
Model Card for ministral-8b-instruct-FAQ-MES-WEB
This model is a fine-tuned version of mistralai/Ministral-8B-Instruct-2410 on the fenyo/FAQ-MES-WEB dataset. It has been trained using TRL on aPC running Windows 11, WSL (Ubuntu 24.04) and one Nvidia RTX-5090 GPU.
Quick start
from transformers import pipeline
question = "Qu'est-ce que Mon espace santé ?"
generator = pipeline("text-generation", model="fenyo/ministral-8b-instruct-merged", device="cuda")
output = generator([{"role": "system", "content": "You are a helpful chatbot assistant for the Mon Espace Santé website. You answer only based on the information present in the FAQ. If the information is not available, you must respond with the predefined refusal message and nothing else."}, {"role": "user", "content": question}], max_new_tokens=4096, return_full_text=False)[0]
print(output["generated_text"])
Training procedure
![]()
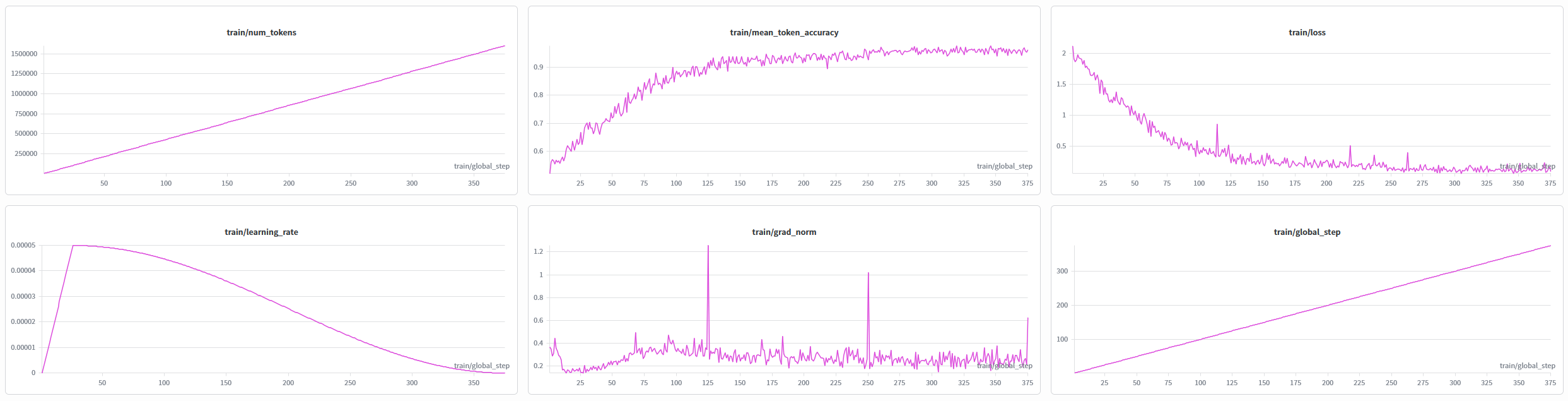
This model was trained with SFT.
Training script and parameters
Parameters file:
wandb_notebook_name="ministral-8b-instruct-FAQ-MES"
model_name="Ministral-8B-Instruct-2410"
tokenizer="Ministral-8B-Instruct-2410"
# Note: ce system_prompt n'est pas injecte par ft-small.py.
# Il doit deja etre present dans la colonne messages du dataset pour qu'il soit appris.
system_prompt="You are a helpful chatbot assistant for the Mon Espace Santé website. You answer only based on the information present in the FAQ. If the information is not available, you must respond with the predefined refusal message and nothing else."
var_dataset_name="fenyo/FAQ-MES-WEB"
var_wandb_project="fenyo-FAQ-MES-WEB-ministral"
var_wandb_run="ministral-8b-instruct"
attn_implementation="eager"
ft_bf16=True
ft_assistant_only_loss=True
lora_r=16
lora_alpha=32
lora_dropout=0.05
lora_bias="none"
lora_target_modules="q_proj" "k_proj" "v_proj" "o_proj" "gate_proj" "up_proj" "down_proj"
ft_learning_rate=5e-5
ft_gradient_checkpointing=True
ft_num_train_epochs=3
ft_logging_steps=1
ft_per_device_train_batch_size=4
ft_gradient_accumulation_steps=8
ft_max_length=1024
ft_warmup_steps=25
ft_lr_scheduler_type="cosine"
ft_output_dir="ministral-8b-instruct-lora"
ft_push_to_hub=False
ft_report_to="wandb"
ft_eval_strategy="steps"
ft_eval_steps=125
Script de finetuning :
import argparse
import os
import shlex
from huggingface_hub import login
from datasets import load_dataset
import transformers
from transformers import AutoTokenizer
import torch
from transformers import AutoModelForCausalLM
from peft import LoraConfig, TaskType
from trl.trainer.sft_config import SFTConfig
from trl.trainer.sft_trainer import SFTTrainer
def _coerce_value(raw):
lowered = raw.lower()
if lowered == "true":
return True
if lowered == "false":
return False
try:
return int(raw)
except ValueError:
pass
try:
return float(raw)
except ValueError:
pass
return raw
def _load_params(path):
params = {}
with open(path, "r", encoding="utf-8") as f:
for line in f:
stripped = line.strip()
if not stripped or stripped.startswith("#"):
continue
tokens = shlex.split(stripped)
if not tokens or "=" not in tokens[0]:
continue
key, first_value = tokens[0].split("=", 1)
values = [first_value] + tokens[1:]
if len(values) == 1:
params[key] = _coerce_value(values[0])
else:
params[key] = [_coerce_value(v) for v in values]
return params
def _get_param(params, key, alias=None, default=None, required=True):
if key in params:
return params[key]
if alias and alias in params:
return params[alias]
if required:
raise ValueError(f"Missing required parameter: {key}")
return default
def _wants_wandb(report_to):
if report_to is None:
return False
if isinstance(report_to, str):
values = [report_to]
else:
values = report_to
normalized = {str(value).strip().lower() for value in values}
return "wandb" in normalized
def _require_env(name, help_text):
value = os.environ.get(name)
if value:
return value
raise RuntimeError(f"Missing environment variable {name!r}. {help_text}")
def _get_env(name):
value = os.environ.get(name)
if value:
return value
return None
def _parse_args():
parser = argparse.ArgumentParser()
parser.add_argument(
"--max-examples",
type=int,
default=None,
help="Limit train and validation datasets to the first N examples for quick tests.",
)
parser.add_argument(
"--push-to-hub",
action="store_true",
help="Enable Hub uploads for the current run. By default, uploads are disabled.",
)
return parser.parse_args()
def _limit_dataset(dataset, max_examples):
if max_examples is None:
return dataset
if max_examples <= 0:
raise ValueError("--max-examples must be a positive integer")
return dataset.select(range(min(max_examples, len(dataset))))
def _ensure_empty_output_dir(output_dir):
if not os.path.exists(output_dir):
return
if not os.path.isdir(output_dir):
raise RuntimeError(
f"Output path exists and is not a directory: {os.path.abspath(output_dir)}"
)
if os.listdir(output_dir):
raise RuntimeError(
"Output directory is not empty. "
f"Refusing to run: {os.path.abspath(output_dir)}"
)
def _ensure_assistant_generation_template(tokenizer, assistant_only_loss):
if not assistant_only_loss:
return
chat_template = getattr(tokenizer, "chat_template", None)
if not chat_template:
raise RuntimeError(
"assistant_only_loss=True requires a tokenizer chat template, but none is configured."
)
if "{% generation %}" in chat_template:
return
assistant_block = '{{- message["content"] + eos_token}}'
if assistant_block not in chat_template:
raise RuntimeError(
"assistant_only_loss=True requires assistant generation markers, and the chat template "
"does not contain the expected assistant block to patch automatically."
)
tokenizer.chat_template = chat_template.replace(
assistant_block,
'{% generation %}{{- message["content"] + eos_token}}{% endgeneration %}',
1,
)
print(
"Patched tokenizer chat template with generation markers so assistant_only_loss can be enabled."
)
def _visible_text(text):
return (
text.replace("\r", "<CR>")
.replace("\t", "<TAB>")
.replace("\n", "<EOL>\n")
)
def _masked_visible_text(text, char_mask):
masked_chars = []
for ch, keep in zip(text, char_mask):
if keep:
masked_chars.append(ch)
elif ch == "\n":
masked_chars.append("\n")
elif ch == "\t":
masked_chars.append("\t")
else:
masked_chars.append(".")
return _visible_text("".join(masked_chars))
def _preview_training_example(dataset, tokenizer, assistant_only_loss):
if len(dataset) == 0:
raise RuntimeError("Training dataset is empty.")
example = dataset[0]
messages = example["messages"]
rendered = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=False,
)
tokenized = tokenizer.apply_chat_template(
messages,
tokenize=True,
return_dict=True,
add_generation_prompt=False,
return_assistant_tokens_mask=assistant_only_loss,
)
input_ids = tokenized["input_ids"]
assistant_mask = tokenized.get("assistant_masks")
if assistant_mask is None:
assistant_mask = [1] * len(input_ids)
tokenized_with_offsets = tokenizer(
rendered,
add_special_tokens=False,
return_offsets_mapping=True,
)
offset_ids = tokenized_with_offsets["input_ids"]
offsets = tokenized_with_offsets["offset_mapping"]
if input_ids != offset_ids:
raise RuntimeError(
"Preview tokenization mismatch between chat template rendering and tokenizer offsets."
)
char_mask = [False] * len(rendered)
for keep, (start, end) in zip(assistant_mask, offsets):
if keep:
for idx in range(start, end):
char_mask[idx] = True
trainable_text = "".join(
ch for ch, keep in zip(rendered, char_mask) if keep
)
print("\n=== First Training Example Preview ===")
print(f"Messages in example: {len(messages)}")
print(f"Rendered characters: {len(rendered)}")
print(f"Rendered tokens: {len(input_ids)}")
print(f"Trainable tokens: {sum(assistant_mask)}")
print(
"\nView 1: Full model input."
" This is the exact text produced by the chat template and sent to the model."
" It should include control tokens such as <s>, [INST], [/INST], the user prompt,"
" and the assistant answer."
)
print("\nRendered chat template:")
print(_visible_text(rendered))
print(
"\nView 2: Same model input after applying the loss mask."
" Visible characters are the ones whose tokens contribute to the training loss."
" Dots mark text that is still provided to the model as context but should not be optimized,"
" such as [INST], the prompt, and other prompt-side control tokens."
)
print("\nRendered chat template after loss mask:")
print(_masked_visible_text(rendered, char_mask))
print(
"\nView 3: Trainable text only."
" This is the assistant-side text extracted from the masked view."
" It should contain only what we want the fine-tuning objective to learn to predict."
)
print("\nTrainable text only:")
print(_visible_text(trainable_text))
print("=== End Preview ===\n")
def _load_tokenizer(tokenizer_name):
attempts = [
{
"kwargs": {"use_fast": True, "fix_mistral_regex": True},
"reason": "preferred tokenizer load with mistral regex fix",
},
{
"kwargs": {"use_fast": True, "fix_mistral_regex": False},
"reason": "fallback when the local tokenizers API is incompatible with the mistral regex patch",
},
{
"kwargs": {"use_fast": False},
"reason": "last-resort tokenizer load without fast-tokenizer features",
},
]
errors = []
for attempt in attempts:
try:
if errors:
print(
f"Retrying tokenizer load for {tokenizer_name!r}: {attempt['reason']}."
)
return AutoTokenizer.from_pretrained(tokenizer_name, **attempt["kwargs"])
except Exception as exc:
errors.append((attempt["kwargs"], exc))
message = str(exc)
can_retry = False
if (
attempt["kwargs"].get("fix_mistral_regex") is True
and "backend_tokenizer" in message
):
can_retry = True
elif "fix_mistral_regex" in message:
can_retry = True
if not can_retry:
raise
attempted = ", ".join(str(kwargs) for kwargs, _ in errors)
raise RuntimeError(
f"Unable to load tokenizer {tokenizer_name!r} after trying: {attempted}"
) from errors[-1][1]
def _fold_system_into_user(example):
messages = example.get("messages", [])
if len(messages) < 2:
return example
first_message = messages[0]
second_message = messages[1]
if first_message.get("role") != "system" or second_message.get("role") != "user":
return example
system_text = (first_message.get("content") or "").strip()
user_text = (second_message.get("content") or "").strip()
merged_user = dict(second_message)
merged_user["content"] = (
"Instructions:\n"
f"{system_text}\n\n"
"Question utilisateur:\n"
f"{user_text}"
)
example["messages"] = [merged_user] + messages[2:]
return example
args = _parse_args()
params_path = os.environ.get("PARAMS_CFG", "params-small.cfg")
if not os.path.isabs(params_path):
params_path = os.path.join(os.path.dirname(__file__), params_path)
params = _load_params(params_path)
known_keys = {
"var_dataset_name",
"var_wandb_project",
"var_wandb_run",
"wandb_notebook_name",
"model_name",
"tokenizer",
"system_prompt",
"attn_implementation",
"ft_bf16",
"ft_assistant_only_loss",
"lora_r",
"lora_alpha",
"lora_dropout",
"lora_bias",
"lora_target_modules",
"ft_learning_rate",
"ft_gradient_checkpointing",
"ft_num_train_epochs",
"ft_logging_steps",
"ft_per_device_train_batch_size",
"ft_gradient_accumulation_steps",
"ft_max_length",
"ft_warmup_steps",
"ft_lr_scheduler_type",
"ft_output_dir",
"ft_push_to_hub",
"ft_report_to",
"ft_eval_strategy",
"ft_eval_steps",
}
unknown_keys = sorted(k for k in params.keys() if k not in known_keys)
if unknown_keys:
print(f"Unknown keys in {params_path}: {', '.join(unknown_keys)}")
target_modules = _get_param(params, "lora_target_modules")
if isinstance(target_modules, str):
target_modules = [target_modules]
resolved_params = {
"var_dataset_name": _get_param(params, "var_dataset_name"),
"var_wandb_project": _get_param(params, "var_wandb_project"),
"var_wandb_run": _get_param(params, "var_wandb_run"),
"wandb_notebook_name": _get_param(params, "wandb_notebook_name"),
"model_name": _get_param(params, "model_name", default=None, required=False),
"tokenizer": _get_param(params, "tokenizer"),
"attn_implementation": _get_param(params, "attn_implementation", default="eager", required=False),
"ft_bf16": _get_param(params, "ft_bf16", default=True, required=False),
"ft_assistant_only_loss": _get_param(params, "ft_assistant_only_loss", default=True, required=False),
"lora_r": _get_param(params, "lora_r"),
"lora_alpha": _get_param(params, "lora_alpha"),
"lora_dropout": _get_param(params, "lora_dropout"),
"lora_bias": _get_param(params, "lora_bias"),
"lora_target_modules": target_modules,
"ft_learning_rate": _get_param(params, "ft_learning_rate"),
"ft_gradient_checkpointing": _get_param(params, "ft_gradient_checkpointing"),
"ft_num_train_epochs": _get_param(params, "ft_num_train_epochs"),
"ft_logging_steps": _get_param(params, "ft_logging_steps"),
"ft_per_device_train_batch_size": _get_param(params, "ft_per_device_train_batch_size"),
"ft_gradient_accumulation_steps": _get_param(params, "ft_gradient_accumulation_steps"),
"ft_max_length": _get_param(params, "ft_max_length"),
"ft_warmup_steps": _get_param(params, "ft_warmup_steps"),
"ft_lr_scheduler_type": _get_param(params, "ft_lr_scheduler_type"),
"ft_output_dir": _get_param(params, "ft_output_dir"),
"ft_push_to_hub": _get_param(params, "ft_push_to_hub"),
"ft_report_to": _get_param(params, "ft_report_to"),
"ft_eval_strategy": _get_param(params, "ft_eval_strategy"),
"ft_eval_steps": _get_param(params, "ft_eval_steps"),
}
resolved_params["ft_push_to_hub"] = args.push_to_hub
_ensure_empty_output_dir(resolved_params["ft_output_dir"])
print(f"Config values from {params_path}:")
for key in sorted(resolved_params.keys()):
print(f" {key}={resolved_params[key]}")
var_dataset_name = resolved_params["var_dataset_name"]
var_wandb_project = resolved_params["var_wandb_project"]
var_wandb_run = resolved_params["var_wandb_run"]
wandb_notebook_name = resolved_params["wandb_notebook_name"]
tokenizer_name = resolved_params["tokenizer"]
model_name = resolved_params["model_name"] or tokenizer_name
model_kwargs = dict(
attn_implementation=resolved_params["attn_implementation"],
dtype=torch.bfloat16,
use_cache=False,
)
os.environ['WANDB_NOTEBOOK_NAME'] = wandb_notebook_name
hf_token = _get_env("hfkey")
if hf_token:
login(token=hf_token)
else:
print("hfkey is not set; relying on local Hugging Face access and cached credentials.")
if _wants_wandb(resolved_params["ft_report_to"]):
try:
import wandb
except ModuleNotFoundError as exc:
raise ModuleNotFoundError(
"Weights & Biases reporting is enabled but the 'wandb' package is not installed. "
"Install it with '.venv/bin/python -m pip install wandb' or disable W&B by setting "
"ft_report_to=\"none\" in the params file."
) from exc
wandb.login(key=_require_env("wandbkey", "Export your Weights & Biases token or disable W&B with ft_report_to=\"none\"."))
wandb.init(project=var_wandb_project, entity="alexandre-fenyo-fenyonet", name=var_wandb_run)
# Chargement du tokenizer
tokenizer = _load_tokenizer(tokenizer_name)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
_ensure_assistant_generation_template(
tokenizer, resolved_params["ft_assistant_only_loss"]
)
# Chargement du modèle
model = AutoModelForCausalLM.from_pretrained(model_name, **model_kwargs)
model.config.pad_token_id = tokenizer.pad_token_id
# Chargement des jeux de données
train_dataset = load_dataset(var_dataset_name, split="train")
# Conserve uniquement la colonne "messages" (ou adapte selon ton schéma)
train_dataset = train_dataset.remove_columns([c for c in train_dataset.column_names if c != "messages"])
train_dataset = train_dataset.map(_fold_system_into_user)
train_dataset = _limit_dataset(train_dataset, args.max_examples)
eval_dataset = load_dataset(var_dataset_name, split="validation")
eval_dataset = eval_dataset.remove_columns([c for c in eval_dataset.column_names if c != "messages"])
eval_dataset = eval_dataset.map(_fold_system_into_user)
eval_dataset = _limit_dataset(eval_dataset, args.max_examples)
print(f"Dataset sizes: train={len(train_dataset)} validation={len(eval_dataset)}")
_preview_training_example(
train_dataset, tokenizer, resolved_params["ft_assistant_only_loss"]
)
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=resolved_params["lora_r"],
lora_alpha=resolved_params["lora_alpha"],
lora_dropout=resolved_params["lora_dropout"],
bias=resolved_params["lora_bias"],
target_modules=target_modules,
)
training_args = SFTConfig(
learning_rate=resolved_params["ft_learning_rate"],
bf16=resolved_params["ft_bf16"],
gradient_checkpointing=resolved_params["ft_gradient_checkpointing"],
num_train_epochs=resolved_params["ft_num_train_epochs"],
logging_steps=resolved_params["ft_logging_steps"],
per_device_train_batch_size=resolved_params["ft_per_device_train_batch_size"],
gradient_accumulation_steps=resolved_params["ft_gradient_accumulation_steps"],
max_length=resolved_params["ft_max_length"],
warmup_steps=resolved_params["ft_warmup_steps"],
lr_scheduler_type=resolved_params["ft_lr_scheduler_type"],
output_dir=resolved_params["ft_output_dir"],
push_to_hub=resolved_params["ft_push_to_hub"],
report_to=resolved_params["ft_report_to"],
eval_strategy=resolved_params["ft_eval_strategy"],
eval_steps=resolved_params["ft_eval_steps"],
assistant_only_loss=resolved_params["ft_assistant_only_loss"],
save_strategy="epoch",
save_total_limit=100,
)
trainer = SFTTrainer(
model=model,
peft_config=peft_config,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
processing_class=tokenizer,
)
trainer.train()
trainer.save_model(training_args.output_dir)
# trainer.push_to_hub(dataset_name=var_dataset_name)
Framework versions
accelerate==1.13.0
datasets==4.8.4
huggingface_hub==1.8.0
nbclient==0.10.4
nbformat==5.10.4
peft==0.18.1
tokenizers==0.22.2
torch==2.11.0
transformers==5.4.0
trl==0.29.1
wandb==0.25.1
- Downloads last month
- 339
Model tree for fenyo/ministral-8b-instruct-FAQ-MES-WEB
Base model
mistralai/Ministral-8B-Instruct-2410