
TTS-PRISM-7B
A Perceptual Reasoning and Interpretable Speech Model for Fine-Grained Diagnosis
![]()
![]()
⭐ If TTS-PRISM is helpful to your research, please help star our GitHub repo. Thanks! 🤗
📖 Introduction
While generative text-to-speech (TTS) models approach human-level quality, monolithic metrics (like MOS) fail to diagnose fine-grained acoustic artifacts or explain perceptual collapse. To address this, we propose TTS-PRISM, a multi-dimensional diagnostic framework for Mandarin.
Powered by the MiMo-Audio backbone and fine-tuned on a targeted 200k-sample diagnostic dataset, TTS-PRISM embeds explicit scoring criteria and reasoning into an efficient end-to-end model. It not only predicts scores but also generates rationales explaining the specific acoustic flaws or expressive highlights.
🎯 The 12-Dimensional Evaluation Schema
Unlike generalist models, TTS-PRISM evaluates speech across a strictly defined 12-dimensional hierarchical taxonomy:
| Layer | Dimension | Description |
|---|---|---|
| Basic Capability (Score 1-5) |
🎧 Audio Clarity | Detects background noise, electronic distortion, or artifacts. |
| 🗣️ Pronunciation | Identifies incomplete articulation, tone sandhi errors, etc. | |
| 🎵 Prosody (3) | Evaluates Intonation, Pauses, and Speech Rate. | |
| 🔄 Consistency (3) | Monitors Speaker, Style, and Emotion consistency. | |
| Advanced Expressiveness (Score 0-2 Bonus) |
💥 Stress | Evaluates keyword emphasis via pitch or loudness. |
| 〰️ Lengthening | Checks for natural syllabic lengthening at phrase boundaries. | |
| 🎭 Paralinguistics | Detects non-verbal cues (laughter, sighs, breaths). | |
| 💖 Emotion | Evaluates the fullness and intensity of the expressed sentiment. |
🏗 Architecture Overview
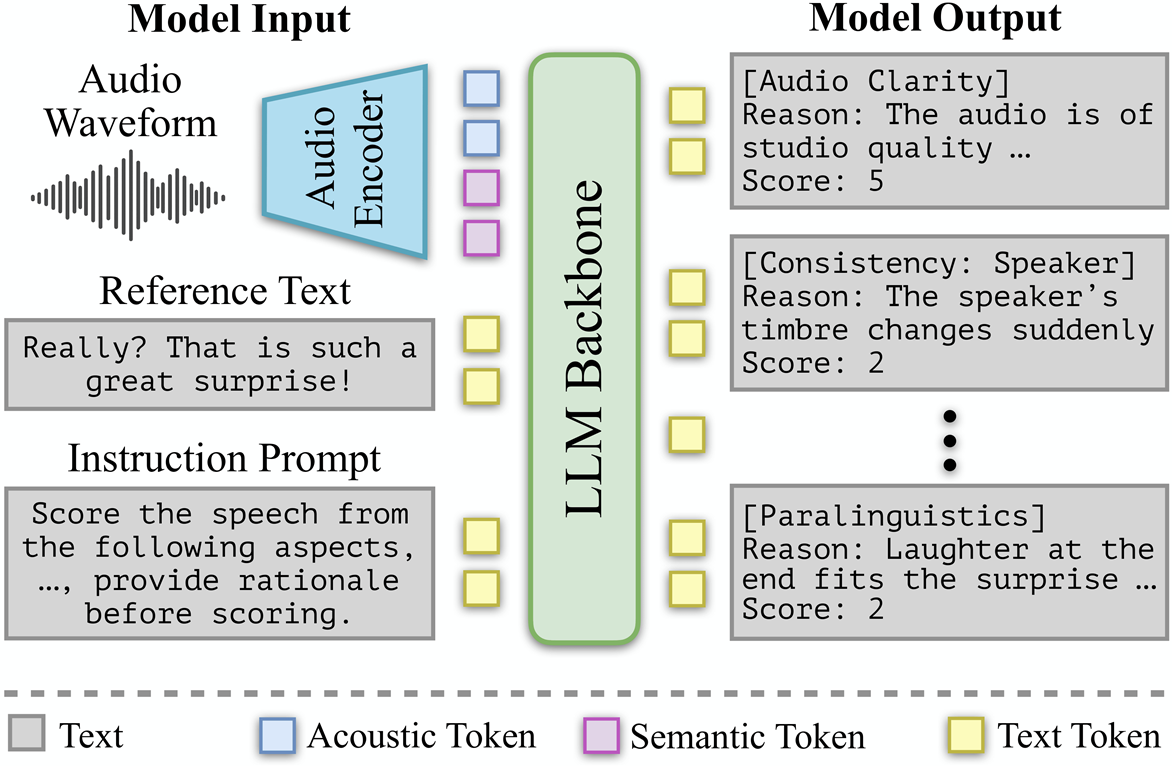
Overall architecture of the TTS-PRISM framework.
📥 Model Download & Usage
This repository contains the model weights for TTS-PRISM-7B.
You can download the model weights using the huggingface-cli:
pip install huggingface-hub
# Download the Tokenizer
hf download XiaomiMiMo/MiMo-Audio-Tokenizer --local-dir ./models/MiMo-Audio-Tokenizer
# Download the TTS-PRISM-7B weights
hf download xiaomi-research/TTS-PRISM-7B --local-dir ./models/TTS-PRISM-7B
🚀 Running Inference
For the complete inference pipeline, data preparation, and 12-dimensional diagnostic scripts, please visit our official GitHub repository: 👉 xiaomi-research/tts-prism
✒️ Citation
If you find our work helpful, please cite our paper:
@inproceedings{wang2026ttsprism,
title={TTS-PRISM: A Perceptual Reasoning and Interpretable Speech Model for Fine-Grained Diagnosis},
author={Wang, Xi and others},
booktitle={Interspeech},
year={2026}
}
⚖️ License
This project is licensed under the Apache License 2.0. Copyright (c) 2026 Xiaomi Corporation.
- Downloads last month
- 15