TTS-PRISM-7B
A Perceptual Reasoning and Interpretable Speech Model for Fine-Grained Diagnosis
![]()
![]()
⭐ If TTS-PRISM is helpful to your research, please help star our GitHub repo. Thanks! 🤗
![]()
![]()
⭐ If TTS-PRISM is helpful to your research, please help star our GitHub repo. Thanks! 🤗
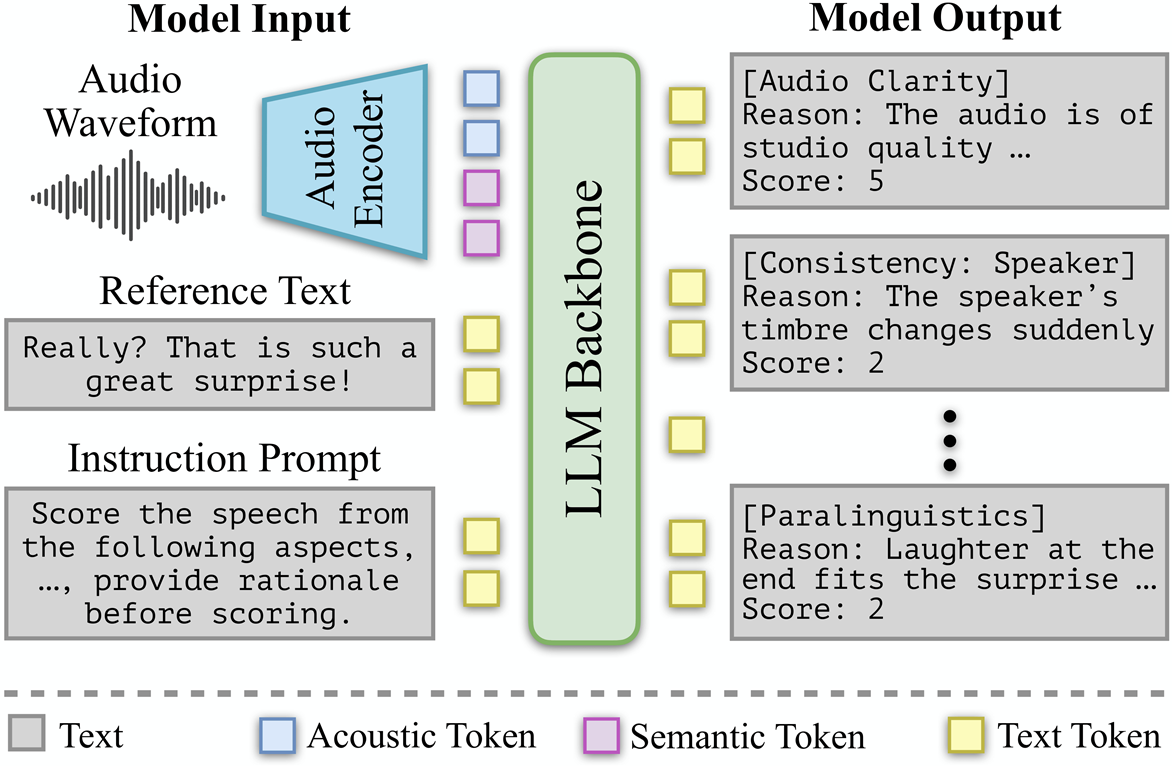
Overall architecture of the TTS-PRISM framework.