| 52 |
+
"description": "Get the current weather for a location",
|
| 53 |
+
"parameters": {
|
| 54 |
+
"type": "object",
|
| 55 |
+
"properties": {
|
| 56 |
+
"location": {"type": "string", "description": "City name or coordinates"}
|
| 57 |
+
},
|
| 58 |
+
"required": ["location"],
|
| 59 |
+
"additionalProperties": False,
|
| 60 |
+
},
|
| 61 |
+
"strict": True,
|
| 62 |
+
},
|
| 63 |
+
}
|
| 64 |
+
|
| 65 |
+
if __name__ == "__main__":
|
| 66 |
+
response = query_gpt("What is the weather in San Francisco?", [WEATHER_TOOL])
|
| 67 |
+
print([tool_call["function"] for tool_call in response["tool_calls"]])Copy to clipboardErrorCopied
|
| 68 |
+
```
|
| 69 |
+
|
| 70 |
+
### [How to define functions](#/function-calling?id=how-to-define-functions)
|
| 71 |
+
|
| 72 |
+
The function definition is a [JSON schema](https://json-schema.org/) with a few OpenAI specific properties.
|
| 73 |
+
See the [Supported schemas](https://platform.openai.com/docs/guides/structured-outputs#supported-schemas).
|
| 74 |
+
|
| 75 |
+
Here’s an example of a function definition for scheduling a meeting:
|
| 76 |
+
|
| 77 |
+
```
|
| 78 |
+
MEETING_TOOL = {
|
| 79 |
+
"type": "function",
|
| 80 |
+
"function": {
|
| 81 |
+
"name": "schedule_meeting",
|
| 82 |
+
"description": "Schedule a meeting room for a specific date and time",
|
| 83 |
+
"parameters": {
|
| 84 |
+
"type": "object",
|
| 85 |
+
"properties": {
|
| 86 |
+
"date": {
|
| 87 |
+
"type": "string",
|
| 88 |
+
"description": "Meeting date in YYYY-MM-DD format"
|
| 89 |
+
},
|
| 90 |
+
"time": {
|
| 91 |
+
"type": "string",
|
| 92 |
+
"description": "Meeting time in HH:MM format"
|
| 93 |
+
},
|
| 94 |
+
"meeting_room": {
|
| 95 |
+
"type": "string",
|
| 96 |
+
"description": "Name of the meeting room"
|
| 97 |
+
}
|
| 98 |
+
},
|
| 99 |
+
"required": ["date", "time", "meeting_room"],
|
| 100 |
+
"additionalProperties": False
|
| 101 |
+
},
|
| 102 |
+
"strict": True
|
| 103 |
+
}
|
| 104 |
+
}Copy to clipboardErrorCopied
|
| 105 |
+
```
|
| 106 |
+
|
| 107 |
+
### [How to define multiple functions](#/function-calling?id=how-to-define-multiple-functions)
|
| 108 |
+
|
| 109 |
+
You can define multiple functions by passing a list of function definitions to the `tools` parameter.
|
| 110 |
+
|
| 111 |
+
Here’s an example of a list of function definitions for handling employee expenses and calculating performance bonuses:
|
| 112 |
+
|
| 113 |
+
```
|
| 114 |
+
tools = [
|
| 115 |
+
{
|
| 116 |
+
"type": "function",
|
| 117 |
+
"function": {
|
| 118 |
+
"name": "get_expense_balance",
|
| 119 |
+
"description": "Get expense balance for an employee",
|
| 120 |
+
"parameters": {
|
| 121 |
+
"type": "object",
|
| 122 |
+
"properties": {
|
| 123 |
+
"employee_id": {
|
| 124 |
+
"type": "integer",
|
| 125 |
+
"description": "Employee ID number"
|
| 126 |
+
}
|
| 127 |
+
},
|
| 128 |
+
"required": ["employee_id"],
|
| 129 |
+
"additionalProperties": False
|
| 130 |
+
},
|
| 131 |
+
"strict": True
|
| 132 |
+
}
|
| 133 |
+
},
|
| 134 |
+
{
|
| 135 |
+
"type": "function",
|
| 136 |
+
"function": {
|
| 137 |
+
"name": "calculate_performance_bonus",
|
| 138 |
+
"description": "Calculate yearly performance bonus for an employee",
|
| 139 |
+
"parameters": {
|
| 140 |
+
"type": "object",
|
| 141 |
+
"properties": {
|
| 142 |
+
"employee_id": {
|
| 143 |
+
"type": "integer",
|
| 144 |
+
"description": "Employee ID number"
|
| 145 |
+
},
|
| 146 |
+
"current_year": {
|
| 147 |
+
"type": "integer",
|
| 148 |
+
"description": "Year to calculate bonus for"
|
| 149 |
+
}
|
| 150 |
+
},
|
| 151 |
+
"required": ["employee_id", "current_year"],
|
| 152 |
+
"additionalProperties": False
|
| 153 |
+
},
|
| 154 |
+
"strict": True
|
| 155 |
+
}
|
| 156 |
+
}
|
| 157 |
+
]Copy to clipboardErrorCopied
|
| 158 |
+
```
|
| 159 |
+
|
| 160 |
+
Best Practices:
|
| 161 |
+
|
| 162 |
+
1. **Use Strict Mode**
|
| 163 |
+
* Always set `strict: True` to ensure valid function calls
|
| 164 |
+
* Define all required parameters
|
| 165 |
+
* Set `additionalProperties: False`
|
| 166 |
+
2. **Use tool choice**
|
| 167 |
+
* Set `tool_choice: "required"` to ensure that the model will always call one or more tools
|
| 168 |
+
* The default is `tool_choice: "auto"` which means the model will choose a tool only if appropriate
|
| 169 |
+
3. **Clear Descriptions**
|
| 170 |
+
* Write detailed function and parameter descriptions
|
| 171 |
+
* Include expected formats and units
|
| 172 |
+
* Mention any constraints or limitations
|
| 173 |
+
4. **Error Handling**
|
| 174 |
+
* Validate function inputs before execution
|
| 175 |
+
* Return clear error messages
|
| 176 |
+
* Handle missing or invalid parameters
|
| 177 |
+
|
| 178 |
+
[Previous
|
| 179 |
+
|
| 180 |
+
Hybrid RAG with TypeSense](#/hybrid-rag-typesense)
|
| 181 |
+
|
| 182 |
+
[Next
|
| 183 |
+
|
| 184 |
+
LLM Agents](#/llm-agents)
|
markdown_files/Geospatial_Analysis_with_Excel.md
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Geospatial Analysis with Excel"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/geospatial-analysis-with-excel?id=geospatial-analysis-with-excel"
|
| 4 |
+
downloaded_at: "2025-06-08T23:26:02.659173"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Geospatial Analysis with Excel](#/geospatial-analysis-with-excel?id=geospatial-analysis-with-excel)
|
| 8 |
+
----------------------------------------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
[](https://youtu.be/49LjxNvxyVs)
|
| 11 |
+
|
| 12 |
+
You’ll learn how to create a data-driven story about coffee shop coverage in Manhattan, covering:
|
| 13 |
+
|
| 14 |
+
* **Data Collection**: Collect and scrape data for coffee shop locations and census population from various sources.
|
| 15 |
+
* **Data Processing**: Use Python libraries like geopandas for merging population data with geographic maps.
|
| 16 |
+
* **Map Creation**: Generate coverage maps using tools like QGIS and Excel to visualize coffee shop distribution and population impact.
|
| 17 |
+
* **Visualization**: Create physical, Power BI, and video visualizations to present the data effectively.
|
| 18 |
+
* **Storytelling**: Craft a narrative around coffee shop competition, including strategic insights and potential market changes.
|
| 19 |
+
|
| 20 |
+
Here are links that explain how the video was made:
|
| 21 |
+
|
| 22 |
+
* [The Making of the Manhattan Coffee Kings](https://blog.gramener.com/the-making-of-manhattans-coffee-kings/)
|
| 23 |
+
* [Shaping and merging maps](https://blog.gramener.com/shaping-and-merging-maps/)
|
| 24 |
+
* [Visualizing data on 3D maps](https://blog.gramener.com/visualizing-data-on-3d-maps/)
|
| 25 |
+
* [Physical and digital 3D maps](https://blog.gramener.com/physical-and-digital-3d-maps/)
|
| 26 |
+
|
| 27 |
+
[Previous
|
| 28 |
+
|
| 29 |
+
Data Analysis with ChatGPT](#/data-analysis-with-chatgpt)
|
| 30 |
+
|
| 31 |
+
[Next
|
| 32 |
+
|
| 33 |
+
Geospatial Analysis with Python](#/geospatial-analysis-with-python)
|
markdown_files/Geospatial_Analysis_with_Python.md
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Geospatial Analysis with Python"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/geospatial-analysis-with-python?id=geospatial-analysis-with-python"
|
| 4 |
+
downloaded_at: "2025-06-08T23:22:52.295346"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Geospatial Analysis with Python](#/geospatial-analysis-with-python?id=geospatial-analysis-with-python)
|
| 8 |
+
-------------------------------------------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
[](https://youtu.be/m_qayAJt-yE)
|
| 11 |
+
|
| 12 |
+
You’ll learn how to perform geospatial analysis for location-based decision making, covering:
|
| 13 |
+
|
| 14 |
+
* **Distance Calculation**: Compute distances between various store locations and a reference point, such as the Empire State Building.
|
| 15 |
+
* **Data Visualization**: Visualize store locations on a map using Python libraries like Folium.
|
| 16 |
+
* **Store Density Analysis**: Determine the number of stores within a specified radius.
|
| 17 |
+
* **Proximity Analysis**: Identify the closest and farthest stores from a specific location.
|
| 18 |
+
* **Decision Making**: Use geospatial data to assess whether opening a new store is feasible based on existing store distribution.
|
| 19 |
+
|
| 20 |
+
Here are links used in the video:
|
| 21 |
+
|
| 22 |
+
* [Jupyter Notebook](https://colab.research.google.com/drive/1TwKw2pQ9XKSdTUUsTq_ulw7rb-xVhays?usp=sharing)
|
| 23 |
+
* Learn about the [`pandas` package](https://pandas.pydata.org/pandas-docs/stable/user_guide/10min.html) and [video](https://youtu.be/vmEHCJofslg)
|
| 24 |
+
* Learn about the [`numpy` package](https://numpy.org/doc/stable/user/whatisnumpy.html) and [video](https://youtu.be/8JfDAm9y_7s)
|
| 25 |
+
* Learn about the [`folium` package](https://python-visualization.github.io/folium/latest/) and [video](https://youtu.be/t9Ed5QyO7qY)
|
| 26 |
+
* Learn about the [`geopy` package](https://pypi.org/project/geopy/) and [video](https://youtu.be/3jj_5kVmPLs)
|
| 27 |
+
|
| 28 |
+
[Previous
|
| 29 |
+
|
| 30 |
+
Geospatial Analysis with Excel](#/geospatial-analysis-with-excel)
|
| 31 |
+
|
| 32 |
+
[Next
|
| 33 |
+
|
| 34 |
+
Geospatial Analysis with QGIS](#/geospatial-analysis-with-qgis)
|
markdown_files/Geospatial_Analysis_with_QGIS.md
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Geospatial Analysis with QGIS"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/geospatial-analysis-with-qgis?id=geospatial-analysis-with-qgis"
|
| 4 |
+
downloaded_at: "2025-06-08T23:23:28.541219"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Geospatial Analysis with QGIS](#/geospatial-analysis-with-qgis?id=geospatial-analysis-with-qgis)
|
| 8 |
+
-------------------------------------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
[](https://youtu.be/tJhehs0o-ik)
|
| 11 |
+
|
| 12 |
+
You’ll learn how to use QGIS for geographic data processing, covering:
|
| 13 |
+
|
| 14 |
+
* **Shapefiles and KML Files**: Create and manage shapefiles and KML files for storing and analyzing geographic information.
|
| 15 |
+
* **Downloading QGIS**: Install QGIS on different operating systems and familiarize yourself with its interface.
|
| 16 |
+
* **Geospatial Data**: Access and utilize shapefiles from sources like Diva-GIS and integrate them into QGIS projects.
|
| 17 |
+
* **Creating Custom Shapefiles**: Learn how to create custom shapefiles when existing ones are unavailable, including creating a shapefile for South Sudan.
|
| 18 |
+
* **Editing and Visualization**: Use QGIS tools to edit shapefiles, add attributes, and visualize geographic data with various styling and labeling options.
|
| 19 |
+
* **Exporting Data**: Export shapefiles or KML files for use in other applications, such as Google Earth.
|
| 20 |
+
|
| 21 |
+
Here are links used in the video:
|
| 22 |
+
|
| 23 |
+
* [QGIS Project](https://www.qgis.org/en/site/)
|
| 24 |
+
* [Shapefile Data](https://www.diva-gis.org/gdata)
|
| 25 |
+
|
| 26 |
+
[Previous
|
| 27 |
+
|
| 28 |
+
Geospatial Analysis with Python](#/geospatial-analysis-with-python)
|
| 29 |
+
|
| 30 |
+
[Next
|
| 31 |
+
|
| 32 |
+
Network Analysis in Python](#/network-analysis-in-python)
|
markdown_files/Hybrid_RAG_with_TypeSense.md
ADDED
|
@@ -0,0 +1,154 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Hybrid RAG with TypeSense"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/hybrid-rag-typesense?id=install-and-run-typesense"
|
| 4 |
+
downloaded_at: "2025-06-08T23:25:43.332058"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Hybrid Retrieval Augmented Generation (Hybrid RAG) with TypeSense](#/hybrid-rag-typesense?id=hybrid-retrieval-augmented-generation-hybrid-rag-with-typesense)
|
| 8 |
+
--------------------------------------------------------------------------------------------------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
Hybrid RAG combines semantic (vector) search with traditional keyword search to improve retrieval accuracy and relevance. By mixing exact text matches with embedding-based similarity, you get the best of both worlds: precision when keywords are present, and semantic recall when phrasing varies. [TypeSense](https://typesense.org/) makes this easy with built-in hybrid search and automatic embedding generation.
|
| 11 |
+
|
| 12 |
+
Below is a fully self-contained Hybrid RAG tutorial using TypeSense, Python, and the command line.
|
| 13 |
+
|
| 14 |
+
### [Install and run TypeSense](#/hybrid-rag-typesense?id=install-and-run-typesense)
|
| 15 |
+
|
| 16 |
+
[Install TypeSense](https://typesense.org/docs/guide/install-typesense.html).
|
| 17 |
+
|
| 18 |
+
```
|
| 19 |
+
mkdir typesense-data
|
| 20 |
+
|
| 21 |
+
docker run -p 8108:8108 \
|
| 22 |
+
-v typesense-data:/data typesense/typesense:28.0 \
|
| 23 |
+
--data-dir /data \
|
| 24 |
+
--api-key=secret-key \
|
| 25 |
+
--enable-corsCopy to clipboardErrorCopied
|
| 26 |
+
```
|
| 27 |
+
|
| 28 |
+
* **`docker run`**: spins up a containerized TypeSense server on port 8108
|
| 29 |
+
+ `-p 8108:8108` maps host port to container port.
|
| 30 |
+
+ `-v typesense-data:/data` mounts a Docker volume for persistence.
|
| 31 |
+
+ `--data-dir /data` points TypeSense at that volume.
|
| 32 |
+
+ `--api-key=secret-key` secures your API.
|
| 33 |
+
+ `--enable-cors` allows browser-based requests.
|
| 34 |
+
|
| 35 |
+
**Expected output:**
|
| 36 |
+
|
| 37 |
+
* Docker logs showing TypeSense startup messages, such as `Started Typesense API server`.
|
| 38 |
+
* Listening on `http://0.0.0.0:8108`.
|
| 39 |
+
|
| 40 |
+
### [Embed and import documents into TypeSense](#/hybrid-rag-typesense?id=embed-and-import-documents-into-typesense)
|
| 41 |
+
|
| 42 |
+
Follow the steps in the [RAG with the CLI](#/rag-cli) tutorial to create a `chunks.json` that has one `{id, content}` JSON object per line.
|
| 43 |
+
|
| 44 |
+
[TypeSense supports automatic embedding of documents](https://typesense.org/docs/28.0/api/vector-search.html#option-b-auto-embedding-generation-within-typesense). We’ll use that capability.
|
| 45 |
+
|
| 46 |
+
Save the following as `addnotes.py` and run it with `uv run addnotes.py`.
|
| 47 |
+
|
| 48 |
+
```
|
| 49 |
+
# /// script
|
| 50 |
+
# requires-python = ">=3.13"
|
| 51 |
+
# dependencies = ["httpx"]
|
| 52 |
+
# ///
|
| 53 |
+
import json
|
| 54 |
+
import httpx
|
| 55 |
+
import os
|
| 56 |
+
|
| 57 |
+
headers = {"X-TYPESENSE-API-KEY": "secret-key"}
|
| 58 |
+
|
| 59 |
+
schema = {
|
| 60 |
+
"name": "notes",
|
| 61 |
+
"fields": [
|
| 62 |
+
{"name": "id", "type": "string", "facet": False},
|
| 63 |
+
{"name": "content", "type": "string", "facet": False},
|
| 64 |
+
{
|
| 65 |
+
"name": "embedding",
|
| 66 |
+
"type": "float[]",
|
| 67 |
+
"embed": {
|
| 68 |
+
"from": ["content"],
|
| 69 |
+
"model_config": {
|
| 70 |
+
"model_name": "openai/text-embedding-3-small",
|
| 71 |
+
"api_key": os.getenv("OPENAI_API_KEY"),
|
| 72 |
+
},
|
| 73 |
+
},
|
| 74 |
+
},
|
| 75 |
+
],
|
| 76 |
+
}
|
| 77 |
+
|
| 78 |
+
with open("chunks.json", "r") as f:
|
| 79 |
+
chunks = [json.loads(line) for line in f.readlines()]
|
| 80 |
+
|
| 81 |
+
with httpx.Client() as client:
|
| 82 |
+
# Create the collection
|
| 83 |
+
if client.get(f"http://localhost:8108/collections/notes", headers=headers).status_code == 404:
|
| 84 |
+
r = client.post("http://localhost:8108/collections", json=schema, headers=headers)
|
| 85 |
+
|
| 86 |
+
# Embed the chunks
|
| 87 |
+
result = client.post(
|
| 88 |
+
"http://localhost:8108/collections/notes/documents/import?action=emplace",
|
| 89 |
+
headers={**headers, "Content-Type": "text/plain"},
|
| 90 |
+
data="\n".join(json.dumps(chunk) for chunk in chunks),
|
| 91 |
+
)
|
| 92 |
+
print(result.text)Copy to clipboardErrorCopied
|
| 93 |
+
```
|
| 94 |
+
|
| 95 |
+
* **`httpx.Client`**: an HTTP client for Python.
|
| 96 |
+
* **Collection schema**: `id` and `content` fields plus an `embedding` field with auto-generated embeddings from OpenAI.
|
| 97 |
+
* **Auto-embedding**: the `embed` block instructs TypeSense to call the specified model for each document.
|
| 98 |
+
* **`GET /collections/notes`**: checks existence.
|
| 99 |
+
* **`POST /collections`**: creates the collection.
|
| 100 |
+
* **`POST /collections/notes/documents/import?action=emplace`**: bulk upsert documents, embedding them on the fly.
|
| 101 |
+
|
| 102 |
+
**Expected output:**
|
| 103 |
+
|
| 104 |
+
* A JSON summary string like `{"success": X, "failed": 0}` indicating how many docs were imported.
|
| 105 |
+
* (On timeouts, re-run until all chunks are processed.)
|
| 106 |
+
|
| 107 |
+
### [4. Run a hybrid search and answer a question](#/hybrid-rag-typesense?id=_4-run-a-hybrid-search-and-answer-a-question)
|
| 108 |
+
|
| 109 |
+
Now, we can use a single `curl` against the Multi-Search endpoint to combine keyword and vector search as a [hybrid search](https://typesense.org/docs/28.0/api/vector-search.html#hybrid-search):
|
| 110 |
+
|
| 111 |
+
```
|
| 112 |
+
Q="What does the author affectionately call the => syntax?"
|
| 113 |
+
|
| 114 |
+
payload=$(jq -n --arg coll "notes" --arg q "$Q" \
|
| 115 |
+
'{
|
| 116 |
+
searches: [
|
| 117 |
+
{
|
| 118 |
+
collection: $coll,
|
| 119 |
+
q: $q,
|
| 120 |
+
query_by: "content,embedding",
|
| 121 |
+
sort_by: "_text_match:desc",
|
| 122 |
+
prefix: false,
|
| 123 |
+
exclude_fields: "embedding"
|
| 124 |
+
}
|
| 125 |
+
]
|
| 126 |
+
}'
|
| 127 |
+
)
|
| 128 |
+
curl -s 'http://localhost:8108/multi_search' \
|
| 129 |
+
-H "X-TYPESENSE-API-KEY: secret-key" \
|
| 130 |
+
-d "$payload" \
|
| 131 |
+
| jq -r '.results[].hits[].document.content' \
|
| 132 |
+
| llm -s "${Q} - \$Answer ONLY from these notes. Cite verbatim from the notes." \
|
| 133 |
+
| uvx streamdownCopy to clipboardErrorCopied
|
| 134 |
+
```
|
| 135 |
+
|
| 136 |
+
* **`query_by: "content,embedding"`**: tells TypeSense to score by both keyword and vector similarity.
|
| 137 |
+
* **`sort_by: "_text_match:desc"`**: boosts exact text hits.
|
| 138 |
+
* **`exclude_fields: "embedding"`**: keeps responses lightweight.
|
| 139 |
+
* **`curl -d`**: posts the search request.
|
| 140 |
+
* **`jq -r`**: extracts each hit’s `content`. See [jq manual](https://stedolan.github.io/jq/manual/)
|
| 141 |
+
* **`llm -s`** and **`uvx streamdown`**: generate and stream a grounded answer.
|
| 142 |
+
|
| 143 |
+
**Expected output:**
|
| 144 |
+
|
| 145 |
+
* The raw matched snippets printed first.
|
| 146 |
+
* Then a concise, streamed LLM answer citing the note verbatim.
|
| 147 |
+
|
| 148 |
+
[Previous
|
| 149 |
+
|
| 150 |
+
RAG with the CLI)](#/rag-cli)
|
| 151 |
+
|
| 152 |
+
[Next
|
| 153 |
+
|
| 154 |
+
Function Calling](#/function-calling)
|
markdown_files/Images__Compression.md
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Images: Compression"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/image-compression?id=images-compression"
|
| 4 |
+
downloaded_at: "2025-06-08T23:26:15.003538"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Images: Compression](#/image-compression?id=images-compression)
|
| 8 |
+
----------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
Image compression is essential when deploying apps. Often, pages have dozens of images. Image analysis runs over thousands of images. The cost of storage and bandwidth can grow over time.
|
| 11 |
+
|
| 12 |
+
Here are things you should know when you’re compressing images:
|
| 13 |
+
|
| 14 |
+
* **Image dimensions** are the width and height of the image in pixels. This impacts image size a lot
|
| 15 |
+
* **Lossless** compression (PNG, WebP) preserves exact data
|
| 16 |
+
* **Lossy** compression (JPEG, WebP) removes some data for smaller files
|
| 17 |
+
* **Vector** formats (SVG) scale without quality loss
|
| 18 |
+
* **WebP** is the modern standard, supporting both lossy and lossless
|
| 19 |
+
|
| 20 |
+
Here’s a rule of thumb you can use as of 2025.
|
| 21 |
+
|
| 22 |
+
* Use SVG if you can (i.e. if it’s vector graphics or you can convert it to one)
|
| 23 |
+
* Else, reduce the image to as small as you can, and save as (lossy or lossless) WebP
|
| 24 |
+
|
| 25 |
+
Common operations with Python:
|
| 26 |
+
|
| 27 |
+
```
|
| 28 |
+
from pathlib import Path
|
| 29 |
+
from PIL import Image
|
| 30 |
+
import io
|
| 31 |
+
|
| 32 |
+
async def compress_image(input_path: Path, output_path: Path, quality: int = 85) -> None:
|
| 33 |
+
"""Compress an image while maintaining reasonable quality."""
|
| 34 |
+
with Image.open(input_path) as img:
|
| 35 |
+
# Convert RGBA to RGB if needed
|
| 36 |
+
if img.mode == 'RGBA':
|
| 37 |
+
img = img.convert('RGB')
|
| 38 |
+
# Optimize for web
|
| 39 |
+
img.save(output_path, 'WEBP', quality=quality, optimize=True)
|
| 40 |
+
|
| 41 |
+
# Batch process images
|
| 42 |
+
paths = Path('images').glob('*.jpg')
|
| 43 |
+
for p in paths:
|
| 44 |
+
await compress_image(p, p.with_suffix('.webp'))Copy to clipboardErrorCopied
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
Command line tools include [cwebp](https://developers.google.com/speed/webp/docs/cwebp), [pngquant](https://pngquant.org/), [jpegoptim](https://github.com/tjko/jpegoptim), and [ImageMagick](https://imagemagick.org/).
|
| 48 |
+
|
| 49 |
+
```
|
| 50 |
+
# Convert to WebP
|
| 51 |
+
cwebp -q 85 input.png -o output.webp
|
| 52 |
+
|
| 53 |
+
# Optimize PNG
|
| 54 |
+
pngquant --quality=65-80 image.png
|
| 55 |
+
|
| 56 |
+
# Optimize JPEG
|
| 57 |
+
jpegoptim --strip-all --all-progressive --max=85 image.jpg
|
| 58 |
+
|
| 59 |
+
# Convert and resize
|
| 60 |
+
convert input.jpg -resize 800x600 output.jpg
|
| 61 |
+
|
| 62 |
+
# Batch convert
|
| 63 |
+
mogrify -format webp -quality 85 *.jpgCopy to clipboardErrorCopied
|
| 64 |
+
```
|
| 65 |
+
|
| 66 |
+
Watch this video on modern image formats and optimization (15 min):
|
| 67 |
+
|
| 68 |
+
[](https://youtu.be/F1kYBnY6mwg)
|
| 69 |
+
|
| 70 |
+
Tools for image optimization:
|
| 71 |
+
|
| 72 |
+
* [squoosh.app](https://squoosh.app/): Browser-based compression
|
| 73 |
+
* [ImageOptim](https://imageoptim.com/): GUI tool for Mac
|
| 74 |
+
* [sharp](https://sharp.pixelplumbing.com/): Node.js image processing
|
| 75 |
+
* [Pillow](https://python-pillow.org/): Python imaging library
|
| 76 |
+
|
| 77 |
+
[Previous
|
| 78 |
+
|
| 79 |
+
Markdown](#/markdown)
|
| 80 |
+
|
| 81 |
+
[Next
|
| 82 |
+
|
| 83 |
+
Static hosting: GitHub Pages](#/github-pages)
|
markdown_files/Interactive_Notebooks__Marimo.md
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "Interactive Notebooks: Marimo"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/marimo?id=interactive-notebooks-marimo"
|
| 4 |
+
downloaded_at: "2025-06-08T23:25:35.286078"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[Interactive Notebooks: Marimo](#/marimo?id=interactive-notebooks-marimo)
|
| 8 |
+
-------------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
[Marimo](https://marimo.app/) is a new take on notebooks that solves some headaches of Jupyter. It runs cells reactively - when you change one cell, all dependent cells update automatically, just like a spreadsheet.
|
| 11 |
+
|
| 12 |
+
Marimo’s cells can’t be run out of order. This makes Marimo more reproducible and easier to debug, but requires a mental shift from the Jupyter/Colab way of working.
|
| 13 |
+
|
| 14 |
+
It also runs Python directly in the browser and is quite interactive. [Browse the gallery of examples](https://marimo.io/gallery). With a wide variety of interactive widgets, It’s growing popular as an alternative to Streamlit for building data science web apps.
|
| 15 |
+
|
| 16 |
+
Common Operations:
|
| 17 |
+
|
| 18 |
+
```
|
| 19 |
+
# Create new notebook
|
| 20 |
+
uvx marimo new
|
| 21 |
+
|
| 22 |
+
# Run notebook server
|
| 23 |
+
uvx marimo edit notebook.py
|
| 24 |
+
|
| 25 |
+
# Export to HTML
|
| 26 |
+
uvx marimo export notebook.pyCopy to clipboardErrorCopied
|
| 27 |
+
```
|
| 28 |
+
|
| 29 |
+
Best Practices:
|
| 30 |
+
|
| 31 |
+
1. **Cell Dependencies**
|
| 32 |
+
|
| 33 |
+
* Keep cells focused and atomic
|
| 34 |
+
* Use clear variable names
|
| 35 |
+
* Document data flow between cells
|
| 36 |
+
2. **Interactive Elements**
|
| 37 |
+
|
| 38 |
+
```
|
| 39 |
+
# Add interactive widgets
|
| 40 |
+
slider = mo.ui.slider(1, 100)
|
| 41 |
+
# Create dynamic Markdown
|
| 42 |
+
mo.md(f"{slider} {"🟢" * slider.value}")Copy to clipboardErrorCopied
|
| 43 |
+
```
|
| 44 |
+
3. **Version Control**
|
| 45 |
+
|
| 46 |
+
* Keep notebooks are Python files
|
| 47 |
+
* Use Git to track changes
|
| 48 |
+
* Publish on [marimo.app](https://marimo.app/) for collaboration
|
| 49 |
+
|
| 50 |
+
[](https://youtu.be/9R2cQygaoxQ)
|
| 51 |
+
|
| 52 |
+
[Previous
|
| 53 |
+
|
| 54 |
+
Narratives with LLMs](#/narratives-with-llms)
|
| 55 |
+
|
| 56 |
+
[Next
|
| 57 |
+
|
| 58 |
+
HTML Slides: RevealJS](#/revealjs)
|
markdown_files/JSON.md
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "JSON"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/revealjs"
|
| 4 |
+
downloaded_at: "2025-06-08T23:25:13.176607"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
404 - Not found
|
| 8 |
+
===============
|
markdown_files/JavaScript_tools__npx.md
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "JavaScript tools: npx"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/npx?id=javascript-tools-npx"
|
| 4 |
+
downloaded_at: "2025-06-08T23:21:38.208039"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[JavaScript tools: npx](#/npx?id=javascript-tools-npx)
|
| 8 |
+
------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
[npx](https://docs.npmjs.com/cli/v8/commands/npx) is a command-line tool that comes with npm (Node Package Manager) and allows you to execute npm package binaries and run one-off commands without installing them globally. It’s essential for modern JavaScript development and data science workflows.
|
| 11 |
+
|
| 12 |
+
For data scientists, npx is useful when:
|
| 13 |
+
|
| 14 |
+
* Running JavaScript-based data visualization tools
|
| 15 |
+
* Converting notebooks and documents
|
| 16 |
+
* Testing and formatting code
|
| 17 |
+
* Running development servers
|
| 18 |
+
|
| 19 |
+
Here are common npx commands:
|
| 20 |
+
|
| 21 |
+
```
|
| 22 |
+
# Run a package without installing
|
| 23 |
+
npx http-server . # Start a local web server
|
| 24 |
+
npx prettier --write . # Format code or docs
|
| 25 |
+
npx eslint . # Lint JavaScript
|
| 26 |
+
npx typescript-node script.ts # Run TypeScript directly
|
| 27 |
+
npx esbuild app.js # Bundle JavaScript
|
| 28 |
+
npx jsdoc . # Generate JavaScript docs
|
| 29 |
+
|
| 30 |
+
# Run specific versions
|
| 31 |
+
npx prettier@3.2 --write . # Use prettier 3.2
|
| 32 |
+
|
| 33 |
+
# Execute remote scripts (use with caution!)
|
| 34 |
+
npx github:user/repo # Run from GitHubCopy to clipboardErrorCopied
|
| 35 |
+
```
|
| 36 |
+
|
| 37 |
+
Watch this introduction to npx (6 min):
|
| 38 |
+
|
| 39 |
+
[](https://youtu.be/55WaAoZV_tQ)
|
| 40 |
+
|
| 41 |
+
[Previous
|
| 42 |
+
|
| 43 |
+
Python tools: uv](#/uv)
|
| 44 |
+
|
| 45 |
+
[Next
|
| 46 |
+
|
| 47 |
+
Unicode](#/unicode)
|
markdown_files/LLM_Agents.md
ADDED
|
@@ -0,0 +1,123 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: "LLM Agents"
|
| 3 |
+
original_url: "https://tds.s-anand.net/#/llm-agents?id=command-line-agent-example"
|
| 4 |
+
downloaded_at: "2025-06-08T23:25:53.665479"
|
| 5 |
+
---
|
| 6 |
+
|
| 7 |
+
[LLM Agents: Building AI Systems That Can Think and Act](#/llm-agents?id=llm-agents-building-ai-systems-that-can-think-and-act)
|
| 8 |
+
-------------------------------------------------------------------------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
LLM Agents are AI systems that can define and execute their own workflows to accomplish tasks. Unlike simple prompt-response patterns, agents make multiple LLM calls, use tools, and adapt their approach based on intermediate results. They represent a significant step toward more autonomous AI systems.
|
| 11 |
+
|
| 12 |
+
[](https://youtu.be/DWUdGhRrv2c)
|
| 13 |
+
|
| 14 |
+
### [What Makes an Agent?](#/llm-agents?id=what-makes-an-agent)
|
| 15 |
+
|
| 16 |
+
An LLM agent consists of three core components:
|
| 17 |
+
|
| 18 |
+
1. **LLM Brain**: Makes decisions about what to do next
|
| 19 |
+
2. **Tools**: External capabilities the agent can use (e.g., web search, code execution)
|
| 20 |
+
3. **Memory**: Retains context across multiple steps
|
| 21 |
+
|
| 22 |
+
Agents operate through a loop:
|
| 23 |
+
|
| 24 |
+
* Observe the environment
|
| 25 |
+
* Think about what to do
|
| 26 |
+
* Take action using tools
|
| 27 |
+
* Observe results
|
| 28 |
+
* Repeat until task completion
|
| 29 |
+
|
| 30 |
+
### [Command-Line Agent Example](#/llm-agents?id=command-line-agent-example)
|
| 31 |
+
|
| 32 |
+
We’ve created a minimal command-line agent called [`llm-cmd-agent.py`](llm-cmd-agent.py) that:
|
| 33 |
+
|
| 34 |
+
1. Takes a task description from the command line
|
| 35 |
+
2. Generates code to accomplish the task
|
| 36 |
+
3. Automatically extracts and executes the code
|
| 37 |
+
4. Passes the results back to the LLM
|
| 38 |
+
5. Provides a final answer or tries again if the execution fails
|
| 39 |
+
|
| 40 |
+
Here’s how it works:
|
| 41 |
+
|
| 42 |
+
```
|
| 43 |
+
uv run llm-cmd-agent.py "list all Python files under the current directory, recursively, by size"
|
| 44 |
+
uv run llm-cmd-agent.py "convert the largest Markdown file to HTML"Copy to clipboardErrorCopied
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
The agent will:
|
| 48 |
+
|
| 49 |
+
1. Generate a shell script to list files with their sizes
|
| 50 |
+
2. Execute the script in a subprocess
|
| 51 |
+
3. Capture the output (stdout and stderr)
|
| 52 |
+
4. Pass the output back to the LLM for interpretation
|
| 53 |
+
5. Present a final answer to the user
|
| 54 |
+
|
| 55 |
+
Under the hood, the agent follows this workflow:
|
| 56 |
+
|
| 57 |
+
1. Initial prompt to generate a shell script
|
| 58 |
+
2. Code extraction from the LLM response
|
| 59 |
+
3. Code execution in a subprocess
|
| 60 |
+
4. Result interpretation by the LLM
|
| 61 |
+
5. Error handling and retry logic if needed
|
| 62 |
+
|
| 63 |
+
This demonstrates the core agent loop of:
|
| 64 |
+
|
| 65 |
+
* Planning (generating code)
|
| 66 |
+
* Execution (running the code)
|
| 67 |
+
* Reflection (interpreting results)
|
| 68 |
+
* Adaptation (fixing errors if needed)
|
| 69 |
+
|
| 70 |
+
### [Agent Architectures](#/llm-agents?id=agent-architectures)
|
| 71 |
+
|
| 72 |
+
Different agent architectures exist for different use cases:
|
| 73 |
+
|
| 74 |
+
1. **ReAct** (Reasoning + Acting): Interleaves reasoning steps with actions
|
| 75 |
+
2. **Reflexion**: Adds self-reflection to improve reasoning
|
| 76 |
+
3. **MRKL** (Modular Reasoning, Knowledge and Language): Combines neural and symbolic modules
|
| 77 |
+
4. **Plan-and-Execute**: Creates a plan first, then executes steps
|
| 78 |
+
|
| 79 |
+
### [Real-World Applications](#/llm-agents?id=real-world-applications)
|
| 80 |
+
|
| 81 |
+
LLM agents can be applied to various domains:
|
| 82 |
+
|
| 83 |
+
1. **Research assistants** that search, summarize, and synthesize information
|
| 84 |
+
2. **Coding assistants** that write, debug, and explain code
|
| 85 |
+
3. **Data analysis agents** that clean, visualize, and interpret data
|
| 86 |
+
4. **Customer service agents** that handle queries and perform actions
|
| 87 |
+
5. **Personal assistants** that manage schedules, emails, and tasks
|
| 88 |
+
|
| 89 |
+
### [Project Ideas](#/llm-agents?id=project-ideas)
|
| 90 |
+
|
| 91 |
+
Here are some practical agent projects you could build:
|
| 92 |
+
|
| 93 |
+
1. **Study buddy agent**: Helps create flashcards, generates practice questions, and explains concepts
|
| 94 |
+
2. **Job application assistant**: Searches job listings, tailors resumes, and prepares interview responses
|
| 95 |
+
3. **Personal finance agent**: Categorizes expenses, suggests budgets, and identifies savings opportunities
|
| 96 |
+
4. **Health and fitness coach**: Creates workout plans, tracks nutrition, and provides motivation
|
| 97 |
+
5. **Course project helper**: Breaks down assignments, suggests resources, and reviews work
|
| 98 |
+
|
| 99 |
+
### [Best Practices](#/llm-agents?id=best-practices)
|
| 100 |
+
|
| 101 |
+
1. **Clear instructions**: Define the agent’s capabilities and limitations
|
| 102 |
+
2. **Effective tool design**: Create tools that are specific and reliable
|
| 103 |
+
3. **Robust error handling**: Agents should recover gracefully from failures
|
| 104 |
+
4. **Memory management**: Balance context retention with token efficiency
|
| 105 |
+
5. **User feedback**: Allow users to correct or guide the agent
|
| 106 |
+
|
| 107 |
+
### [Limitations and Challenges](#/llm-agents?id=limitations-and-challenges)
|
| 108 |
+
|
| 109 |
+
Current LLM agents face several challenges:
|
| 110 |
+
|
| 111 |
+
1. **Hallucination**: Agents may generate false information or tool calls
|
| 112 |
+
2. **Planning limitations**: Complex tasks require better planning capabilities
|
| 113 |
+
3. **Tool integration complexity**: Each new tool adds implementation overhead
|
| 114 |
+
4. **Context window constraints**: Limited memory for long-running tasks
|
| 115 |
+
5. **Security concerns**: Tool access requires careful permission management
|
| 116 |
+
|
| 117 |
+
[Previous
|
| 118 |
+
|
| 119 |
+
Function Calling](#/function-calling)
|
| 120 |
+
|
| 121 |
+
[Next
|
| 122 |
+
|
| 123 |
+
LLM Image Generation](#/llm-image-generation)
|