metadata
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
- AlekseiPravdin/KSI-RP-NSK-128k-7B
- flammenai/flammen18X-mistral-7B
- gguf
- Q2_K
- Q3_K_L
- Q3_K_M
- Q3_K_S
- Q4_0
- Q4_1
- Q4_K_S
- Q4_k_m
- Q5_0
- Q5_1
- Q6_K
- Q5_K_S
- Q5_k_m
- Q8_0
- 128k
language:
- en
- ru
- th
KSI-RPG-128k-7B-GGUF ⭐️⭐️⭐️
KSI-RPG-128k-7B is a merge of the following models using mergekit:
🧩 Configuration
slices:
- sources:
- model: AlekseiPravdin/KSI-RP-NSK-128k-7B
layer_range: [0, 32]
- model: flammenai/flammen18X-mistral-7B
layer_range: [0, 32]
merge_method: slerp
base_model: AlekseiPravdin/KSI-RP-NSK-128k-7B
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
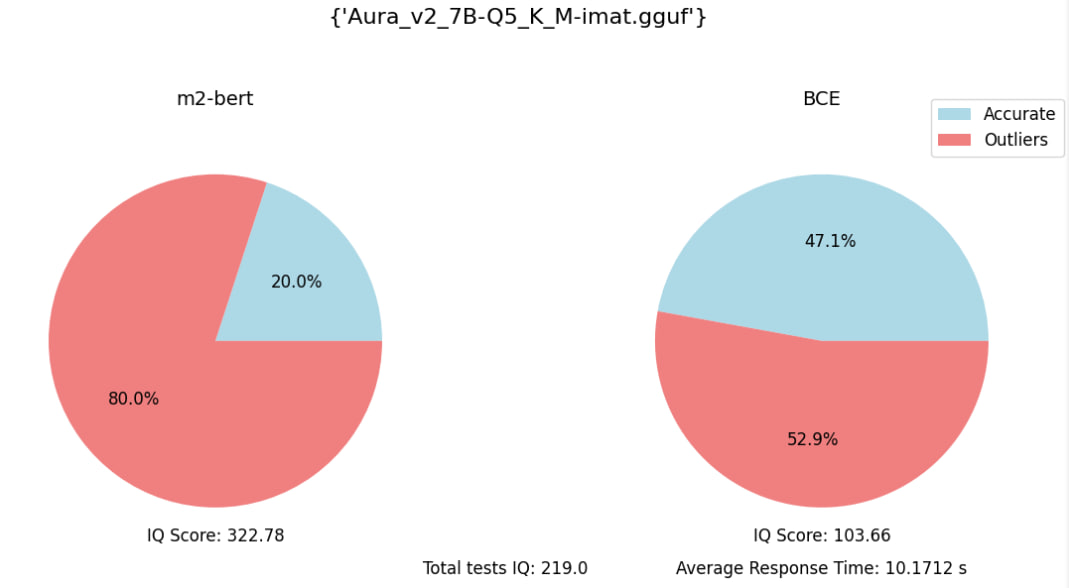
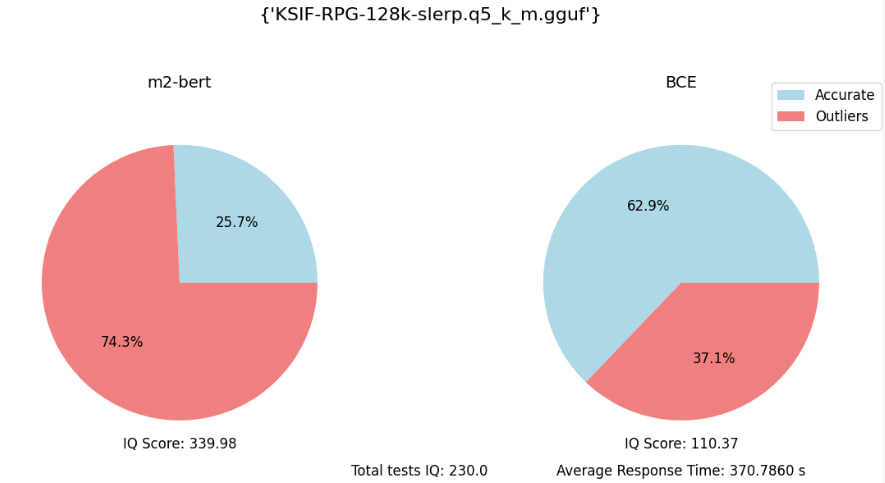
Eval embedding benchmark (with 70 specific quesions):