Buckets:

| Name | Size | Uploaded | Xet hash |
|---|---|---|---|
| .eval_results | 1 items | ||
| .gitattributes | 1.58 kB xet | 329c2979 | |
| README.md | 9.47 kB xet | e28dd7dd | |
| chat_template.jinja | 4.88 kB xet | 541fd2d5 | |
| config.json | 2.29 kB xet | db7aeee9 | |
| generation_config.json | 111 Bytes xet | 833df32a | |
| mellum-logo-dark.svg | 5.18 kB xet | 2abd7f34 | |
| mellum_evals_grid_1700.jpg | 1.34 MB xet | 47ce72da | |
| model-00001-of-00005.safetensors | 5 GB xet | db248e2f | |
| model-00002-of-00005.safetensors | 5 GB xet | a0efa518 | |
| model-00003-of-00005.safetensors | 5 GB xet | b7fa52b0 | |
| model-00004-of-00005.safetensors | 5 GB xet | ee897e1a | |
| model-00005-of-00005.safetensors | 4.31 GB xet | 2eb74ea7 | |
| model.safetensors.index.json | 527 kB xet | 60c1bc34 | |
| special_tokens_map.json | 1.19 kB xet | 8cf35d3a | |
| tokenizer.json | 7.09 MB xet | 324c8f88 | |
| tokenizer_config.json | 7.03 kB xet | 4eec4b03 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Mellum2 Thinking
Use this model when you want explicit chain-of-thought before the final answer — complex debugging, multi-step planning, agentic workflows, and math- or reasoning-heavy tasks. For direct, low-latency answers without reasoning traces, use Instruct instead.
Mellum2 Thinking Highlights
Mellum 2 Thinking is a post-trained reasoning-augmented assistant model trained by JetBrains.
The model uses a Mixture-of-Experts architecture with 64 experts and activates 8 experts per token. It uses a combination of sliding-window and full attention layers, with a context length of 131,072 tokens.
It is produced from Mellum2-12B-A2.5B-Base by supervised fine-tuning (loss computed only on the final assistant turn) followed by reinforcement learning with verifiable rewards (RLVR) on a harder data mix that includes a long-form math subset. The model emits its reasoning inside <think>...</think> blocks before the final answer.
Mellum2 Model Family
This repository contains one checkpoint from the Mellum 2 family.
| Checkpoint | Description |
|---|---|
| Base Pretrain | Base checkpoint before long-context extension |
| Base | Final base model |
| Instruct SFT | Supervised instruction-tuned checkpoint |
| Thinking SFT | Supervised thinking checkpoint |
| Instruct | RL-tuned instruction model |
| Thinking | RL-tuned thinking model |
Model Overview
Mellum2 Thinking has the following features:
- Number of Layers: 28
- Hidden Size: 2304
- Intermediate Size: 7168
- MoE Intermediate Size: 896
- Number of Experts: 64
- Number of Activated Experts: 8
- Number of Attention Heads (GQA): 32 for Q and 4 for KV
- Context Length: 131,072
- Sliding Window: 1,024
- Vocabulary Size: 98,304
- Precision: bfloat16
- License: Apache 2.0
Serving with vLLM
# Without tool calling
vllm serve JetBrains/Mellum2-12B-A2.5B-Thinking \
--max-model-len 131072 \
--reasoning-parser qwen3
# With tool calling
vllm serve JetBrains/Mellum2-12B-A2.5B-Thinking \
--max-model-len 131072 \
--reasoning-parser qwen3 \
--enable-auto-tool-choice \
--tool-call-parser hermes
Quickstart
Text-Only Input
from openai import OpenAI
# Configured by environment variables
client = OpenAI()
messages = [
{"role": "user", "content": "Is 1024 a power of 2? Explain your reasoning."},
]
chat_response = client.chat.completions.create(
model="JetBrains/Mellum2-12B-A2.5B-Thinking",
messages=messages,
max_tokens=81920,
temperature=0.6,
top_p=0.95,
extra_body={
"top_k": 20,
},
)
print("Chat response:", chat_response)
Evaluation
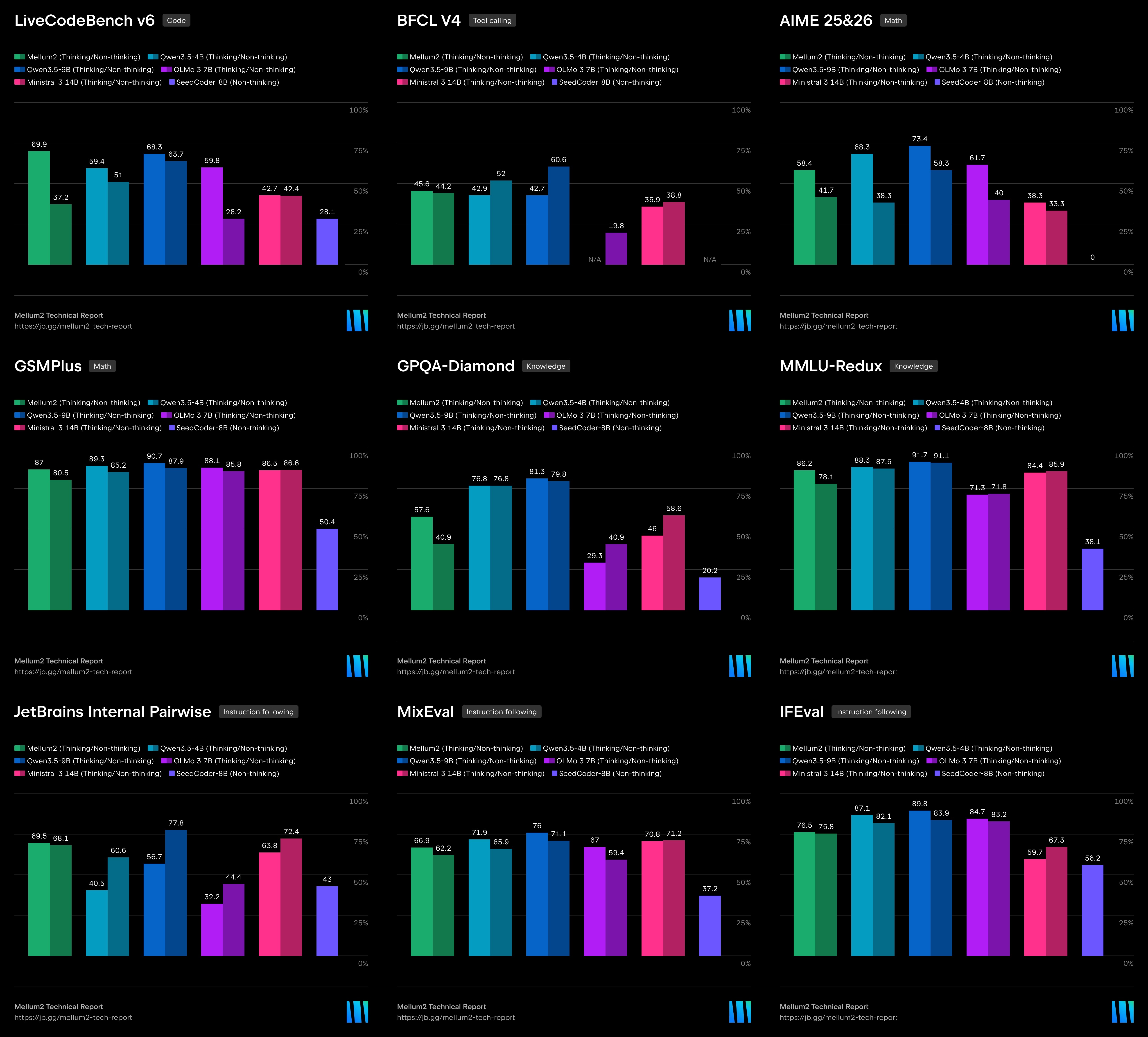
Post-training evaluation for the thinking/reasoning variants. All values are percentages; higher is better except HarmBench, where lower is better. All values self-reported by JetBrains.
| Benchmark | Mellum2 Thinking SFT | Mellum2 Thinking | Qwen3.5 (4B) | Qwen3.5 (9B) | OLMo-3 (7B) | Ministral 3 (14B) |
|---|---|---|---|---|---|---|
| Coding | ||||||
| LiveCodeBench v6 | 75.1 | 69.9 | 59.4 | 68.3 | 59.8 | 42.7 |
| Tool Use | ||||||
| BFCL v4 | 38.8 | 45.6 | 42.9 | 42.7 | — | 35.9 |
| BFCL v3 | 60.5 | 69.4 | 73.9 | 68.5 | — | 52.2 |
| Math | ||||||
| AIME | 20.0 | 58.4 | 68.3 | 73.4 | 61.7 | 38.3 |
| GSM-Plus | 62.6 | 87.0 | 89.3 | 90.7 | 88.1 | 86.5 |
| Knowledge | ||||||
| MMLU-Redux | 84.8 | 86.2 | 88.3 | 91.7 | 71.3 | 84.4 |
| GPQA Diamond | 39.9 | 57.6 | 76.8 | 81.3 | 29.3 | 46.0 |
| Conversational | ||||||
| IFEval | 69.1 | 76.5 | 87.1 | 89.8 | 84.7 | 59.7 |
| JetBrains pairwise | 64.4 | 69.5 | 40.5 | 56.7 | 32.2 | 63.8 |
| MixEval | 63.4 | 66.9 | 71.9 | 76.0 | 67.0 | 70.8 |
| BS-Bench | 14.0 | 15.0 | 63.0 | 70.0 | 23.0 | 9.0 |
| Safety | ||||||
| HarmBench (↓) | 12.2 | 20.6 | 15.9 | 6.6 | 48.7 | 70.0 |
| XSTest | 90.8 | 89.6 | 96.8 | 97.6 | 93.2 | 96.8 |
Notes:
- AIME is the mean of AIME 2025 and AIME 2026 (30 questions each).
- BFCL v4 is the macro-average of five subtasks: v1, v2, v3, web search, memory.
- JetBrains pairwise is win rate against
Qwen2.5-7B-Instructon an internal benchmark. —indicates the model lacks native tool calling (OLMo-3-7B-Thinking).
For more details, see the Mellum2 Technical Report.
License
Released under the Apache 2.0 license.
- Total size
- 24.3 GB
- Files
- 17
- Last updated
- Jun 3
- Pre-warmed CDN
- US EU US EU